Do Stop Me Now: Detecting Boilerplate Responses with a Single Iteration
Abstract: LLMs often expend significant computational resources generating boilerplate responses, such as refusals, simple acknowledgements and casual greetings, which adds unnecessary cost and latency. To address this inefficiency, we propose a simple yet highly effective method for detecting such responses after only a single generation step. We demonstrate that the log-probability distribution of the first generated token serves as a powerful signal for classifying the nature of the entire subsequent response. Our experiments, conducted across a diverse range of small, large, and reasoning-specialized models, show that the first-token log-probability vectors form distinctly separable clusters for different response types. Using a lightweight k-NN classifier, we achieve high accuracy in predicting whether a response will be a substantive answer or a form of boilerplate response, including user-specified refusals. The primary implication is a practical, computationally trivial technique, optimizing LLM inference by enabling early termination or redirection to a smaller model, thereby yielding significant savings in computational cost. This work presents a direct path toward more efficient and sustainable LLM deployment.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What this paper is about
This paper shows a simple trick to save time, money, and energy when using AI chatbots (LLMs, or LLMs). The idea: you can tell if the AI is about to give a “boilerplate” reply—like a refusal (“I’m sorry, I can’t do that”), a polite greeting (“Hello!”), or a “You’re welcome!”—by looking at just the very first step the AI takes while starting its reply. If you can spot this early, you can stop generation or switch to a smaller, cheaper model, cutting costs without hurting the user’s experience.
The main questions they asked
- Can we predict what kind of full response an AI will give—useful answer vs. boilerplate—after only the first step of generation?
- Is the “first step” signal strong across different types of models (small, large, and reasoning-focused)?
- Can this prediction be done using a tiny, fast classifier that is easy to run in real systems?
How they did it (in plain language)
First, a quick explanation of a few terms they use:
- Token: Think of tokens as word-pieces. A model writes its answer one token at a time (like picking the next puzzle piece).
- Probability of a token: Before picking the next token, the model considers many possible tokens and gives each a probability (how likely it is to choose it).
- Log-probability: A math way to store probabilities that’s easier for computers to work with. You can think of it like a “compressed” measure of how confident the model is.
- k-NN (k-Nearest Neighbors): A very simple classifier. To guess what something is, it looks at the “k” closest examples it has seen before and goes with the majority.
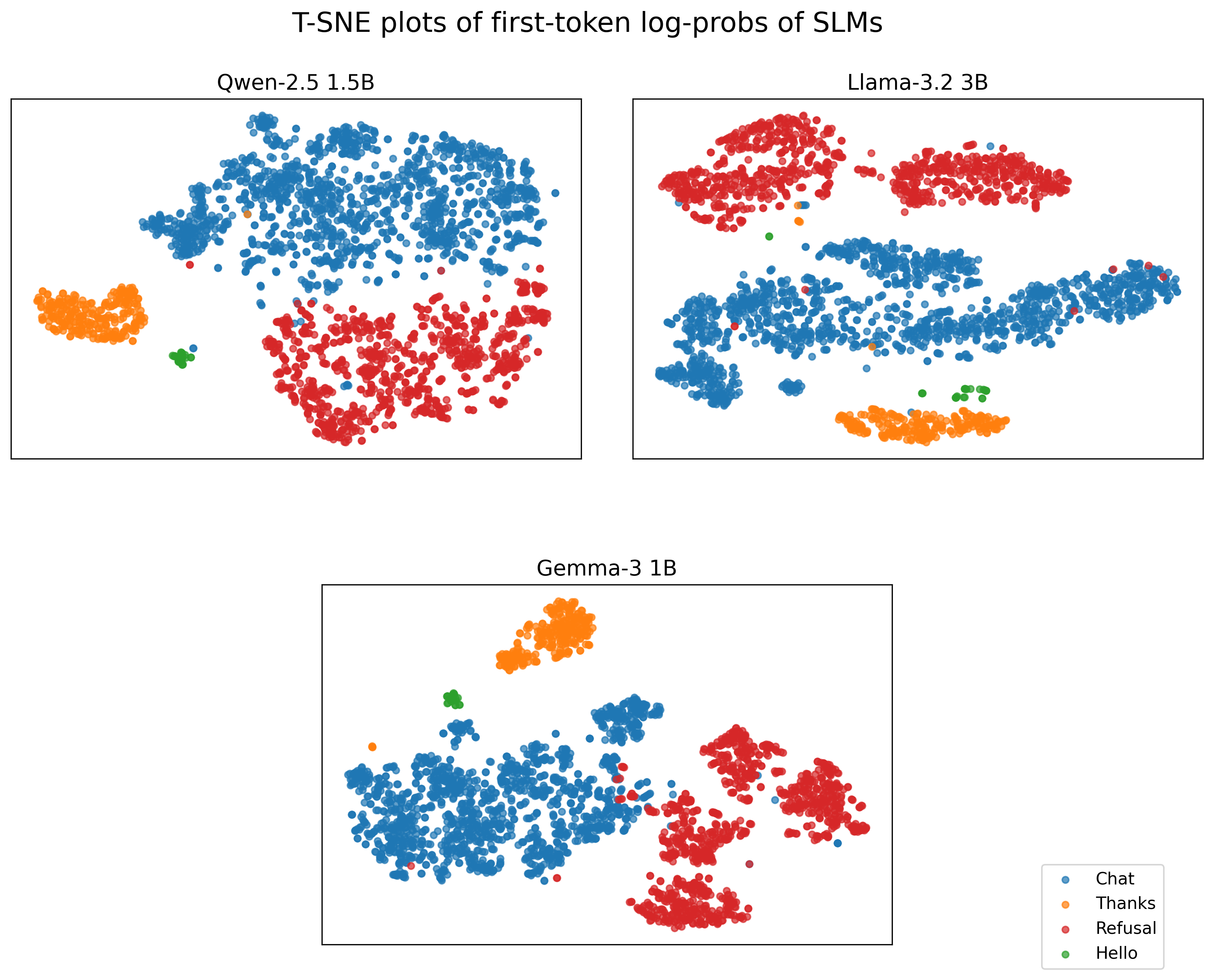
- t-SNE: A way to draw a map of high-dimensional data in 2D so we can see clusters (groups that naturally form).
