- The paper introduces a flow-aware DRL agent combining PPO, GTrXL, and auxiliary flow prediction to achieve a 97.6% success rate and a 0.2% crash rate.
- It leverages high-fidelity CFD simulations with KD-tree indexed tricubic interpolation to retrieve real-time flow velocities for efficient collision-free trajectories.
- The transformer-based architecture outperforms PPO+LSTM and classical Zermelo methods by enhancing sample efficiency, robustness, and generalization in complex environments.
Deep Reinforcement Learning for UAV Navigation in 3D Urban Turbulent Flow
Overview
This paper presents a comprehensive study of autonomous UAV navigation in a three-dimensional urban environment characterized by turbulent flow, leveraging deep reinforcement learning (DRL) techniques. The authors introduce a flow-aware Proximal Policy Optimization (PPO) agent augmented with a Gated Transformer XL (GTrXL) architecture and a multi-objective auxiliary flow prediction head. The approach is benchmarked against PPO+LSTM, PPO+GTrXL, and the classical Zermelo's navigation algorithm, demonstrating substantial improvements in success rate, crash rate, and sample efficiency. The work is situated within a high-fidelity CFD simulation of urban flow, with rigorous algorithmic and architectural innovations tailored to the challenges of dynamic, partially observable, and highly disturbed environments.
The navigation task is set in a 3D urban flow field generated by spectral-element simulations (Nek5000), with two obstacles representing buildings. The UAV is modeled as a mass point with six translational and two rotational degrees of freedom (yaw, pitch), evolving under thrust, angular rates, and local flow velocity. The environment is discretized into overlapping blocks, enabling efficient on-the-fly retrieval of velocity vectors via parallelized tricubic spatial and cubic temporal interpolation, with KD-tree indexing and aggressive caching to minimize I/O overhead.
The agent receives continuous observations comprising its orientation, position, relative angles to the target, Euclidean distance to the target, and obstacle detection via ray-tracing in elevation and azimuth directions.
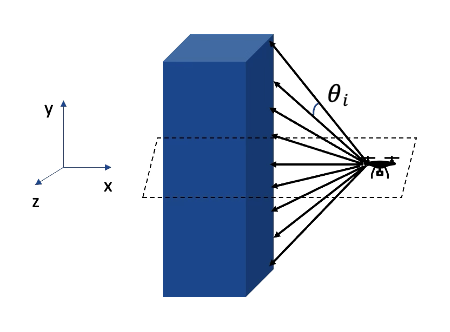

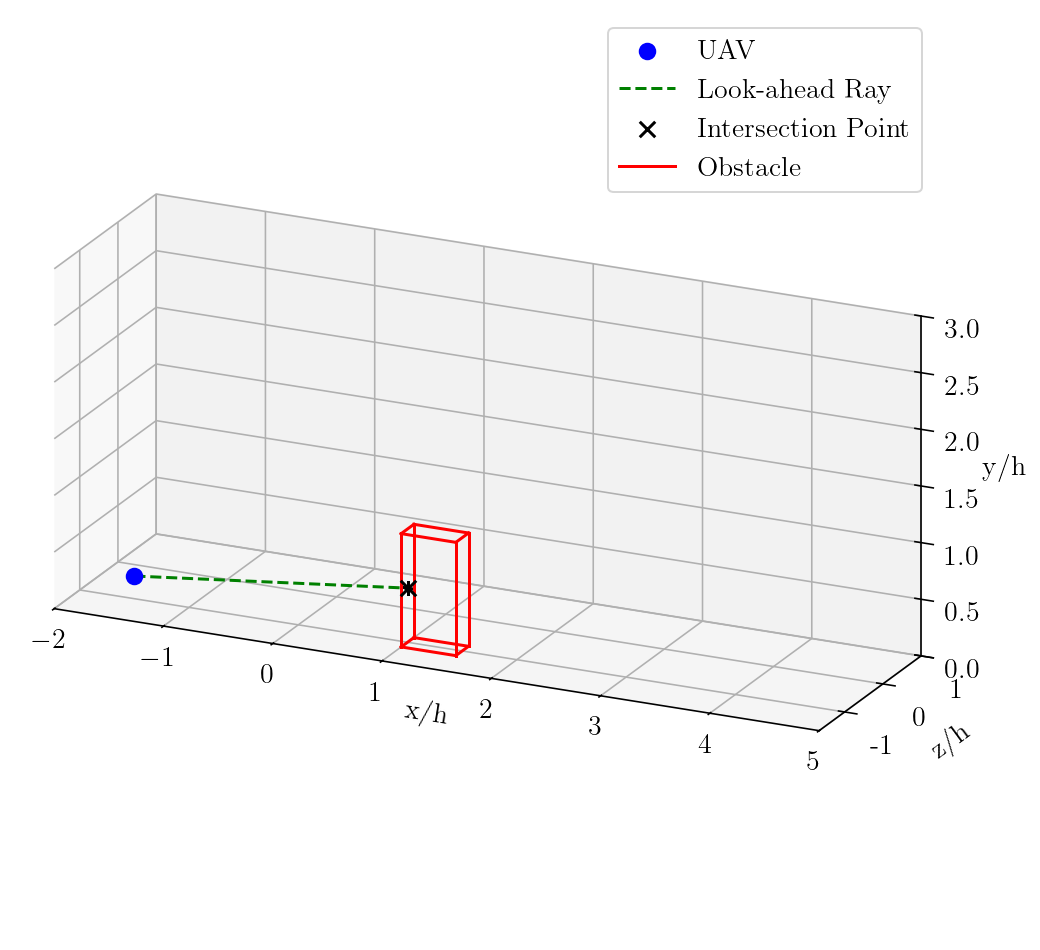
Figure 1: Elevation sensor ray configuration for obstacle detection in the 3D urban domain.
