From Denoising to Refining: A Corrective Framework for Vision-Language Diffusion Model
Abstract: Discrete diffusion models have emerged as a promising direction for vision-language tasks, offering bidirectional context modeling and theoretical parallelization. However, their practical application is severely hindered by a train-inference discrepancy, which leads to catastrophic error cascades: initial token errors during parallel decoding pollute the generation context, triggering a chain reaction of compounding errors and leading to syntactic errors and semantic hallucinations. To address this fundamental challenge, we reframe the generation process from passive denoising to active refining. We introduce ReDiff, a refining-enhanced diffusion framework that teaches the model to identify and correct its own errors. Our approach features a two-stage training process: first, we instill a foundational revision capability by training the model to revise synthetic errors; second, we implement a novel online self-correction loop where the model is explicitly trained to revise its own flawed drafts by learning from an expert's corrections. This mistake-driven learning endows the model with the crucial ability to revisit and refine its already generated output, effectively breaking the error cascade. Extensive experiments demonstrate that ReDiff significantly improves the coherence and factual accuracy of generated content, enabling stable and efficient parallel generation far superior to traditional denoising methods. Our codes and models are available at https://rediff-hku.github.io/.





Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Explaining “From Denoising to Refining: A Corrective Framework for Vision-Language Diffusion Model”
Overview: What is this paper about?
This paper is about improving how AI models describe images with text. The authors focus on a special kind of AI called a “diffusion model” that can generate sentences by filling in missing words. They noticed a big problem: when the model makes a small mistake early, that mistake spreads and causes more mistakes later, leading to messy grammar or made-up details about the image. Their solution, called ReDiff, teaches the model to spot and fix its own mistakes as it writes, like a student who revises drafts instead of just turning in the first attempt.
Objectives: What problems are they trying to solve?
The paper asks simple, practical questions:
- How can we stop small errors from turning into big, messy text when the AI generates multiple words at the same time?
- Can we teach the AI to not only “fill in blanks” but also “revise” what it already wrote?
- Will this make image descriptions more accurate, more detailed, and faster to produce?
Methods: How does their approach work?
To understand the approach, think of writing an essay in rounds:
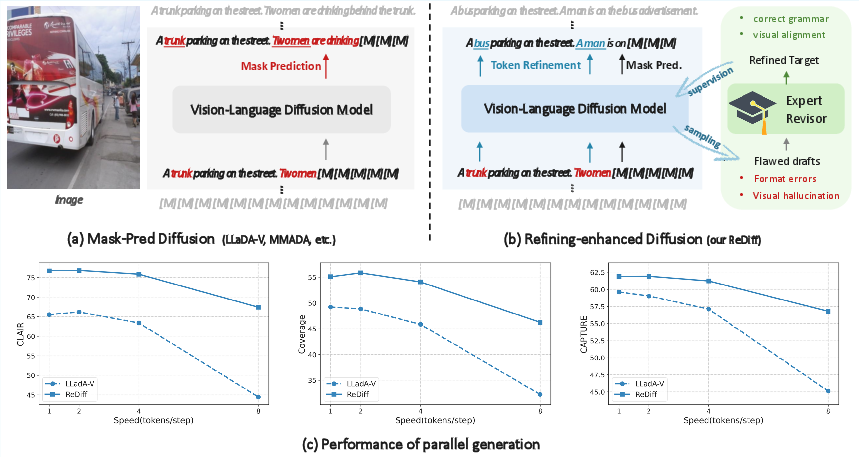
- Traditional “denoising” diffusion models act like filling in a worksheet with blanks. They reveal words bit by bit but don’t change words already revealed—even if they’re wrong.
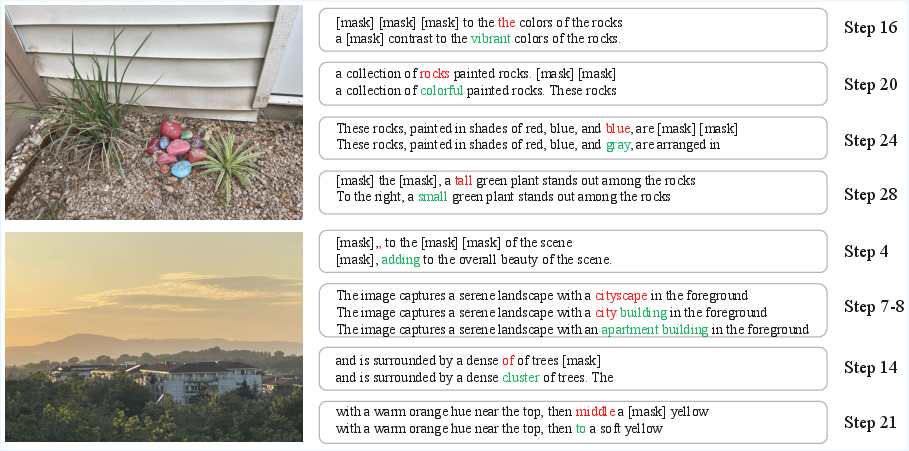
- ReDiff changes that by adding “refining.” The model can update words it already wrote if it realizes they don’t fit.