What they tested:
- The “first-step” idea
- When an AI starts answering, it first assigns probabilities to all possible first tokens. The authors looked only at this one moment.
- Their hunch: that one “probability snapshot” already tells you if the answer will be a refusal, a greeting, a quick “thanks,” or a real, helpful answer—because these types of replies tend to start differently.
- A custom dataset
- They built a dataset of about 3,000 short chats in four categories:
- Refusal: Prompts the model should refuse (like harmful requests) or can’t answer due to missing info.
- Thanks: The user says thanks, triggering “You’re welcome!”-type replies.
- Hello: Greetings like “Hi!” or “Good morning!”
- Chat: Normal questions that should get a real answer.
- They mixed real harmful prompts (for Refusal), instruction prompts (for Chat), added follow-up turns, and also created many “thanks” and “hello” examples to cover boilerplate.
- They built a dataset of about 3,000 short chats in four categories:
- The classifier
- For each chat, they ran the model, gathered the log-probabilities of just the first token the model would generate, and used those numbers as features.
- They drew 2D maps (using t-SNE) to see if different reply types formed separate clusters. They did.
- They trained a tiny k-NN classifier (k=3) on these features and tested it with cross-validation to make sure it generalizes.
- Models they tried
- Small open-source models: Llama 3.2 3B, Qwen 2.5 1.5B, Gemma 3 1B.
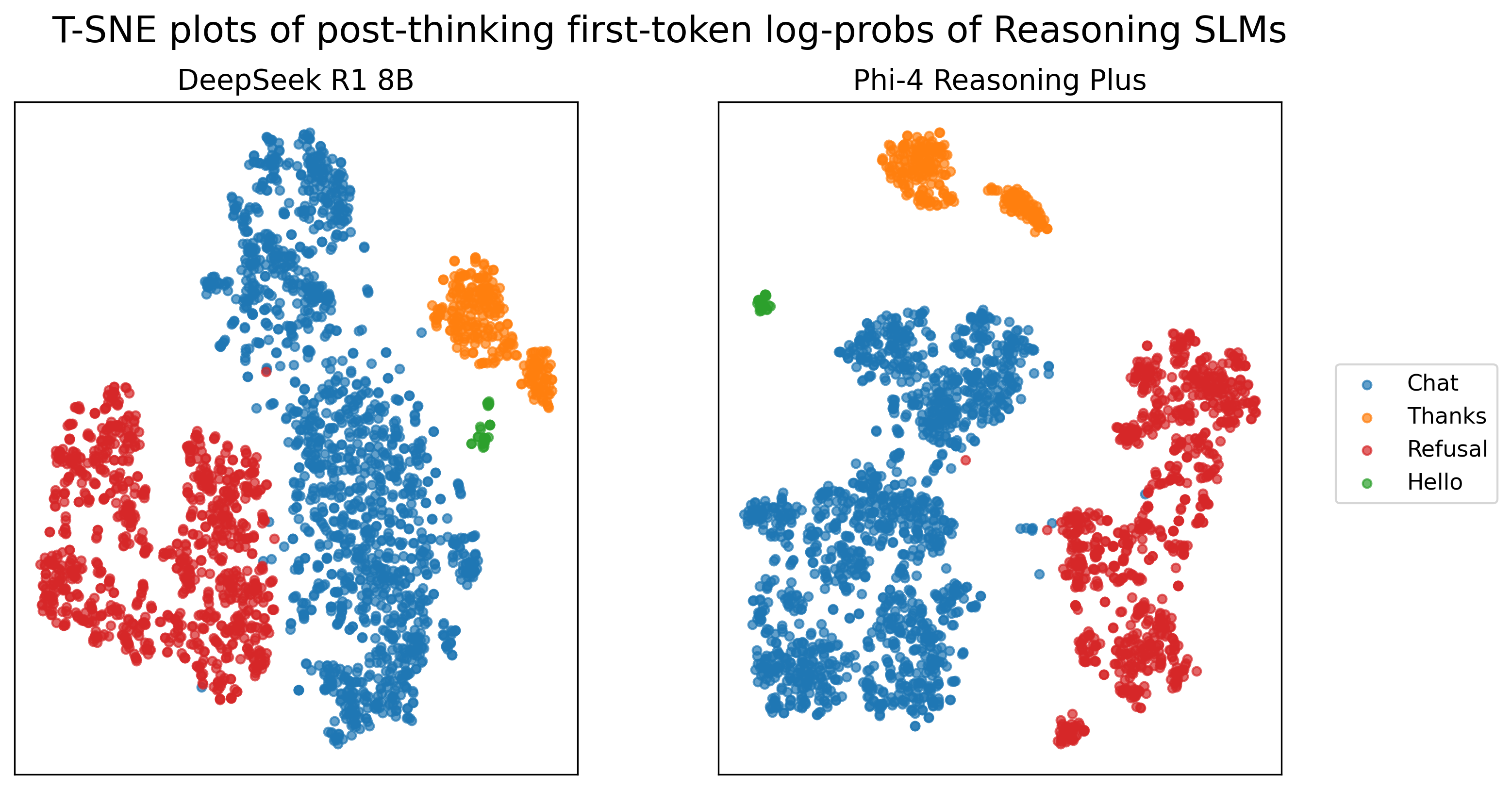
- Reasoning models: DeepSeek-R1 8B, Phi-4 Reasoning Plus. For these, they skipped the “thinking” preface and measured the first token of the actual reply.
