Coupled Diffusion Sampling for Training-Free Multi-View Image Editing
Abstract: We present an inference-time diffusion sampling method to perform multi-view consistent image editing using pre-trained 2D image editing models. These models can independently produce high-quality edits for each image in a set of multi-view images of a 3D scene or object, but they do not maintain consistency across views. Existing approaches typically address this by optimizing over explicit 3D representations, but they suffer from a lengthy optimization process and instability under sparse view settings. We propose an implicit 3D regularization approach by constraining the generated 2D image sequences to adhere to a pre-trained multi-view image distribution. This is achieved through coupled diffusion sampling, a simple diffusion sampling technique that concurrently samples two trajectories from both a multi-view image distribution and a 2D edited image distribution, using a coupling term to enforce the multi-view consistency among the generated images. We validate the effectiveness and generality of this framework on three distinct multi-view image editing tasks, demonstrating its applicability across various model architectures and highlighting its potential as a general solution for multi-view consistent editing.









Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
What is this paper about?
This paper shows a simple way to edit a set of photos of the same object or scene (taken from different angles) so that all the edits match each other. It does this without extra training, using existing AI image editors. The key idea is called “coupled diffusion sampling,” which gently ties together a regular 2D image editor and a multi-view model so the final edits look right from every view.
Key Objectives
In clear terms, the paper aims to:
- Make edits consistent across different camera views of the same object or scene, using off-the-shelf 2D editing models.
- Avoid slow, fragile 3D optimization methods like NeRF that need many views and lots of compute.
- Create a general, training-free method that works for several kinds of edits, such as changing shape (spatial edits), altering style (stylization), and changing lighting (relighting).
Methods and Approach
The problem with multi-view editing
Imagine you have a statue and you take photos all around it. If you paint a red stripe on one photo using a normal 2D editor, you want the stripe to appear in the right place in all other photos too. Standard 2D editors edit each photo separately, so the stripe often slips, stretches, or disappears in other views. Some methods try to build a full 3D model to fix this, but that’s slow and tricky when you don’t have many photos.
What is a diffusion model, simply?
Think of a diffusion model like an artist who starts with a super noisy picture (like TV static) and slowly “cleans” it step by step until a clear image appears. Each step uses learned “hints” (directions) about what a real image should look like.
Coupled diffusion sampling (the core idea)
The paper runs two “artists” at the same time:
- The 2D editing model: good at making the edit look how you want (e.g., style change, object move, new lighting).
- The multi-view model: good at keeping different views consistent with each other.
They tie these two artists together with a soft “rubber band.” At every step of generation, each model sees what the other is making and is gently pulled toward it, while still staying true to its own strengths. This “rubber band” is a simple mathematical term that encourages the two outputs to be close without forcing them to be identical.
In practice:
- The method adds an extra guidance term during sampling that nudges the 2D edited images and the multi-view images toward each other.
- No extra training is needed; it all happens at inference-time (during generation).
- It works in the “latent space” of Stable Diffusion (think of latent space like a compact, secret code version of an image that’s quicker to process).
Why this works
- Any sequence from a well-trained multi-view model tends to be view-consistent by design.
- Any edit from a strong 2D model tends to satisfy the user’s editing goal.
- Gently coupling them gets the best of both: edits that are consistent across angles and faithful to the user’s intent.
Main Findings
The authors tested their method on three common multi-view editing tasks. Here’s what they found:
- Spatial editing (changing shape or position): The method preserved the object’s identity and produced realistic changes (like correct shadows) across views, beating baselines on both visual quality and consistency.
- Stylization (changing look with prompts, e.g., “make it watercolor”): It kept the subject consistent across angles and reduced flicker, while following the style prompt well. Competing methods either lost identity, flickered, or produced artifacts.
- Relighting (changing lighting with an environment map or text): The method reduced color flicker and kept lighting consistent across views, matching or improving metrics compared to baselines like NeRF-based relighting and other model-combination methods.
Other highlights:
- Works across different model backbones (e.g., SD2.1, SDXL; multi-view models like Stable Virtual Camera, MVDream, MV-Adapter).
- Also helps align two different text prompts in a 2D flow model (Flux), showing the coupling idea is versatile.
