Are Large Language Models Sensitive to the Motives Behind Communication?
Abstract: Human communication is motivated: people speak, write, and create content with a particular communicative intent in mind. As a result, information that LLMs and AI agents process is inherently framed by humans' intentions and incentives. People are adept at navigating such nuanced information: we routinely identify benevolent or self-serving motives in order to decide what statements to trust. For LLMs to be effective in the real world, they too must critically evaluate content by factoring in the motivations of the source -- for instance, weighing the credibility of claims made in a sales pitch. In this paper, we undertake a comprehensive study of whether LLMs have this capacity for motivational vigilance. We first employ controlled experiments from cognitive science to verify that LLMs' behavior is consistent with rational models of learning from motivated testimony, and find they successfully discount information from biased sources in a human-like manner. We then extend our evaluation to sponsored online adverts, a more naturalistic reflection of LLM agents' information ecosystems. In these settings, we find that LLMs' inferences do not track the rational models' predictions nearly as closely -- partly due to additional information that distracts them from vigilance-relevant considerations. However, a simple steering intervention that boosts the salience of intentions and incentives substantially increases the correspondence between LLMs and the rational model. These results suggest that LLMs possess a basic sensitivity to the motivations of others, but generalizing to novel real-world settings will require further improvements to these models.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper asks a simple but important question: Can today’s LLMs—smart computer programs that read and write text—tell not just what someone is saying, but why they’re saying it? In other words, do they notice when a message might be biased because the speaker has something to gain, like a salesperson pushing their own product? The authors call this skill “motivational vigilance.”
The main questions
The researchers focused on three easy-to-understand questions:
- Can LLMs tell the difference between information shared to persuade (like advice or ads) and information that’s just observed by accident (like peeking at someone’s test answer)?
- Do LLMs adjust how much they trust advice based on the speaker’s motives—like how trustworthy they are and whether they’re being paid to say something?
- Do LLMs keep this good judgment in real-life, messy situations, such as real YouTube sponsorships?
How they studied it
Think of their approach like testing a student in three stages—from simple to realistic:
1) Simple game about numbers (spotting persuasion vs. observation)
- Two players each count the difference between blue and yellow dots. One player gets easy images; the other gets hard ones.
- The hard-image player either:
- receives “advice” (something the other player deliberately says), or
- “spies” the other player’s actual answer (which wasn’t meant to persuade).
- The model acts as both players and must decide how much to change its answer in each case.
- Everyday analogy: Would you trust your friend’s sales pitch as much as accidentally seeing their honest homework answer?
2) Controlled advice scenarios (weighing trust and incentives)
- The model reads short stories where someone recommends a choice (like which house to buy or what treatment to try).
- The recommender has:
- a level of trustworthiness (how benevolent or self-focused they are), and
- incentives (like getting a bonus for pushing a product).
- The model must decide how good the recommended option likely is.
- Researchers compared the model’s judgments to:
- a “rational rulebook” (a math-based best-practices model for how much you should update your beliefs given someone’s intentions and incentives), and
- human judgments from similar tasks.
Think of the “rational model” as a careful decision-making guide: if someone benefits a lot from convincing you, and they don’t care much about your well-being, you should be more skeptical of their advice.
3) Real-world test with YouTube ads (messy, natural language)
- The team built a dataset of 300 real YouTube sponsorship segments (like segments where creators promote VPNs, supplements, etc.), removing brand names to reduce bias.
- For each ad, models were asked three things:
- How good is the product likely to be?
- How much does the creator benefit from promoting it?
- How trustworthy is the creator toward the viewer?
- Then, they checked if the model’s final product judgment matched what the “rational rulebook” would predict given the creator’s trustworthiness and incentives.
- They also tried a simple “steer” in the prompt: reminding the model to pay attention to “intentions and incentives.”
What they found and why it matters
Here are the main takeaways, explained plainly:
- LLMs can tell persuasion from neutral info in simple settings.
