- The paper presents a hybrid model that integrates deterministic prediction with autoregressive diffusion to capture fine-scale precipitation details.
- It introduces token-wise attention to reduce computational complexity, enabling full-resolution self-attention on high-dimensional radar data.
- Experimental results on four benchmark datasets demonstrate improved localization, perceptual quality, and temporal robustness over previous methods.
RainDiff: End-to-End Precipitation Nowcasting via Token-wise Attention Diffusion
Introduction and Motivation
Precipitation nowcasting, the short-term prediction of radar echo sequences, is a critical task in meteorology due to the chaotic and tightly coupled spatio-temporal dynamics of atmospheric processes. Traditional NWP methods, while physically grounded, are computationally prohibitive for rapid updates. Deep learning-based deterministic models, such as ConvLSTM and SimVP, have improved large-scale advection modeling but suffer from oversmoothing and loss of fine-scale details at longer lead times. Probabilistic generative models, including GANs and diffusion-based approaches, introduce stochasticity to mitigate blurriness but often degrade positional accuracy due to excessive randomness. Hybrid architectures, such as DiffCast and CasCast, attempt to balance deterministic and stochastic modeling but face scalability and generalization limitations, particularly due to reliance on latent autoencoders or omission of attention mechanisms in pixel space.
RainDiff Architecture
RainDiff introduces a hybrid framework that integrates Token-wise Attention (TWA) into both the U-Net diffusion model and the spatio-temporal encoder, enabling efficient full-resolution self-attention directly in pixel space. The architecture comprises three main components:
- Deterministic Predictor (Fθ1): Estimates the conditional mean μ(X0) of future radar frames using MSE loss, capturing global motion trends.
- Spatio-temporal Encoder (Fθ3): Processes the concatenation of input frames and deterministic predictions to extract conditioning features h, refined by a Post-attention module to emphasize salient context and suppress irrelevant information.
- Diffusion-based Stochastic Module (Fθ2): Models the residual r=y−μ via a segment-wise autoregressive diffusion process, conditioned on h and previously predicted segments.
The overall framework is illustrated below.
(Figure 1)
Figure 1: RainDiff architecture: deterministic prediction, cascaded spatio-temporal encoding with Post-attention, and segment-wise diffusion with Token-wise Attention.
Token-wise Attention Mechanism
Conventional self-attention mechanisms, such as those in ViT, incur quadratic complexity in the number of tokens, making them infeasible for high-resolution radar data. RainDiff's Token-wise Attention reduces this to linear complexity by aggregating global query and key representations via learnable weights and softmax normalization along the token dimension. This enables full-resolution attention at all spatial scales without latent bottlenecks or external autoencoders. The output is refined through MLPs operating on normalized queries and key-value interactions.
Spatio-temporal Encoder and Post-attention
The spatio-temporal encoder is constructed as a cascade of ResNet and ConvGRU blocks, extracting multi-resolution conditioning features. Post-attention is applied after the encoder outputs, rather than within recurrent steps, to mitigate gradient attenuation and improve training stability. This design choice is empirically validated to yield higher efficiency and comparable or superior performance to in-block attention integration.
Stochastic Segment-wise Diffusion
RainDiff models the residual sequence in contiguous segments, each predicted autoregressively via a backward diffusion process. The denoising is conditioned on the global context h and previously generated segments, with the overall loss balancing deterministic and stochastic components. This approach reduces variance and improves sample fidelity, particularly at longer forecast horizons.
Experimental Results
RainDiff is evaluated on four benchmark datasets: Shanghai Radar, SEVIR, MeteoNet, and CIKM, using metrics such as CSI, HSS, LPIPS, and SSIM. The model is trained end-to-end for 300K iterations with a batch size of 4 on a single NVIDIA A6000 GPU. RainDiff consistently outperforms deterministic and probabilistic baselines across all datasets and metrics, achieving superior localization, perceptual quality, and robustness at long lead times.
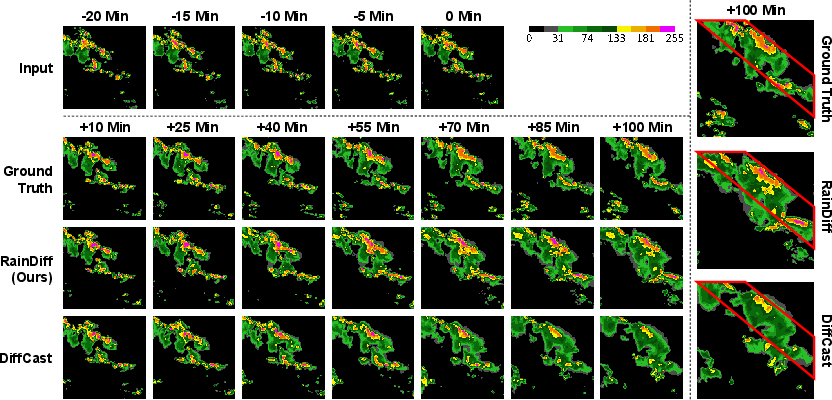
Figure 2: SEVIR dataset visualization: RainDiff preserves weather fronts and avoids oversmoothing at the longest forecast horizon compared to DiffCast.
(Figure 3)
Figure 3: Qualitative comparison on Shanghai Radar: RainDiff generates sharper, more coherent precipitation contours than deterministic and stochastic baselines.
Frame-wise CSI and HSS analyses demonstrate that RainDiff maintains higher accuracy and skill scores as lead time increases, indicating enhanced temporal robustness.
(Figure 4)
Figure 4: Frame-wise CSI and HSS for various methods on Shanghai Radar: RainDiff sustains superior performance at longer horizons.
Ablation Studies
Ablation experiments confirm the necessity of both Token-wise Attention and Post-attention. Removing either component results in significant performance degradation. Alternative attention integration strategies within the spatio-temporal encoder are less efficient and do not match the performance of RainDiff's Post-attention design.
Computational Efficiency
Token-wise Attention achieves O(nd) time and space complexity, a substantial improvement over the O(n2) complexity of ViT-style self-attention, enabling scalable deployment on high-resolution radar data without latent compression.
Implications and Future Directions
RainDiff advances the state-of-the-art in precipitation nowcasting by enabling efficient, high-fidelity, and robust generative modeling of spatio-temporal radar sequences. The elimination of latent autoencoders enhances generalization and simplifies the training pipeline, making the approach broadly applicable to other domains with high-dimensional spatio-temporal data. Theoretical analysis and empirical results highlight the importance of attention placement and computational tractability in diffusion-based forecasting.
Future work may incorporate physical constraints via multi-modal inputs, further reduce latency by replacing autoregressive sampling, and extend the framework to other geoscientific and medical imaging applications where high-resolution, temporally coherent generative modeling is required.
Conclusion
RainDiff presents a scalable, end-to-end diffusion framework for precipitation nowcasting, leveraging Token-wise Attention and Post-attention to achieve superior localization, perceptual quality, and long-horizon robustness. The architectural innovations and empirical results underscore the practical and theoretical significance of efficient attention mechanisms in spatio-temporal generative modeling.