- User studies showed strong preference for the coupled results.
- There’s a tunable “guidance strength” (how tight the rubber band is). Increasing it improves faithfulness to the edit but can reduce cross-view diversity if too high, so you choose a balanced value.
Why It’s Important
This method makes multi-view image editing practical and fast:
- Training-free and optimization-free: No heavy 3D training or long optimization loops.
- Flexible: Works with various existing 2D editors and multi-view models.
- Consistent: Produces edits that look correct from different angles, which is crucial for content creation, product visualization, and AR/VR.
Looking ahead, the same idea could be extended to video: coupling a 2D editor with a video diffusion model could create edits that stay consistent across frames, again without extra training. In short, coupled diffusion sampling offers a simple, general recipe for making AI edits more reliable across viewpoints and time.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, concrete list of what remains missing, uncertain, or unexplored in the paper, framed to guide future research:
- Lack of theoretical guarantees: no formal characterization of the target joint distribution induced by the coupling term, nor proofs of convergence, bias, or preservation of each model’s marginal; unclear when the method “stays within” each model’s prior versus drifting.
- Dependence on shared schedules/latents: the algorithm assumes matched DDPM noise schedules and a shared latent space; how to couple models with different samplers (DDIM/DPM-Solver/consistency models), different time parameterizations, or incompatible latent spaces remains open.
- Energy design is simplistic: the Euclidean x0-based coupling ignores camera geometry; explore geometry-aware potentials (e.g., epipolar constraints, depth/normal consistency, cross-view optical flow, pose-conditioned warping) and their impact on 3D correctness.
- Guidance scheduling is ad hoc: only a global scalar λ is used; investigate principled, time-dependent, or adaptive schedules (e.g., Lagrangian/dual updates, verifier-based auto-tuning, inconsistency-driven λ), and spatially varying coupling to allow local edits without over-regularizing.
- Limited analysis of noise choices: the roles of independent vs shared/correlated noise across the two trajectories and across views are not studied; quantify how noise coupling affects alignment, diversity, and stability.
- Where to couple remains underexplored: coupling is done in the SD latent; systematically compare latent vs pixel vs feature-space coupling (and hybrid schemes) for color fidelity, artifact suppression, and geometry preservation.
- Computational and memory costs: running two diffusion models concurrently scales linearly in cost; no runtime/memory profiling, multi-GPU strategies, or analysis of scalability to high resolutions and large numbers of views (e.g., N>16).
- Robustness to camera issues: assumptions about known/accurate camera poses are not explicit; sensitivity to pose noise, rolling-shutter/exposure variation, and unposed inputs is untested; integration with pose estimation/SLAM remains open.
- Sparse and uneven view coverage: behavior under very sparse, highly non-overlapping, or imbalanced view sets is not quantified; guidelines for the minimum viable coverage are missing.
- Diversity–consistency trade-off: increasing λ improves per-image fidelity but can collapse diversity or harm consistency; develop mechanisms that explicitly control this trade-off (e.g., constrained sampling, diversity-promoting priors, orthogonal subspace noise).
- Multi-view model conflicts: when the 2D edit conflicts with the multi-view model’s prior (e.g., “CGI-like” bias, background priors), there is no conflict-resolution policy; devise edit-strength controls, per-region weights, or learned arbitration.
- Lighting fidelity and flicker: evaluation uses metrics that may miss subtle temporal/view lighting flicker; develop task-appropriate perceptual flicker measures and physical light-transport consistency checks, and study disentanglement from view-dependent effects.
- Background control in text relighting: acknowledged weak background prior is not addressed; explore coupling with dedicated background generators, matting/segmentation-aware coupling, or scene decomposition.
- Scope of spatial edits: demonstrated edits are mostly rigid transforms; effectiveness on nonrigid deformations, topology changes, insertions/removals, and complex object–scene interactions remains unclear.
- Complex scenes and occlusions: performance in cluttered, multi-object scenes with heavy occlusions is not evaluated; design occlusion-aware coupling or region-specific constraints.
