- The paper introduces DialectGen, a novel benchmark that quantifies performance drops of 32%–48% in multimodal models when processing dialectal variations.
- It details an encoder-based mitigation strategy using dialect learning, polysemy control, and KL regularization to align representations without sacrificing polysemy performance.
- Empirical results show a +34.4% improvement in dialect performance on Stable Diffusion 1.5 with minimal SAE loss, demonstrating practical enhancements for equitable multimodal generation.
DialectGen: Benchmarking and Improving Dialect Robustness in Multimodal Generation
Motivation and Problem Statement
Multimodal generative models, particularly text-to-image and text-to-video systems, are increasingly deployed in real-world applications where users interact using diverse linguistic varieties. English, as a contact language, exhibits substantial dialectal variation, yet the majority of pretraining corpora and model development pipelines focus on Standard American English (SAE) and, to a lesser extent, British English (BrE). This leads to a systematic underrepresentation of lower-resource dialects, resulting in significant performance disparities and allocational harms for dialect speakers. The paper introduces DialectGen, a large-scale benchmark and mitigation framework to systematically evaluate and improve the dialect robustness of multimodal generative models.

Figure 1: Multimodal generative model outputs on semantically identical prompts differing only in a single synonymous lexical feature in Standard American English (top) and a lower-resource English dialect (bottom).
DialectGen Benchmark: Dataset Construction and Validation
DialectGen comprises over 4,200 rigorously validated prompts spanning six English dialects: SAE, BrE, Chicano English (ChE), Indian English (InE), Singaporean English (SgE), and African American English (AAE). The dataset construction pipeline involves:
- Lexeme Selection: Extraction of 1,126 dialectal lexemes and their SAE equivalents from authoritative regional dictionaries.
- Prompt Generation: Use of GPT-4o to generate concise (≤6 words) and detailed (≥9 words) visual scene prompts for each lexeme pair, ensuring the dialect lexeme is central to the scene.
- Human Validation: Dual annotation by dialect speakers via a custom Amazon Mechanical Turk interface, including a dialect assessment quiz to ensure annotator-dialect alignment.

Figure 2: The Amazon Mechanical Turk data annotation interface for dialect speaker human filtering of generated prompts.
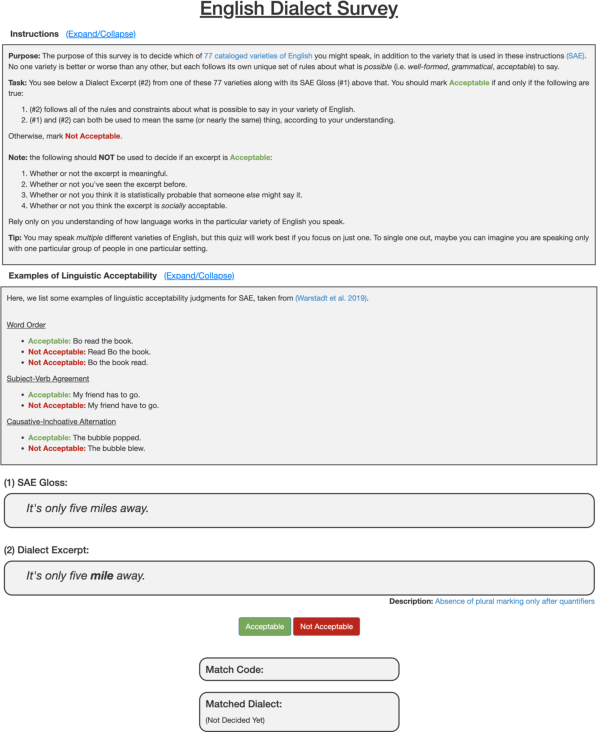
Figure 3: The English Dialect Speaker Assessment Quiz for matching annotators to dialects.
Prompts are retained only if both annotators confirm exact synonymy and lack of ambiguity, especially for polysemous lexemes. This process results in a high-quality, controlled dataset suitable for robust benchmarking.
Empirical Evaluation: Model Robustness Analysis
Seventeen state-of-the-art text-to-image and text-to-video generative models are evaluated on DialectGen using both automatic (VQAScore, CLIPScore) and human alignment metrics. The evaluation protocol computes the relative performance drop when a single dialectal lexeme replaces its SAE counterpart in a prompt.
Key findings:
- Severe Performance Degradation: SOTA models exhibit 32.26% to 48.17% performance drops on dialectal prompts, with the most pronounced failures for ChE and InE. BrE, being higher-resource, incurs smaller drops.
- Prompt Length Sensitivity: Concise prompts reveal larger robustness gaps than detailed prompts, indicating that models rely heavily on context to disambiguate dialectal terms.
- Polysemy Failure Modes: Models systematically default to SAE interpretations of polysemous lexemes, even when contextually implausible.
Baseline Mitigation Strategies and Limitations
The study benchmarks several mitigation strategies:
- UNet Fine-tuning: Standard practice in diffusion models, but yields only marginal dialect gains (<7%) and often degrades SAE and polysemy performance.
- Prompt Revision/Translation: LLM-based prompt rewriting or translation to SAE improves dialect performance by small margins, but does not address the underlying representation gap.
Encoder-Based Mitigation: Methodology
The core contribution is a general encoder-based mitigation strategy targeting the text encoder of diffusion-based generative models. The approach integrates three loss components:
- Dialect Learning Loss (LDL): Minimizes cosine distance between the target encoder's embedding of a dialect prompt and the frozen encoder's embedding of its SAE synonym, aligning their semantic representations.
