- The paper demonstrates that hybrid AI feedback significantly increases revision rates compared to solely directive or metacognitive approaches.
- Methodologically, the study uses linguistic markers and automated coding to differentiate feedback types via imperatives, reflective prompts, and word counts.
- Implications suggest that controlled AI-generated feedback offers scalable, personalized instructional support without affecting overall resource quality or student confidence.
Introduction and Theoretical Context
This paper presents a semester-long randomized controlled trial (RCT) evaluating the impact of three distinct AI-generated feedback types—directive, metacognitive, and hybrid—on student engagement, confidence, and resource quality in a higher education programming and design course. The study is situated within the RiPPLE adaptive learning platform, leveraging its resource co-creation and peer evaluation workflow to systematically deliver feedback interventions at scale.
The research is motivated by the pedagogical tension between clarity and reflection in feedback design. Directive feedback provides explicit, actionable guidance, reducing cognitive load and accelerating error correction, particularly for novices. Metacognitive feedback, grounded in SRL and metacognitive theory, prompts learners to reflect, self-assess, and regulate their learning, fostering deeper transfer and autonomy but potentially increasing cognitive load and slowing immediate revision. Hybrid feedback aims to integrate the strengths of both approaches, balancing actionable guidance with reflective scaffolding.
Experimental Design and Implementation