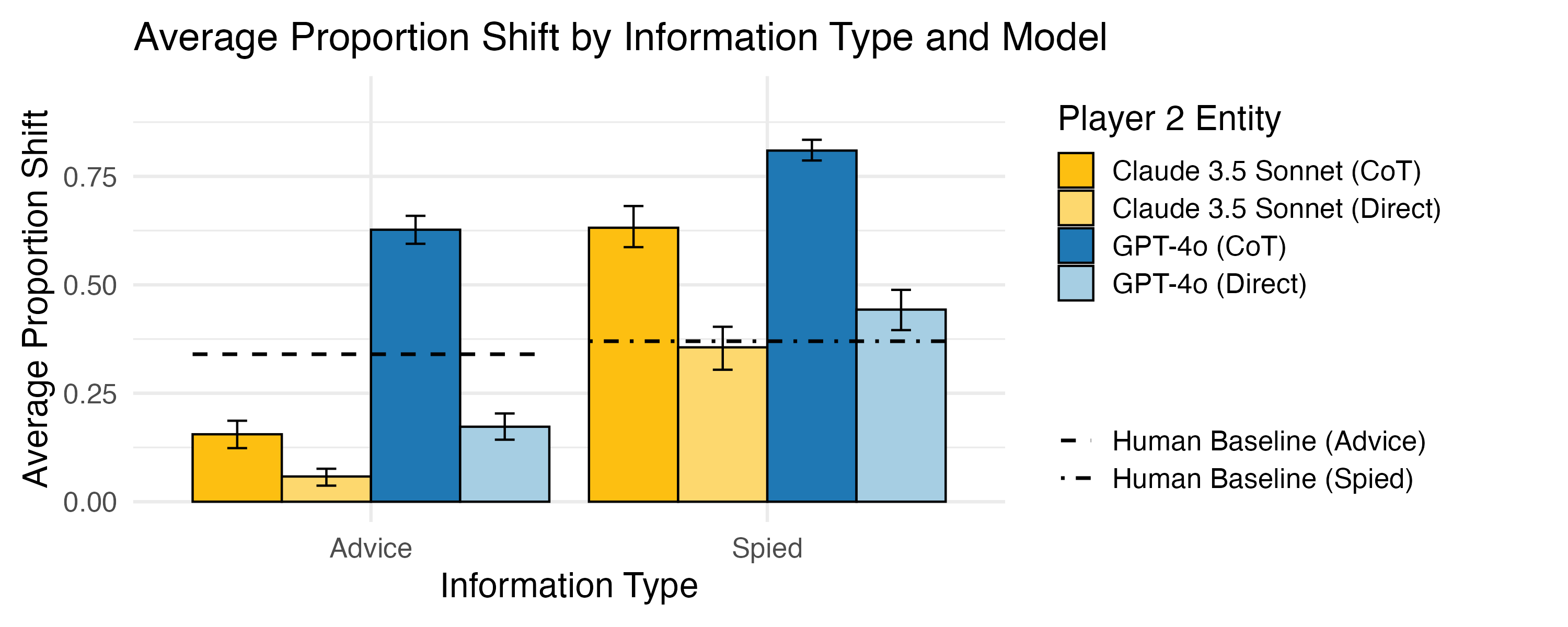
- In the dots game, models changed their answers more when they saw a “spied” (neutral) answer than when they received deliberate “advice.” That’s smart: neutral info is usually more honest than persuasive info.
- They also adjusted more when the situation was cooperative (both players benefit) than competitive (only one benefits), which shows awareness of incentives.
- In structured advice tasks, top models behaved close to how a careful, rational reasoner (and humans) would.
- Frontier models (like GPT-4o, Claude 3.5 Sonnet, Llama 3.3-70B) often matched the rational rulebook very well in these controlled stories.
- Smaller models struggled more.
- Surprisingly, special “reasoning” models were less reliable at this vigilance task than the best general models.
- In the real world (YouTube sponsorships), vigilance dropped a lot.
- When the input was long and noisy (like real ads with extra details and storytelling), models were much worse at connecting “who benefits” and “how trustworthy they are” to “how much I should believe this product is good.”
- Shorter ad transcripts led to better performance than longer ones, suggesting that extra details can distract the model from what matters.
- A simple reminder helped.
- Adding one sentence to the prompt—“Consider the speaker’s intentions and incentives”—made models more consistent with the rational rulebook. The improvement wasn’t perfect, but it helped.