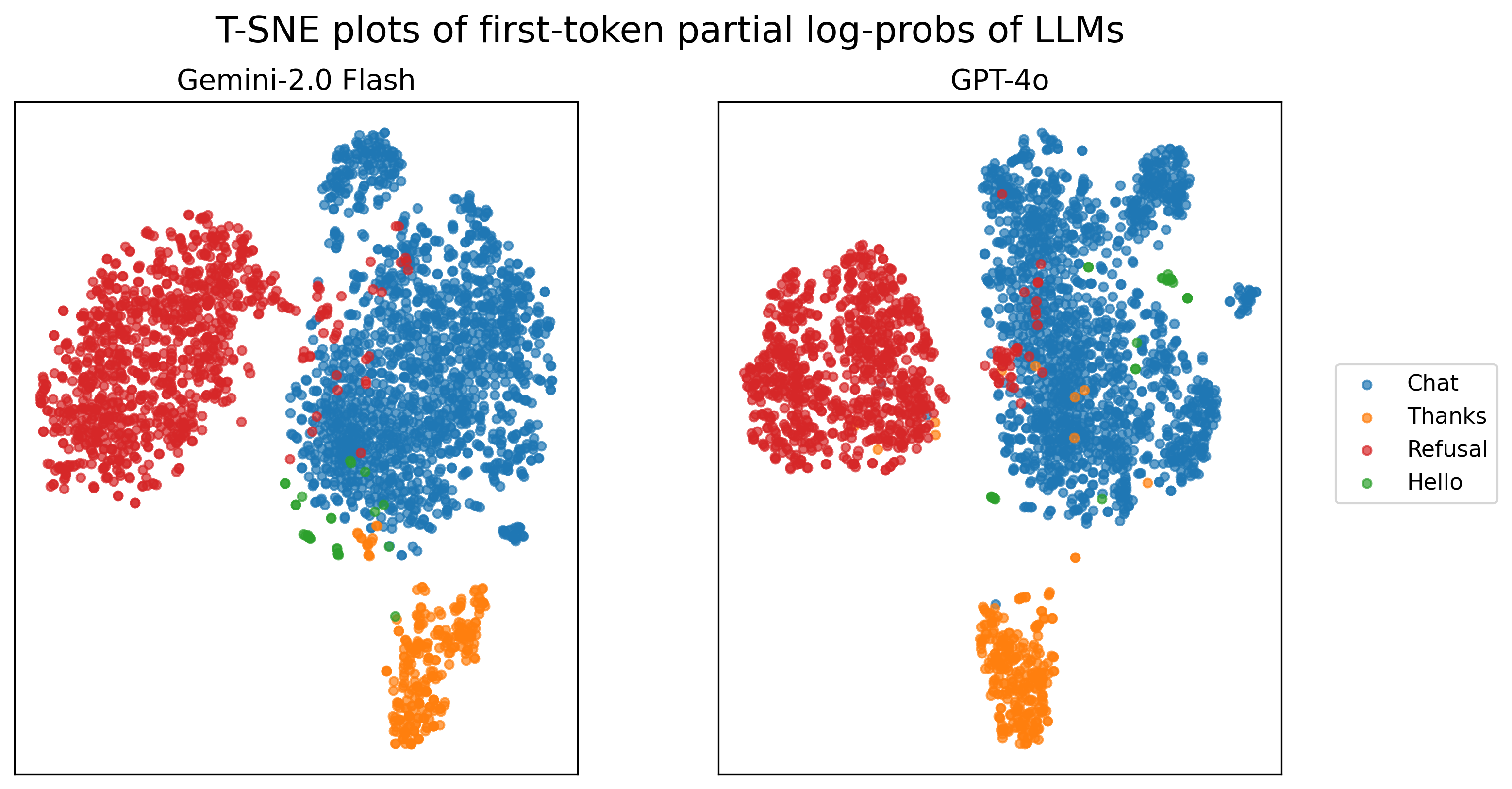
- Large cloud models: GPT-4o and Gemini 2.0 Flash. These only expose probabilities for the top 20 tokens, but the method still worked using this partial information.
What they found and why it matters
- Clear clusters from the first step: The very first token’s probability pattern strongly signals the type of the entire response. On 2D maps, different response types (Refusal, Thanks, Hello, Chat) separate into distinct groups.