The authors used two training stages:
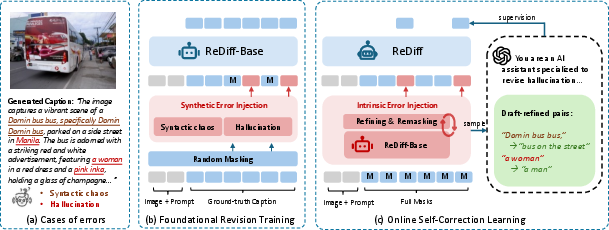
- Stage I: Foundational Revision Training
- Grammar glitches or repeated words (syntactic errors)
- Wrong facts about the image, like calling a bus a “truck” (hallucinations)
- The model learns to fix these and recover the original correct sentence. This builds basic “editing” skills.
- Stage II: Online Self-Correction Learning Now the model writes its own drafts describing images. An expert AI (a stronger model) reviews the draft, corrects errors, and provides the improved version. ReDiff then trains specifically on those “before-and-after” corrections, learning how to fix its own typical mistakes. This is like getting feedback with a red pen and practicing those exact corrections.
During inference (the actual generation):
- The model starts with a fully masked sentence (all words hidden), then, at each step, it:
- Unmasks several new words at once (fast, parallel generation).
- Revises previously written words if needed.
- This reduces error cascades because the model can backtrack and fix bad guesses.
Findings: What did they discover?
The authors tested ReDiff on image captioning benchmarks and found:
- ReDiff created more fluent, detailed, and accurate captions than other diffusion-based models.
- It stayed stable even when generating multiple words per step (fewer steps = faster). Other models often became repetitive or chaotic when sped up.
- On several metrics and datasets (like CapMAS, CapArena, and DetailCaps), ReDiff achieved higher scores than previous diffusion models and sometimes matched or beat common autoregressive models (the kind that write one word at a time).
Why this matters:
- It shows diffusion models can be both fast and reliable when equipped with revision skills.
- It reduces hallucinations (made-up facts) and messy formatting—critical for trustworthiness.
Impact: Why is this important and what could happen next?
ReDiff makes AI better at “thinking twice” while generating text, especially when describing images. This has big benefits:
- More accurate captions for apps helping people understand visual content (like accessibility tools).
- Faster yet dependable generation for creative work, education, and media.
- A general idea that applies beyond captions: teaching models to correct their own output can improve many AI tasks.
In short, the paper shifts the mindset from “just fill in the blanks” to “write, check, and revise.” That change helps AI produce clearer, truer, and more stable text—especially when working fast.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a consolidated list of concrete gaps and open questions that remain unresolved and that future work could directly act on:
- Missing compute/latency analysis: quantify wall-clock throughput, latency per step, and memory use for refinement vs. standard mask-pred diffusion at different token-per-step settings; report tokens/sec and cost per 1k output tokens.
- Token-flip stability and convergence: measure and control oscillations where tokens repeatedly change across steps; report flip rates, edit distance trajectories, and introduce/ablate stabilization strategies (e.g., confidence thresholds, trust regions, EMA over logits).
- Inference hyperparameters: systematically study dynamic token-per-step schedules, adaptive confidence thresholds, temperature/sampling vs. greedy decoding, early-stopping criteria, and their impact on quality vs. speed.
- Theoretical guarantees: provide convergence analyses or bounds showing when and why iterative refinement mitigates error cascades; characterize trade-offs between number of steps, edit rates, and final quality.
- Generalization beyond detailed captioning: validate on diverse multimodal tasks (VQA, instruction following, OCR-heavy tasks, counting, reasoning, multi-turn dialogues); quantify transfer and potential failure modes.
- OOD robustness: evaluate on out-of-domain images (medical, diagrams, charts, cartoons), low-light/noisy images, and adversarial perturbations; characterize robustness of refinement.