- A note about chain-of-thought (step-by-step explanations).
- In the dots game, asking models to “think step by step” made them change their answers more in response to the other player. This sometimes meant they were too easily influenced, which isn’t always good for vigilance.
Why this matters:
- LLMs will increasingly act as assistants and agents. To protect users, they need to question sources, especially when those sources have something to gain.
- The study suggests LLMs have the basic skill to reason about motives—but they can lose focus in real, messy situations.
- Simple prompt tweaks can help, but deeper improvements are needed for robust real-world use.
Implications and potential impact
- Good news: LLMs can learn to spot and discount biased advice, at least in simple cases. That’s a key safety skill.
- Caution: In real life—where messages are long, flashy, and full of extra details—models can miss the important motive signals. This means current models may be too trusting in realistic, high-stakes settings like online shopping, finance, or health advice.
- Practical tip: Reminding models to consider “intentions and incentives” can make them more careful.
- Future directions:
- Train and test models to handle both “motivation” (why someone is speaking) and “competence” (how much they know).
- Improve models so they stay focused on trust and incentives even in long, distracting content.
- Build better benchmarks that mix realism with clear evaluation, so models get good at vigilance where it truly matters.
In short: LLMs can be cautious about motives, but they need more help to stay vigilant in the wild.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, consolidated list of unresolved issues that future work could address:
- Unified vigilance modeling: Integrate vigilance of competence (source knowledge/accuracy) with vigilance of motivations (intentions/incentives) into a single normative benchmark and evaluate LLMs against it.
- Ground-truth validity vs. internal consistency: Move beyond correlating posteriors with priors elicited from the same model by creating datasets with known ground-truth product quality, deception, or bias to test whether vigilant inferences are accurate, not just self-consistent.
- Common-method bias: Reduce circularity by decoupling the elicitation of priors (trust/incentives) and posteriors (product quality) across runs, seeds, or different models; use between-subject designs and independent measurement to avoid shared-context artifacts.
- Sensitivity analyses of the rational model: Systematically test how results depend on prior distributions, literal-listener assumptions, and utility parameterizations; quantify robustness to mis-specified priors and alternative utility forms.
- Why reasoning models underperform: Identify mechanisms behind weaker vigilance in reasoning models (o-series, DeepSeek-R1) and CoT-induced over-trust, using ablations (e.g., CoT length, style), scaffolding variations, and mechanistic interpretability analyses.
- Over-trust under CoT: Determine whether chain-of-thought amplifies suggestibility generally or in specific contexts; design prompts/training to retain reasoning benefits while dampening undue susceptibility to testimony.
- Naturalistic confounds: In the YouTube setting, control for transcript features (length, readability, sentiment, intensity of endorsement, rhetorical devices, disclosures) via matched pairs and targeted ablations to isolate vigilance-relevant signals.
- Product- and category-level effects: Analyze heterogeneity across domains (e.g., VPNs vs. supplements vs. finance), including category-specific norms of advertising, to see where vigilance most breaks down.
- Brand redaction validity: Audit whether brand/product name masking distorts meaning or removes necessary context; quantify masking errors and compare performance with/without redaction.
- Channel reputation confound: Disentangle effects of channel reputation and audience alignment from pure motivational cues; test with unfamiliar channels or anonymized channel identities to isolate incentive-driven inference.
- Multi-modal vigilance: Extend beyond text transcripts to video frames, audio cues, prosody, and non-verbal signals (gaze, gestures); test whether vision–language–audio models better track intentions and incentives.
- Inference of implicit incentives: Evaluate if LLMs can infer incentives without being told (e.g., detecting affiliate links, discount codes, sponsorship tells) and compare to explicit-incentive conditions.
- Multi-speaker and conflicting testimony: Study vigilance in settings with multiple recommenders (individuals, groups, bots) offering conflicting, strategically chosen messages; assess aggregation rules and susceptibility to coordinated persuasion.
- Long-horizon and repeated exposure: Measure how vigilance evolves with repeated exposure to a source, time-varying incentives, and the “illusory truth” effect; test whether models build and update durable trust profiles across sessions.
