- The paper demonstrates a novel method for controllable dimensionality reduction by integrating generalized Gromov–Wasserstein optimal transport with dual conditional flow matching.
- It employs a U-Net based drift network to facilitate bidirectional mappings, achieving superior reconstruction and embedding quality compared to PCA, VAE, and diffusion autoencoders.
- Empirical evaluations on MNIST, CIFAR-10, TinyImageNet, AFHQ, and QM9 illustrate CPFM’s robustness in preserving semantic structure and enabling high-fidelity reconstructions.
Coupled Flow Matching: Controllable Dimensionality Reduction via Dual Conditional Flows
Overview and Motivation
Coupled Flow Matching (CPFM) introduces a principled framework for controllable dimensionality reduction and high-fidelity reconstruction, leveraging advances in optimal transport (OT) and flow-based generative modeling. The method addresses the inherent limitations of classical dimension reduction techniques—such as PCA, t-SNE, and UMAP—which are non-invertible and often discard information irrecoverably. CPFM enables explicit control over which semantic factors are retained in the low-dimensional embedding, while ensuring that residual information remains recoverable through a learned flow network. This is achieved by integrating a generalized Gromov–Wasserstein OT objective with a dual conditional flow-matching architecture, facilitating bidirectional mappings between high-dimensional data x and low-dimensional embeddings y.
Figure 1: An overview of coupled flow matching.
Generalized Gromov–Wasserstein Optimal Transport
The first stage of CPFM constructs a probabilistic correspondence between data samples and embeddings using a kernelized quadratic OT objective. Unlike standard GWOT, which relies solely on Euclidean distances, the generalized formulation incorporates user-specified kernels to encode semantic priors, relational structure, or label information. The transport cost is defined as:
π∈Π(μX,μY)inf∬X2×Y2k(x,x′)∥y−y′∥2dπ(x,y)dπ(x′,y′)
where k(x,x′) is a symmetric kernel capturing domain-specific structure. This enables targeted submanifold design and improved interpretability of the embedding space.
Optimization is performed via an alternating minimization algorithm for an entropy-regularized version of GWOT, with per-iteration complexity O(n2). The algorithm leverages a variational reformulation, introducing an auxiliary variable A to linearize the quadratic coupling, and employs Sinkhorn iterations for efficient computation. An adaptive ε-scheduling scheme is used to balance convergence speed and numerical stability.

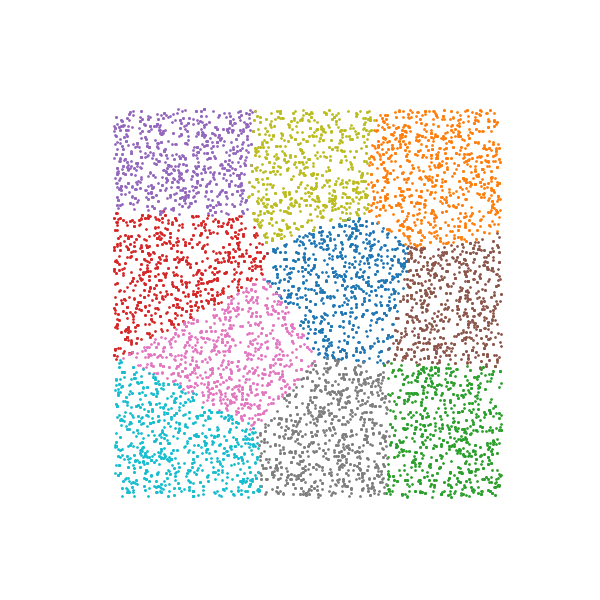
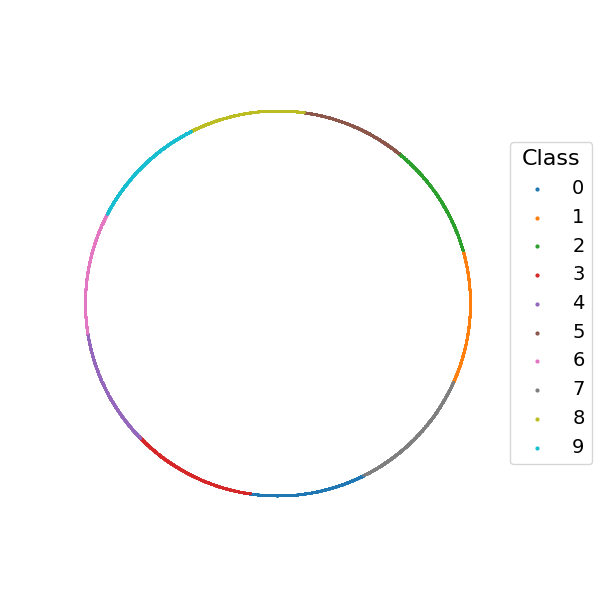
Figure 2: Based on the generalized GWOT transport plan π, each source sample x is associated with a probability distribution over candidate embeddings y.