- Polysemy Control Loss (LPC): Preserves the model's ability to distinguish polysemous lexemes in SAE contexts by minimizing the distance between target and frozen encoder embeddings for SAE polysemous prompts.
- KL Regularization (LKL): Maintains general SAE performance by aligning the output distribution of the target encoder with the frozen reference encoder using surrogate logits derived from similarity scores in a shared image-text embedding space.
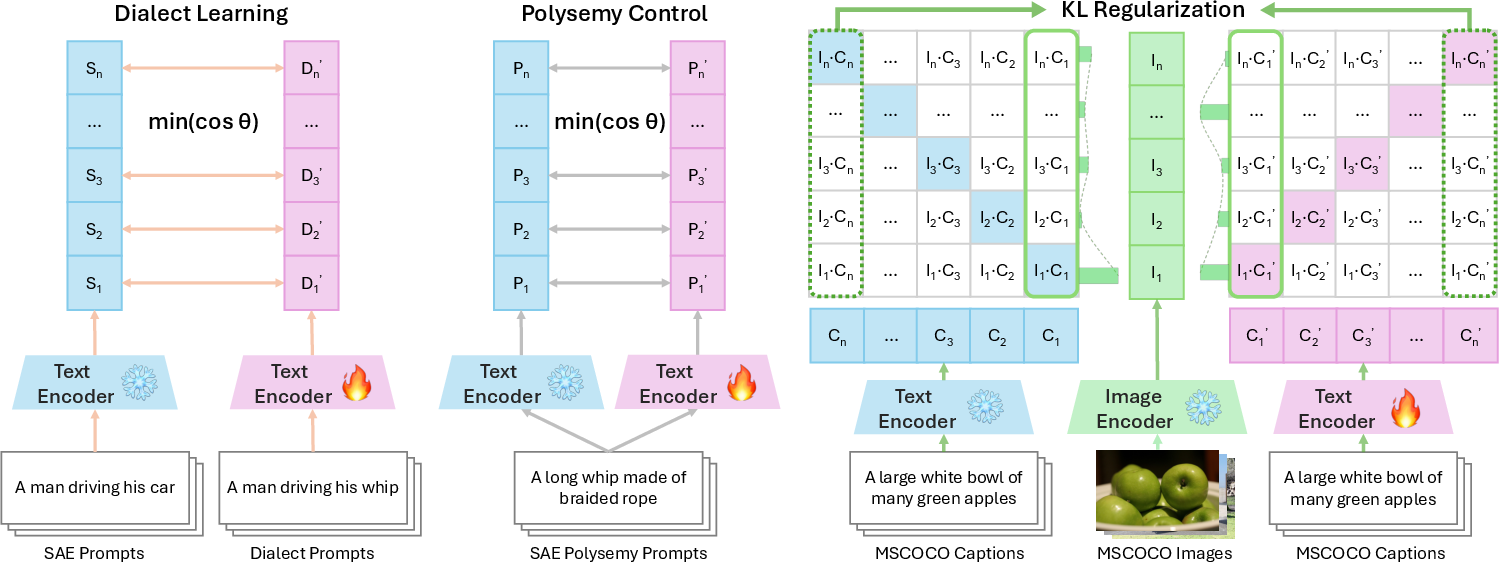
Figure 4: Losses used in the mitigation strategy, with text prompts for Dialect Learning and Polysemy Control from DialectGen and image-caption pairs for KL Regularization from MSCOCO.
Quantitative and Qualitative Results
The encoder-based mitigation strategy achieves:
Implementation Considerations
- Computational Efficiency: Fine-tuning the text encoder with the proposed losses is computationally efficient, requiring less than one hour on a single NVIDIA RTX A6000 GPU for SD1.5, and approximately one hour on four GPUs for SDXL.
- Generalizability: The method is compatible with CLIP-style encoders and can be extended to other multimodal architectures with shared embedding spaces.
- Resource Requirements: Text-to-video models incur higher computational costs, but the mitigation strategy is designed to be model-agnostic and scalable.
Theoretical and Practical Implications
The findings demonstrate that lexical dialectal variation, rather than grammatical variation, is the primary driver of robustness failures in current multimodal generative models. The encoder-based mitigation approach provides a principled mechanism for aligning dialectal and SAE representations without sacrificing generalization or polysemy handling. This has direct implications for equitable model deployment in linguistically diverse settings and highlights the need for dialect-aware pretraining and evaluation protocols.
Future Directions
- Cultural and Representational Biases: Systematic study of representational shifts (e.g., skin tone, environment) induced by dialectal prompts.
- Grammatical and Joint Variation: Extension of evaluation to grammatical and multi-lexeme dialectal variations.
- Downstream Impact: Assessment of dialectal robustness gaps on downstream tasks and societal outcomes.
- Text-to-Video Mitigation: Application and scaling of the mitigation strategy to high-resource text-to-video models.
Conclusion
DialectGen establishes a rigorous benchmark and mitigation framework for dialect robustness in multimodal generative models. The encoder-based mitigation strategy achieves strong dialectal robustness without compromising SAE or polysemy performance, setting a new standard for equitable and inclusive multimodal generation. The work underscores the necessity of dialect-aware model development and provides a reproducible foundation for future research in this domain.