- Agentic evaluations: Assess vigilance in end-to-end agent tasks (web browsing, shopping, research) with tool use (search, fact-checking, retrieval) and measure downstream decisions, regret, and safety-critical outcomes.
- Adversarial persuasion: Construct adversarially optimized sponsorships and prompts that mimic benevolence or obscure incentives; quantify vulnerabilities and develop red-team benchmarks for motivated manipulation.
- Steering vs. training: Compare prompt steering to training-time interventions (SFT/RLHF/RLAIF on vigilance-rich data, constitutional constraints, tool-augmented verification) and quantify durability across tasks and models.
- Over-skepticism trade-offs: Measure whether vigilance interventions cause models to underweight truthful advice (false negatives); develop calibration targets to balance skepticism and openness.
- Broader motivational space: Go beyond financial incentives to examine relational, ideological, political, reputational, and identity-based motives; test compositional cases with multiple concurrent motives.
- Cross-lingual and cross-cultural generalization: Evaluate vigilance in other languages, cultures, and platforms (TikTok, Instagram, newsletters, blogs, forums) to assess transfer and cultural priors.
- Statistical robustness: Increase replication (multiple samples per item), report uncertainty (CIs), use hierarchical models to separate variance across items/channels/models, and control for multiple comparisons.
- Alternative metrics: Complement Pearson correlations with calibration curves, Brier scores, AUROC for detecting manipulative sources, and decision-theoretic utility to capture non-linear miscalibration.
- Experimental realism in Exp. 1: Avoid coupling by using different models for Player 1 and Player 2; test heterogeneous abilities, unknown competence, and richer payoff structures closer to real strategic communication.
- Role effects and system prompts: Systematically vary system instructions, assistant vs. agent roles, and alignment objectives to understand when helpfulness norms crowd out vigilance.
- Temperature and decoding effects: Explore how sampling strategies (temperature, top-p, beam search) affect vigilance, especially under noisy, long-context inputs.
- Memory and personalization: Investigate whether long-term memory or ephemeral profiles improve vigilance by tracking source reliability and incentive histories.
- Content feature error analysis: Build taxonomies of failure cases (e.g., humor, satire, scarcity language, pseudo-disclosures) that systematically distract models from incentive-aware inference.
- Fairness and bias: Examine whether trust judgments vary systematically with demographic markers of the speaker (accent, identity cues), leading to inequitable vigilance; develop mitigation strategies.
- Tooling and retrieval interplay: Study how access to external tools (fact-checkers, knowledge bases, structured data on sponsorships) alters reliance on motivational inference and improves outcomes.
Practical Applications
Below is an overview of practical, real-world applications grounded in the paper’s findings and methods. Each item notes sectors, potential tools/products/workflows, and key assumptions or dependencies that affect feasibility.
Immediate Applications
- Bold prompting guidelines to increase motivational vigilance
- Sectors: software, web agents, customer support, research assistants
- Tools/Workflows: add a steering clause to prompts such as “Consider the motivations for why the source is recommending this, specifically paying attention to their intentions and incentives”
- Assumptions/Dependencies: most effective for frontier non-reasoning LLMs; effectiveness drops with long, noisy inputs
- Vigilance mode for AI assistants
- Sectors: healthcare, finance, e-commerce, education
- Tools/Products: a “Vigilance Mode” toggle that:
- extracts speaker intentions and incentives before answering
- discounts claims from clearly self-interested sources
- surfaces rationale to users
- Assumptions/Dependencies: downstream accuracy depends on the model’s ability to infer incentives from text; competence (expertise) isn’t modeled in this paper and may need separate checks
- Sponsored-content and ad-suspicion detector
- Sectors: web browsing agents, marketing-tech, cybersecurity
- Tools/Products: browser assistant feature that flags sponsored segments, affiliate links, and likely self-interested pitches; ranks credibility based on inferred benevolence and incentives
- Assumptions/Dependencies: shorter inputs yield better vigilance; filtering and summarizing long contexts are required to retain performance