- Generalization across backbones/samplers: a brief 2D flow-model example (Flux) is shown, but no general derivation for flow/consistency/rectified-flow samplers, nor for cross-backbone multi-view models; establish a unifying coupling framework across generative families.
- Automatic λ selection: no procedure for selecting λ beyond manual tuning; investigate verifier/critic-based auto-tuning, Bayesian optimization, or reinforcement strategies for task-specific λ.
- Reproducibility and stability: sensitivity to seeds, initialization, and hyperparameters is not reported; provide variance analyses, failure cases, and robust defaults.
- Evaluation scope: user studies (n=25) and datasets are small; expand to standardized multi-view benchmarks (e.g., DTU, CO3D), in-the-wild captures, low-light/HDR conditions, and report stronger identity/edit-fidelity metrics (beyond VBench/CLIP), including face/instance retrieval measures where applicable.
- Scaling to video: the paper suggests video as future work but does not address how to jointly enforce temporal and cross-view consistency (e.g., tri-plane coupling over time, causal sampling, motion-aware energies); define concrete protocols and baselines.
- Learning the coupling: the coupling is hand-crafted at test time; explore learnable energy functions or lightweight adapters trained on small multi-view/edit corpora to improve robustness while retaining data efficiency.
- Downstream 3D reconstruction: while improving 2D multi-view consistency, it is unclear how edits affect downstream 3D reconstruction (mesh/NeRF quality, photometric/geometry accuracy); provide metrics like triangulation error, depth consistency, or reconstruction fidelity.
Practical Applications
Summary
The paper introduces coupled diffusion sampling: an inference-time method that jointly samples from a pre-trained 2D image editing model and a pre-trained multi-view diffusion model using a simple coupling term. This produces edits that are faithful to the 2D editing objective while remaining multi-view consistent—without training new models or optimizing explicit 3D representations. Demonstrated tasks include multi-view spatial editing (object moves/geometry changes), stylization (e.g., ControlNet), and relighting (environment-map and text-driven), with generalization across backbones (SD2.1, SDXL) and even flow-based generators (Flux).
Below are practical, real-world applications derived from the method, organized by immediacy, with sectors, potential tools/workflows, and key dependencies/assumptions.
Immediate Applications
These applications can be deployed now with available 2D editing and multi-view diffusion models.
- Multi-view product content editing and relighting (E-commerce, Advertising)
- Use case: Apply brand-consistent styles, colorways, or lighting across all angles of a product shot on a turntable or captured from multiple viewpoints.
- Tools/workflows:
- “CoupledSampler” plugin for product photo pipelines (e.g., integration with Shopify/BigCommerce asset managers).
- ControlNet-based stylization or IC-Light/Neural Gaffer for relighting, coupled with a multi-view model such as Stable Virtual Camera.
- Dependencies/assumptions:
- Access to pre-trained 2D editing model (e.g., ControlNet, IC-Light) and a multi-view diffusion model in a compatible latent space (e.g., SD2.1/SDXL).
- Sufficient GPU resources for dual-trajectory sampling; careful choice of coupling strength λ.
- Rapid, 3D-free asset retexturing for games and AR/VR (Gaming, XR, Digital Content)
- Use case: Generate consistent textures/appearances across camera views for 3D assets without SDS optimization or full recon.
- Tools/workflows:
- “Retexture” add-on for Blender/Unreal that couples ControlNet stylization with a multi-view generator; export UV maps via multi-view texture baking.
- Dependencies/assumptions:
- Input multi-view images (e.g., rig or turntable captures) of the asset; latent-space alignment between models.
- Multi-camera scene relighting for previsualization (VFX/Film, Broadcast)
- Use case: Preview scene relighting across multi-camera rigs quickly, maintaining consistency across angles for art direction or pre-viz.
- Tools/workflows:
- On-set tool coupling Neural Gaffer (env-map) or IC-Light (text) with a multi-view model; batch inference across cameras.
- Dependencies/assumptions:
- Stable camera calibration or known relative viewpoints improves results; high-quality environment maps for controlled relighting.
- Spatial edits propagated across all views (Creative studios, Photography)
- Use case: Move/remove/replace objects consistently across multiple images of a scene (e.g., repositioning props, fixing set elements, adjusting shadows).