Dual Conditional Flow Matching
The second stage extrapolates the discrete OT coupling to the entire joint space via Dual Conditional Flow Matching (DCFM). DCFM trains a shared drift network uθ with dual conditioning: given x, it predicts flows on y to sample p(y∣x); given y, it predicts flows on x to sample p(x∣y). The network architecture employs a U-Net backbone with time and embedding conditioning, and two output heads selected by a role flag.
Training alternates between the two conditional objectives, using a mute-masking strategy to ensure only the active direction contributes to the loss. The combined loss admits a solution that simultaneously approximates both conditional flows, enabling bidirectional sampling and reconstruction.
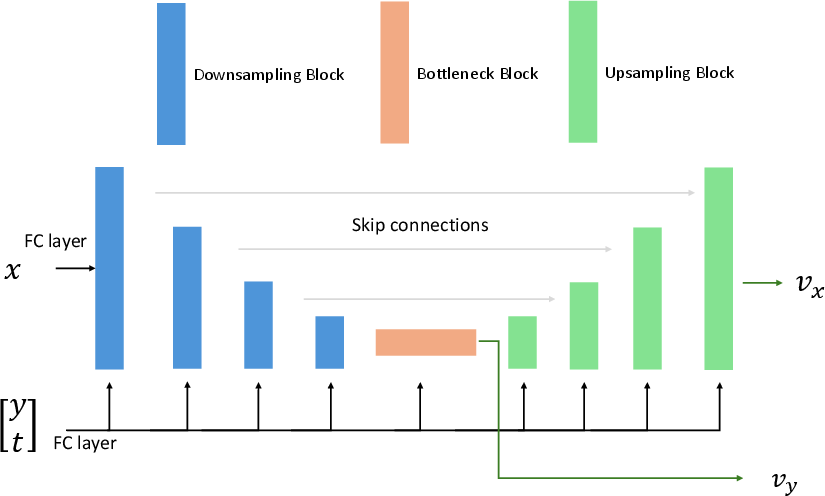
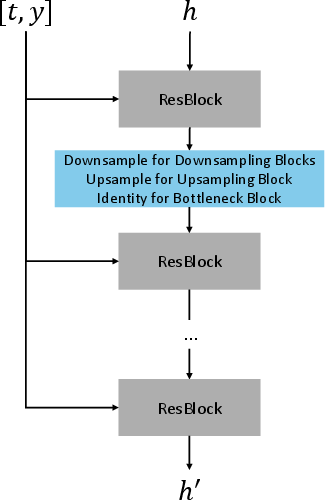
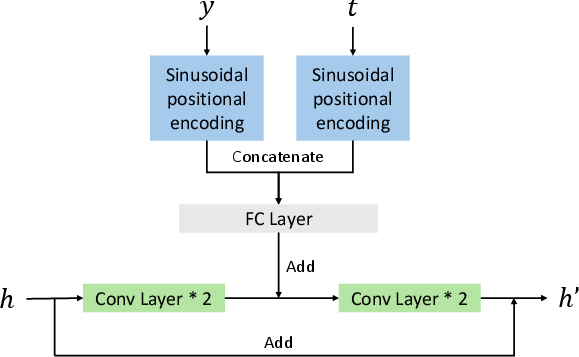
Figure 3: U-Net backbone.