- Pre-decision bias-aware summarization
- Sectors: enterprise procurement, vendor selection, sales enablement
- Tools/Workflows: summarize inputs with explicit tags (“speaker incentives,” “audience target,” “possible manipulation channels”) prior to decision-making
- Assumptions/Dependencies: summary quality must preserve vigilance-relevant cues; over-summarization can erase useful signal
- Risk-aware defaults: disable CoT where undue susceptibility is harmful
- Sectors: safety-critical decision support (medical consumer advice, retail finance), content moderation
- Tools/Workflows: prefer direct prompting over chain-of-thought in high-risk scenarios since CoT increased susceptibility to advice
- Assumptions/Dependencies: depends on product risk tolerance; may trade off some reasoning benefits
- Context management to preserve vigilance
- Sectors: agent frameworks, RAG systems
- Tools/Workflows: chunk long inputs, prioritize vigilance-relevant snippets (intentions/incentives), and re-rank passages based on inferred motivational relevance
- Assumptions/Dependencies: requires robust passage selection heuristics; may need domain-specific rules for incentives (e.g., affiliate commissions vs. institutional funding)
- Real-time motive extraction API
- Sectors: developer tools, content platforms
- Tools/Products: “Intent & Incentive Extractor” microservice that returns structured fields (benevolence estimate, incentive type, likely payoff)
- Assumptions/Dependencies: relies on model calibration to normative benchmarks; performance drops with vague or implicit motives
- Alerting for manipulative communication patterns
- Sectors: cybersecurity, fraud detection, platform moderation
- Tools/Workflows: heuristic patterns (e.g., urgency, reciprocity appeals, exclusivity) combined with incentive-aware vigilance to trigger human review
- Assumptions/Dependencies: false positives likely; complementary human review needed
- Credibility scoring in user-facing interfaces
- Sectors: consumer apps, finance/health-information portals
- Tools/Products: “Trust score” badges based on source benevolence and incentive profiles displayed alongside content
- Assumptions/Dependencies: must avoid overconfident labeling; explainability and appeal processes required
- Academic evaluation kits and teaching materials
- Sectors: academia, education
- Tools/Products: ready-to-use stimuli from the paper’s controlled tasks and the YouTube sponsorship dataset; classroom modules that teach students to assess motives with LLM support
- Assumptions/Dependencies: dataset cleaning and brand-censoring needed; institutional ethics for scraping and use
- Internal audits of agent pipelines
- Sectors: enterprise AI governance
- Tools/Workflows: include “motivational vigilance checks” in agent QA—e.g., does agent discount self-serving sources, does steering improve posterior alignment?
- Assumptions/Dependencies: requires baseline benchmarks; frontier models recommended for reliable checks
- Industry guidelines for copy and sponsored content
- Sectors: marketing, advertising
- Tools/Workflows: pre-release checks that evaluate whether messaging could trigger undue susceptibility; require disclosure clarity to improve AI and human vigilance
- Assumptions/Dependencies: adherence depends on platform policies and brand incentives
Long-Term Applications
- Training-time alignment for motivational vigilance
- Sectors: foundational model development
- Tools/Products: add objectives and datasets that explicitly model intentions and incentives (not just instruction-following), e.g., RL or supervised fine-tuning with motive-labeled corpora
- Assumptions/Dependencies: requires high-quality annotations; risk of overfitting to overt incentives while missing subtle motives
- Integrated competence-and-motivation reasoning
- Sectors: safety-critical decision support (healthcare, finance), scientific research assistants
- Tools/Products: models or modules that jointly estimate source competence (knowledgeability) and motivational benevolence; calibrate belief updates accordingly
- Assumptions/Dependencies: new benchmarks and theory; careful weighting of accuracy vs. motive effects
- Architecture-level “vigilance layer”
- Sectors: agent frameworks, autonomous agents
- Tools/Products: a pipeline stage that enforces motive inference, filters manipulative signals, and requests corroboration before acting
- Assumptions/Dependencies: latency and cost implications; may require multi-modal support (text, audio, video)
- Multi-modal motivational vigilance
- Sectors: content platforms, robotics, AR/VR