The RiPPLE system operationalizes a cyclical process of resource creation, peer evaluation, and adaptive practice.
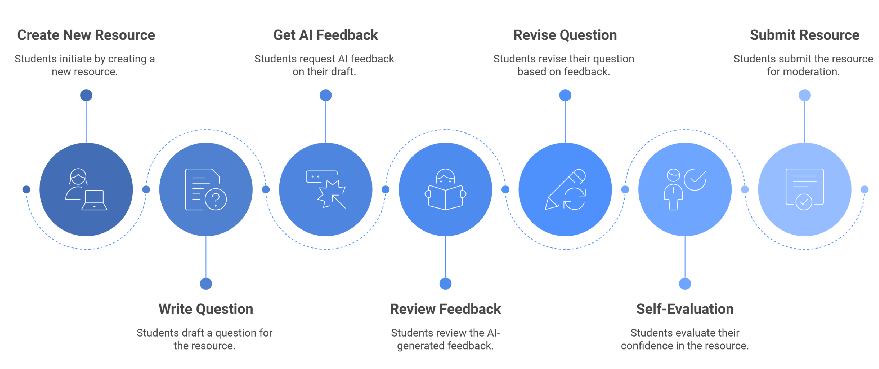
Figure 1: Student resource creation process in RiPPLE.
During the creation stage, students author educational resources (e.g., MCQs), which are then subjected to AI-generated feedback. The feedback is structured into three segments: Summary, Strengths, and Suggestions for Improvement, with only the Suggestions segment varying by condition. The MCQ creation interface and feedback delivery are standardized across all groups.
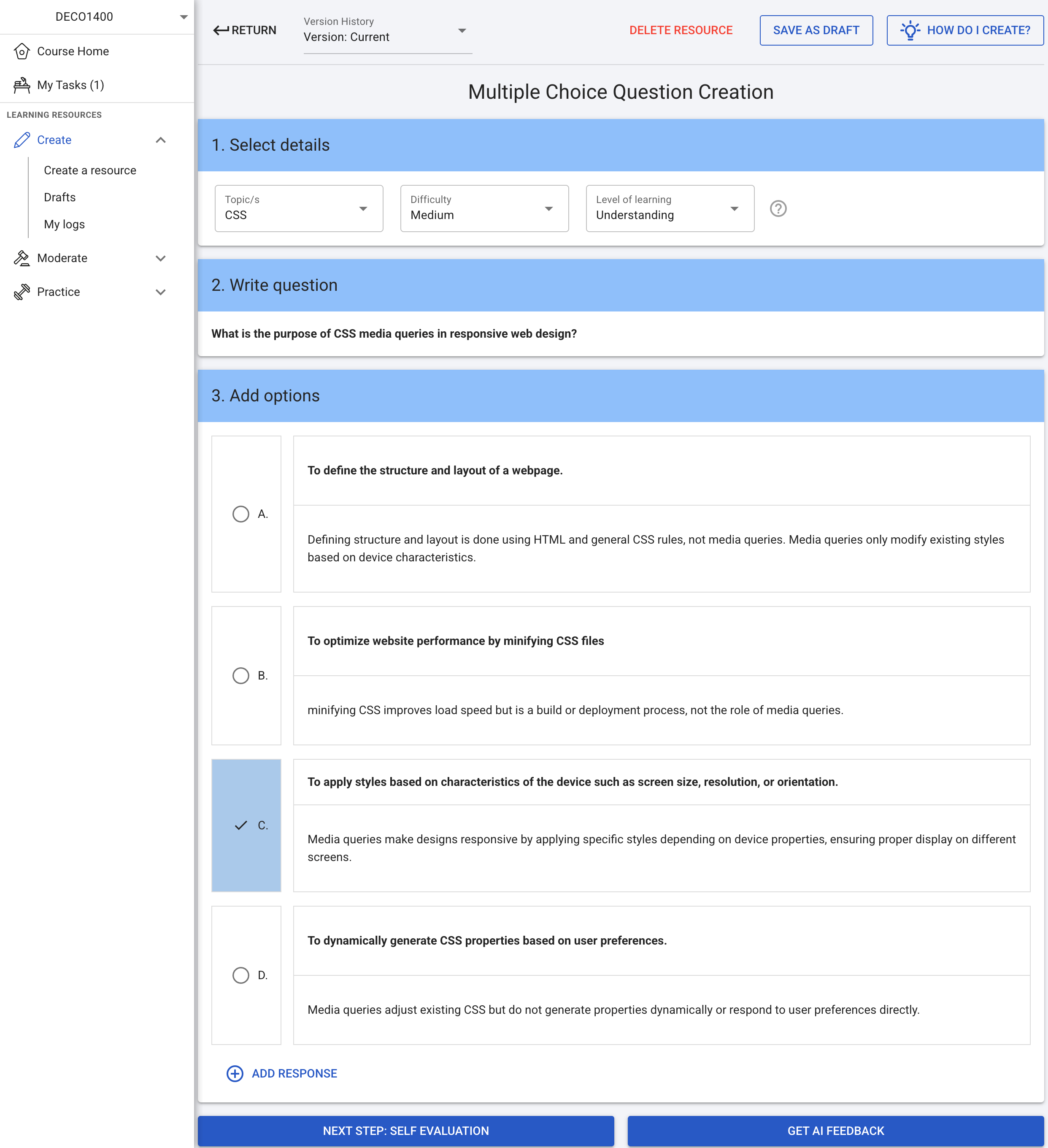
Figure 2: Creation stage on the RiPPLE platform showing the example MCQ used across all feedback conditions.
Participants (N=329) were randomly assigned to one of three feedback conditions. The directive group received prescriptive, error-correcting feedback; the metacognitive group received reflective prompts; and the hybrid group received a blend of both. All analyses focused on the Suggestions segment to ensure functional differentiation.
Linguistic and Structural Differentiation of Feedback Types
The study rigorously operationalizes linguistic markers to distinguish feedback types: imperatives (directive), reflective prompts (metacognitive), and word count (verbosity). Automated sentence-level coding and normalization per 100 words ensure robust comparison.
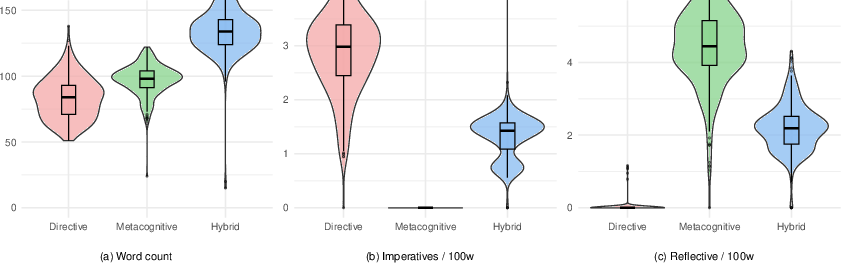
Figure 3: Distribution of linguistic features across feedback conditions.
Results show strong, statistically significant separation:
- Imperatives per 100 words: Directive (M=2.91), Hybrid (M=1.34), Metacognitive (M=0.00).
- Reflective prompts per 100 words: Metacognitive (M=4.45), Hybrid (M=2.20), Directive (M=0.01).
