Humanoid Goalkeeper: Learning from Position Conditioned Task-Motion Constraints
Abstract: We present a reinforcement learning framework for autonomous goalkeeping with humanoid robots in real-world scenarios. While prior work has demonstrated similar capabilities on quadrupedal platforms, humanoid goalkeeping introduces two critical challenges: (1) generating natural, human-like whole-body motions, and (2) covering a wider guarding range with an equivalent response time. Unlike existing approaches that rely on separate teleoperation or fixed motion tracking for whole-body control, our method learns a single end-to-end RL policy, enabling fully autonomous, highly dynamic, and human-like robot-object interactions. To achieve this, we integrate multiple human motion priors conditioned on perceptual inputs into the RL training via an adversarial scheme. We demonstrate the effectiveness of our method through real-world experiments, where the humanoid robot successfully performs agile, autonomous, and naturalistic interceptions of fast-moving balls. In addition to goalkeeping, we demonstrate the generalization of our approach through tasks such as ball escaping and grabbing. Our work presents a practical and scalable solution for enabling highly dynamic interactions between robots and moving objects, advancing the field toward more adaptive and lifelike robotic behaviors.





Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Humanoid Goalkeeper: A Simple Explanation
What is this paper about?
This paper shows how a humanoid robot can act like a soccer goalkeeper. It learns to watch a fast-moving ball and move its whole body—hands, legs, and torso—to block the ball in real time. The goal is to make the robot both effective (it actually stops the ball) and natural-looking (it moves like a person would).
What questions does the paper try to answer?
The researchers focus on two big questions:
- How can a humanoid robot learn quick, full-body, human-like motions to block balls coming from different directions and heights?
- How can the robot cover a wide range of the goal fast enough, while staying balanced and ready for the next play?
How did they do it? (Methods in plain language)
Think of training the robot like teaching a beginner goalie using three tools: experience, examples, and a game plan.
- Reinforcement Learning (learning by doing): The robot practices in a simulator (like a realistic video game). Each time it blocks a ball, it gets a “reward.” Over many tries, it learns which movements work best.
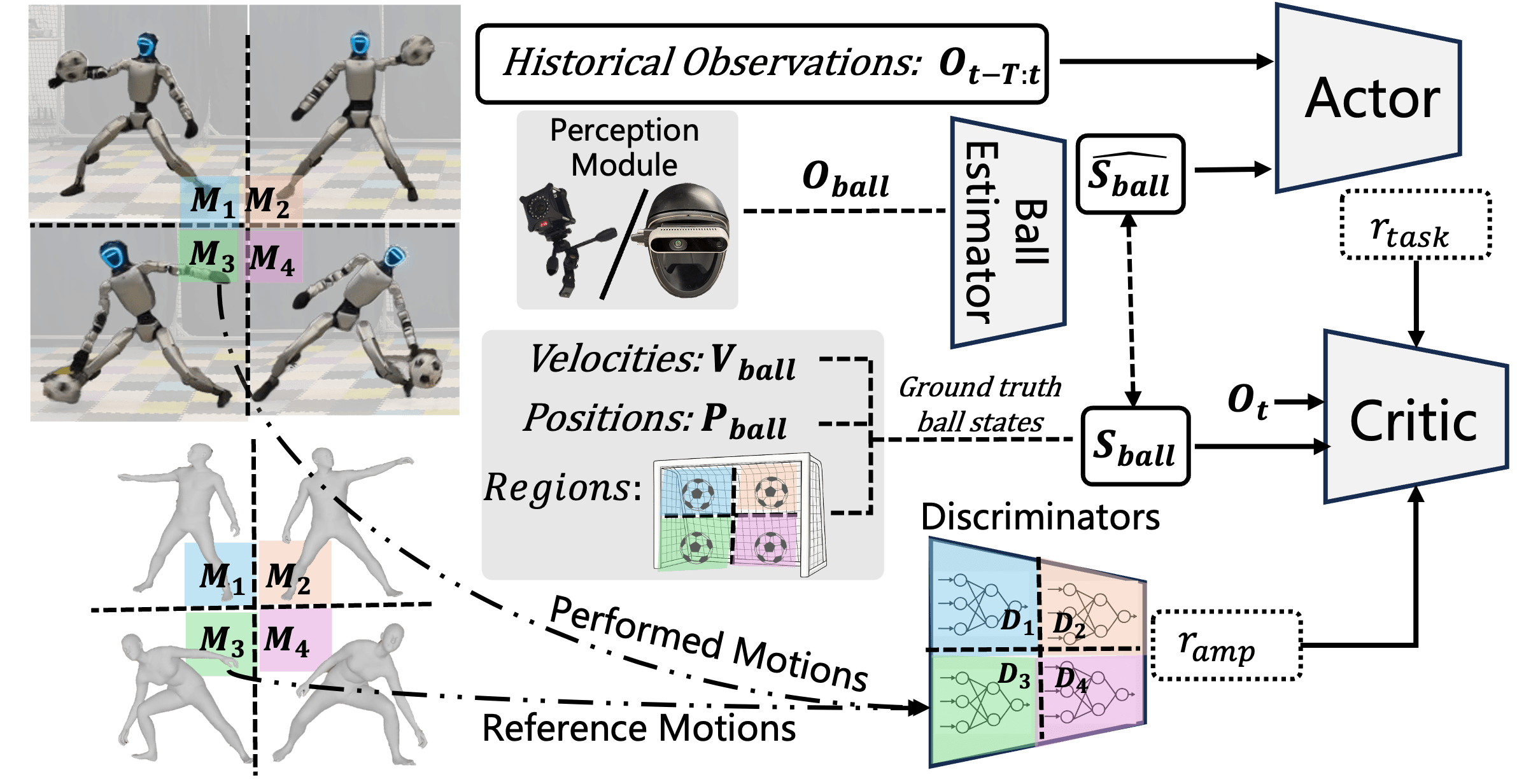
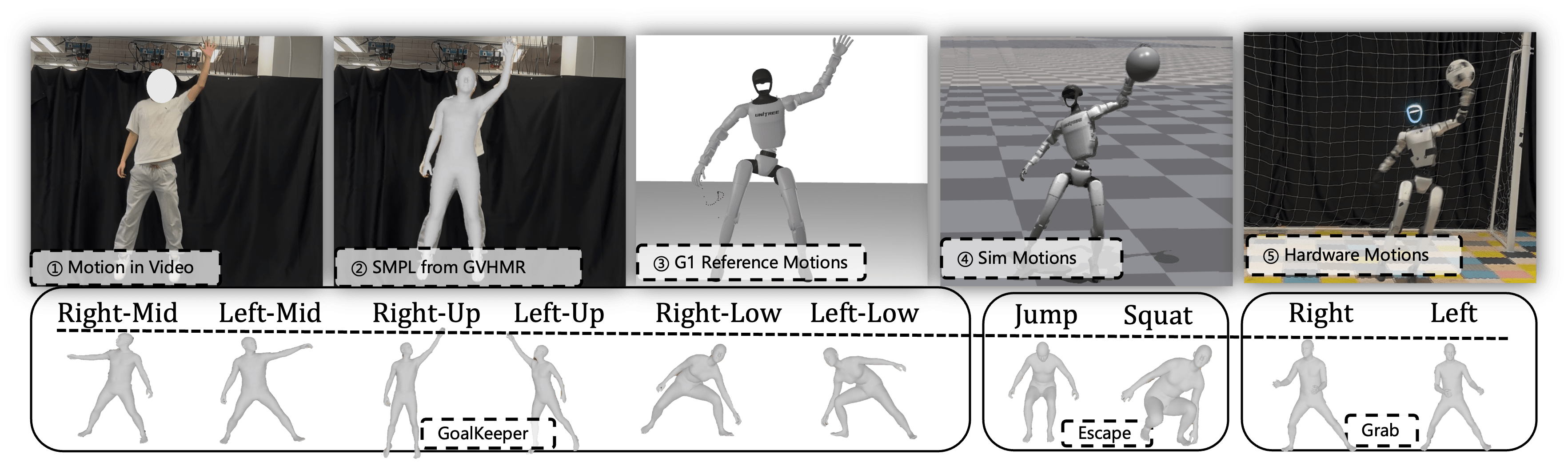
- Motion priors (learning from examples): The team recorded videos of a human doing goalie moves, turned that into motion data, and “retargeted” it to the robot’s joints. This gives the robot a library of human-like moves to imitate.
- A “judge” for natural movement (adversarial training): A special AI model acts like a judge. It looks at the robot’s moves and scores how “human-like” they are compared to the human motion library. The robot tries to improve to please the judge while still blocking the ball.
- Position-conditioned strategy (using a smart game plan): The goal area is split into regions (left low, left mid, left high, right low, etc.). The robot learns different styles of motion depending on where the ball is headed—like using the left hand for left-side balls or jumping for high balls. This helps it pick the right move quickly.
- Seeing the ball (perception): The robot needs to know where the ball is. They used two ways:
- Motion capture (MoCap): external sensors track the ball and the robot precisely.
- Head camera: an onboard depth camera with an infrared filter detects a reflective ball.
- To make sure the robot works in the real world, they add noise and occasional “missing data” during training, just like what happens with real cameras (ball goes out of view, gets occluded, etc.).