- High accuracy with a tiny classifier: A simple k-NN classifier accurately predicts the response type after a single generation step across many models. Accuracy is especially strong for small and reasoning models, and still good for large cloud models even with only top-20 probabilities.
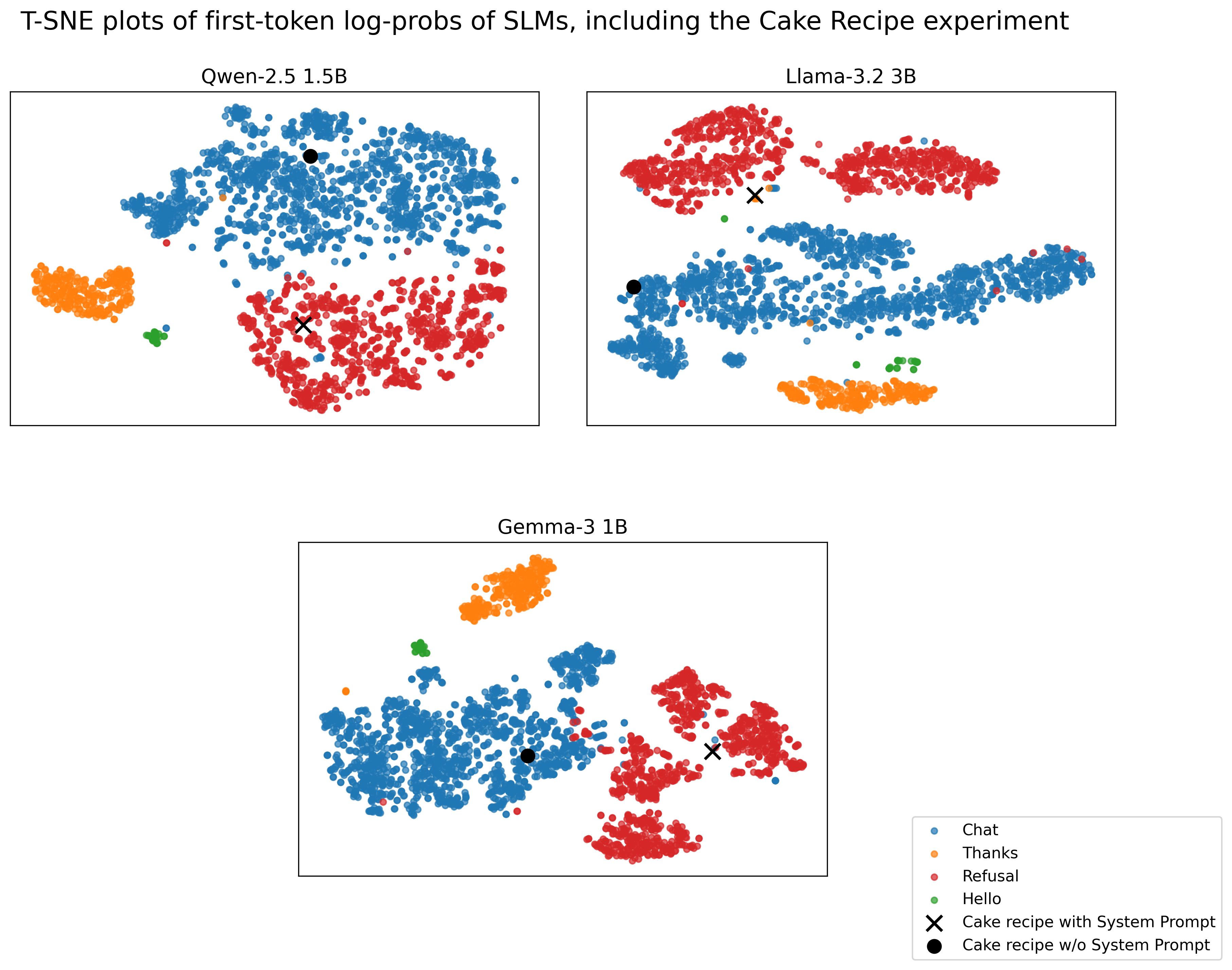
- Works for different kinds of refusals:
- Safety refusals (e.g., “I can’t help with that harmful request”).
- Capability refusals (e.g., missing context, so the model says it can’t do it).
- System-prompt refusals (e.g., the system explicitly says “do not provide this recipe”): the method still detects a likely refusal early.
- Cost and speed benefits: If you detect boilerplate early, you can:
- Stop generation right away.
- Route the request to a smaller, cheaper model better suited for simple replies.
- Cut latency and energy use while keeping users happy.
In short, a fast, low-cost check at the very start can prevent a lot of wasted computation on predictable, non-essential text.
Why this is important
- Saves money and energy: AI companies spend a lot to generate tokens. Cutting back on boilerplate saves real resources and reduces environmental impact.
- Faster responses: Early detection can make apps feel snappier by stopping long, unnecessary outputs.
- Easy to plug in: This uses just the first step’s probabilities and a tiny classifier, so it’s practical for production systems.
- Helps model routing: Systems can quickly decide to hand off simple queries to smaller models and reserve big models for complex tasks.
Final takeaway
The first tiny “hint” the model gives—its probability spread for the very first token—is enough to reliably guess if the whole reply will be useful or just boilerplate. Using this, systems can stop or reroute early, saving time, money, and energy without hurting the user experience. The authors also released their dataset so others can build on this idea and explore more types of boilerplate, different languages, and future multi-modal settings.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, concrete list of gaps that remain unresolved and that future researchers could directly act on.