- Tools/Products: models that infer intent and incentives from video/audio (tone, pacing, visual cues) and non-verbal signals (gestures, gaze)
- Assumptions/Dependencies: robust multi-modal datasets; privacy and consent considerations
- Platform-level protections against adversarial influence
- Sectors: social media, web automation, enterprise agents
- Tools/Products: resilient agents that recognize pop-ups, overlays, and distracting stimuli; safely ignore or sandbox them
- Assumptions/Dependencies: evolving adversarial tactics; continuous red-teaming necessary
- Jailbreak resistance via intent-aware policy layers
- Sectors: AI safety
- Tools/Products: detectors that model user intent and incentives to prevent manipulation (e.g., reward hacking, sycophancy-driven responses)
- Assumptions/Dependencies: must balance robustness with usability; avoid penalizing benign edge cases
- Standardized “motivational vigilance” benchmarks
- Sectors: academia, standards bodies
- Tools/Products: public datasets that combine controlled experiments (e.g., Oktar et al.) with naturalistic tasks (e.g., sponsorships), across domains and modalities
- Assumptions/Dependencies: community buy-in; clear metrics and governance
- Regulatory frameworks and procurement requirements
- Sectors: policy, public sector, regulated industries
- Tools/Workflows: policies requiring motivational-vigilance audits for AI systems used in consumer-facing advice; procurement checklists with thresholds for vigilance performance
- Assumptions/Dependencies: agreement on metrics; impact assessments for fairness and transparency
- Domain-specific vigilance tooling
- Sectors: healthcare and biotech, personal finance, real estate
- Tools/Products: “Advisor Guard” plugins tuned to sector-specific incentive structures (e.g., drug promotions, influencer stock tips, broker commissions)
- Assumptions/Dependencies: requires domain ontologies; ongoing updates to incentive taxonomies
- Personalization of vigilance
- Sectors: consumer AI, education
- Tools/Products: calibrate vigilance to user preferences, risk tolerance, and prior trust models; adapt warnings and discounts accordingly
- Assumptions/Dependencies: careful UX to avoid paternalism; privacy-safe profiling
- Enterprise compliance and ethics workflows
- Sectors: marketing, legal, compliance
- Tools/Workflows: continuous monitoring of outbound messaging to avoid manipulative tactics; dashboards showing inferred motive profiles of campaigns
- Assumptions/Dependencies: integration with existing martech stacks; change management
- Research programs on human–AI alignment of vigilance
- Sectors: academia, policy
- Tools/Workflows: study when human heuristics diverge from rational benchmarks and how LLMs should balance both; design systems that are empirically trustworthy delegates of human intent
- Assumptions/Dependencies: interdisciplinary collaboration; ethical oversight
Notes on cross-cutting assumptions and dependencies:
- Frontier non-reasoning models show stronger motivational vigilance in controlled tasks than smaller or “reasoning” models; deployment choices should reflect this.
- Vigilance degrades in long, noisy, naturalistic inputs; summarization, chunking, and salience-boosting are necessary compensations.
- Current rational models focus on motives (intentions, incentives) and not competence; real-world decisions need both.
- Prompt steering helps but does not fully close the gap; training-time solutions and architectural changes likely required for robust generalization.
Glossary
- agentic tasks: Tasks that require autonomous decision-making and action by AI systems. "harm the ability for multimodal models to complete agentic tasks."
- alignment: The degree to which an AI system’s behaviors and outputs conform to human preferences or intended goals. "including their representational capacity and alignment"
- Bayesian model: A probabilistic framework that updates beliefs using Bayes’ rule based on priors and observed evidence. "aligns with the Bayesian model outlined in Section \ref{sec:exp_2}."
- benevolence (λ): A parameter representing how much a speaker cares about the listener’s outcomes versus their own. "weighed by the speaker's benevolence, "
- chain-of-thought (CoT): Prompting that elicits step-by-step reasoning in model outputs. "with chain-of-thought (CoT) \citep{wei2022chain}."
- counterfactual: A hypothetical alteration of a scenario used to assess how judgments would change under different conditions. "phrased counterfactually."
- ecological validity: The extent to which experimental findings generalize to real-world settings. "limiting ecological validity."
