- The paper presents a dual-branch CNN that combines spatial (RGB) and frequency-domain features via a channel attention module for enhanced detection of facial forgeries.
- It employs a composite FSC loss integrating focal, supervised contrastive, and frequency center margin losses to boost feature discriminability and mitigate class imbalance.
- Experimental results on the DiFF benchmark demonstrate near-perfect in-domain accuracy and superior cross-domain performance compared to human evaluators.
Dual-Branch CNNs for Robust Detection of AI-Generated Facial Forgeries
Introduction
The proliferation of high-fidelity generative models, particularly diffusion-based architectures, has significantly increased the realism and diversity of facial forgeries. These advances have rendered traditional detection methods—reliant on spatial or handcrafted features—insufficient, especially as diffusion models produce forgeries with minimal low-level artifacts. The paper "A Dual-Branch CNN for Robust Detection of AI-Generated Facial Forgeries" (2510.24640) addresses this challenge by proposing a dual-branch convolutional neural network (CNN) that integrates spatial and frequency-domain cues, augmented by a channel attention mechanism and a composite loss function (FSC Loss) to enhance discriminative feature learning and generalization.
Diffusion-Based Facial Forgery Generation Pipelines
The DiFF benchmark, central to this work, encompasses four representative forgery generation paradigms: text-to-image (T2I), image-to-image (I2I), face swap (FS), and face edit (FE). Each pipeline leverages diffusion models but targets distinct manipulation objectives, from synthesizing entirely new identities to subtle attribute modifications.
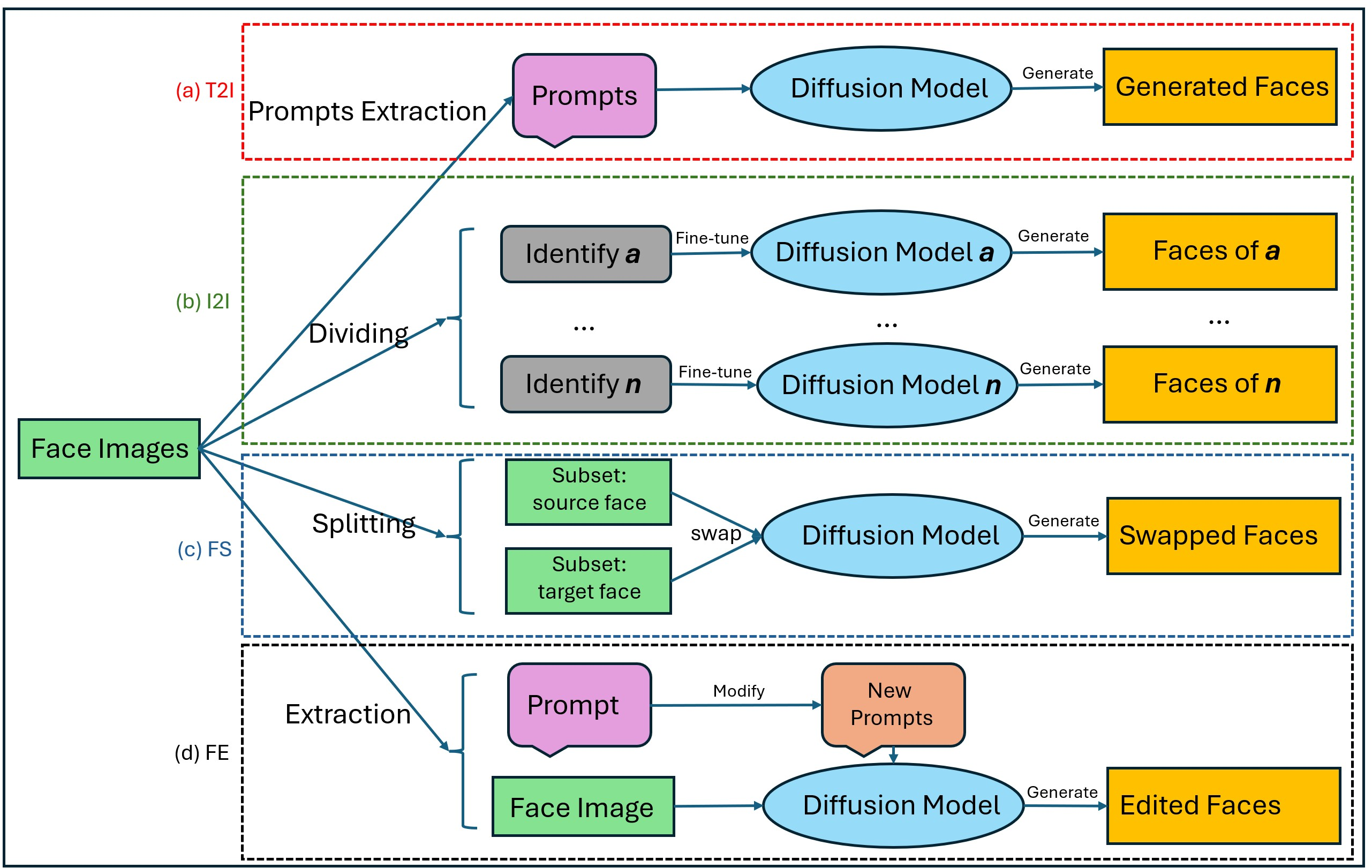
Figure 1: Four diffusion-based facial forgery pipelines: (a) T2I, (b) I2I, (c) FS, and (d) FE, illustrating the diversity and complexity of modern facial manipulations.
The diversity of these pipelines underscores the necessity for detection models that are robust to both overt and subtle manipulations, as well as capable of generalizing across manipulation types.
Dual-Branch Detection Architecture
The proposed detection framework employs a dual-branch architecture, with one branch dedicated to spatial (RGB) features and the other to frequency-domain features. The RGB branch utilizes a ResNet-50 backbone, while the frequency branch processes the log-magnitude spectrum (via FFT) of the grayscale image through a ResNet-34. The outputs are concatenated and refined by a channel attention module, which adaptively emphasizes informative channels before final classification.
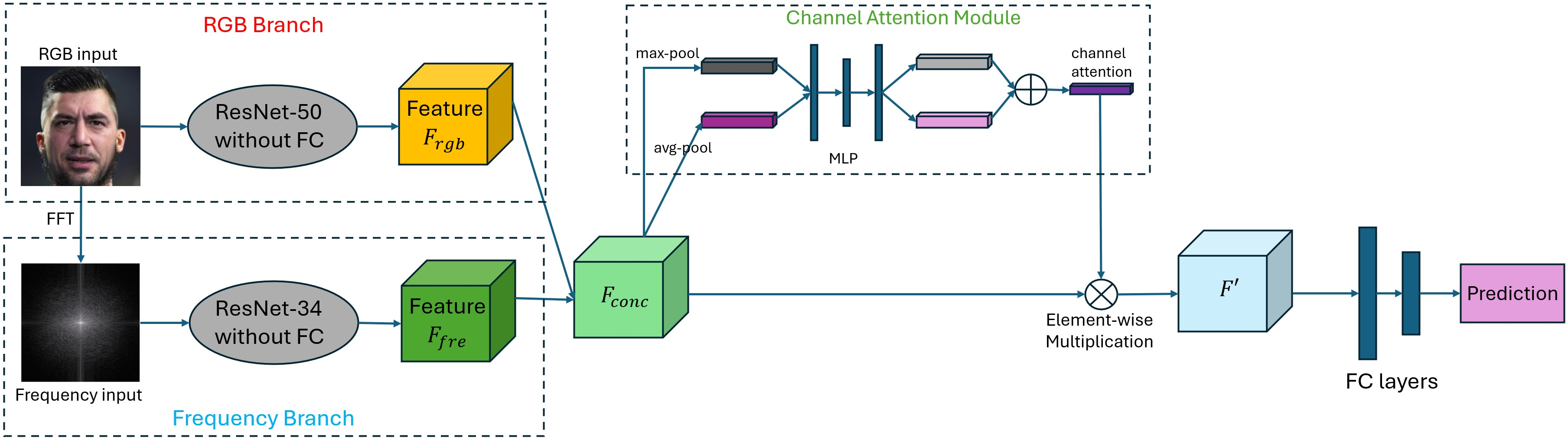
Figure 2: The dual-branch detection framework, integrating spatial and frequency cues via channel attention for robust real-vs-fake prediction.