- Ambiguous dataset size and composition due to LaTeX artifacts (e.g., “0.5ex3k”, “0.5ex500”): clarify exact counts per class and per turn type; publish a clean schema and splits to enable reproducibility.
- Heavy reliance on model-generated and auto-labeled data without human validation: quantify label noise, add human adjudication, and report inter-annotator agreement to ensure ground-truth reliability.
- Narrow definition of “boilerplate” restricted to four coarse classes (Chat, Hello, Thanks, Refusal): develop a broader taxonomy (e.g., disclaimers, hedging, formatting boilerplate, meta-instructions, content warnings, safety caveats, sign-offs) and test detection beyond greetings/thanks/refusals.
- Class imbalance (Hello ≈1.4%) and potential dataset biases (e.g., “Chat with missing context”): perform stratified sampling, report per-class calibration, and run robustness checks to prevent inflated metrics from simple cues.
- Lack of in-the-wild evaluation: assess performance on real product logs across diverse domains to validate generalization beyond curated/bench datasets.
- No cross-model generalization demonstrated: classifiers are trained per-model; investigate universal or transferable representations (e.g., probability-derived features, entropy, cumulative probability mass of top-k) that work across different tokenizers and vocabularies.
- Model update drift unaddressed: test stability across model versions and provider updates; propose adaptation strategies (e.g., continual calibration) to maintain accuracy over time.
- Cloud LLMs only provide top-20 log-probabilities: quantify the impact of truncated distributions on classification accuracy; evaluate sensitivity to different top-k settings and missing non-top tokens.
- Sparse vector reconstruction for closed models is under-specified: detail normalization, handling of unmatched token IDs across models, and vector dimensionality alignment to avoid hidden confounds.
- Reasoning models require artificial “empty thinking” tags: assess applicability when internal thoughts aren’t exposed or are provider-restricted; explore pre-generation or pre-softmax signals that don’t require think tags.
- No systematic study of system-prompt-induced refusals: beyond a single cake recipe example, perform controlled sweeps across refusal categories and policies to measure detection reliability and calibration.
- Mixed responses not addressed (boilerplate lead-in followed by substantive content): measure how often first tokens mislead the classifier; consider multi-token early windows (e.g., first 3–5 tokens) and hybrid decision rules.
- Decoding settings omitted: evaluate robustness to temperature, top-p, nucleus sampling, beam search, and presence of system/assistant formatting templates that can alter first-token distributions.
- Attack surface unexamined: analyze adversarial prompts that manipulate first-token probabilities (e.g., prompt injections that start with content-like tokens); develop defenses and detection of evasion.
- Operational impact not quantified: measure real-world token/time savings, compute cost reduction, and user experience trade-offs (false positives that cut off useful answers, false negatives that let boilerplate through).
- Decision policy and thresholds missing: provide confidence scoring, calibrated probabilities, and termination/redirection policies (e.g., abstain zones) instead of hard k-NN labels.
- Classifier choice not ablated: compare k-NN with logistic regression, calibrated SVM, shallow neural nets, and distance-metric learning; report sensitivity to k, distance metric, and feature scaling.
- Cluster quality not rigorously measured: supplement t-SNE visuals with quantitative metrics (e.g., silhouette score, Davies–Bouldin) and evaluate cluster separability under distribution shift.
- Feature engineering unexplored: test derived features such as entropy, top-1 probability, cumulative mass of boilerplate token sets, or ratio features; compare against hidden-state probes and refusal metrics from prior work.
- Cross-lingual generalization not tested: evaluate the method across multiple languages and scripts; quantify how tokenization and language-specific politeness markers affect first-token signals.
- Multimodal settings left open: assess whether analogous early signals exist for text+image or text+audio models when responses may start with non-text or structured tool outputs.
- Safety and compliance implications unexamined: ensure early termination does not suppress necessary safety warnings or disclaimers; evaluate effects on harm reduction and transparency.
- End-to-end routing pipeline not demonstrated: integrate with small-model fallback, semantic caching, or multi-token prediction and report throughput, latency, and accuracy in a realistic serving stack.
- Reproducibility gaps: release code, exact prompts, system prompts, API parameters (sampling settings, top-k retrieval), t-SNE hyperparameters, seeds, and model versions to enable exact replication.
- Stability across conversation context: study sensitivity to prompt formatting, role labels, preceding turns, and conversation length; determine whether context-specific first-token biases degrade detection.
- Granular refusal types not distinguished (safeguards vs incapability): provide a labeled breakdown and per-type metrics; analyze whether different refusal causes have distinct probability signatures.
- Handling of partial or streaming generation not evaluated: measure how early in the stream reliable detection is possible and the trade-offs between speed and accuracy.
- Cost of the classifier itself overlooked: quantify k-NN overhead at scale (memory/latency on large reference sets) and compare against lightweight parametric alternatives or on-the-fly calibration.
Practical Applications
Immediate Applications
The following applications can be deployed now using the paper’s method of classifying response types from the first-token log-probability vectors and lightweight k-NN inference.
- Boilerplate suppression at inference (API-level)
- Sectors: software, cloud, energy
- Use case: Add a “boilerplate suppression” toggle to LLM APIs that aborts generation when the first-token signal predicts a refusal, greeting, or simple acknowledgement, or replaces it with a compact template.