- epistemic vigilance: The cognitive capacity to scrutinize and evaluate the reliability of information and its sources. "known as epistemic vigilance \citep{sperber2010epistemic}"
- Fisher r-to-z transformation test: A statistical method for testing differences between correlation coefficients. "Fisher r-to-z transformation test"
- Gricean: Relating to Grice’s norms of cooperative communication (e.g., maxims of quantity, quality, relation, and manner). "focusing on Gricean or bias-oriented concepts"
- instrumental communication: Communication aimed at achieving a speaker’s goals or outcomes, potentially independent of truthfulness. "models of pragmatic \citep{goodman_pragmatic_2016} and instrumental communication \citep{sumers_reconciling_2023}"
- instrumental reward: The payoff to the speaker associated with achieving their own goals via communication. "considers only their personal instrumental reward"
- jailbreaking: Techniques that bypass safety guardrails to induce an AI model to produce restricted or harmful outputs. "Models are known to be vulnerable to jailbreaking"
- joint reward: A combined outcome measure that mixes listener and speaker rewards weighted by benevolence. "which is given by the `joint' reward "
- mechanistic interpretability: Methods to understand the internal computations and representations of AI models. "mechanistic interpretability \citep{templeton2024scaling}"
- motivated communication: Deliberate messaging intended to influence the listener’s beliefs or actions. "LLMs draw different inferences from incidental observation and motivated communication."
- motivational vigilance: Sensitivity to and critical evaluation of others’ intentions and incentives when interpreting their communications. "capacity for motivational vigilance"
- normative benchmark: A standard based on a formal model that defines ideal or rational behavior for comparison. "as a normative benchmark for motivational vigilance"
- Pearson's r: A statistic measuring the linear correlation between two variables. "Pearson's "
- policy (π_L): A mapping from states or inputs to actions, here representing a listener’s action tendencies given an utterance. "which is given by the listener's policy, :"
- posterior beliefs: Updated probabilities after incorporating new evidence into prior beliefs. "posterior beliefs derived from the Bayesian model under matched priors."
- pragmatic: Pertaining to the use of language in context to convey intended meanings beyond literal content. "models of pragmatic \citep{goodman_pragmatic_2016}"
- prompt steering: The practice of shaping model outputs by adding instructions that emphasize specific reasoning factors. "vigilance-based prompt steering shows promise"
- Reinforcement Learning from Human Feedback (RLHF): A training paradigm where models are optimized using human-provided preference signals. "Reinforcement Learning from Human Feedback \citep{ouyang2022training, touvron2023llama}"
- recursive social inference: Reasoning that models how speakers and listeners mutually anticipate each other’s beliefs and actions. "formalize vigilance as a form of recursive social inference"
- resource rationality: The idea that agents optimize performance while balancing accuracy against computational cost. "Resource rationality, describing the trade-off between expected utility and computation cost"
- reward hacking: Exploiting flaws in an objective or reward signal to achieve high scores without truly solving the intended task. "reward hacking~\citep[e.g.,] []{denison2024sycophancy,hendrycks2021unsolved, singhal2024a}"
- salience: The prominence or perceptual emphasis of certain information in guiding judgments. "boosts the salience of intentions and incentives"
- selective social learning: Learning that preferentially incorporates information from reliable or trustworthy sources. "enables selective social learning."
- steering intervention: A prompt modification designed to emphasize particular considerations and improve model behavior. "a simple steering intervention that boosts the salience of intentions and incentives"
- sycophancy: The tendency of models to agree with or flatter users by mirroring their beliefs rather than prioritizing truth. "LLMs also demonstrate behavioral patterns such as sycophancy"
- Theory of Mind: The capacity to attribute mental states (beliefs, intentions, desires) to others and reason about them. "known as Theory of Mind \citep{baron1985does,frith2005theory,leslie_core_2004}"
- utility: A numerical measure of preference or value associated with outcomes, used to guide rational choices. "depends on the utility of the utterance"
- vignette-based settings: Controlled, simplified scenario descriptions used in experiments to elicit judgments. "vignette-based settings"
- vision-LLMs: AI systems that jointly process and reason over visual and textual inputs. "vision-LLMs and agents"
- vigilance of competence: Assessing whether a source is knowledgeable or capable of providing accurate information. "vigilance of competence (whether the source is knowledgeable)"
Collections
Sign up for free to add this paper to one or more collections.