- Word count: Hybrid feedback is longest (M=134), followed by Metacognitive (M=97), and Directive (M=83).
These findings confirm that prompt engineering can reliably produce functionally distinct feedback aligned with pedagogical intent, supporting the use of LLMs for controlled feedback interventions.
Engagement Patterns and Revision Behavior
Engagement was measured via time-on-task, revision rates, and event-flow transitions. No significant differences in engagement time were observed across conditions, suggesting comparable cognitive investment. However, revision behavior diverged:
- Revision rates: Metacognitive (12.1%) < Directive (21.1%) < Hybrid (27.5%); Hybrid significantly exceeds Metacognitive (OR=4.3, p<.001).
- Event-flow analysis: Hybrid feedback induces denser editing loops and more returns to resource editing prior to self-assessment, indicating higher engagement with feedback.
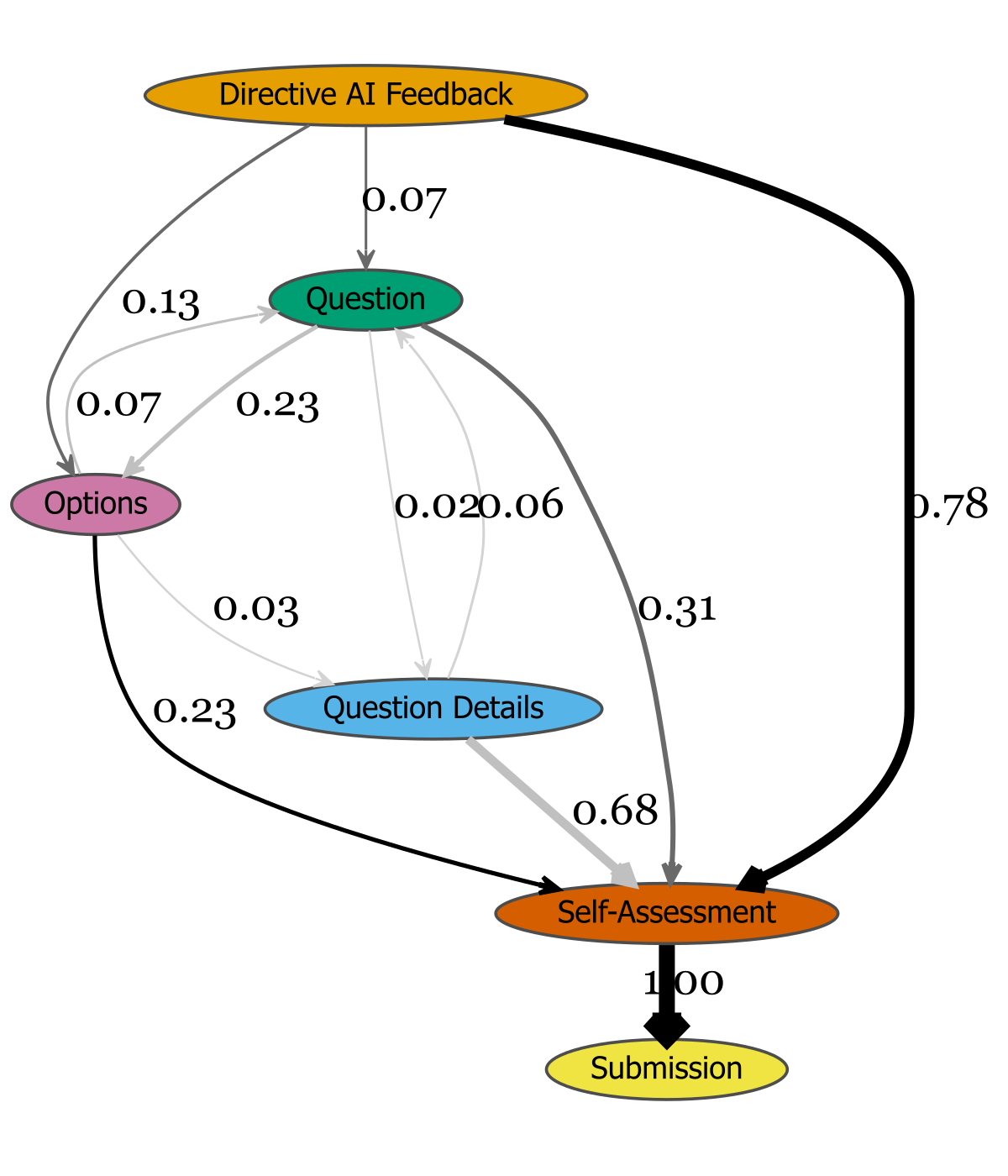
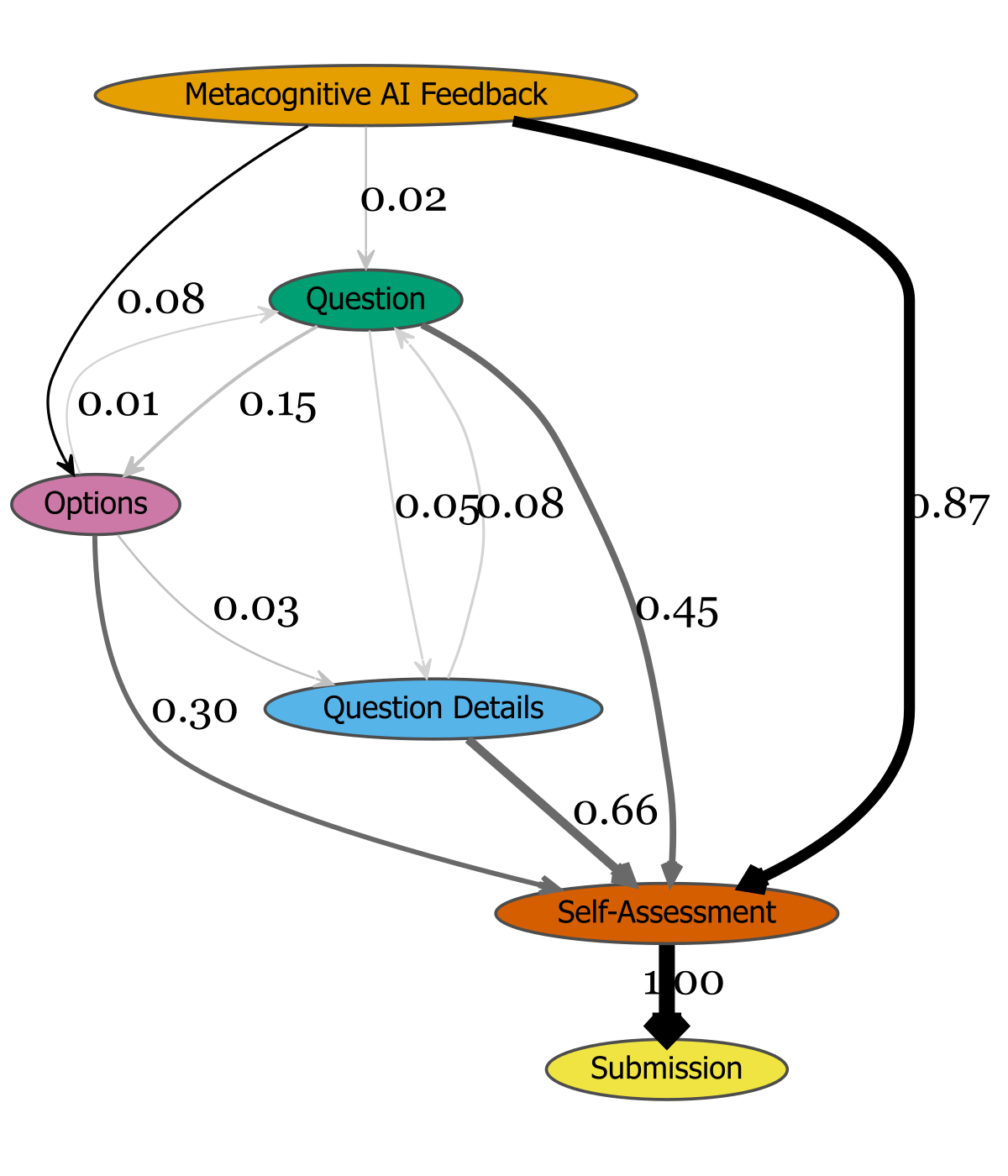
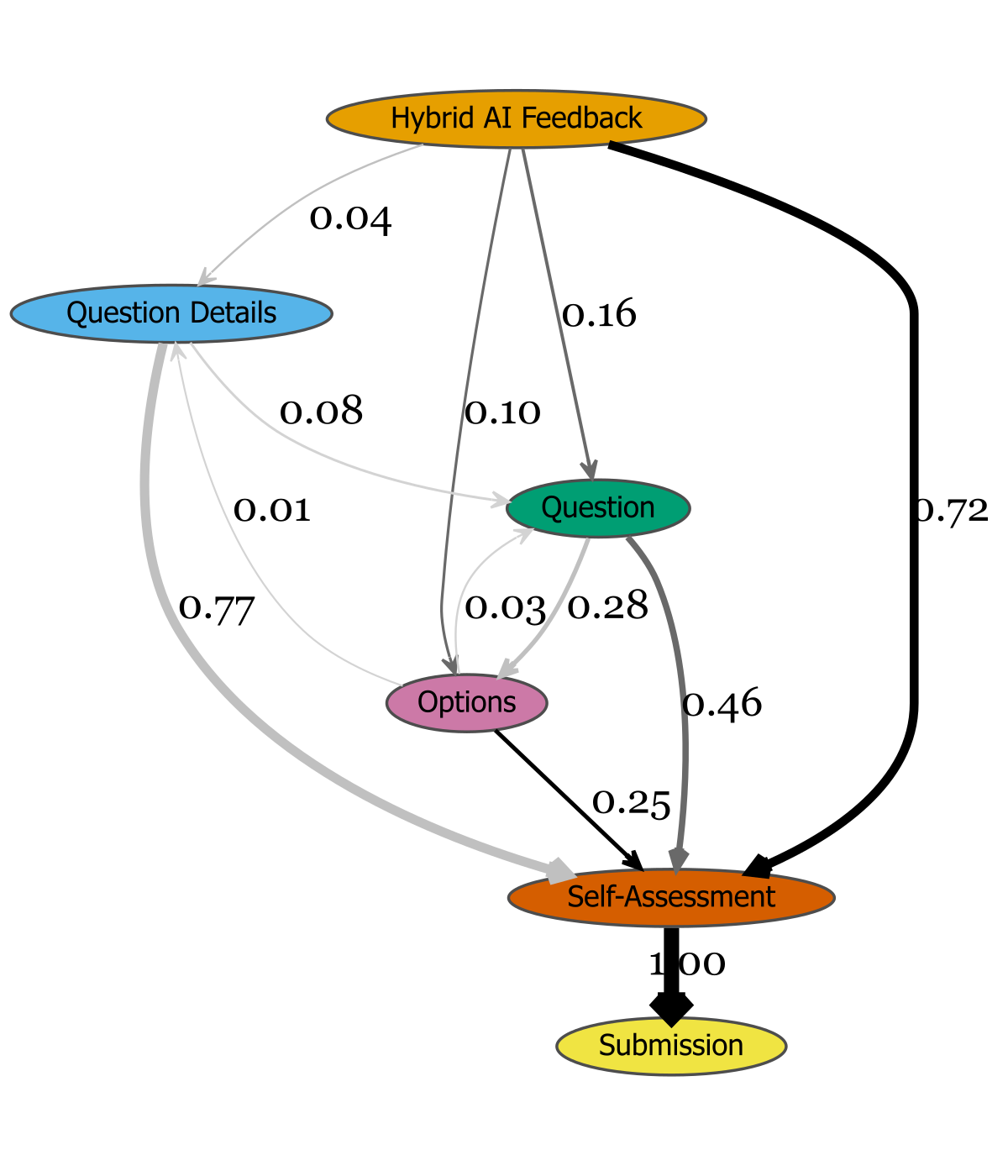
Figure 4: Task engagement flows for the Directive group, illustrating event transitions post-feedback.
These results indicate that while metacognitive feedback prompts reflection, it may not translate into immediate revision, especially for novices. Hybrid feedback, by combining actionable and reflective elements, maximizes revision behavior without sacrificing reflective engagement.
Confidence and Resource Quality Outcomes
Confidence was assessed via post-revision self-ratings; resource quality was measured through a composite of peer, instructor, and algorithmic scores. Both metrics showed no significant differences across feedback conditions:
- Confidence: Medians uniformly high (Mdn=4.0), with no significant contrasts.