- Long-sequence behavior: test scaling to longer outputs (≫128 tokens), multi-paragraph/image-set descriptions, and document-level narratives; analyze degradation and memory/latency implications.
- Multilingual and cross-lingual capability: assess refinement efficacy across languages, code-switching, and transliteration; determine whether error types and correction behaviors transfer.
- Dependence on a proprietary “expert” (o4-mini): ablate with open-source experts of varying strengths; measure sensitivity to expert quality, bias, and style; study privacy/cost implications of sending images/drafts to external services.
- Requirement for ground-truth during Stage II: Stage II needs GT to guide the expert’s revisions; develop methods that do not require labeled references (e.g., self-consistency ensembles, agreement-based critics, learned reward models, RLAIF/RLHF).
- Data efficiency and cost: report annotation/call costs to produce 10k draft–refined pairs; study active selection of drafts that maximize refinement gains per budget; compare single vs. multiple rounds with controlled data budgets.
- Expert error tolerance: quantify robustness to noisy or suboptimal expert corrections; study how misaligned or partially-correct revisions affect training and final performance.
- Alignment of corrections to tokens: detail and evaluate the alignment procedure mapping expert-edited spans to token-level supervision; measure alignment errors and their downstream impact.
- Edit granularity: compare token-level vs. span-level editing objectives, copy/keep losses, and minimal-edit regularizers to prevent over-correction or semantic drift.
- Preservation of user intent/style: evaluate whether refinement unintentionally alters valid stylistic choices or user-specified constraints; introduce metrics for semantic/intent preservation and minimality of edits.
- Adaptive refinement budgets: design policies that allocate more refinement to uncertain regions and less to stable spans; compare learned refinement masks vs. full-sequence rewriting each step.
- Risk of oscillatory or catastrophic edits: analyze cases where refinement degrades factuality or coherence; introduce guardrails (e.g., monotonicity constraints, edit distance caps, rollback-on-degrade mechanisms).
- Metrics and evaluation bias: heavy reliance on GPT-4o-based judges; conduct blinded human evaluations, inter-annotator agreement, and robustness of rankings across multiple judges; use image-grounded factuality protocols that avoid the “extraction sparsity” artifact noted in the paper.
- Comparative baselines: include strong AR self-refinement/editing baselines (e.g., Levenshtein Transformer, insertion-based decoders, self-critique/rewrite loops, RLHF/RLAIF with hallucination penalties, retrieval-augmented VLMs).
- Corruption/noise design: ablate forward noising schedules (), corruption types, and replacement rates; include more realistic model-like errors beyond random replacements and ViCrit hallucinations; evaluate mismatch between synthetic errors and real model errors.
- Scaling laws: study how refinement benefits scale with model size, vision encoder strength, vocabulary size, and dataset size; report parameter–data–compute trade-offs.
- Vision encoder and architecture choices: ablate vision backbones (CLIP, SigLIP, EVA, etc.), cross-modal connectors, and attention schemes; analyze how bidirectional attention contributes to refinement efficacy.
- Stepwise quality–speed Pareto: provide comprehensive Pareto frontiers across steps/tokens-per-step vs. quality metrics; include error bars and statistical significance testing.
- Cross-dataset generalization and leakage checks: ensure no training–test leakage, especially since Stage II uses ground-truth to guide the expert; evaluate on held-out datasets with different caption styles.
- Safety/fairness considerations: test whether refinement reduces harmful or identity-related hallucinations; evaluate bias across demographics and image content categories.
- Video/temporal extension: assess whether refinement helps temporal consistency in video captioning or multimodal reasoning over sequences; quantify temporal coherence metrics.
- Edit accounting: report number, type, and locality of edits per step and per sample; tie edit statistics to final gains to validate the “correction” hypothesis.
- Interplay with caching and compute reuse: quantify overhead of recomputing full-sequence logits each step when updating previously unmasked tokens; explore attention cache reuse or partial re-scoring.
- Open-source reproducibility: provide missing implementation specifics (noise schedule, selection/re-masking policy, temperature, prompts in main text), seeds, and exact training configs to enable faithful replication.
Practical Applications
Immediate Applications
Below are deployable use cases that leverage ReDiff’s refining-enhanced discrete diffusion framework for vision-language generation, with emphasis on stability under parallel decoding, reduced hallucinations, and improved factuality.
