Evontree: Ontology Rule-Guided Self-Evolution of Large Language Models
Abstract: LLMs have demonstrated exceptional capabilities across multiple domains by leveraging massive pre-training and curated fine-tuning data. However, in data-sensitive fields such as healthcare, the lack of high-quality, domain-specific training corpus hinders LLMs' adaptation for specialized applications. Meanwhile, domain experts have distilled domain wisdom into ontology rules, which formalize relationships among concepts and ensure the integrity of knowledge management repositories. Viewing LLMs as implicit repositories of human knowledge, we propose Evontree, a novel framework that leverages a small set of high-quality ontology rules to systematically extract, validate, and enhance domain knowledge within LLMs, without requiring extensive external datasets. Specifically, Evontree extracts domain ontology from raw models, detects inconsistencies using two core ontology rules, and reinforces the refined knowledge via self-distilled fine-tuning. Extensive experiments on medical QA benchmarks with Llama3-8B-Instruct and Med42-v2 demonstrate consistent outperformance over both unmodified models and leading supervised baselines, achieving up to a 3.7% improvement in accuracy. These results confirm the effectiveness, efficiency, and robustness of our approach for low-resource domain adaptation of LLMs.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Explaining “Evontree: Ontology Rule-Guided Self-Evolution of LLMs”
Overview: What is this paper about?
This paper introduces a way to help LLMs, like Llama 3, get better at specialized topics (such as medicine) without using huge, private, or hard-to-get datasets. The method is called “Evontree.” It teaches the model to improve itself using a few simple, expert-made rules about how concepts relate, and by checking and filling in gaps in the model’s own knowledge.
The main idea in simple terms
- Think of an LLM like a very smart student who has read a lot but might still be unsure about certain facts in specialized areas.
- Experts often organize knowledge using “ontologies”—these are like clean, well-structured maps of ideas that say things like “X is a type of Y” or “A is another name for B.”
- Evontree uses just a couple of these rules to: 1) Pull out what the model already “thinks” it knows, 2) Check if these thoughts fit the rules, 3) Find what the model is missing, 4) Teach the model those missing pieces using carefully generated practice questions and answers.
Key questions the researchers asked
- Can we improve an LLM’s medical knowledge using only a small set of high-quality rules, instead of tons of data?
- Can we find and fix places where the model’s knowledge is inconsistent or incomplete?
- Will this self-improvement keep the model reliable and safe?
- Which parts of the approach matter most for making the model better?
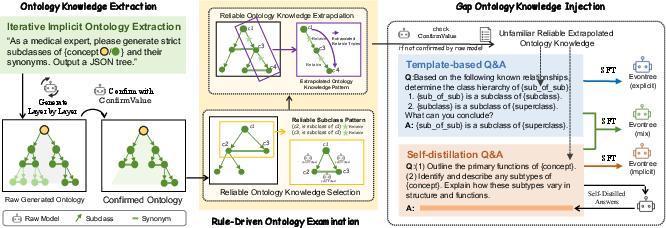
How Evontree works (in everyday language)
Here’s the approach in four steps, with simple explanations and analogies:
- Building a knowledge “tree” from the model
- The team asks the model to list concepts and their “subclasses” (like a family tree: “Muscle Cell” is a type of “Cell”) and synonyms (different names for the same thing, like “Myocyte” and “Muscle Cell”).
- This creates an “ontology tree” of the model’s current understanding.
- Checking how confident the model is
- The model is asked True/False questions about each relationship (for example, “Is A a synonym of B?”).
- They use a score called “ConfirmValue,” based on a measure named “perplexity.”
- Perplexity is like a “surprise meter”: low surprise means the model is confident; high surprise means it’s unsure. If the model consistently shows low surprise (high confidence) across several ways of asking the question, that relationship is considered “confirmed.”
- Using simple rules to spot reliable facts and discover new ones
- Two core rules guide this process:
- R1 (Synonym-to-Subclass): If x is a synonym of y, and y is a type of z, then x is also a type of z. Example: If “Myocyte” and “Muscle Cell” mean the same thing, and “Muscle Cell” is a type of “Cell,” then “Myocyte” is a type of “Cell.”
- R2 (Subclass chain): If x is a type of y, and y is a type of z, then x is a type of z. Example: If “Skeletal Muscle Fiber” is a type of “Myocyte,” and “Myocyte” is a type of “Cell,” then “Skeletal Muscle Fiber” is a type of “Cell.”
