- The paper demonstrates that selecting the shortest completion among parallel outputs enhances accuracy and efficiency in LLMs compared to traditional methods.
- It leverages a heuristic that distinguishes between succinct and overthinking regimes, significantly reducing token usage and computational overhead.
- Experiments on benchmarks like AIME reveal a four percentage point accuracy boost over single-solution attempts, highlighting its practical efficiency.
Summary of "The Virtues of Brevity: Avoid Overthinking in Parallel Test-Time Reasoning"
Introduction
The paper "The Virtues of Brevity: Avoid Overthinking in Parallel Test-Time Reasoning" (2510.21067) presents a novel approach in the field of reinforcing reasoning capability in LLMs. The authors propose a heuristic based on selecting the shortest completion from multiple parallel generated solutions, challenging the conventional methods that rely heavily on complex scoring models and self-consistency techniques. Their primary contribution is the demonstration of this counterintuitive heuristic's effectiveness in optimizing accuracy and computational efficiency without sacrificing performance.
Theoretical Framework
The paper posits that reasoning models operate within two distinct regimes: the conventional succinct regime and the verbose overthinking regime. The succinct regime is characterized by confidence with shorter solutions reflecting higher certainty, whereas the overthinking regime consists of excessive tokens as a compensation for uncertainty in the models' outputs. The shortest-solution heuristic essentially exploits these regimes by preferentially targeting the confident regime, leading to improved efficiency. This methodology provides a competitive alternative to other Best-of-N selection strategies like self-consistency, which depend on output comparability and additional computational overhead (2510.21067).
Experimental Analysis
Extensive experiments were conducted on three LLMs: DeepSeek-R1, Grok-3-mini, and Qwen3-32B, using the AIME and LiveCodeBench benchmarks. The results demonstrated that selecting the shortest solution enhanced performance comparable to or exceeding more complex strategies such as self-consistency, while significantly reducing computational requirements. The Pareto curve analysis indicated substantial token savings, affirming the heuristic's promise as a token-efficient approach when measuring accuracy against token usage.
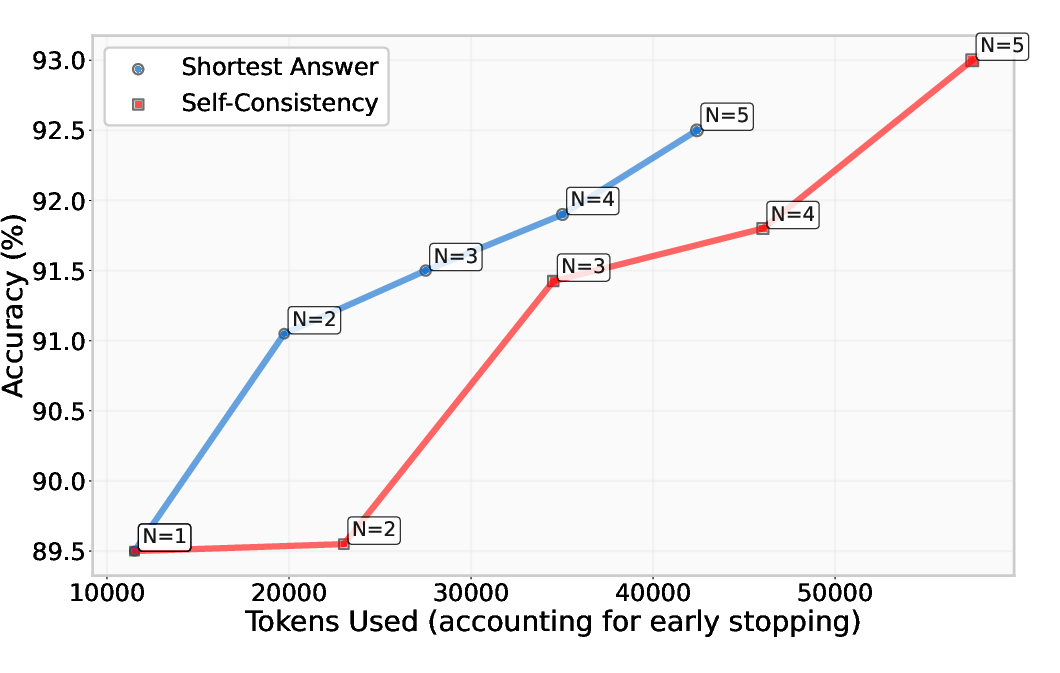
Figure 1: Pareto curve of accuracy against token usage for DeepSeek-R1, comparing the efficacy of self-consistency and picking the shortest solution on 400 AIME questions.
Numerical Findings
Quantitative results reveal that this heuristic matched self-consistency performance across various benchmarks, with notable accuracy improvements such as a four percentage point increase over single-solution attempts in DeepSeek-R1. Moreover, discrepancies between shortest and longest solutions highlight the utility of brevity, with the longest solutions exhibiting increased uncertainty density, corroborating the overthinking hypothesis.