Frequency Representation
The frequency branch is motivated by the observation that generative models, despite producing visually plausible images, often leave subtle spectral artifacts due to upsampling, non-linear activations, and iterative denoising. The grayscale conversion (ITU-R BT.601) followed by FFT and log-scaling ensures that the frequency branch is sensitive to these artifacts, which are often imperceptible in the spatial domain.
Channel Attention Fusion
The channel attention module, inspired by CBAM, computes both average and max pooled descriptors across spatial dimensions, processes them through an MLP, and fuses the results via a sigmoid activation. This mechanism adaptively reweights the concatenated feature channels, allowing the network to focus on the most discriminative cues for forgery detection.
FSC Loss Function
The FSC Loss is a composite objective comprising:
- Focal Loss: Addresses class imbalance and emphasizes hard samples.
- Supervised Contrastive Loss: Encourages intra-class compactness and inter-class separability in the embedding space.
- Frequency Center Margin Loss: Enforces compactness of frequency features within classes and a margin between class centers, directly targeting frequency-domain discriminability.
This multi-faceted loss function is critical for learning robust, generalizable features, particularly in the presence of subtle or cross-domain manipulations.
Experimental Evaluation
Dataset and Protocol
The DiFF benchmark is used for evaluation, featuring identity-disjoint splits and a balanced distribution of real and fake images across T2I, I2I, FS, and FE categories. This dataset is specifically curated to reflect the diversity and realism of contemporary facial forgeries, including those generated by state-of-the-art diffusion models.
In-Domain and Cross-Domain Results
The dual-branch model achieves near-perfect in-domain accuracy (≥99% across all categories), matching or exceeding state-of-the-art baselines such as F3-Net and EfficientNet. More notably, in cross-domain settings—where the model is trained on one manipulation type and tested on others—the proposed method consistently outperforms baselines, with substantial margins in several cases (e.g., 47.98% on FS when trained on T2I, compared to 45.07% for F3-Net).
The model's average accuracy across all forgery types (T2I: 72.92%, I2I: 69.25%, FS: 54.95%, FE: 53.60%) significantly exceeds human performance (T2I: 59.65%, I2I: 59.63%, FS: 51.50%, FE: 45.53%), as measured by a large-scale user study. This demonstrates the model's ability to detect forgeries that are challenging even for trained human observers.
Ablation Studies
Ablation experiments confirm the necessity of each architectural component:
- Removing the frequency branch results in the largest performance drop (average 13.4% decrease), highlighting the importance of frequency cues.
- Excluding the frequency center margin loss or channel attention module also degrades performance, particularly on FE and FS subsets, indicating that both frequency-specific supervision and adaptive feature fusion are critical for robust detection.
Implications and Future Directions
The dual-branch architecture, with explicit frequency-domain modeling and attention-based fusion, demonstrates strong generalization across diverse and challenging forgery types. The FSC loss further enhances feature discriminability, particularly in the frequency domain, which is increasingly relevant as generative models become more adept at suppressing spatial artifacts.
Practically, this approach is well-suited for deployment in real-world media forensics pipelines, where the nature of forgeries encountered is both diverse and evolving. The modularity of the architecture allows for straightforward extension to other modalities (e.g., video, audio) or integration with transformer-based backbones for further performance gains.
Theoretically, the results suggest that frequency-domain artifacts remain a persistent weakness of current generative models, even as their spatial realism improves. Future research may explore more sophisticated frequency representations (e.g., wavelet transforms), self-supervised pretraining on unlabeled forgeries, or adversarial training to further close the gap between synthetic and real distributions.
Conclusion
This work presents a dual-branch CNN architecture for robust detection of AI-generated facial forgeries, integrating spatial and frequency cues via channel attention and supervised by a composite FSC loss. The model achieves state-of-the-art performance on the DiFF benchmark, significantly outperforming human observers and prior baselines, particularly in cross-domain scenarios. The findings underscore the importance of frequency-domain analysis and adaptive feature fusion in the ongoing development of generalizable and trustworthy forgery detection systems.