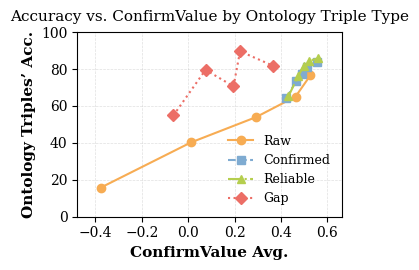
- First, they select “reliable” facts (so they don’t build new facts on mistakes). They do this by finding triangles of mutually supporting relationships (like three puzzle pieces that fit together), which are unlikely to all be wrong.
- Then they use R2 to “extend” the knowledge: stringing together “is-a-type-of” chains to infer new, logical facts.
- Finally, they find “gap” facts: new facts that are very likely true but the model isn’t confident about yet (low ConfirmValue). These are the teaching targets.
- Two core rules guide this process:
- Teaching the model its missing pieces
- The team creates practice questions and answers using the gap facts and their supporting chains.
- Two styles are tested:
- Explicit: Straight, rule-based Q&A about the ontology.
- Implicit: More natural questions (like “Outline the functions of X” or “Describe subtypes of Y”), with gentle hints that include the ontology chain.
- The model is fine-tuned (lightly retrained) on this self-made, high-quality practice data so it “internalizes” the missing knowledge.
What did they find, and why it matters?
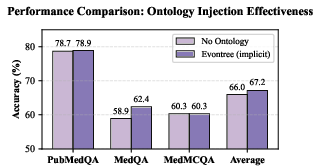
- Clear improvements in medical question answering:
- On standard medical tests (MedQA, MedMCQA, PubMedQA), Evontree improved a general LLaMA 3 model by about 3.1% on average, and a medical-tuned model (Med42-v2) by about 3.7%.
- The “implicit” and “mixed” teaching styles worked better than “explicit” rule-only Q&A. In simple terms: natural, hint-guided learning helps more than stiff templates.
- Quality over quantity:
- Instead of grabbing huge datasets (which are hard to get in healthcare), Evontree succeeds using a tiny set of high-quality rules and careful selection.
- By focusing on the model’s “blind spots” (gap facts), the method adds exactly the knowledge the model needs and avoids confusing it.
- General skills and safety stayed stable:
- The model’s overall abilities (like general knowledge tests) barely changed or sometimes improved.
- Safety (resisting harmful prompts) remained similar, especially with the implicit/mixed teaching style.
- Each component matters:
- Removing the “reliable selection” step led to injecting more mistakes and worse results.
- Skipping the “gap” filter and injecting everything hurt performance (too much noisy training).
- Removing ontology hints from training questions reduced gains, showing those hints are important.
Why this is important
- Helps in privacy-sensitive fields:
- In areas like medicine and finance, collecting huge, high-quality datasets is difficult due to privacy and cost. Evontree shows you can still boost performance by using a few expert rules and the model’s own knowledge.
- Makes models self-improving:
- The model learns to examine itself, find gaps, and then study exactly what it needs. That’s efficient and scalable.
- Could apply beyond medicine:
- The same idea—using small sets of ontology rules to guide self-improvement—could help models adapt to other fields (biology, chemistry, law, finance) without massive data.
Simple takeaway
Evontree is like a smart study plan for AI: it checks what the model knows, uses simple logic rules to discover what it should also know, figures out where it’s unsure, and then teaches it those missing pieces with well-designed practice. This helps the model get better at specialized tasks, especially in areas where gathering huge datasets is tough, all while keeping its general skills and safety intact.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a consolidated list of what remains missing, uncertain, or unexplored in the paper, phrased to be concrete and actionable for future research:
- Ontology expressivity is minimal: only subclass and synonym relations plus two simple rules (R1, R2). Extend to richer axioms (e.g., disjointness, equivalence, domain/range constraints, part-of, causal, interacts-with) and evaluate their impact on extraction, validation, and downstream performance.
- Tree-structured extraction may distort real ontologies (which are DAGs with cross-links). Investigate DAG-based extraction, cycle detection, and cross-hierarchy edges, and quantify how tree enforcement affects coverage and correctness.
- Synonym handling relies on “exact synonym” decisions without disambiguation. Add polysemy resolution, near-synonym vs exact-synonym distinctions, and grounding/normalization to canonical identifiers (e.g., UMLS CUIs) to prevent semantic drift.
- Reliability selection assumes that “closed triangles” rarely co-occur erroneously, yet all edges are model-generated. Quantify the rate of coherent-but-wrong triangles, add external sanity checks, and study error propagation when triangles are incorrect.