- Tools/workflows:
- “Magic Fixup MV” pipeline: perform coarse 3D-aware edit (depth-assisted unproject/transform/reproject), then run coupled sampling to harmonize across views.
- Dependencies/assumptions:
- Depth estimation or proxy geometry for robust 3D-aware edits; careful λ scheduling to avoid over-constraining edits.
- Domain randomization for multi-camera rigs (Robotics, Autonomous Driving, Simulation)
- Use case: Apply consistent style/lighting/weather transforms across synchronized cameras for training perception models.
- Tools/workflows:
- ROS/Gazebo/Carla nodes that wrap the coupled sampler to transform multi-view datasets uniformly.
- Dependencies/assumptions:
- Multi-view priors should match domain (urban/outdoor scenes benefit from MV priors trained on similar data); compute budget for dataset-scale processing.
- Real estate staging and material changes across angles (AEC, Real Estate)
- Use case: Change flooring, wall paints, or material finishes consistently across a room’s multi-view capture for client approvals.
- Tools/workflows:
- AEC pipeline integration (Twinmotion/Enscape plugins) to stylize material appearance with ControlNet+MV coupling.
- Dependencies/assumptions:
- Interior scene priors in the MV model improve stability; managing complex specularities/shadows may require careful λ.
- Cultural heritage virtual restoration (Museums, Heritage Digitization)
- Use case: Non-destructive virtual cleanup/restoration applied consistently across archived multi-view captures of artifacts.
- Tools/workflows:
- Curator UI to annotate a single view; propagate via coupled sampling; export consistent multi-view visualizations.
- Dependencies/assumptions:
- Domain-appropriate 2D restoration model; conservative λ to preserve identity and detail.
- Multi-view dataset generation and augmentation (Academia, ML engineering)
- Use case: Create multi-view-consistent training/benchmark datasets with controlled style/illumination variations.
- Tools/workflows:
- Dataset generator CLI/SDK that accepts base views and transforms (style, relight, spatial edit) and emits consistent multi-view variants; includes MEt3r-based QA.
- Dependencies/assumptions:
- License-compliant base models; bias auditing (MV priors often exhibit “Objaverse-like” appearance—coupling with strong T2I reduces this but doesn’t eliminate it).
- Creator tools for 3D social posts (Consumer apps)
- Use case: Users walk around an object/person, then apply a single style or relight that remains consistent across angles for interactive posts.
- Tools/workflows:
- Mobile/cloud hybrid: on-device capture + cloud coupled sampling; simple λ slider for “more edit vs. more consistency.”
- Dependencies/assumptions:
- Likely requires cloud inference today; privacy and provenance controls recommended.
Long-Term Applications
These require further research, scaling, model availability, or engineering to meet performance, fidelity, or safety constraints.
- Spatiotemporal scene editing with moving cameras (VFX/Film, XR)
- Use case: Coupling 2D video editing models with video/multi-view diffusion to maintain both temporal coherence and view consistency across complex shots.
- Tools/products:
- “Coupled Video-MV” editor; distillation/acceleration for near-real-time previews.
- Dependencies/assumptions:
- Strong video diffusion priors; memory-efficient multi-trajectory sampling; robust λ schedules through time; motion-aware coupling.
- Live, multi-camera broadcast relighting and branding (Media, Sports)
- Use case: Real-time, consistent relighting and style overlays across all broadcast cameras.
- Tools/products:
- FPGA/GPU edge accelerators; model distillation/LoRA specialization for specific venues; control surfaces for lighting directors.
- Dependencies/assumptions:
- Tight latency budgets; safety guardrails (no identity drift); calibration and pose priors; legal review for on-air transformations.
- Generalized 3D-free scene authoring and set-dressing (Design, Virtual Production)
- Use case: Interactive object placement, material changes, and global relighting across sparse-view captures without explicit 3D reconstruction.
- Tools/products:
- WYSIWYG authoring suite with coupled sampling under-the-hood; hybrid depth priors to stabilize geometry-sensitive edits.
- Dependencies/assumptions:
- Richer MV priors trained on indoor/outdoor scenes; integration with depth/normal predictors; UI for edit provenance and rollback.