- Tools/products/workflows: Per-model k-NN classifier over first-token log-probabilities; small template library for common boilerplate; API parameter to return a structured status (e.g.,
{class: "thanks", action: "template"}). - Assumptions/dependencies: Access to token log-probabilities (or top-k) at the first generation step; classifier must be trained per model since token spaces differ; clear UX to avoid perceived rudeness.
- Cost-aware model routing and early termination in orchestration
- Sectors: software, MLOps
- Use case: In LangChain, LlamaIndex, vLLM, or custom inference servers, detect boilerplate and route the request to a cheaper model or a rule-based template; terminate long generations early.
- Tools/products/workflows: Middleware that reads first-token log-probabilities, runs a k-NN classifier, and triggers routing/termination logic; policy rules (e.g., suppress “hello” and “you’re welcome”).
- Assumptions/dependencies: Minimal latency overhead; safe defaults for edge cases; per-model calibration and thresholds.
- Semantic cache synergy for repetitive boilerplate
- Sectors: software, cloud
- Use case: Combine detection with semantic caching so that common acknowledgements and greetings are served from cache or templates without full generation.
- Tools/products/workflows: Embed-based cache (e.g., GPT Semantic Cache) plus early boilerplate detection; deduped courtesy responses.
- Assumptions/dependencies: Reliable cache hit strategy; cache invalidation rules; consistent brand style in templates.
- Contact center and CX chatbots: accelerate useful turns
- Sectors: customer support, enterprise software
- Use case: Skip generating non-essential pleasantries or long refusals to improve first-response time and throughput; optionally compress refusals to one line.
- Tools/products/workflows: CX bot plugin that implements first-token detection and short templates; analytics to monitor customer sentiment impacts.
- Assumptions/dependencies: Politeness standards vary; A/B testing required; avoid suppressing legally required notices or empathy lines.
- Edge/mobile assistants “concise mode”
- Sectors: robotics, consumer devices, energy
- Use case: On-device assistants suppress boilerplate to save battery and reduce latency; offer a user-configurable politeness level.
- Tools/products/workflows: Lightweight on-device k-NN; a setting in voice assistant apps; short audio templates for “hello”/“thanks.”
- Assumptions/dependencies: Access to local log-probabilities; privacy policy alignment; user acceptability of reduced niceties.
- Analytics and prompt hygiene
- Sectors: industry, academia
- Use case: Instrument systems to log predicted response type at the first token, quantify boilerplate share, and optimize prompts/system instructions to reduce waste.
- Tools/products/workflows: Dashboards with boilerplate-rate metrics; integration with A/B testing of prompt variants; use the released dataset for benchmarking.
- Assumptions/dependencies: Governance for logging; dataset/domain coverage; organizational buy-in to modify prompt practices.
- Safety and guardrail monitoring
- Sectors: policy, trust & safety
- Use case: Detect imminent refusals (policy-triggered or incapability) at the first token and route to human review or alternative workflows; calibrate refusal rates without retraining.
- Tools/products/workflows: Rules for refusal class handling (e.g., show a helpful rephrase or follow-up question); logs for auditability of refusals by type.
- Assumptions/dependencies: False positive/negative balance; per-domain refusal taxonomy; sensitivity to system prompts.
- Education assistants: trim filler, keep substance
- Sectors: education
- Use case: Classroom assistants suppress “meta talk” and greetings; streamline Q&A to focus on explanations and steps.
- Tools/products/workflows: LMS plugins with early detection; templates for brief acknowledgements; teacher-configurable politeness settings.
- Assumptions/dependencies: Age-appropriate tone; cultural norms; ensure that “meta” reasoning isn’t mistakenly suppressed when pedagogically useful.
- Healthcare documentation workflows
- Sectors: healthcare
- Use case: Replace standard disclaimers and acknowledgements with pre-approved templates when detected; reduce token and compliance overhead.
- Tools/products/workflows: EHR-integrated boilerplate library; early detection to swap in mandated phrasing; latency-sensitive dictation tools.
- Assumptions/dependencies: Regulatory compliance (HIPAA, local laws); don’t suppress clinically relevant safety language; robust approvals.
- Financial assistants and trading tools
- Sectors: finance
- Use case: Suppress courtesy and format boilerplate in market updates; reduce decision latency in time-critical workflows.
- Tools/products/workflows: Integration with trading bots; concise templates; confidence gating combined with early detection.
- Assumptions/dependencies: Risk management; logging; ensure no suppression of material risk disclosures.
Long-Term Applications
The following applications require further research, scaling, standardization, or integration beyond the proof-of-concept.
- Multilingual and multimodal generalization
- Sectors: software, robotics
- Use case: Extend first-token detection to non-English languages and multimodal assistants (speech, vision) to catch filler in real-time interactions.
- Tools/products/workflows: Multilingual datasets; alignment across tokenizers; speech-act mapping for ASR outputs.
- Assumptions/dependencies: Per-language calibration; availability of log-probabilities in multimodal APIs; varied politeness norms.
- Standardized benchmarks and open-source libraries
- Sectors: academia, open-source
- Use case: Community library for first-token classifiers; shared benchmarks using the released dataset plus domain-specific corpora.