- High-throughput, cost-efficient image captioning for media libraries and catalogs
- Sectors: media/entertainment, digital asset management (DAM), stock photo providers
- Tools/products/workflows: “Refinement-enhanced Captioning API” or SDK that replaces or complements AR captioners; batch pipelines using 4–8 tokens/step parallel decoding to cut inference cost while maintaining quality; auto-QA with spot human review
- Assumptions/dependencies: availability of a base discrete diffusion LVLM (e.g., LLaDA-V) and the ReDiff training recipe; compute for Stage I/II training; domain similarity to training sets; evaluation pipelines (e.g., CLAIR/CAPTURE-like metrics)
- E-commerce product image captioning and SEO metadata generation
- Sectors: retail/e-commerce, marketplaces
- Tools/products/workflows: automatic product captions, attributes, and alt text for listings; batch refresh workflows tied to catalog updates; “refine draft” loop to correct attributes (color, count) and avoid hallucinated features
- Assumptions/dependencies: product-specific vocabularies and attribute ontologies; optional expert-in-the-loop (human or LLM) during onboarding; alignment with brand/style guides
- Accessibility alt-text generation at scale
- Sectors: public sector, enterprise IT, web platforms, education
- Tools/products/workflows: CMS plug-in that generates and iteratively refines alt text during content publishing; dashboard for QA to meet WCAG compliance
- Assumptions/dependencies: human QA still recommended for compliance-critical content; privacy constraints on image ingestion; domain drift if images differ greatly from training data
- Data labeling acceleration for vision-language datasets
- Sectors: AI/ML teams, labeling vendors, academia
- Tools/products/workflows: “model-as-drafter” flow where ReDiff creates captions; humans or an “expert model” revise them; refined pairs get fed back into Stage II to bootstrap domain-specific performance
- Assumptions/dependencies: budget for expert model or annotators; data governance for draft-refined pairs; integration into labeling platforms
- Multimedia search and indexing via robust, detailed descriptions
- Sectors: enterprise search, DAM, content management
- Tools/products/workflows: pipeline that uses ReDiff captions to enrich image metadata and scene graphs; improved recall/precision in search; scheduled refinement jobs to cut hallucination-driven indexing noise
- Assumptions/dependencies: scene graph extraction remains external; evaluation of retrieval gains; monitoring to detect drift
- Publisher workflows for scientific and news figure captions
- Sectors: scholarly publishing, newsrooms
- Tools/products/workflows: auto-caption drafts for figures/charts with iterative refinement; editorial review UI surfacing “changed” tokens between refinement steps for quick QA
- Assumptions/dependencies: domain shift for charts/diagrams may require domain-adapted Stage I/II data; safety checks to prevent misinterpretations
- Social and creator tools: “refine my caption” for images
- Sectors: consumer apps, marketing, creator economy
- Tools/products/workflows: in-app assistant that revises user-supplied or model-drafted captions to remove errors and improve fluency; A/B testing vs AR baselines for engagement
- Assumptions/dependencies: speed/latency budgets; moderation and brand safety filters
- Cloud AI service tier for fast parallel multimodal generation
- Sectors: cloud providers, MLOps platforms
- Tools/products/workflows: a ReDiff-backed service tier optimized for 2–8 tokens/step; SLAs oriented around consistent quality at lower latency/cost; autoscaling batch workers
- Assumptions/dependencies: GPU availability and batching; user acceptance of diffusion-based decoding behavior vs AR determinism; monitoring for rare failure modes
- Academic benchmarking and methodology transfer
- Sectors: academia/research labs
- Tools/products/workflows: deploy ReDiff as a baseline for multimodal generation; ablation-friendly training recipe (synthetic corruption + online self-correction with expert) for other datasets/tasks
- Assumptions/dependencies: access to expert revisors (LLM or human); compute to replicate Stage II
Long-Term Applications
These use cases are plausible extensions but need further research, domain adaptation, scaling, or regulatory clearance.