- Sim-to-real appearance adaptation preserving geometry (Robotics, Autonomous Systems)
- Use case: Couple strong 2D stylizers (domain adaptation) with MV priors to avoid geometry drift across multi-sensor rigs; improve transfer.
- Tools/products:
- Synthetic data factories with coupled modules; automated λ tuning per scene and sensor.
- Dependencies/assumptions:
- Large-scale automation (thousands of scenes); robust evaluation of geometry preservation; safety validation.
- Aerial mapping relighting/deweathering across flight lines (GIS, Surveying)
- Use case: Normalize lighting/weather over multi-view aerial imagery for mosaicking and 3D recon quality improvements.
- Tools/products:
- Photogrammetry pre-processing plugin that runs coupled relighting before SfM/MVS.
- Dependencies/assumptions:
- MV prior trained on aerial/top-down scenes; preservation of radiometric integrity; QA against photogrammetric metrics.
- Medical multi-view consistency editing (Healthcare imaging; exploratory)
- Use case: Consistent artifact removal or illumination normalization across stereo/endoscopic multi-view sequences for analysis or teaching.
- Tools/products:
- Research tools with domain-specific priors; rigorous clinical validation.
- Dependencies/assumptions:
- Medical-grade models and datasets; strict safety, interpretability, and regulatory compliance; strong constraints to avoid hallucinations.
- Cross-modal coupling (Audio–visual, Text–MV, Physics–MV)
- Use case: Enforce consistency between MV visuals and external modalities (e.g., audio-driven lighting cues or textual scene rules).
- Tools/products:
- Generalized “Coupler SDK” supporting arbitrary differentiable energies U(x, x’); adapters for flow and diffusion models.
- Dependencies/assumptions:
- Reliable cross-modal priors; stable optimization with multiple constraints; conflict resolution between objectives.
- Provenance, watermarking, and compliance for multi-view synthetic media (Policy, Trust & Safety)
- Use case: Embed provenance/watermarking in coupled sampling outputs; certify consistent edits across views for disclosure requirements.
- Tools/products:
- C2PA-compliant provenance injection during sampling; consistency attestations (e.g., MEt3r thresholds).
- Dependencies/assumptions:
- Standardized APIs in foundational models; governance frameworks for synthetic MV content; user consent and IP licensing.
- Industrial design review at scale (Manufacturing)
- Use case: Batch-generate consistent colorway/finish options across multi-view photos of prototypes for stakeholder reviews.
- Tools/products:
- PLM add-ons that invoke coupled stylization/relighting; comparison dashboards.
- Dependencies/assumptions:
- Corporate compute infrastructure; traceability (which edits applied, when, by whom); approval workflows.
Notes on Feasibility and Assumptions (global)
- Model availability and compatibility:
- Requires a suitable pair of models: a 2D editing model for the task and a multi-view diffusion model with compatible latent spaces (e.g., SD2.1-to-SD2.1, SDXL-to-SDXL).
- Performance and identity preservation depend on the MV prior; coupling helps reduce “CGI/Objaverse” look but may not eliminate it entirely.
- Compute and performance:
- Two concurrent sampling trajectories raise compute and memory needs versus single-model generation. Distillation/acceleration may be needed for real-time use.
- Edit–consistency trade-off:
- Tuning λ is critical: higher λ increases faithfulness to 2D edits but can reduce cross-view consistency or cause collapse; scheduling λ over timesteps is often beneficial.
- Input coverage and depth cues:
- Sparse views are supported but depth/pose estimates improve spatial edits and shadow/reflection coherence; best results when views overlap sufficiently.
- Safety, IP, and governance:
- Ensure rights to edit source content and to use base models; provide provenance/watermarking; apply guardrails to avoid harmful or deceptive uses.
- Evaluation and QA:
- Use multi-view metrics (e.g., MEt3r), temporal/subject consistency (e.g., VBench), and task-specific checks; human preference studies for subjective quality.
Glossary
- 3D Gaussian Splatting: A graphics representation that renders scenes using a set of 3D Gaussians for fast, differentiable view synthesis. Example: "3D Gaussian Splatting"
- Canny edges: Edge maps produced by the Canny detector, often used as geometric conditioning for image generation/editing. Example: "such as the Canny edges of an image."
