- The paper introduces AUGUSTUS, which integrates multimodal signals with human-inspired memory processes.
- It employs a four-stage methodology—encode, store, retrieve, act—with graph-structured contextual memory for efficient, concept-driven retrieval.
- Experimental results demonstrate a 3.5× faster retrieval speed and enhanced performance in ImageNet classification and conversational benchmarks.
AUGUSTUS: An LLM-Driven Multimodal Agent System with Contextualized User Memory
Introduction
The paper "AUGUSTUS: An LLM-Driven Multimodal Agent System with Contextualized User Memory" (2510.15261) introduces AUGUSTUS, a novel multimodal agent system inspired by human cognitive models of memory, particularly retrieval-augmented generation (RAG). This system innovatively integrates multimodal signals within its memory architecture, aiming to overcome the limitations of existing systems which predominantly utilize text-based memory storage. AUGUSTUS operates through four main stages—encode, store in memory, retrieve, and act—structured to mimic human cognitive processes as described in cognitive neuroscience. This approach not only enhances efficiency but also showcases improvements in processing tasks such as ImageNet classification where it outperforms traditional systems like MemGPT.
System Architecture
AUGUSTUS is engineered as a loop of operations grounded in cognitive science, designed to simulate human memory processes. The loop begins with the encoding stage, where diverse modalities (text, images, audio) are transcribed into textual format using powerful models like Video-LLaVA and WhisperX. This text-based transformation facilitates storage and retrieval within the system's memory architecture, which mirrors the constructs of human episodic and semantic memory.
The storage component is divided into in-context memory (akin to working memory) and external memory databases such as recall and contextual memory. The latter utilizes a novel graph-structured contextual memory allowing for efficient, concept-driven retrieval, leveraging semantic tagging. This architectural choice is critical for minimizing retrieval times and optimizing storage efficiency. Contrastively, recall memory logs historical interactions, ensuring comprehensive chronological context.
Figure illustrations provide insights into memory organization and retrieval mechanics within AUGUSTUS:
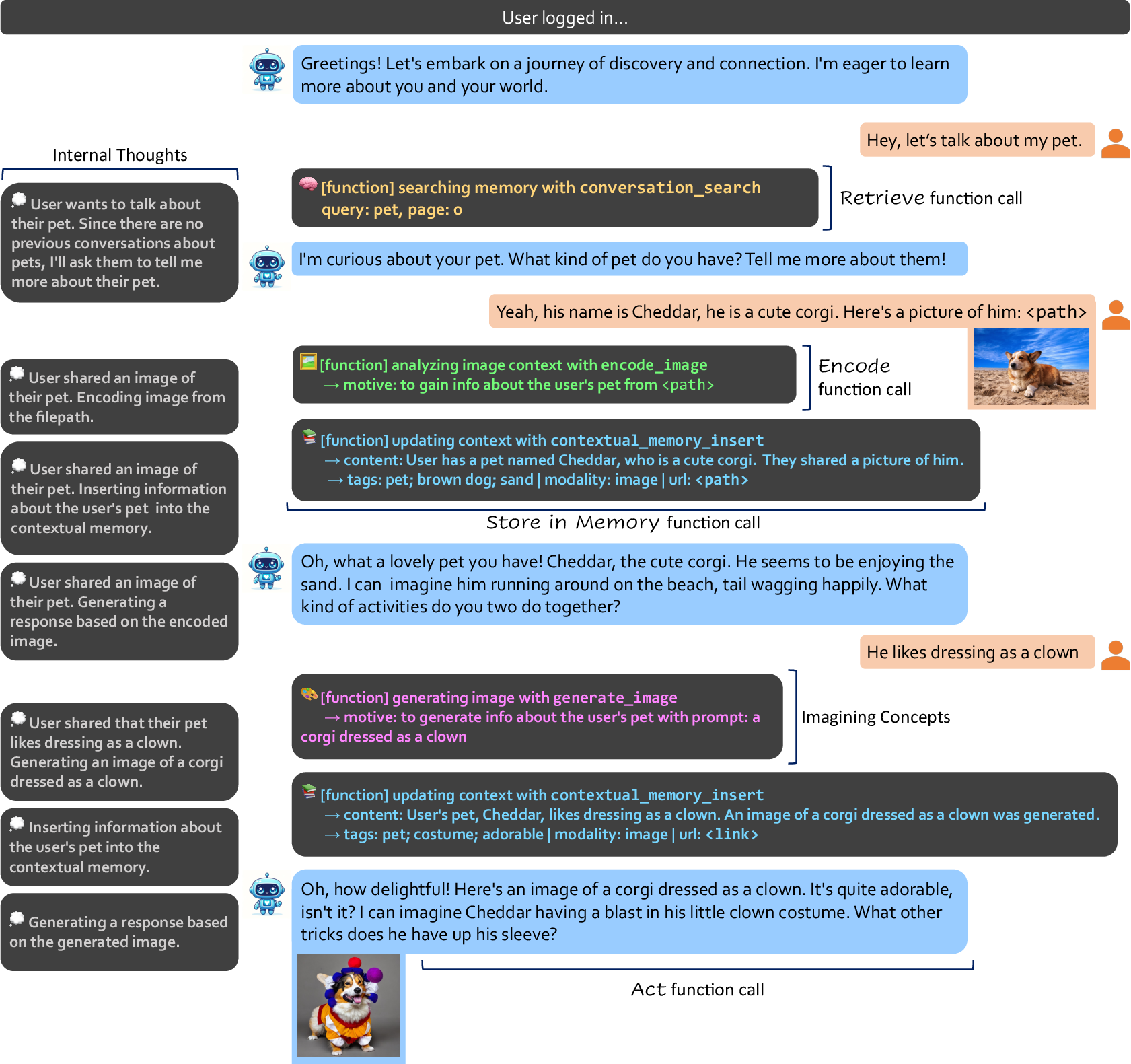
Figure 1: Snapshot of a conversation between a user and AUGUSTUS about the user's pet. Our system calls different functions corresponding to the four stages of operation to engage with the user while thinking internally.