- Resource quality: All groups scored similarly (Directive M=3.62, Metacognitive M=3.72, Hybrid M=3.75).
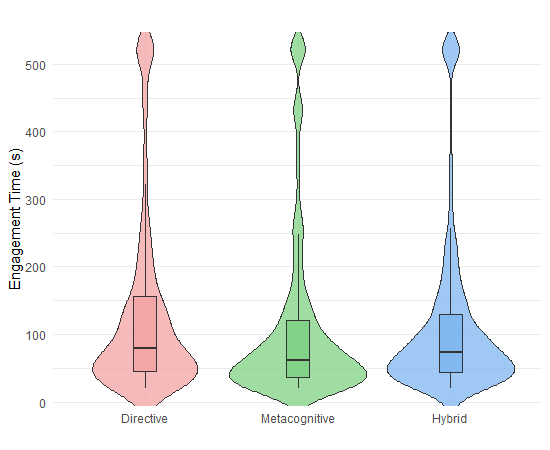
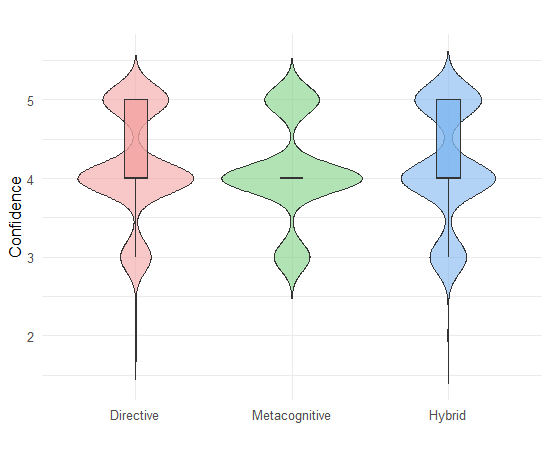
Figure 5: Engagement times across feedback conditions.
These null results suggest a ceiling effect, with students producing high-quality drafts prior to feedback. The feedback thus serves more as validation and refinement than as a driver of substantial improvement. The absence of confidence erosion across conditions is notable, indicating that none of the feedback types undermined self-efficacy.
Implications for AI-Driven Feedback Design
The empirical evidence supports several key implications:
- Prompt engineering is critical: Linguistic and functional differentiation of feedback types is achievable and necessary for controlled pedagogical interventions.
- Hybrid feedback is optimal for engagement: Integrating directive and metacognitive elements increases revision rates and supports both immediate and reflective engagement.
- Metacognitive feedback alone may be insufficient for novices: Without scaffolding, reflective prompts can lead to cognitive overload and inaction.
- No evidence of differential impact on confidence or final resource quality: Feedback type does not affect self-efficacy or performance in high-performing cohorts, suggesting a role for feedback in consolidation rather than remediation.
These findings align with recent meta-analyses and systematic reviews indicating that feedback effectiveness is context-dependent and mediated by learner readiness, feedback literacy, and task difficulty.
Limitations and Future Directions
The study is limited by its single-course context and high baseline performance, which may mask potential effects in more heterogeneous or lower-achieving populations. Behavioral proxies (time-on-task, revision rates) do not capture deeper cognitive or affective processes. Future work should incorporate qualitative analyses of feedback uptake, longitudinal tracking of transfer effects, and integration of emotional and motivational dimensions in feedback design.
The scalability and consistency of AI-generated feedback offer unique opportunities for large-scale, controlled studies of feedback mechanisms. Advances in LLM prompt engineering, affective computing, and adaptive feedback systems will further refine the capacity of AI to support differentiated, personalized learning at scale.
Conclusion
This RCT demonstrates that AI-generated feedback can be systematically engineered to deliver directive, metacognitive, and hybrid interventions with clear linguistic and functional distinctions. Hybrid feedback maximizes revision engagement while maintaining reflective scaffolding, without compromising confidence or resource quality. The results provide robust empirical guidance for the design and deployment of AI-driven feedback systems in higher education, emphasizing the importance of prompt design, feedback literacy, and adaptive scaffolding. The integration of AI in feedback processes holds promise for scalable, personalized, and pedagogically aligned support, contingent on ongoing refinement and contextualization.