- Staying steady after the save: Episodes last longer than the ball’s flight so the robot also learns to recover balance and return to a neutral posture. Sometimes training even restarts from a mid-motion pose so it can play continuously.
What did they find, and why does it matter?
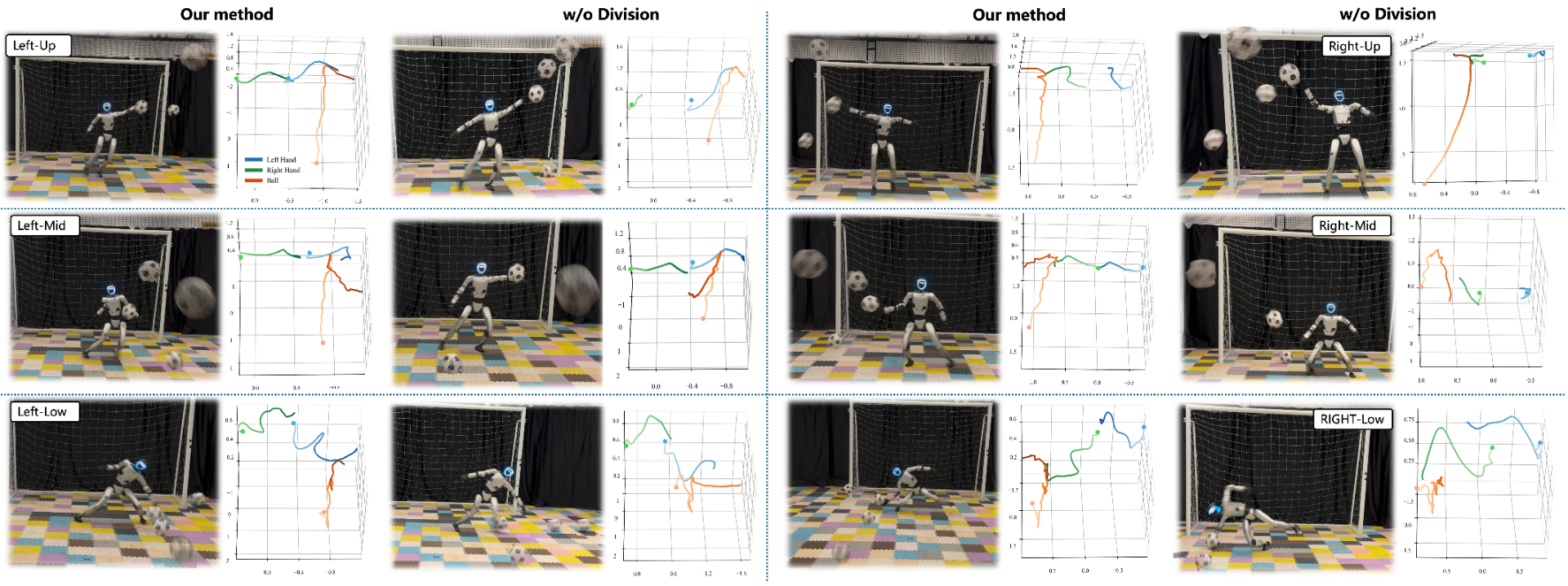
- Strong performance in simulation: In their main setup, the robot blocked about 81% of shots in simulation over a large goal area and a range of speeds. It moved in ways that consistently matched human-like styles for different regions.
- Real-world results: On a real humanoid robot (Unitree G1), the method achieved 21 successful saves out of 30 using motion capture, and 14/30 using only the onboard camera (the camera had a narrow field of view, so the ball often disappeared close to the robot).
- Better than simpler baselines: Versions without the region-based “game plan” or without the human-motion judge either didn’t save as well or moved less naturally. Combining task success and human-like style—both conditioned on where the ball is going—worked best overall.
- Whole-body agility: The robot didn’t just block with its hands—it stepped sideways, squatted, or jumped when needed, like a real goalkeeper covering more of the goal.
- Keeps playing: The robot can do consecutive saves without resetting to a default pose, making it closer to real match behavior.
- Generalizes to other tasks: Using the same approach, the robot learned related skills:
- Escaping a ball (squat for low balls, jump for high balls).
- Grabbing a moving ball with a soft bag (harder in real life due to the floppy bag).
Why it matters: Humanoid robots usually struggle with fast, full-body actions that must look natural and be safe. This work shows a practical way to combine goal-focused learning and human-like motion, moving closer to athletic, lifelike robots that can interact with fast-moving objects.
What could this mean for the future?
- Smarter athletic robots: The same ideas could help robots play other sports-like tasks (table tennis, volleyball, catching) or handle fast-moving objects safely in factories or homes.