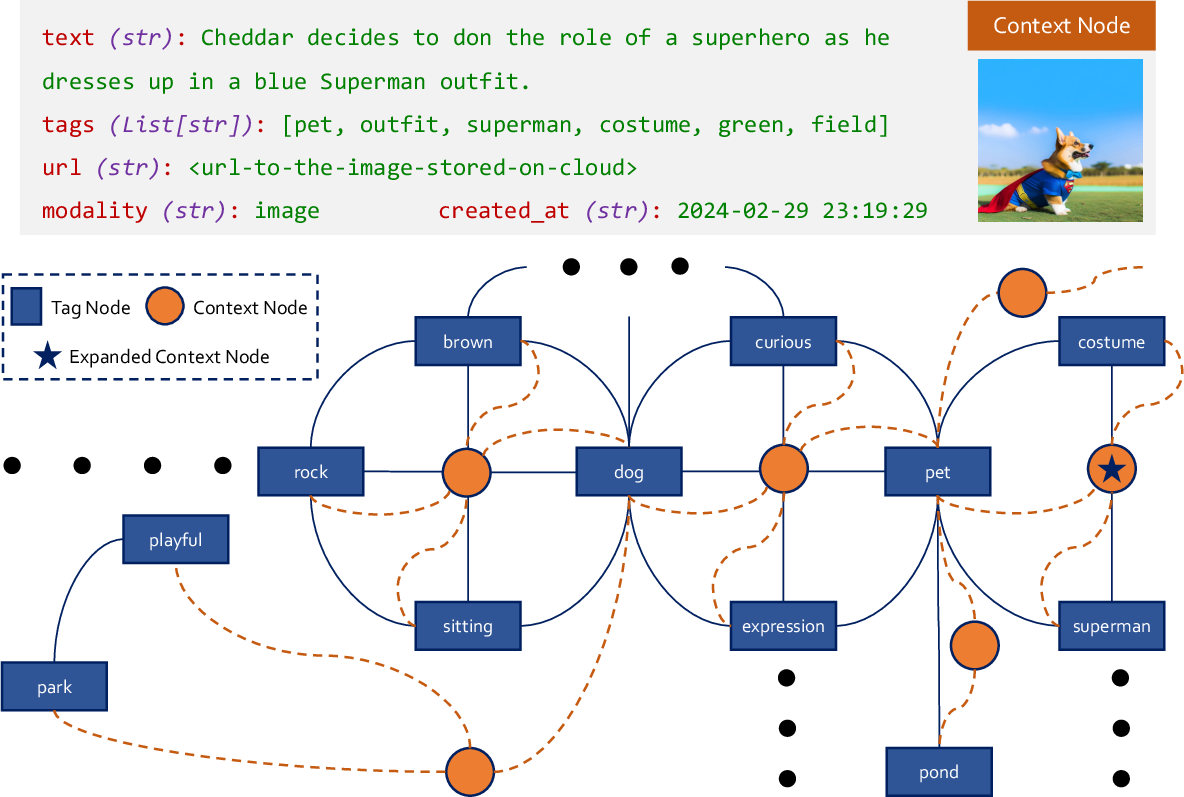
Figure 2: Organization of Information in the Contextual Memory. AUGUSTUS conceptualizes information into semantic tags connected with the corresponding context node, creating associations among the tags.
Memory Retrieval and Personalization
The retrieval phase employs the Contextual-Personalized (CoPe) search algorithm, designed for concept-driven retrieval from the hierarchical contextual memory. By using a clustering mechanism over semantic tags, CoPe reduces the search space and enhances retrieval efficiency, exhibiting a 3.5× faster performance than traditional RAG setups while maintaining high accuracy in large-scale tasks like ImageNet classification.