- Tools/products/workflows: Model-agnostic wrappers; evaluation suites; leaderboards of boilerplate detection accuracy.
- Assumptions/dependencies: Broad dataset coverage; contributors across models; maintenance of API adapters for closed models (top-k only).
- Training-time integration (gated generation)
- Sectors: software
- Use case: Train or fine-tune models to emit stronger early signals (e.g., refusal tokens) or learn gating to minimize boilerplate proactively.
- Tools/products/workflows: Combine with refusal tokens and single-direction metrics; distill gating into smaller heads; reinforcement learning for concise responses.
- Assumptions/dependencies: Access to training pipeline; potential trade-offs with user experience and alignment; careful calibration.
- Beyond boilerplate: early quality and risk prediction
- Sectors: healthcare, finance, enterprise software
- Use case: Use early signals (first token or hidden states) to predict answer length, confidence, hallucination risk, or reasoning depth; abort or reroute low-quality generations.
- Tools/products/workflows: Probing classifiers over pre-generation hidden representations; integration with TRAIL-like schedulers.
- Assumptions/dependencies: Robust labels for confidence/hallucination; domain-specific thresholds; guardrails against premature aborting of correct but long answers.
- Compute-aware schedulers and sustainability reporting
- Sectors: cloud, energy, policy
- Use case: Fleet-level schedulers that avoid wasting GPU cycles on boilerplate; standardized reporting of “tokens saved” and energy reductions.
- Tools/products/workflows: Orchestrators that prioritize substantive generations; dashboards showing environmental impact; SLAs tied to efficiency.
- Assumptions/dependencies: Accurate detection at scale; integration with billing/telemetry; regulatory-ready metrics.
- Regulatory and compliance frameworks for courtesy suppression
- Sectors: policy, compliance
- Use case: Guidelines for when and how to suppress politeness phrases and refusals; audit trails for consistency and fairness.
- Tools/products/workflows: Policy checklists; consent settings; audit logs of detection decisions; localization of standards.
- Assumptions/dependencies: Stakeholder input (users, regulators); sensitivity to cultural norms; documentation and transparency.
- Personalized politeness and tone controls
- Sectors: consumer apps, enterprise
- Use case: User or organization-level profiles that set politeness/tone preferences; dynamic balancing of brevity vs. warmth.
- Tools/products/workflows: Preference models; adaptive thresholds; brand style templates tied to detection outputs.
- Assumptions/dependencies: Accurate preference capture; testing for satisfaction; safeguards to prevent exclusionary tone.
- Real-time voice assistants and human-robot interaction
- Sectors: robotics, consumer devices
- Use case: Millisecond-level suppression of filler speech; faster turn-taking; improved perceived responsiveness.
- Tools/products/workflows: Streaming log-probabilities for TTS/ASR loops; prosody-aware templates; duplex conversation management.
- Assumptions/dependencies: Low-latency access to probabilities; speech safety disclaimers; error recovery strategies.
- Security and jailbreak response routing
- Sectors: trust & safety, security
- Use case: Detect interactions likely to elicit refusals (or policy violations) and route to hardened models or human oversight; flag suspicious flows early.
- Tools/products/workflows: Risk-based routers; anomaly detection layered with first-token classification; incident logs.
- Assumptions/dependencies: Labels for risky intents; false-positive control; coordination with broader moderation systems.
- Economic models and pricing tiers
- Sectors: cloud, SaaS
- Use case: Offer “efficiency tiers” where boilerplate suppression reduces cost per request; pass savings to customers.
- Tools/products/workflows: Usage metering of saved tokens; billing integration; marketing of sustainability benefits.
- Assumptions/dependencies: Transparent measurement; customer acceptance; fairness across workloads.
Glossary
- AdvBench dataset: A benchmark of harmful prompts used to evaluate adversarial robustness and refusal behavior in aligned LLMs. "We use the AdvBench dataset, containing harmful prompts, and classify these as Refusal."
- Alpaca dataset: An instruction-following dataset used to create chat prompts, often with minimal or no additional context. "We then sampled 0.5ex500 random prompts from the Alpaca dataset, and classify these as Chat."
- BERT models: Pre-trained bidirectional transformer models commonly used for downstream classification and probing tasks. "others employing separate lightweight LLMs or BERT models for length prediction"
- boilerplate responses: Standardized, non-substantive outputs (e.g., refusals, acknowledgements, greetings) that add cost without solving the task. "LLMs often expend significant computational resources generating boilerplate responses"
- center-of-mass: The average point of a cluster used informally to denote its geometric center in a visualization. "the first token log-probabilities are closer to the Refusal class center-of-mass."
- Dialogue Act Classification (DAC): The task of identifying the communicative intent behind utterances in conversation. "In conversational settings, Dialogue Act Classification (DAC) identifies the communicative intent behind utterances"
- early generation stages: The initial steps of token generation where early signals (e.g., refusal likelihood) can be measured. "at early generation stages"
- Early termination: Halting generation as soon as an outcome is predicted to avoid unnecessary computation and cost. "enabling early termination or redirection to a smaller model"
- Emergent response planning: A phenomenon where internal hidden representations encode global attributes of a future response before tokens are generated. "A foundational concept in this area is emergent response planning"
- exact answer tokens: Specific tokens within a generated response that encode concentrated truthfulness or correctness information. "truthfulness information is concentrated in 'exact answer tokens' within the generated response"
- first-token log-probability embeddings: The vector of log-probabilities over the vocabulary for the first generated token, used as an embedding for classification. "we trained k-Nearest Neighbors (k-NN) classifiers on the first-token log-probability embeddings for each model category."
