- The paper introduces a unified system that leverages multimodal parsing and iterative workflows to extract and synthesize evidence from complex documents.
- It employs dynamic, hybrid retrieval strategies and layout-aware parsing techniques, achieving a 50.6% accuracy that significantly outperforms baseline methods.
- The system establishes the M4DocBench benchmark, setting a new standard for evaluating multimodal, multi-hop document research capabilities.
Doc-Researcher: A Unified System for Multimodal Document Parsing and Deep Research
Introduction
The "Doc-Researcher" paper presents a unified system aimed at bridging the gap between current deep research systems and multimodal document processing. Traditional systems have been largely limited to textual web data and overlook the multimodal nature of documents such as scientific papers, technical reports, and financial documents that contain critical information embedded in figures, tables, charts, and equations. Doc-Researcher integrates multimodal document parsing with advanced multi-agent deep research capabilities to address this limitation, facilitating complex query decomposition and iterative evidence synthesis across diverse document collections.
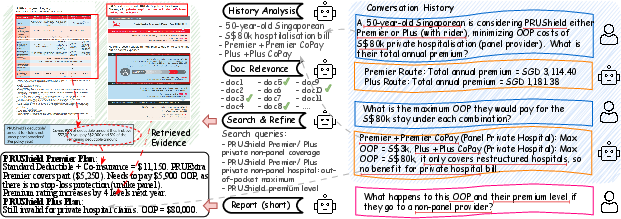
Figure 1: An typical use case of multimodal doc deep research. The user asks a multi-hop question in the context of multi-turn conversations, where ground-truth evidence spans across multiple documents and modalities. The demo conversations, evidence, and answer are shortened for simplicity.
System Architecture
Doc-Researcher is structured into three main components:
- Deep Multimodal Parsing: This component preserves layout structure and visual semantics via MinerU for layout-aware document analysis and intelligent chunking strategies.
- Systematic Retrieval Architecture: Doc-Researcher supports text-only, vision-only, and hybrid retrieval paradigms with dynamic granularity selection which adapts retrieval strategies to query characteristics (Figure 2).
- Iterative Multi-Agent Workflows: These workflows decompose complex queries, progressively accumulate evidence, and synthesize comprehensive answers across documents and modalities.
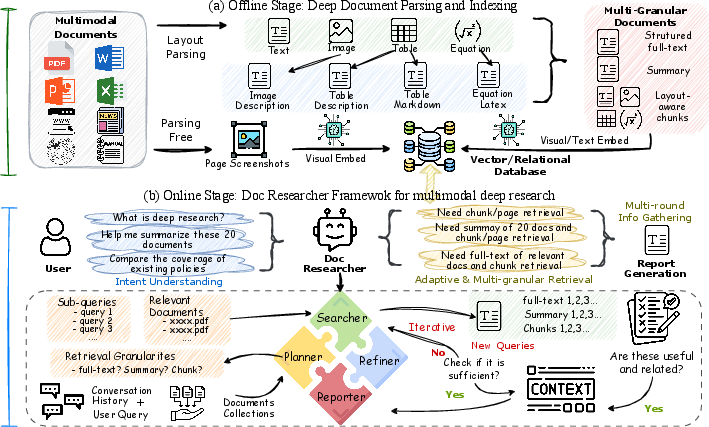
Figure 2: Doc-Researcher Architecture: (a) multimodal deep parsing and indexing, and (b) multimodal deep research.
Evaluation and Benchmarking
To validate the system, the paper introduces M4DocBench, a novel benchmark designed for evaluating multi-modal, multi-hop, multi-document, and multi-turn deep research capabilities. M4DocBench comprises 158 expert-annotated questions across 304 documents, enforcing rigorous testing that existing benchmarks cannot assess.
Experimental Results
The experiments demonstrate that Doc-Researcher achieves a substantial accuracy of 50.6%, which is 3.4 times better than state-of-the-art baselines. This underscores that effective document research requires not just improved retrieval but fundamentally deep parsing to preserve multimodal integrity and support iterative research.
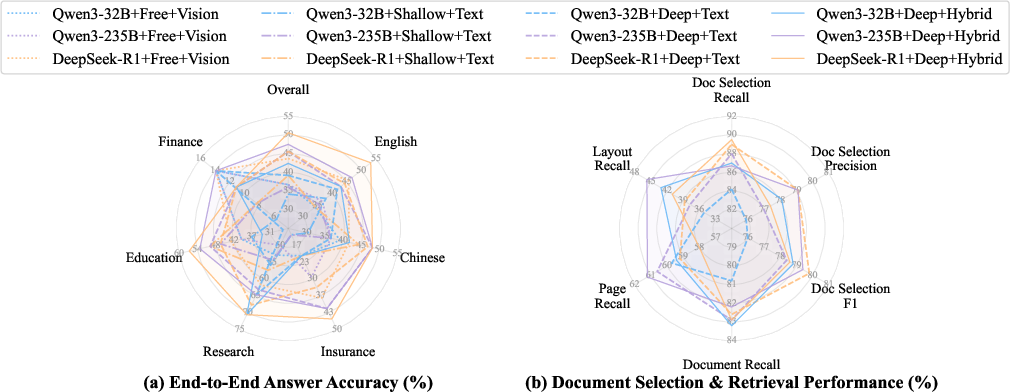
Figure 3: Accuracy and retrieval performance of Doc-Researcher using different backbone LLMs and retrieval schemes.
Doc-Researcher's architecture facilitates efficient learning, large-scale document retrieval, and complex multi-modal query processing, as evidenced by the increased performance metrics compared to existing systems (Figure 4).
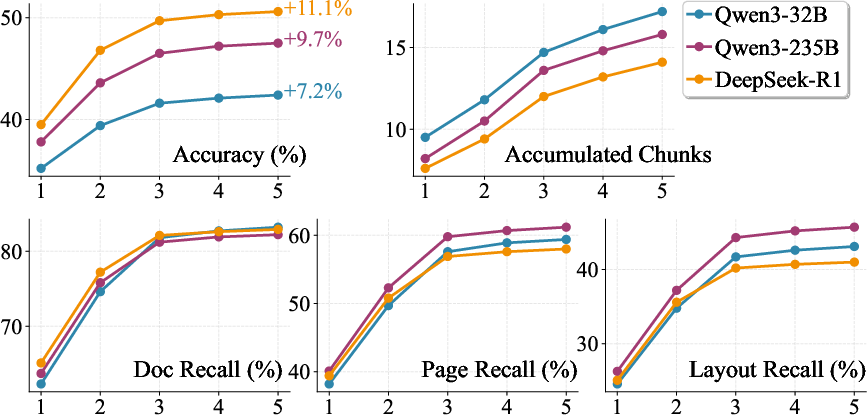
Figure 4: Performance with increasing search depth.
Implications and Future Work
The implications of Doc-Researcher are substantial, establishing a new paradigm for conducting deep research on multimodal document collections. It integrates sophisticated parsing and retrieval systems, proving effective for complex reasoning across multimodal and multi-document scenarios. Future directions include optimizing the system for better cross-modal reasoning mechanisms and developing more compact multimodal embeddings to reduce computational overhead.
Conclusion
In conclusion, Doc-Researcher successfully addresses significant gaps in multimodal document processing systems, providing a robust framework for deep research in complex, multimodal environments. The development of Doc-Researcher marks a pivotal shift towards leveraging LLMs for enhanced document understanding, promising advancements in multimodal research capabilities and setting a benchmark for future systems.