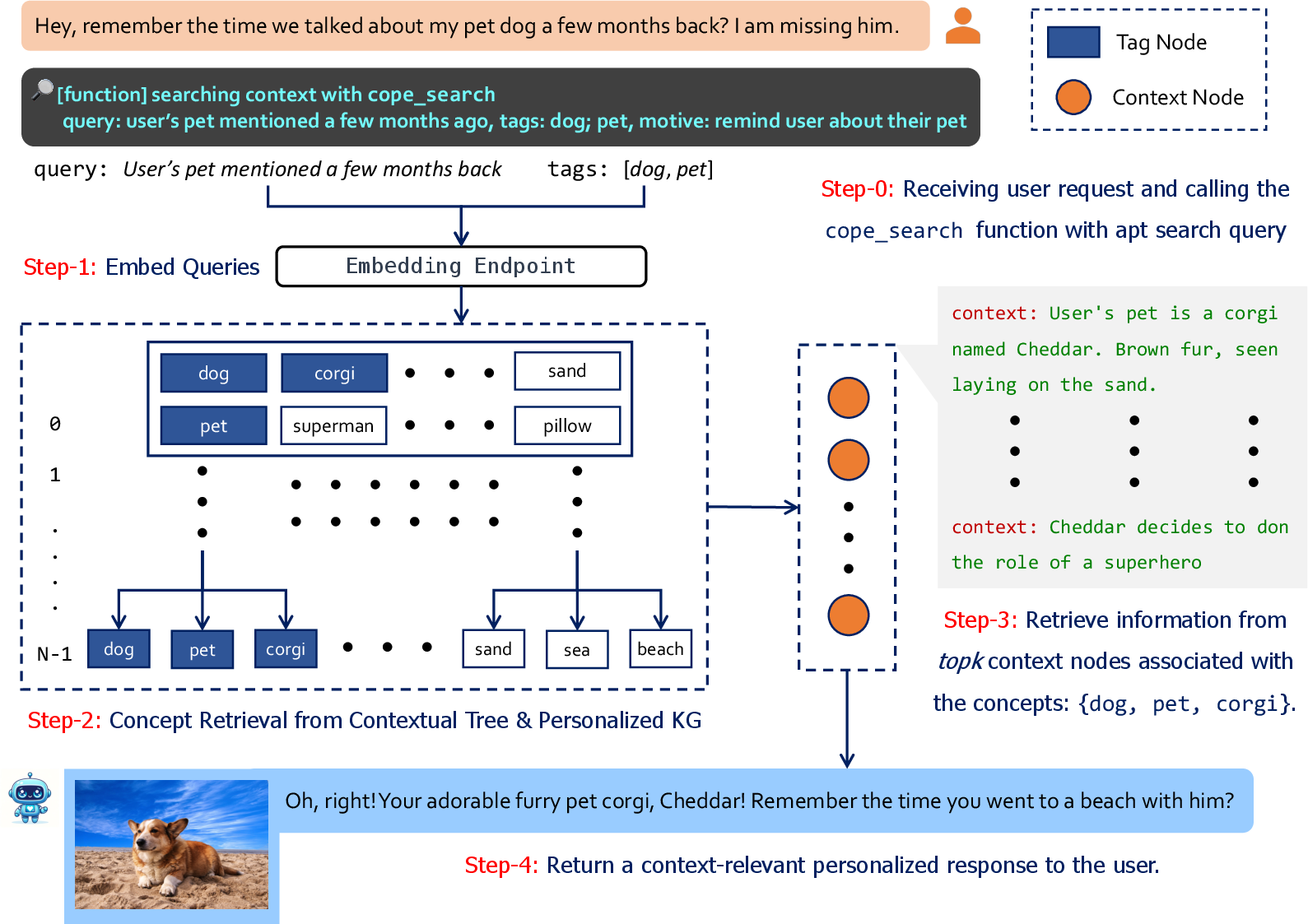
Figure 3: Retrieval with CoPe Search. Given a query, AUGUSTUS retrieves relevant concept (pet; dog; corgi), followed by concept-driven context retrieval to send a personalized response to the user.
Additionally, AUGUSTUS's personalized response capability underscores its utility in ongoing user interactions, tailoring outputs based on retrieved contextual knowledge.

Figure 4: Personalized response to the user. AUGUSTUS retrieves relevant information from the contextual memory by calling the cope_search function to generate an image aligned with the information about dogs from prior user conversations.
Experimental Evaluation
The empirical evaluation positions AUGUSTUS favorably against existing benchmarks. In ImageNet classification, AUGUSTUS delivered competitive top-1 accuracy, comparable to state-of-the-art vision models, demonstrating robustness in concept retrieval. Further tests on the Multi-Session Chat (MSC) benchmark evidenced AUGUSTUS's superior performance in sustaining conversation consistency and user context retention, as quantified by ROUGE-L scoring metrics.
Conclusion
AUGUSTUS marks a significant evolution in multimodal agent systems by aligning artificial memory with cognitive neuroscience principles. Its framework, emphasizing memory efficiency and retrieval augmentation, reflects a promising direction for AI systems requiring complex multimodal understanding and user-specific personalization. Future research could focus on expanding AUGUSTUS's cognitive capabilities, embedding learning features for system self-improvement, and further diversifying modality support to better emulate comprehensive human cognition systems.