- Better training recipes: Mixing “learn by doing” with “learn from humans,” and conditioning both on the situation (like target regions), leads to more reliable and natural results.
- Next steps:
- Add high-level planning so the robot repositions between shots, like a real keeper.
- Improve vision so it doesn’t depend on motion capture and can track balls longer with onboard cameras (wider field of view, active head movement).
- Teach the robot to catch and hold the ball, not just deflect it.
In short, this paper takes a big step toward robots that move more like us and react in real time to fast, unpredictable events—just like a real goalkeeper.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise list of unresolved issues that are missing, uncertain, or left unexplored in the paper—each framed to be actionable for future research.
- Perception generalization and robustness:
- The onboard perception relies on a high-reflectivity ball and IR filtering; it is unclear how the system performs with standard soccer balls, varying textures/colors, cluttered backgrounds, outdoor lighting, and non-IR conditions.
- Field-of-view limitations are only partially addressed by training-time dropouts; the paper does not model or compensate for real camera latency, exposure changes, motion blur, or calibration drift—nor does it quantify their impact.
- The ball estimator’s architecture, training details, and quantitative performance (e.g., position RMSE, landing-region classification accuracy, latency) are not reported, making it difficult to assess or improve estimator reliability.
- No active sensing or head/torso reorientation strategy is implemented or evaluated to maintain ball visibility under FoV constraints; the benefits and costs (e.g., reaction time vs. visual tracking stability) are unexplored.
- Sensor fusion between MoCap and camera (or inertial data) is absent; open question: can multi-modal fusion improve tracking continuity and reduce performance drops in near-field occlusion?
- Task modeling and realism:
- Ball trajectories are simplified; the simulator and policy do not account for aerodynamic effects (drag, lift, spin), ground bounces, deflections, rebounds off goalposts, or multi-shot sequences—all critical in realistic goalkeeping.
- The policy’s response to non-goal-directed balls is acknowledged as naive; a target-intent classifier or decision layer (e.g., “ignore,” “track,” “reposition”) is missing and unquantified.
- Evaluation success focuses on blocking before the goal line; rebound control (direction, speed), safe deflection, and catching are not measured—important for match-level performance.
- Region conditioning and policy structure:
- Region segmentation is statically predefined (six regions) and not learned; sensitivity to boundary design, number of regions, and continuous conditioning (e.g., via learned latent embeddings) remains unexplored.
- Hand selection is hard-coded by region (left-hand for left region, etc.); the benefits of dynamic hand selection, two-handed saves, or using other body parts (legs, torso) for edge cases are not investigated.
- The actor does not directly use ball velocity (only the critic does); the impact of providing velocity estimates (or a ballistic model) to the actor on reaction speed and accuracy is not ablated.
- Motion priors and AMP formulation:
- The motion discriminators use joint position transitions only; they omit contact states, foot placements, end-effector-to-ball geometry, and base dynamics—potentially limiting motion realism under interaction.
- The “soft AMP” variant (Gaussian sampling around executed transitions and max-reward selection) lacks theoretical analysis and empirical ablation: sensitivity to sample count N, sampling variance, stability, and convergence are unclear.
- The reference motion dataset (size, diversity, coverage across regions/speeds/heights) and retargeting fidelity to Unitree G1 are not quantified; bias and gaps in the motion library may affect behavior in unrepresented scenarios.
- The approach does not explore conditioning AMP on richer task features (e.g., predicted time-to-contact, vertical speed) or learning a shared discriminator with continuous task-conditioned embeddings.
- Reward shaping and training details:
- Key reward hyperparameters (e.g., d_th, d_keep, σ_keep) are not systematically ablated; their sensitivity and optimal ranges remain unknown.