The action space includes thrust and angular changes, and the reward function is a composite of transition, obstacle, free-space, best-direction, step, proximity-velocity, and energy penalties, with terminal bonuses and penalties for target acquisition, collisions, and out-of-bounds events.
Algorithmic Innovations
PPO+LSTM and PPO+GTrXL Baselines
The PPO+LSTM baseline leverages recurrent memory to encode temporal dependencies but is limited by its fixed-size hidden state and sequential update bottleneck, which impairs long-horizon credit assignment and spatial reasoning in 3D domains. The PPO+GTrXL replaces recurrence with gated self-attention, enabling direct access to temporally distant observations and flexible memory scaling.
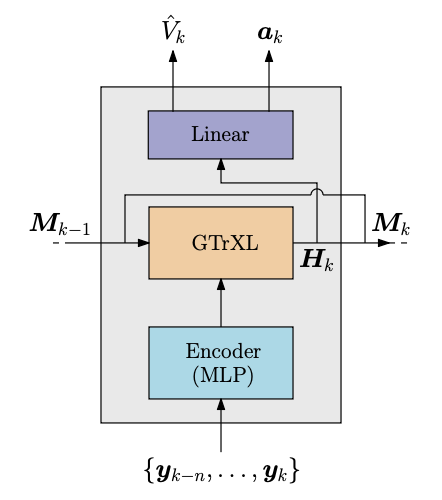
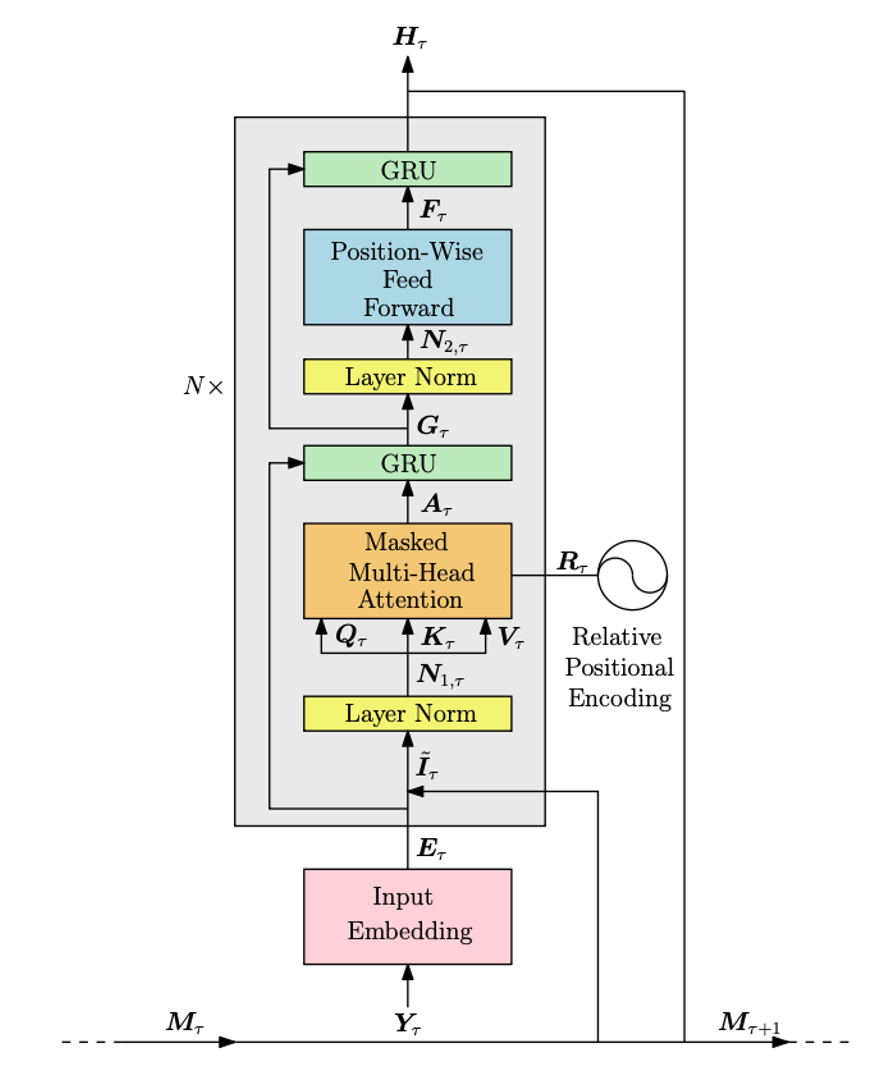
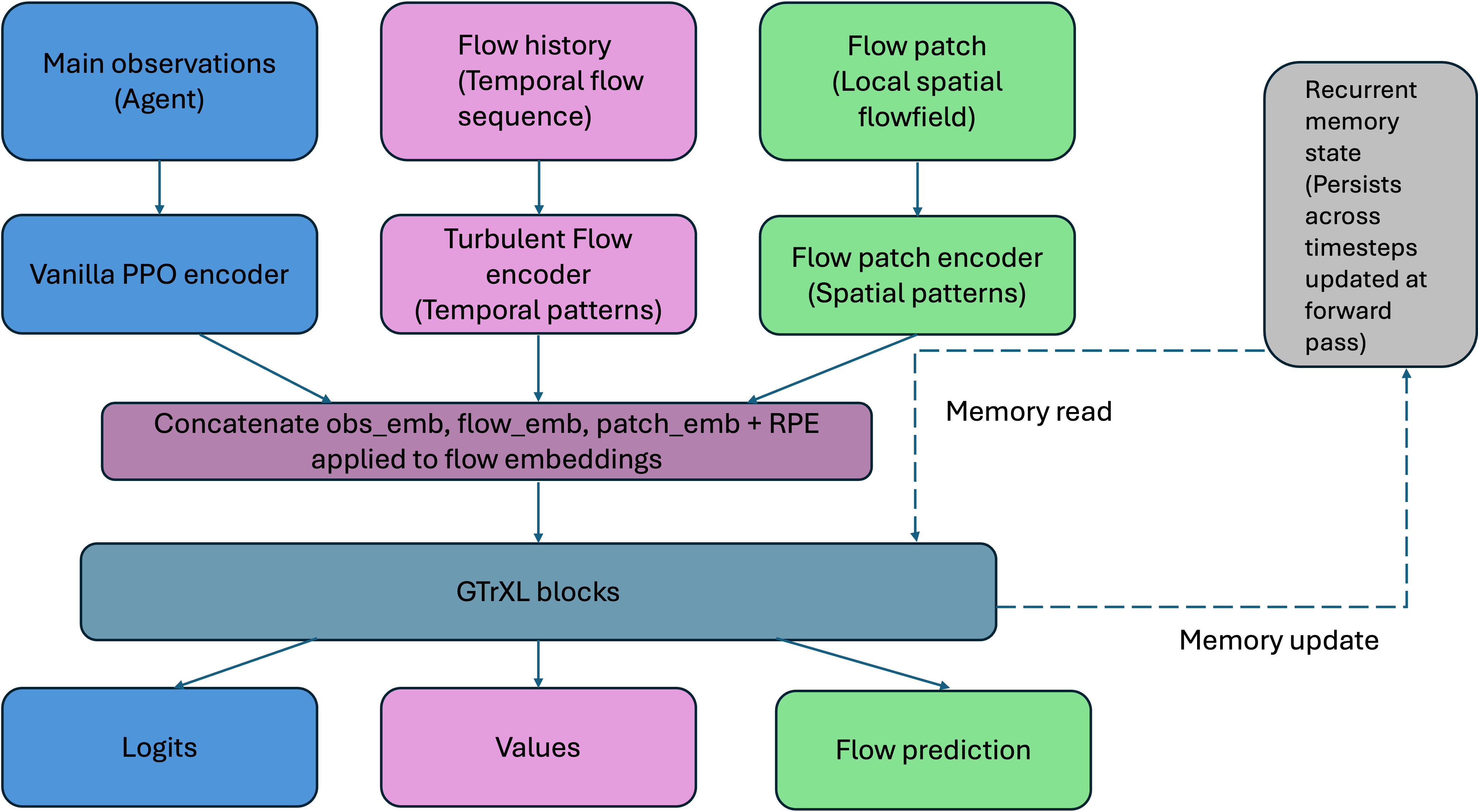
Figure 2: PPO+GTrXL architecture, illustrating the flow of observations through the transformer block and policy/value heads.