- Classifier guidance: A technique that steers diffusion sampling toward target labels using gradients from a discriminative classifier. Example: "A widely used technique is classifier guidance, where a discriminative classifier steers the diffusion trajectory toward a target label"
- CLIP score: A text-image alignment metric computed using CLIP to evaluate how well outputs match prompts. Example: "CLIP score is computed against the edit prompt."
- Compositional sampling methods: Inference procedures that combine the priors or scores of multiple diffusion models to generate outputs satisfying multiple constraints. Example: "Compositional sampling methods for diffusion models have been proposed to combine the priors of multiple models."
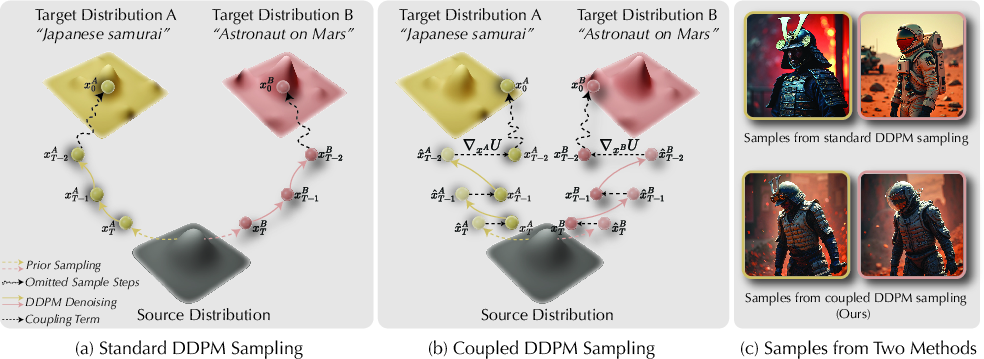
- Coupled DDPM Sampling: An algorithm that jointly samples from two DDPMs with an added coupling term to keep their trajectories close. Example: "Coupled DDPM Sampling"
- Coupled diffusion sampling: A sampling strategy that concurrently runs two diffusion processes and couples them to enforce cross-model consistency. Example: "This is achieved through coupled diffusion sampling, a simple diffusion sampling technique that concurrently samples two trajectories from both a multi-view image distribution and a 2D edited image distribution"
- Coupling function: A function that measures closeness between two samples to guide coupled sampling. Example: "We introduce a coupling function U: ℝd × ℝd → ℝ that measures the closeness of two samples."
- Energy term: An additional potential added during sampling to bias trajectories toward satisfying coupling or constraints. Example: "by steering the standard diffusion sampling trajectory with an energy term coupling two sampling trajectories."
- Environment map: A full lighting representation of the surrounding environment used to relight scenes/objects. Example: "which takes an explicit environment map as input"
- Euclidean Distance: The L2 norm used as a closeness measure in the coupling objective. Example: "A natural choice is the Euclidean Distance"
- Feed-forward sampling: Generating outputs via a fixed forward pass without expensive per-scene optimization. Example: "our method does not require a costly optimization process, as it relies solely on feed-forward sampling."
- Flow-based model: A generative model that transforms noise to data via learned continuous flows or ODEs. Example: "Although Flux is a flow-based model"
- Forward noising process: The diffusion forward process that incrementally adds noise to data according to a schedule. Example: "consider the forward noising process:"
- Foundation multi-view diffusion model: A pre-trained, general-purpose multi-view generator used as a prior to regularize consistency. Example: "we couple it with a foundation multi-view diffusion model"
- Gradient-based guidance: Steering diffusion sampling using gradients of a differentiable objective defined on generated samples. Example: "gradient-based guidance can be directly applied during sampling"
- Guidance strength (λ): A hyperparameter controlling the influence of the coupling/regularization term during sampling. Example: "We quantitatively evaluate the effects of guidance strength λ on spatial editing performance."
- Implicit 3D regularization: Enforcing 3D/multi-view consistency by constraining samples to a multi-view image distribution rather than optimizing an explicit 3D representation. Example: "We propose an implicit 3D regularization approach by constraining the generated 2D image sequences to adhere to a pre-trained multi-view image distribution."