- Real-time AR narration and assistive vision
- Sectors: accessibility, consumer electronics
- Tools/products/workflows: low-latency on-device/edge captioning for smart glasses that refines descriptions across frames; optional user prompt-in-the-loop to guide refinement
- Assumptions/dependencies: significant optimization (quantization, distillation) for edge; privacy-preserving inference; robustness to open-world scenes; power constraints
- Robotics and industrial automation perception reports
- Sectors: robotics, manufacturing, logistics
- Tools/products/workflows: closed-loop perception layer that produces and refines scene descriptions for task planners; “corrective narrative” to reduce error cascades in downstream decisions
- Assumptions/dependencies: integration with sensor fusion and control stacks; rigorous safety validation; domain-specific training (warehouse, factory scenes)
- Medical imaging reporting with human-in-the-loop
- Sectors: healthcare
- Tools/products/workflows: draft findings from radiology/pathology images that a clinician refines; structured reporting assistance that minimizes hallucinations and highlights low-confidence segments
- Assumptions/dependencies: domain training data and expert revisors; clinical validation and regulatory approval; strict privacy/compliance; calibrated uncertainty estimates
- Autonomous driving and public safety narration
- Sectors: automotive, public safety
- Tools/products/workflows: explainable scene descriptions for monitoring and post-hoc analysis; iterative refinement to correct initial misreads (e.g., object class, count)
- Assumptions/dependencies: real-time constraints; high-stakes safety; extensive validation; bias and failure mode audits
- Video-level summarization with temporal refinement
- Sectors: media, surveillance, education
- Tools/products/workflows: extend ReDiff’s token refinement across time to revise summaries as more frames are processed; hierarchical “draft → refine” loops across shots/scenes
- Assumptions/dependencies: temporal architectures and datasets; scalable benchmarks; compute for long-context processing
- Multimodal dialog and VQA with self-corrective turns
- Sectors: education, customer support, enterprise assistants
- Tools/products/workflows: dialog agents that refine prior turns when contradictions surface; “self-correction memory” that updates earlier tokens/sentences
- Assumptions/dependencies: adaptation beyond captioning to QA/dialog; evaluation beyond caption metrics; safety for user-facing corrections
- Domain-specific synthetic data generation with quality control
- Sectors: AI/ML, data vendors
- Tools/products/workflows: use ReDiff to produce high-fidelity captions for underrepresented domains; iterative expert refinement as a built-in QA loop; generate training corpora for downstream LVLMs
- Assumptions/dependencies: reliable quality metrics; governance to prevent synthetic artifacts compounding bias; cost of expert supervision
- General discrete diffusion LLM acceleration (beyond vision-language)
- Sectors: software/AI platforms, code assistants
- Tools/products/workflows: apply the “refine-not-just-denoise” training to text/code diffusion models, enabling stable multi-token-per-step decoding for faster inference
- Assumptions/dependencies: transferability to pure-text/code tasks; availability of expert revisors; competitive performance vs optimized AR models
- Edge deployment and green AI initiatives
- Sectors: mobile/edge AI, energy/sustainability
- Tools/products/workflows: leverage parallel decoding stability to reduce inference steps and energy per caption; carbon-aware scheduling for batch captioning jobs
- Assumptions/dependencies: measured energy gains in practice; model compression; hardware support
- Policy and compliance toolchains for accessible content at scale
- Sectors: government, large enterprises, education
- Tools/products/workflows: centralized services to generate and refine alt text across legacy archives; audit trails showing self-corrections for compliance reviews
- Assumptions/dependencies: procurement and data-sharing frameworks; human governance; provenance tracking for draft/refined outputs
Cross-cutting Assumptions and Dependencies
- Expert revisors for Stage II: The paper uses an external “expert model” (e.g., o4-mini). In production, this can be a human editor, a domain-tuned LLM, or a hybrid; it adds cost and may introduce licensing/privacy constraints.
- Task/domain transfer: Results are shown on detailed image captioning. Extensions (VQA, medical, robotics, video) require task-specific data, evaluation, and likely new corruption schemes and prompts.
- Metrics and safety: Benchmarks rely partly on LLM-as-a-judge (e.g., GPT-4o-based metrics). For sensitive domains, independent, domain-specific evaluation and safety audits are needed.
- Infrastructure: Training involves two stages and iterative loops; adequate compute, data governance, and MLOps are required. Inference benefits from batching and optimized kernels to realize speedups.
- Model stack compatibility: ReDiff assumes a discrete diffusion, mask-pred LVLM with bidirectional attention and token update capability. Porting to other architectures may require engineering effort.
- Bias and privacy: Both base and expert models can encode biases; images may contain PII. Governance, redaction, and bias mitigation remain essential.
Glossary
- Absorbing state: A terminal token that remains unchanged during corruption in a discrete process, often used as a special placeholder. "or an absorbing state (e.g., a [MASK] token)."
- Autoregressive (AR) paradigm: A generation approach that produces tokens sequentially in a fixed direction, conditioning each token on previously generated ones. "Discrete diffusion models have recently emerged as a promising alternative to the dominant autoregressive (AR) paradigm for vision-LLMs (VLMs)"
- Bidirectional attention mechanism: An attention setup where each token can attend to both past and future positions, enabling updates to already generated content. "Our ReDiff, however, leverages the bidirectional attention mechanism inherent to the diffusion paradigm."