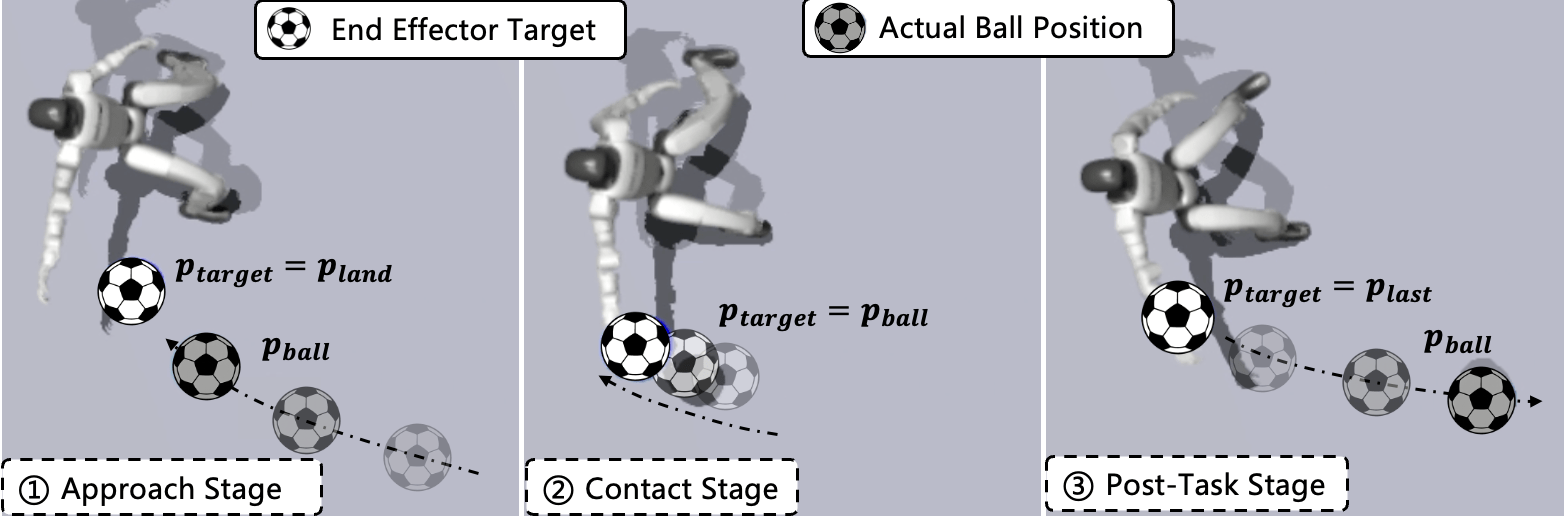
- Post-task stability is enforced with a 3-second episode and generic terms; no explicit constraints (e.g., capture point, foot placement targets) are validated for preventing falls after extreme maneuvers.
- The policy’s control frequency, observation horizon T, action latency, and hardware loop timings are not reported; reaction-time budgets and end-to-end delay analysis are missing.
- Sim-to-real transfer:
- Sim-to-real randomization is limited to 5 cm position noise and late-flight dropouts; unmodeled real-world factors (timing jitter, calibration shifts, lighting, floor friction variations, contact compliance) are not included.
- Foot-ground interactions (slip, different surfaces, compliance) are not characterized; their influence on lateral jumps/squats and upper-region saves is not assessed.
- Energy use, actuator saturation/thermal limits, and wear under repeated high-dynamic motions are not measured—important for sustained deployment.
- Evaluation scope and methodology:
- Hardware evaluation uses only five trials per region (30 total per modality), limiting statistical confidence; power analyses, confidence intervals, and test-retest reliability are absent.
- Upper-region failures are observed but not analyzed; root-cause diagnostics (e.g., timing, reachability, kinematic limits, estimator errors) are missing.
- Motion quality is assessed via DTW pose error; subjective human-likeness studies, contact correctness (e.g., avoiding unsafe arm hyperextension), and foot placement accuracy are not evaluated.
- Generalization tasks (jump/squat escape, bag-based grabbing) are under-modeled (e.g., deformable bag not simulated); adding deformable object models, tactile sensing, or gripper control is needed to improve grabbing reliability.
- Planning and match-level behavior:
- A high-level planner is absent; repositioning between shots, situational awareness (goalposts, teammates, opponents), and continuous match-level strategies are not implemented.
- No global state estimation (goal geometry, robot-to-goal alignment) is used—restricting anticipatory positioning and wide-area coverage under variable shot origins.
- Safety and compliance:
- Safety constraints are not formalized (e.g., maximum joint torque/velocity under saves, collision handling, fall detection/avoidance strategies); risk assessment for high-speed impacts is missing.
- Post-impact behaviors (fallback strategies, recovery plans after near-misses or collisions) are not specified.
- Reproducibility and transferability:
- The approach is validated only on Unitree G1; portability to other humanoids, varying morphologies, and different control stacks (torque vs. position control) is untested.
- Detailed simulator configurations (physics parameters for ball and robot, contact models) and calibration procedures for MoCap/camera are not fully documented—hindering exact replication.
Practical Applications
Immediate Applications
Below are applications that can be deployed now using the paper’s methods, tools, and demonstrated hardware setups.
- Humanoid goalkeeper training system for sports tech and entertainment
- Sector: sports technology, entertainment
- Application: Deploy the end-to-end RL policy on commercial humanoids (e.g., Unitree G1) as an autonomous goalkeeper in training sessions, fan engagement experiences, or robotics exhibitions. Supports wide guarding range and human-like motions (lateral shifts, squats, jumps) with sim-to-real perception via MoCap or onboard IR-camera.