- Latent space: A lower-dimensional feature space in which diffusion models operate to generate or edit images efficiently. Example: "operate in the latent space of Stable Diffusion 2.1"
- Linear inverse problems: Reconstruction tasks where observations are linear transforms of unknown signals, often addressed with diffusion priors. Example: "as in linear inverse problems"
- MEt3r: A metric designed to measure 3D/multi-view consistency of generated image sets. Example: "MEt3r \citep{asim24met3r}, which measures the 3D consistency of multi-view outputs."
- Multi-view consistency: Consistency of appearance, geometry, and identity across different viewpoints. Example: "maintain multi-view consistency"
- Multi-view diffusion models: Diffusion models that generate sets of images across views with built-in cross-view coherence. Example: "multi-view diffusion models"
- MultiDiffusion: A compositional diffusion method that fuses scores/trajectories to handle tasks like stitching large images or panoramas. Example: "MultiDiffusion~\citep{bar2023multidiffusion} and SyncTweedies~\citep{kim2024synctweedies} apply score composition for stitching panoramas or large images."
- NeRF (Neural Radiance Fields): A neural volumetric scene representation used for novel view synthesis and 3D reasoning. Example: "NeRF~\citep{mildenhall2020nerf}"
- Novel view synthesis: Generating new viewpoints of a scene/object given one or more input views. Example: "is a novel view synthesis model"
- Product-of-experts sampling: Sampling from the product of multiple model distributions to enforce multiple constraints simultaneously. Example: "product-of-experts sampling"
- PSNR: Peak Signal-to-Noise Ratio, a pixel-wise fidelity metric for image reconstruction quality. Example: "Table~\ref{tab:spatial_edit} demonstrates that our method achieves higher PSNR and SSIM scores"
- Radiance fields: Functions describing emitted/ reflected radiance throughout 3D space; used to model and render view- and light-dependent appearance. Example: "radiance fields can effectively regularize inconsistencies."
- Rejection sampling: A sampling technique used to filter generated candidates according to a target criterion or verifier. Example: "rejection sampling or verifier-based search over large latent spaces"
- Score averaging methods: Heuristics that combine multiple diffusion model scores by averaging, often weakening fidelity or consistency. Example: "score averaging methods have difficulty preserving the identity of the edited subject"
- Score distillation sampling (SDS): Using diffusion model score gradients to supervise 3D assets or textures without paired data. Example: "through score distillation sampling"
- SSIM: Structural Similarity Index Measure, an image quality metric focused on perceived structural similarity. Example: "Table~\ref{tab:spatial_edit} demonstrates that our method achieves higher PSNR and SSIM scores"
- Stop gradient operation: An operator that prevents gradients from flowing through certain variables during optimization/sampling. Example: "where \mathrm{sg} denotes the stop gradient operation."
- SyncTweedies: A synchronized multi-diffusion framework that composes scores across regions/tiles to generate large or structured outputs. Example: "SyncTweedies~\citep{kim2024synctweedies}"
- Text-to-image model: A generative model that synthesizes images conditioned on text prompts. Example: "the text-to-image model Flux"
- Text-to-multi-view models: Generative models that produce multiple view-consistent images from text (or with text conditioning). Example: "text-to-multi-view models, specifically MVDream"
- Unproject/Reproject: 3D geometry operations that map image pixels to 3D (using depth) and back to image space to apply consistent spatial edits. Example: "we unproject the target object in each image using a depth map. We then apply a 3D transformation to the object and reproject it into the image."
- Variance schedule: The sequence of noise variances used across diffusion timesteps in the forward and reverse processes. Example: "with a variance schedule {σt}{t=1}T."
- Verifier-based search: Guidance via a verifier model that scores samples, used to select or steer better generations. Example: "rejection sampling or verifier-based search over large latent spaces"
- VBench: A benchmark for evaluating aspects like temporal and subject consistency in generated videos. Example: "we assess both temporal and subject consistency in our generated videos using VBench"
- View dependent effects: Appearance changes tied to viewpoint (e.g., specular highlights), which can be confounded during relighting. Example: "view dependent effects"
Collections
Sign up for free to add this paper to one or more collections.