- Bidirectional context modeling: Modeling that uses information from both preceding and following tokens to predict or refine outputs. "This approach allows for bidirectional context modeling, granting them greater flexibility in controlling the generation process and a theoretical potential for massive parallelization"
- Cross-entropy loss: A standard classification loss that penalizes incorrect probability distributions over discrete classes, here applied to masked tokens. "The training objective is a cross-entropy loss computed only on the masked tokens:"
- Discrete diffusion models: Generative models that define a corruption and denoising process over discrete variables (tokens) rather than continuous data. "Discrete diffusion models have emerged as a promising direction for vision-language tasks"
- Discrete flow matching: A training paradigm aligning model dynamics to a target flow over discrete states, enabling generative transformations. "FUDOKI~, a multimodal model based on discrete flow matching, progressively revises a random sentence"
- Discrete Markov chains: Stochastic processes where the next state depends only on the current state, used to progressively corrupt text. "employed discrete Markov chains where a transition matrix is progressively applied to the input"
- Edit-based forward process: A corruption strategy that applies edit operations during the forward diffusion steps to facilitate later revisions. "SEED-Diffusion introduced an 'edit-based forward process' for code generation"
- Error cascade: A chain reaction where initial mistakes contaminate context and lead to compounding errors. "the error cascade driven by a training-inference discrepancy."
- Error propagation: The phenomenon where an early error in generation irreversibly misguides subsequent outputs. "In autoregressive models, this issue is exacerbated by error propagation; an incorrectly generated token can irreversibly misguide the subsequent generation path."
- Forward process: The corruption phase of diffusion that transforms clean text into noisy or masked states according to a schedule. "A discrete diffusion model formalizes text generation through a forward and a reverse process."
- MASK token: A special placeholder token indicating a position to be predicted or recovered during training/inference. "replacing tokens with a [MASK] token based on a noise schedule "
- Mask-and-pred diffusion models: Diffusion variants that mask tokens and predict them iteratively, often starting from a fully masked sequence. "More recently, mask-and-pred diffusion models have demonstrated significant empirical success."
- Noise schedule: A function controlling the amount of corruption at each diffusion timestep. "based on a noise schedule "
- Online self-correction learning: A training strategy where the model iteratively learns to fix its own generated drafts using expert-provided refinements. "For the second stage, i.e., online self-correction learning, the model generates its own flawed 'drafts'."
- Parallel decoding: Generating multiple tokens simultaneously in each step, as opposed to strictly sequential generation. "In a parallel decoding scenario, this discrepancy becomes catastrophic."
- Prior distribution: The initial distribution over states used in the reverse diffusion, often a fully masked sequence in text models. "culminating in a fully masked sequence as a prior distribution."
- Q-Former: A lightweight module that bridges visual and language components by transforming visual features into query tokens. "via a lightweight module like an MLP or Q-Former."
- Reverse process: The denoising phase that reconstructs clean text from corrupted inputs. "The reverse process aims to reverse this corruption."
- Scene graph: A structured representation of objects, attributes, and relationships in an image used for evaluating caption quality. "uses the CAPTURE metric, which scores the generated caption by comparing its scene graph to that of the ground-truth description."
- Semantic hallucinations: Generated content that is plausible linguistically but factually inconsistent with the visual input. "leading to syntactic errors and semantic hallucinations."
- Syntactic chaos: Text errors involving incoherence, repetition, or grammatical mistakes. "reveal two predominant error types: syntactic chaos (e.g., incoherence, repetition, grammatical errors)"
- Training-inference discrepancy: The mismatch between training on clean ground-truth data and inferring from the model’s own noisy outputs. "the error cascade driven by a training-inference discrepancy."
- Transition matrix: A matrix specifying probabilities of token transitions during corruption in discrete Markov chains. "where a transition matrix is progressively applied to the input"
- Unmasking: Selecting and fixing predictions for masked positions during diffusion sampling. "progressively unmasking tokens with the highest confidence."
- Visual instruction tuning: Fine-tuning multimodal models with instruction-style data to perform a variety of visual tasks. "and then conduct visual instruction tuning to handle a wide range of vision-centric tasks."
- Vision encoder: A model component that converts images into feature representations for downstream language processing. "The dominant architecture connects a pre-trained vision encoder to an autoregressive LLM"
Collections
Sign up for free to add this paper to one or more collections.