- Tools/products: “Humanoid Goalkeeper” module packaged with the open-source policy, region-conditioned AMP discriminators, motion-retargeting from human videos (GVHMR), and a turnkey perception stack (MoCap or RealSense D435i + IR filter).
- Assumptions/dependencies: Reflective ball or MoCap markers for reliable tracking; safe field setup; hardware with sufficient actuation bandwidth; trained motion priors aligned with venue geometry; compliance with venue safety protocols.
- Dynamic interception demos and interactive exhibits
- Sector: museums, theme parks, media
- Application: Use the human-like motion priors and AMP-based policy to stage live demos where humanoids intercept flying balls or perform “escape” motions (jump/squat) in reaction to thrown objects, with region-specific behavior ensuring engaging, lifelike performances.
- Tools/products: Pre-curated motion library per region; IsaacGym-trained PPO policy with post-task stability; trajectory visualizations for audiences.
- Assumptions/dependencies: Controlled throwing speed/range; IR or MoCap-based ball tracking; safety fencing and supervision.
- Robotics education and research benchmarking
- Sector: academia, education
- Application: Adopt the project’s open-source code and workflows as a hands-on benchmark for embodied intelligence: end-to-end RL with position-conditioned motion priors, sim-to-real perception alignment, and continuous task execution without resets.
- Tools/products: Curriculum modules on AMP, motion curation (GVHMR → robot retargeting), position-conditioned reward design, and noise-injected training for robust perception.
- Assumptions/dependencies: Access to simulation (IsaacGym), modest compute for PPO training, humanoid hardware for lab demos or low-cost simulators for coursework.
- Industrial safety demos for proactive hazard avoidance
- Sector: manufacturing, warehousing
- Application: Prototype a humanoid “soft-interceptor” that uses the escape skill (jump/squat) and lateral repositioning to avoid or deflect benign moving objects (e.g., empty boxes, packaging) entering its workspace, demonstrating whole-body reactive safety behaviors.
- Tools/products: Position-conditioned policies for escape; region estimator and ball estimator adapted to object-class/trajectory; safety envelope monitoring.
- Assumptions/dependencies: Object trajectories roughly ballistic or predictable; sensing tuned to object material/appearance (may require fiducials or IR reflectors); strict safety gating and force-limited contacts.
- Vision-to-robot motion retargeting service
- Sector: animation, robotics software
- Application: Provide a pipeline that turns recorded human motions (from standard RGB videos) into deployable region-specific robot behaviors via GVHMR + retargeting, then integrate in AMP discriminators to shape style-consistent robot actions for new dynamic tasks.
- Tools/products: Motion curation service, region-conditioned AMP discriminator training, soft-AMP variant that samples Gaussian perturbations to avoid over-constraining task accuracy.
- Assumptions/dependencies: Sufficiently clean source videos; calibration between human and robot kinematics; domain-appropriate region definitions.
- Onboard perception baseline for dynamic object interaction
- Sector: robotics platforms, embedded systems
- Application: Use the provided RealSense + IR filter pipeline and the noise-robust estimator (position + region classification) to enable minimal-infrastructure dynamic interaction tasks—e.g., intercepting balls in the upper regions where FoV remains adequate.
- Tools/products: Estimator training code (MSE + cross-entropy), dropout and noise injection recipes, deployment-ready inference stack.
- Assumptions/dependencies: IR-reflective targets; known FoV limitations (short observable window in lower regions); localized coordinate frames; careful camera mounting and calibration.
- Continuous trial operation without manual resets
- Sector: sports robotics, demo operations
- Application: Operate robots across sequential interceptions using the paper’s post-task stability rewards and environment reset strategy (starting new trials from ongoing joint states), reducing downtime and enabling match-like sequences in demos.
- Tools/products: Reward shaping for balance recovery; environment reset-from-ongoing-states workflow; safety monitoring for fatigue and overheating.
- Assumptions/dependencies: Robust stability margins; reliable perception across trials; human-curated schedules to avoid excessive actuator wear.
Long-Term Applications
The following applications require further research, scaling, or engineering beyond the current system’s capabilities.
- Match-level humanoid goalkeeping and multi-agent soccer
- Sector: sports robotics
- Application: Full match integration with high-level planning (repositioning, anticipation, team coordination) and global perception (field awareness) to achieve professional-level autonomous goalkeeping.
- Tools/products: Strategic planner atop the RL controller; predictive multi-object tracking; game-state understanding; role assignment for multi-robot teams.
- Assumptions/dependencies: High-fidelity global sensing; communication latency constraints; robust locomotion across turf; regulatory approval for competitive settings.