Flow-Aware PPO+GTrXL with Auxiliary Prediction
The principal contribution is the integration of a CNN+GRU encoder for flow history and local flow patches, concatenated with proprioceptive embeddings and processed by stacked GTrXL blocks. The architecture jointly optimizes three objectives: policy logits, value estimates, and next-flow-snapshot predictions. The auxiliary flow prediction head is trained with a contrastive InfoNCE loss, enforcing latent representations that are sensitive to navigation-relevant flow dynamics.
The multi-objective loss is:
Ltotal=LPPO+λLcontrastive
where LPPO is the standard PPO loss and Lcontrastive is the InfoNCE objective over flow embeddings.
Experimental Results
Normalized reward curves show that PPO+LSTM saturates at Rnorm=0.94±0.5 after 300 iterations, PPO+GTrXL at 0.98±0.2, and flow-aware PPO+GTrXL at 1.0±0.1, with the latter overtaking the vanilla transformer by iteration 600.
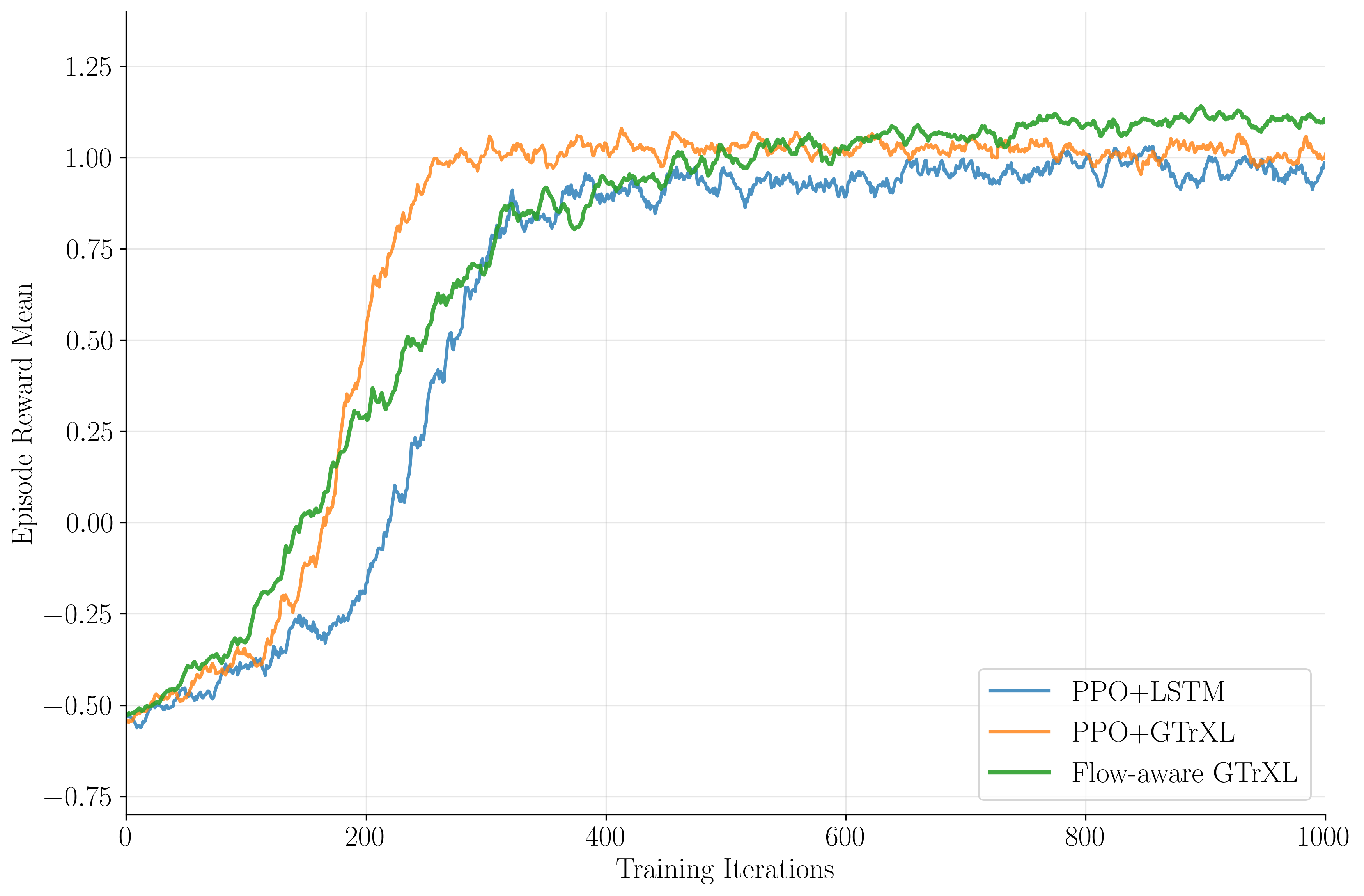
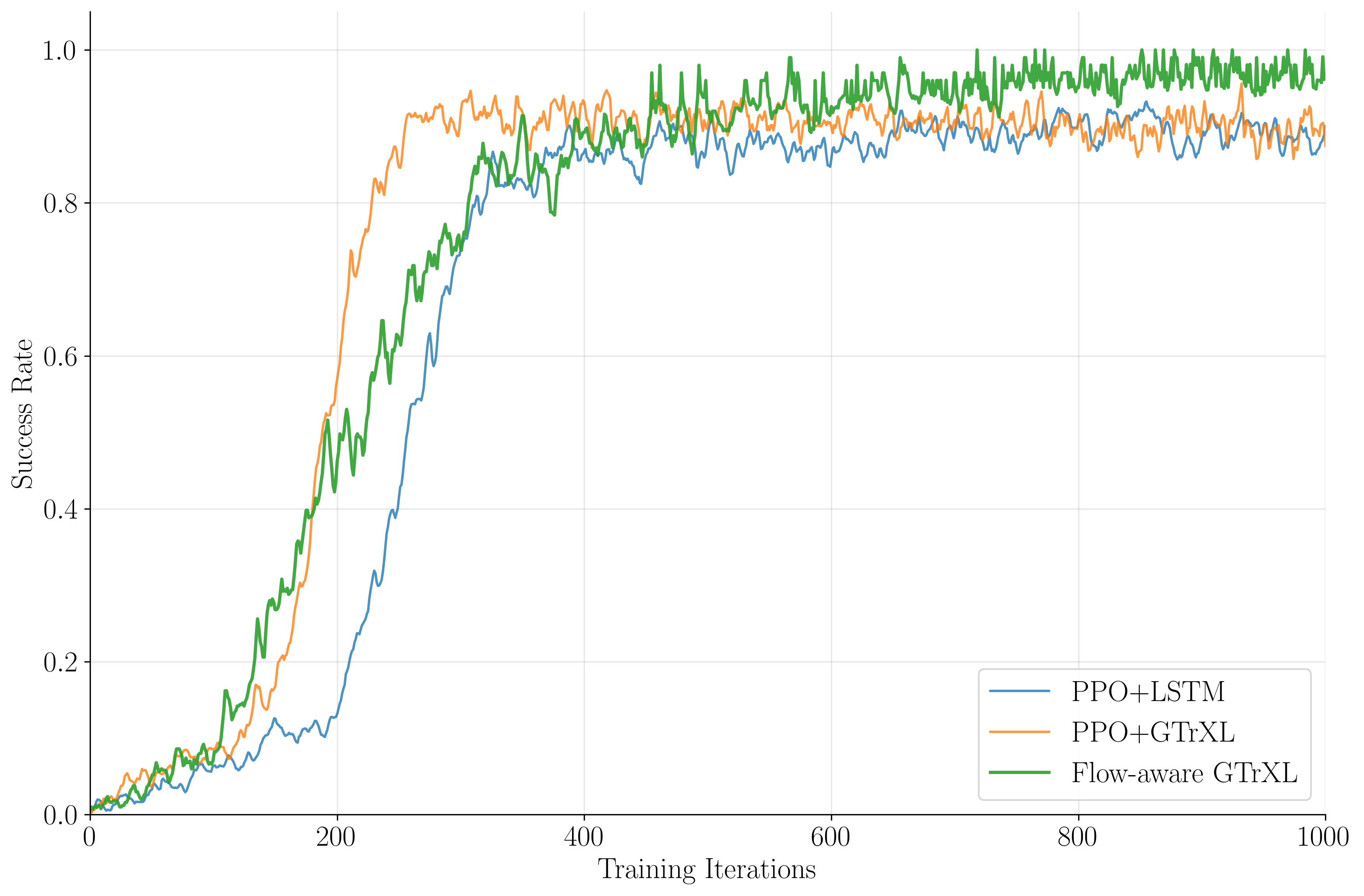
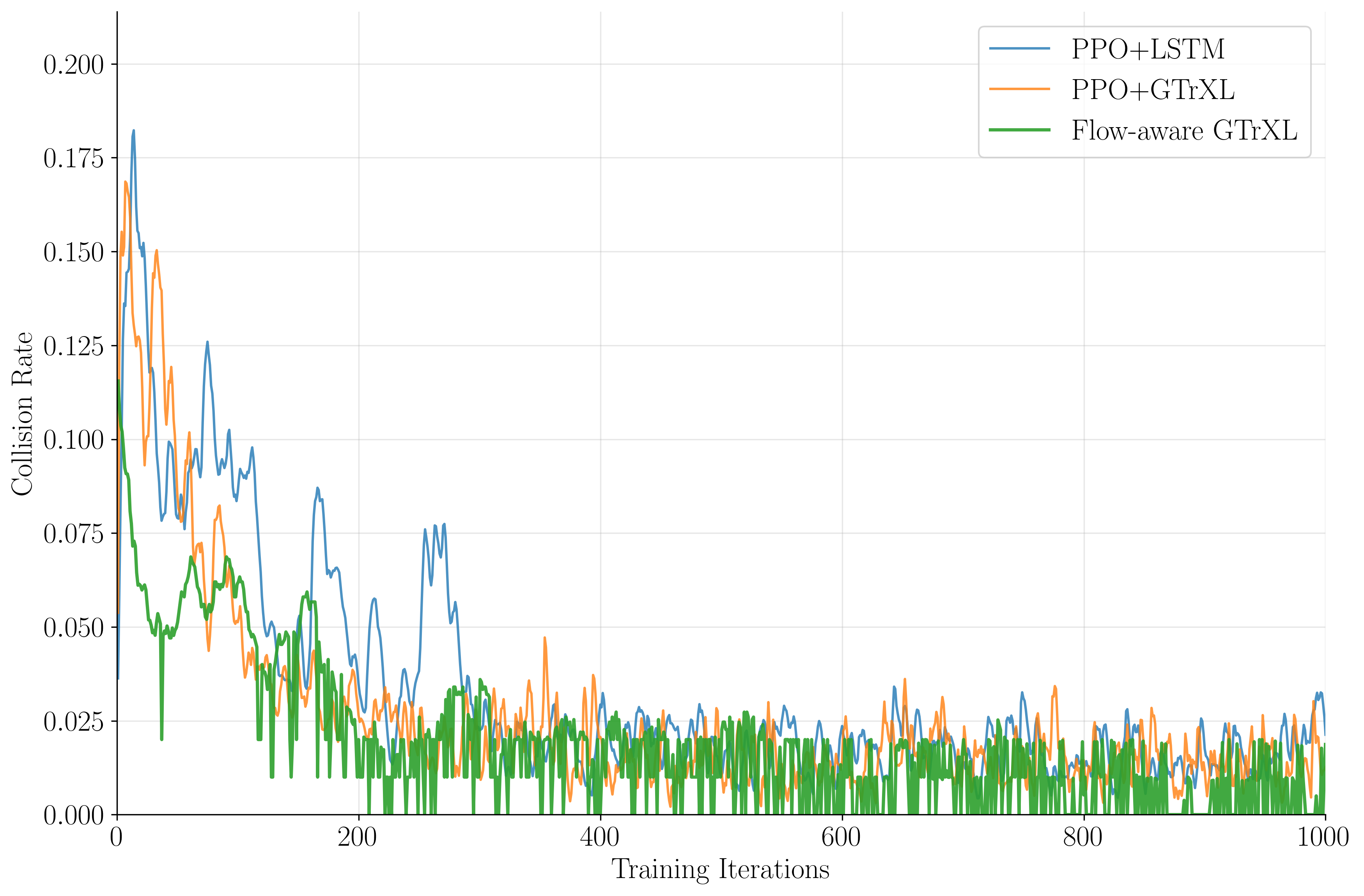
Figure 3: Normalized reward vs. training iterations for PPO+LSTM, PPO+GTrXL, and flow-aware PPO+GTrXL, demonstrating superior convergence and final performance for the flow-aware agent.
Success rates peak at 97.6% for flow-aware PPO+GTrXL, 95.7% for PPO+GTrXL, and 86.7% for PPO+LSTM, while crash rates drop to 0.2%, 0.4%, and 0.5%, respectively. The flow-aware agent exhibits robust generalization in zero-shot inference on unseen flow snapshots.
Trajectory Analysis
Visualization of agent trajectories reveals that the flow-aware PPO+GTrXL produces efficient, collision-free paths that exploit transient flow structures and adapt to gust-driven drift.