Empirical Evaluation
MNIST
On MNIST, CPFM utilizes a composite kernel integrating pixel-level similarity and label information. The resulting embeddings in R2 exhibit well-separated clusters for each digit class, and reconstructions from the latent space preserve class identity and handwriting style diversity.

Figure 4: The MNIST dataset compressed into two dimensions by DCFM, where different classes are distinguished by labels and then reconstructed.
CIFAR-10, TinyImageNet, AFHQ
CPFM is evaluated on CIFAR-10, TinyImageNet, and AFHQ, with the latent space restricted to two dimensions. Quantitative metrics include Wasserstein distance to Gaussian and GWOT loss. CPFM consistently achieves the lowest scores, outperforming KPCA, VAE, DiffAE, and Info-Diffusion baselines, even under extreme compression.
QM9 Molecule Generation
On QM9, CPFM employs a kernel combining Tanimoto similarity and dipole moment differences. The learned embeddings align smoothly with molecular properties, and reconstructions preserve atomic composition and topology, demonstrating chemically meaningful bidirectional mappings.
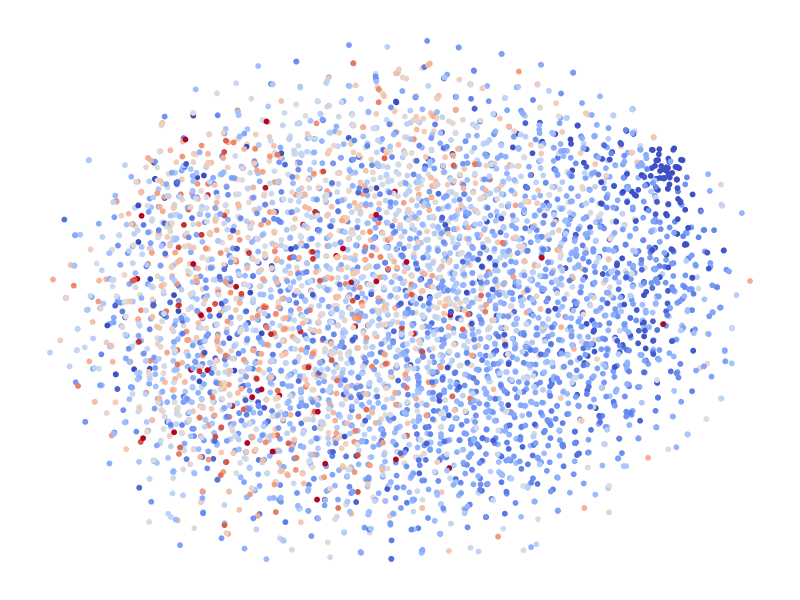
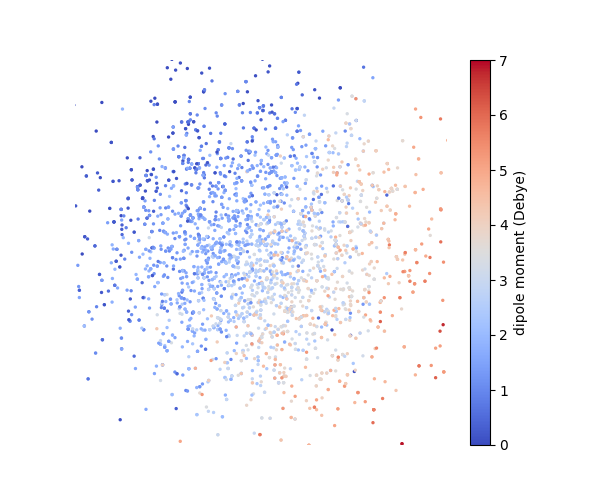
Figure 5: (Left) t-SNE visualization of the VAE latent space, where the labels do not show a clear separation. (Right) Embedding obtained from generalized GWOT, where the molecular embeddings vary continuously in label.