- General-purpose dynamic object interception in workplaces
- Sector: manufacturing, logistics, construction
- Application: Proactive interception or redirection of unpredictable moving objects (tools, packages, small parts), reducing damage or injury, and assisting humans with rapid-response safety actions.
- Tools/products: Multi-modal sensing (vision, radar, depth), trajectory prediction under non-ballistic dynamics, compliance-aware contact strategies, certification-ready safety frameworks.
- Assumptions/dependencies: Reliable environment sensing in clutter; standardized object markers or robust markerless detection; legal liability frameworks and functional safety certification.
- Consumer humanoid assistance: catching, shielding, and avoiding
- Sector: consumer robotics, smart home
- Application: Household robots capable of catching dropped items, avoiding thrown toys, shielding fragile objects, or autonomously moving out of harm’s way using human-like escape motions.
- Tools/products: Domestic-safe object detection, trajectory estimation for varied items, lightweight manipulators with soft catching mechanisms; energy-aware planning for repeated actions.
- Assumptions/dependencies: Affordable hardware; robust perception in unstructured lighting; soft-grasp and impact attenuation designs; user safety guarantees.
- Healthcare and eldercare protective responses
- Sector: healthcare, eldercare
- Application: Robots that react quickly to moving hazards (e.g., rolling walkers, falling objects), execute safe escape or shielding maneuvers, and assist therapists in training reactive motor behaviors.
- Tools/products: Medical-grade safety envelopes; compliant actuation; clinician-configurable task regions; standardized therapeutic protocols.
- Assumptions/dependencies: Strong safety and ethical oversight; clinical validation; integration with facility monitoring systems.
- Sports training analytics and adaptive skill learning
- Sector: sports analytics, coaching tech
- Application: Training tools where humanoids adapt their motion style to athletes’ patterns (via AMP), provide repeatable dynamic drills, and generate analytics on interception timing, coverage, and style similarity.
- Tools/products: Motion style discriminators tuned to athlete data; automated drill generation; analytics dashboards; video-to-robot personalization pipelines.
- Assumptions/dependencies: Athlete consent for motion capture/video; personalization data pipelines; robustness across varied ball types and speeds.
- Active sensing and perception-only deployments (no MoCap)
- Sector: robotics platforms, embedded vision
- Application: Fully onboard sensing with active camera control (gaze, torso/head motion) to maximize FoV and observation window; robust detection under occlusion and clutter for diverse objects beyond reflective balls.
- Tools/products: Active perception policies; sensor fusion (IMU, stereo, event cameras); model-based trajectory filters; domain-adaptive noise injection strategies.
- Assumptions/dependencies: Computational budgets; mechanically controllable sensor mounts; advanced calibration and online adaptation.
- Skill libraries and workflow standardization for position-conditioned motion learning
- Sector: robotics software, toolchains
- Application: Standard libraries for region-conditioned task-motion constraints, AMP discriminators per region, and soft-AMP reward variants to enable rapid development of dynamic interaction tasks (e.g., table tennis, badminton, catching).
- Tools/products: Region-definition APIs; motion curation templates; reward shaping kits; evaluation metrics suites (success, smoothness, DTW-based pose resemblance).
- Assumptions/dependencies: Cross-robot kinematic retargeting standards; shared datasets; interoperable simulators; community benchmarks.
- Regulation and safety policy for public humanoid deployments
- Sector: policy, standards
- Application: Develop guidelines for deploying humanoids in public venues that perform dynamic interception and escape actions, covering sensing modalities (IR markers, cameras), impact safety, privacy around video-derived motion priors, and operator training.
- Tools/products: Certification procedures; safety test protocols; disclosure standards for motion-data usage; incident response playbooks.
- Assumptions/dependencies: Multi-stakeholder consensus; alignment with existing robotic safety standards (e.g., ISO 13482); legal frameworks for liability and data governance.
- Dexterous catching and manipulation of deformable containers
- Sector: robotics manipulation, retail logistics
- Application: Extend from “punching away” to reliable catching and bagging, including deformable containers (soft bags) and diverse objects, with learned contact-rich strategies and real-time grip adaptation.
- Tools/products: Tactile sensing; compliance control; deformable-object simulation; domain-randomized training for varied bags and item shapes.
- Assumptions/dependencies: Accurate physics for deformables; tactile and force feedback; robust hand hardware; extended motion priors encompassing grasping styles.
Glossary
- Adversarial motion prior (AMP): An imitation-learning approach that uses a discriminator to shape policy behavior toward a distribution of expert motions without strict time alignment. Example: "In contrast, adversarial motion priors (AMP) \cite{peng2021amp} offer an alternative approach by integrating expert data without enforcing strict temporal alignment."