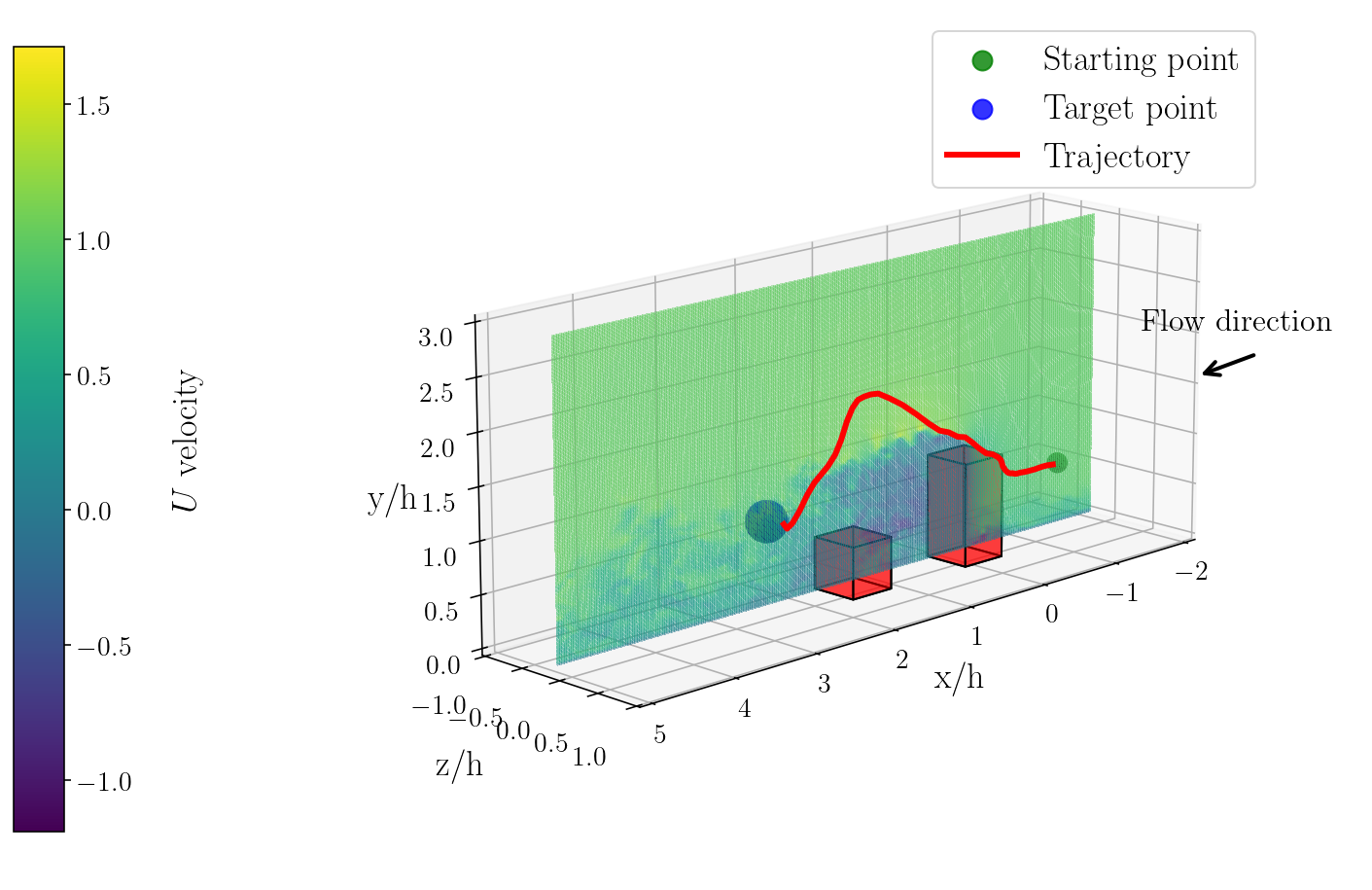
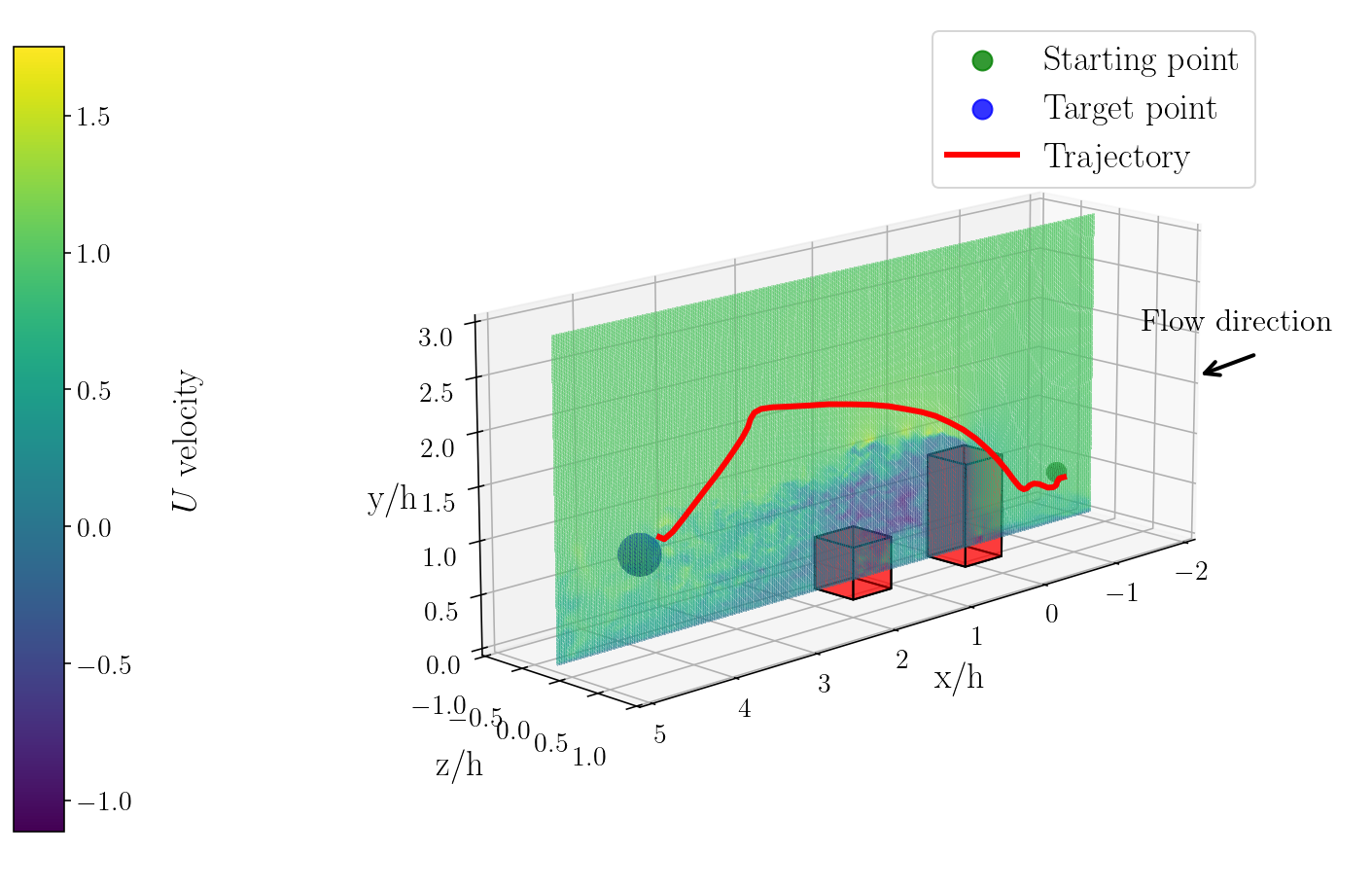
Figure 4: Visualization of trajectories produced by the trained policy of the flow-aware PPO+GTrXL algorithm in the 3D urban flow domain.
Comparison with Zermelo's Algorithm
Zermelo's open-loop optimal control, parameterized by B-splines and solved via sequential quadratic programming, achieves only 61.3% success rate, highlighting its brittleness to flow perturbations and lack of reactivity. All DRL agents decisively outperform Zermelo, underscoring the necessity of closed-loop, temporally aware policies in dynamic environments.
Architectural and Practical Implications
The transformer-based architectures, especially when augmented with physically meaningful auxiliary tasks, demonstrate superior sample efficiency, stability, and robustness. The contrastive flow prediction head stabilizes policy updates and equips the agent with anticipatory control capabilities, reducing reward variance and collision rates. The block-decomposed simulation and interpolation framework enables scalable training on large CFD datasets without prohibitive memory requirements.
The study also identifies limitations: reliance on ground-truth flow snapshots during training, absence of sensor noise and onboard computation constraints, and single-agent scenarios. Future work should address self-supervised flow prediction from onboard sensors, multi-agent interactions, and real-world deployment under hardware constraints.
Future Directions
The results suggest that multi-objective transformer policies, jointly learning to predict and control, are critical for safe and efficient navigation in turbulent 3D environments. The approach is extensible to other autonomous vehicles operating in complex, partially predictable domains, such as urban air corridors or maritime traffic. Anticipated developments include self-supervised flow representation learning, integration with real-time sensor fusion, and scaling to multi-agent coordination.
Conclusion
This work establishes a new benchmark for autonomous UAV navigation in 3D urban turbulent flow, demonstrating that transformer-based DRL agents with auxiliary flow prediction decisively outperform both recurrent and classical optimization baselines in robustness, efficiency, and generalization. The architectural innovations and scalable simulation framework provide a foundation for future research in physically informed, multi-objective reinforcement learning for autonomous systems in complex environments.