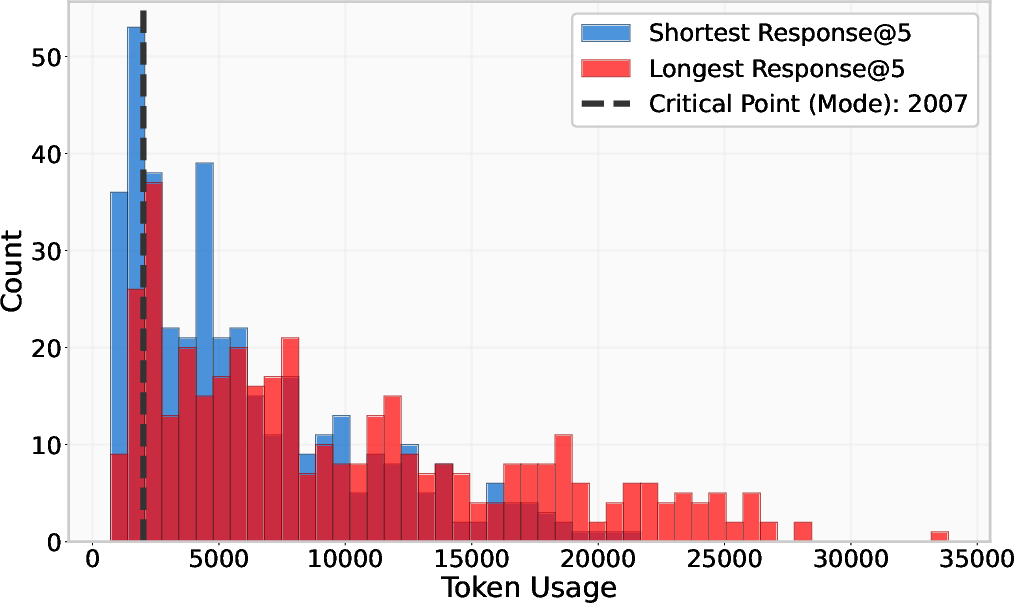
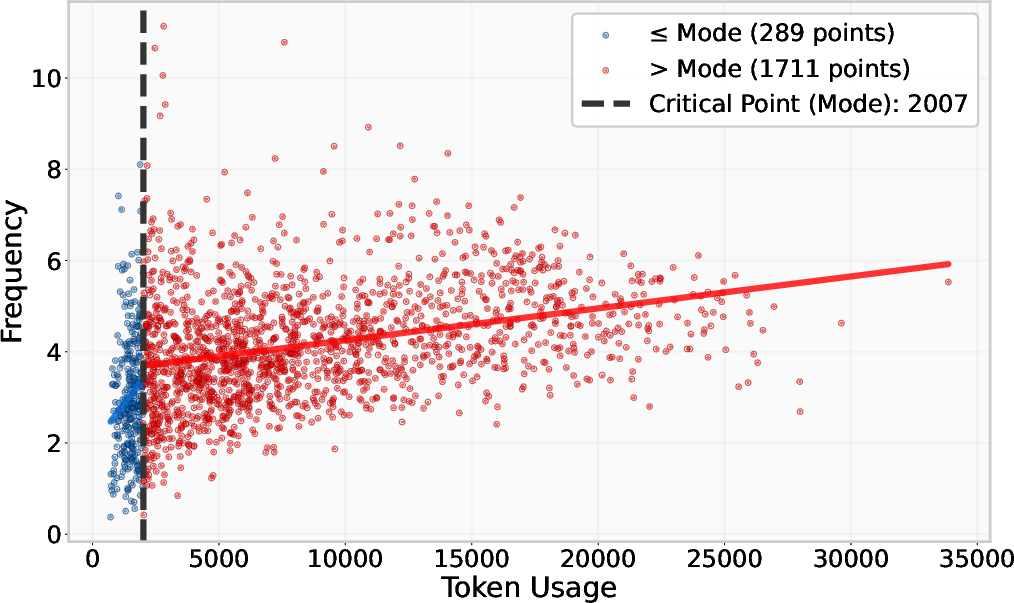
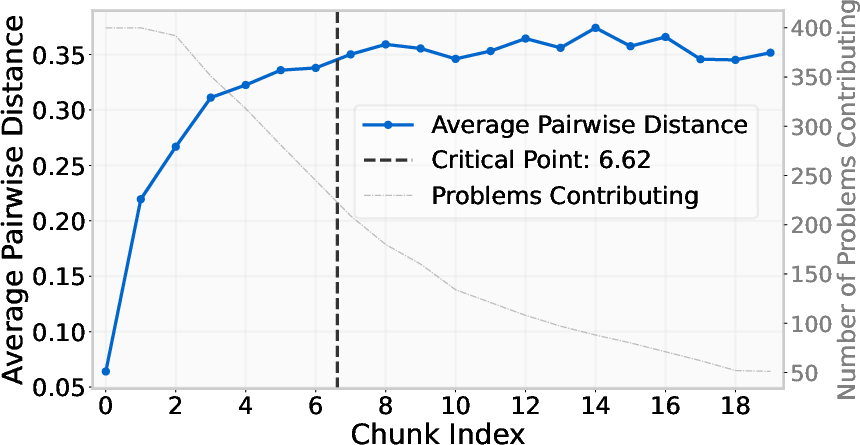
Figure 2: Analysis of different trend breaks for DeepSeek-R1 on the AIME benchmark before and after the critical point, indicating separation between conventional and overthinking regimes.
Speculative Outlook
The heuristic introduced in the paper holds significant implications for future developments in AI. By demonstrating that simpler methods can yield superior computational efficiency without compromising accuracy, this approach paves the way for more scalable AI implementations, particularly in resource-constrained environments. The reduction in computational cost also suggests broader applicability across various tasks and contexts where output comparison is infeasible, providing a potential paradigm shift in parallel test-time reasoning strategies.
Conclusion
The paper effectively challenges established methodologies by introducing a simple yet potent heuristic that leverages the intrinsic regimes of reasoning models. This strategic focus on brevity not only aligns with conventional performance metrics but surpasses them in efficiency, heralding a fresh perspective in optimizing LLM operations. The empirical success of this approach across challenging benchmarks anticipates further exploration and adaptation in optimizing LLM capabilities, driving advancements in AI performance and scalability.