- Ball estimator: A learned module that predicts the ball’s future position and landing region from partial/noisy observations to aid control and conditioning. Example: "We integrate a ball estimator into the training loop, which is effective in identifying regions (for task and motion conditions) and accurately predicting ball positions and moving trajectories (\cref{fig:method}), fully utilizing historical observations."
- Critic network: The value function component in actor–critic RL that estimates expected returns for states, guiding policy updates. Example: "Observation spaces for the actor and critic network."
- Cross-Entropy Loss: A classification loss measuring the discrepancy between predicted class probabilities and true labels. Example: "the region estimator is trained using Cross-Entropy Loss to classify the correct region where the ball is likely to land."
- Discriminator: In adversarial imitation, a network trained to distinguish expert motion transitions from policy-generated ones, providing a guidance signal. Example: "associating each region with a dedicated reference motion slot and a corresponding discriminator ."
- Dynamic Time Warping (DTW): A sequence-alignment technique that compares time series of different speeds by optimally warping their temporal axes. Example: "pose error to expert motion (processed through DTW \cite{sakoe2003dynamic}) from the ball target region ."
- End-effector: The robot’s task-space contact/manipulation point (here, the hands) used to intercept or interact with objects. Example: "Then we define the following smooth, distance-based reward using a sigmoid function to encourage the end-effector (hand) to reach the target position:"
- End-to-end policy: A control policy learned directly from observations to actions without modular decomposition into perception/planning/control stages. Example: "our method learns a single end-to-end RL policy, enabling fully autonomous, highly dynamic, and human-like robot-object interactions."
- Field of View (FoV): The angular extent of the observable world seen at any moment by the sensor/camera. Example: "The primary limitation stems from the narrow camera field of view (FoV), which reduces the observable time window of the ball."
- Floating base: A robot morphology where the base is not fixed to the ground and can move freely (e.g., legged robots), complicating control. Example: "Dynamic Object Interactions with floating base."
- GVHMR: A video-based human motion recovery pipeline used to extract reference motions from RGB videos for imitation. Example: "We first leverage existing pipelines (GVHMR \cite{shen2024world}) that extract humanoid motions from self-recorded RGB videos"
- IsaacGym: A GPU-accelerated physics simulation environment for large-scale RL training of robots. Example: "implemented in the IsaacGym simulator \cite{rudin2022learning}."
- Mean Squared Error (MSE): A regression loss computing the average squared difference between predicted and true values. Example: "The position estimator is trained with Mean Squared Error (MSE) loss to minimize the prediction error of the ball's position"
- Motion capture (MoCap): A system that tracks the 3D positions and orientations of objects/markers to provide precise pose data. Example: "a motion capture (MoCap) system using markers placed on the robotâs head and the ball,"
- Motion primitives: Predefined low-level movement patterns or skills that can be sequenced or selected for complex behaviors. Example: "relying on fixed motion primitives \cite{Ze2025TWISTTW}"
- Motion retargeting: Mapping motion data from a source (e.g., human) to a robot with different morphology/constraints. Example: "we retarget the extracted motions to the Unitree G1 robot"
- Multimodal sensing: Using multiple sensing modalities (e.g., MoCap and depth camera) to improve perception robustness. Example: "we incorporate perception noise, trajectory estimation, and multi-modal sensing into the training loop to close the sim-to-real gap."
- Position-conditioned: Conditioning objectives or priors on spatial context (e.g., ball landing region) to specialize behaviors. Example: "We include a position-conditioned adversarial motion prior (AMP) reward to impose motion constraints during training"
- Proprioceptive observations: Internal robot state measurements (e.g., joint positions/velocities, base IMU) used for control. Example: "combined with proprioceptive observations ."
- Proximal Policy Optimization (PPO): A policy-gradient RL algorithm that stabilizes updates via clipped objectives. Example: "We train policies using the standard PPO algorithm \cite{schulman2017proximal}"
- Sim-to-real gap: The performance discrepancy between simulation-trained policies and their behavior on real hardware. Example: "to close the sim-to-real gap."
- Teleoperation: Human-in-the-loop control of a robot, typically via remote input devices, rather than autonomous control. Example: "rely on separate teleoperation or fixed motion tracking for whole-body control"
- Trajectory estimation: Predicting the future path of a moving object (e.g., ball) from partial/noisy observations. Example: "we incorporate perception noise, trajectory estimation, and multi-modal sensing into the training loop"
- Unitree G1: A specific humanoid robot platform used as the target morphology for retargeted motions and deployment. Example: "retarget the extracted motions to the Unitree G1 robot"
- Whole-body control: Coordinated control of all robot joints/limbs to accomplish dynamic, full-body tasks. Example: "fixed motion tracking for whole-body control"
Collections
Sign up for free to add this paper to one or more collections.