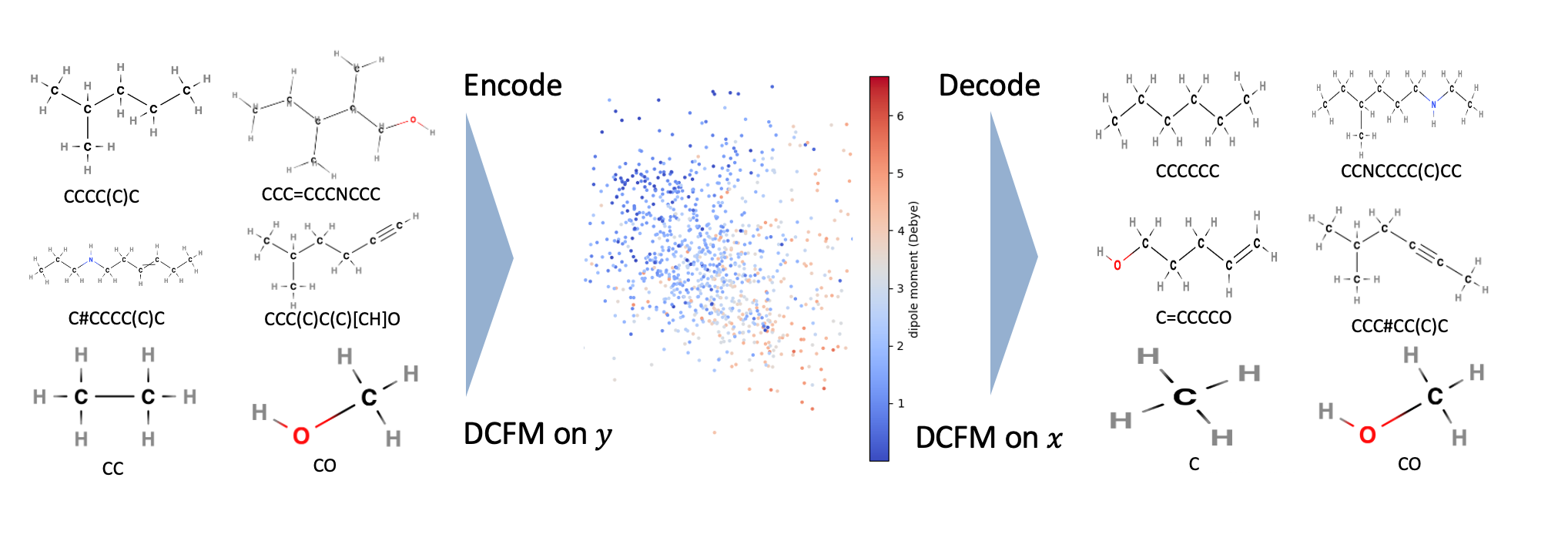
Figure 6: The QM9 dataset compressed into two dimensions by DCFM and then reconstructed.
Implementation Details and Trade-offs
- Computational Complexity: The alternating minimization for GWOT scales as O(n2) per iteration, with practical feasibility up to n∼104 via subsampling and interpolation.
- Network Architecture: The U-Net backbone with dual heads enables parameter sharing and efficient training, but high-resolution datasets remain computationally intensive.
- Controllability: The kernelized OT objective allows explicit encoding of semantic priors, supporting user-driven design of the latent space.
- Bidirectional Sampling: DCFM provides high-fidelity reconstruction and generative diversity, outperforming invertible kernel PCA and diffusion autoencoders in both embedding quality and sample reconstruction.
Limitations and Future Directions
While CPFM demonstrates strong performance in both dimension reduction and reconstruction, training dual conditional flows from scratch is resource-intensive for large-scale or high-resolution data. Future work may explore multi-scale architectures, more efficient OT solvers, and extensions to trans-dimensional or multimodal generative modeling. The framework's flexibility in encoding domain knowledge via kernels suggests potential for broader applications in scientific data analysis, cross-modal generation, and interpretable representation learning.
Conclusion
Coupled Flow Matching provides a rigorous and flexible approach to controllable dimensionality reduction, integrating kernelized optimal transport with dual conditional flow matching. The method achieves semantically rich, interpretable embeddings and high-fidelity reconstructions, with empirical superiority over existing baselines. Its design principles—explicit controllability, bidirectional mapping, and kernelized priors—offer a foundation for future advances in generative modeling and representation learning.