- GPT Semantic Cache: A semantic caching mechanism that uses embeddings to reduce cost and latency by reusing responses to similar queries. "Semantic caching mechanisms, such as GPT Semantic Cache, leverage query embeddings to identify semantically similar questions and retrieve pre-generated responses"
- hallucinations: Instances where an LLM generates incorrect or fabricated information that appears plausible. "Studies on LLM hallucinations indicate that truthfulness information is concentrated in 'exact answer tokens'"
- k-Nearest Neighbors (k-NN): A non-parametric classifier that predicts labels based on the majority class among the k closest points. "we trained k-Nearest Neighbors (k-NN) classifiers on the first-token log-probability embeddings"
- LLM inference: The process of running an LLM to produce outputs, typically incurring computational and financial cost. "optimizing LLM inference by enabling early termination or redirection to a smaller model"
- log-probability distribution: The distribution of log probabilities assigned to possible next tokens, capturing model uncertainty and preferences. "We demonstrate that the log-probability distribution of the first generated token serves as a powerful signal"
- macro-averaged precision, recall, and F1-score: Metrics averaged equally across classes to account for imbalance, providing class-agnostic performance. "We report macro-averaged precision, recall, and F1-score"
- model routing: Directing prompts to different models (e.g., smaller ones for trivial tasks) to reduce cost while maintaining quality. "Another approach is to use model routing, sending simpler prompts (such as those leading to boilerplate responses) to a smaller, cheaper model"
- multi-token prediction: Techniques that predict multiple subsequent tokens in a single inference step to accelerate generation. "advancements in multi-token prediction enable LLMs to jointly predict several subsequent tokens in a single inference step"
- probing classifiers: Classifiers trained on internal model representations to infer properties like error likelihood or response characteristics. "Probing classifiers trained on intermediate representations of these tokens can predict errors"
- Reasoning models: LLMs optimized for step-by-step reasoning, often employing explicit thinking phases. "The examination of reasoning models adds a bit more complexity"
- Refusal Tokens: Special tokens introduced during training that the model learns to emit first when refusing, enabling calibrated control. "The Refusal Tokens strategy proposes prepending a special [refuse] token (or category-specific tokens) to responses during training"
- refusal metric: A scalar indicator of refusal likelihood derived from probabilities of refusal-related tokens at early positions. "This allows for the derivation of a 'refusal metric' by summing the probabilities assigned to a predefined set of 'refusal tokens'"
- refusal tokens: Phrases or tokens associated with refusals (e.g., “I'm sorry”, “I cannot”) used to estimate refusal likelihood. "a predefined set of 'refusal tokens' (e.g., 'I'm sorry', 'I cannot')"
- residual stream activations: Internal transformer representations accumulated via residual connections, which can encode behavior in low-dimensional subspaces. "refusal behavior in LLMs is mediated by a one-dimensional subspace within their residual stream activations"
- semantic caching: Reuse of responses for semantically similar queries identified via embeddings, reducing repeated computation. "Semantic caching mechanisms, such as GPT Semantic Cache, leverage query embeddings to identify semantically similar questions and retrieve pre-generated responses"
- Shuffle-Aware Discriminator (SHAD): A discriminator that distinguishes boilerplate from reasoning tokens by exploiting predictability after shuffling input-output pairs. "The Shuffle-Aware Discriminator (SHAD) offers an automated and adaptive solution by exploiting predictability differences after shuffling input-output combinations"
- softmax probability: The normalized probability obtained by applying softmax to logits over the vocabulary. "At test-time, the softmax probability of this refusal token quantifies the likelihood of a refusal"
- stratified cross-validation: A cross-validation method that maintains class proportions across folds to yield robust, unbiased evaluation. "we performed 5-fold stratified cross-validation"
- system prompt: A controlling instruction provided to the assistant that imposes constraints or behavior. "with a system prompt explicitly stating that the assistant cannot provide a recipe for a Black Forest Cake"
- t-SNE: A nonlinear dimensionality reduction method used to visualize high-dimensional data as 2D clusters. "We visualize the results using 2D t-SNE"
- thinking phase: An initial, internal reasoning stage where models self-explain or plan before producing visible tokens. "they tend to begin with a thinking phase which includes self-explaining and 'self-talking'"
- tiktoken: A tokenizer library used to map token strings to their numerical IDs for OpenAI models. "For GPT-4o, we used tiktoken to retrieve the token IDs from the token string-values"
- token IDs: Numerical identifiers for tokens in a model’s vocabulary used to reconstruct or analyze probability vectors. "provide both the log-probability and token IDs (token indices) of the top 20 tokens."
- token-probability-space: The high-dimensional space formed by token probability distributions, often model-specific and not directly comparable. "as the token-probability-space is not comparable between different models."
- TRAIL: A method that leverages recycled LLM layer embeddings to predict remaining output length with low overhead. "methods like TRAIL leverage recycled LLM layer embeddings to dynamically predict remaining output length"
- zero-shot: Performing a task without task-specific labeled training data, relying on generalization. "LLMs exhibit zero-shot DAC capabilities"
Collections
Sign up for free to add this paper to one or more collections.