- ConfirmValue calibration is circular: the threshold is set using the model’s own one-shot True/False decisions. Calibrate with external ground truth (e.g., curated ontologies) or human labels; compare against alternative uncertainty/confidence metrics (log-odds gaps, temperature scaling, Brier scores, dropout ensembles).
- Prompt sensitivity is under-explored: ConfirmValue uses 4–5 paraphrased prompts. Systematically test robustness to prompt phrasing, adversarial prompts, and multi-lingual prompts; develop prompt-agnostic or learned verifiers.
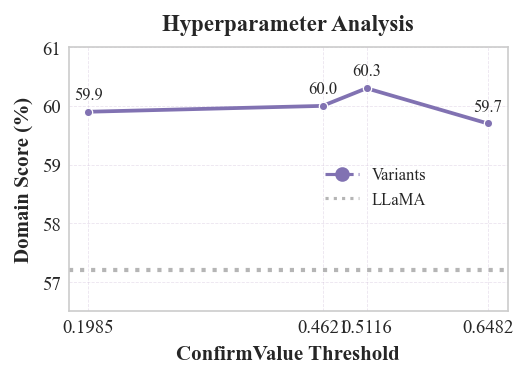
- Hyperparameter selection for gap thresholds is only lightly probed; the interplay of triple accuracy, ConfirmValue, and injection size remains unclear. Provide controlled studies isolating each factor, with learning curves and convergence behavior.
- Seed coverage is limited to 15 manually chosen root concepts at depth ≥3. Study sensitivity to seed choice, automatic seed discovery/expansion, and coverage metrics for domain sub-areas; quantify recall vs precision trade-offs.
- Grounding to standard medical ontologies (SNOMED CT, UMLS, MeSH) is not validated. Map extracted triples to authoritative ontologies, measure alignment (precision/recall), and analyze mismatches to guide correction rules.
- Evaluation relies on multiple-choice QA; no assessment on clinically realistic tasks (e.g., case-based long-form reasoning, evidence retrieval, temporal/causal reasoning). Expand evaluation to free-form, chain-of-thought, and explanation faithfulness tests.
- Triple accuracy is judged by other LLMs (GPT‑4o‑mini, DeepSeek‑V3) rather than domain experts. Incorporate expert annotation or gold ontological resources to obtain reliable labels and inter-annotator agreement.
- Safety analysis is narrow (AdvBench) and shows explicit injection can harm safety. Diagnose failure modes, add safety-aware filtering and adversarial training, and evaluate across broader red-teaming suites and medically sensitive prompts.
- Generalization beyond medicine and to other model families/sizes is untested. Replicate on non-medical domains (law, finance, materials science) and across different architectures (Mistral, Gemma, Qwen) to establish breadth.
- Computational efficiency and scalability are not quantified (ConfirmValue computation across ~150k triples, multiple prompts, and fine-tuning). Report runtime, GPU-hours, and cost vs. gains; propose pruning, batching, or learned scorers to reduce cost.
- Risk of reinforcing internal model biases remains: even “reliable” triples are model-derived. Introduce counterfactual checks, contradiction detection, and cross-model agreement tests to prevent amplifying systematic misconceptions.
- Post-injection consistency is not re-verified. Establish a closed-loop process (inject → re-extract → re-check) with stopping criteria, and measure whether contradictions or cycles accumulate after multiple iterations.
- Catastrophic forgetting is only coarsely checked via broad benchmarks. Add targeted forgetting diagnostics (e.g., knowledge editing probes, contrastive evaluations) and investigate regularization strategies to preserve general knowledge.
- Statistical rigor is limited: small gains (≈0.9–1.1% over best baselines) lack confidence intervals, significance tests, or seed variance. Provide multi-seed runs, statistical tests, and effect sizes.
- Data leakage and contamination are not addressed (pretraining data vs benchmarks; self-distilled data overlap with evaluation knowledge). Audit contamination and enforce strict dataset hygiene.
- Injection strategy diversity is narrow (two concept-centric templates plus explicit chains). Explore template diversity, naturalistic data generation, style augmentation, and instruction mixture design; measure diminishing returns and safety impacts.
- Handling of negation, exceptions, and constraints (e.g., “A is not a subclass of C”) is absent. Incorporate negative constraints and conflict-resolution policies; evaluate how contradiction handling influences reliability.
- Rule acquisition is manual. Investigate automatic rule induction from extracted knowledge, neuro-symbolic learning of rule weights, and learning to select/apply rules conditioned on context.
- Downstream interpretability and traceability are not analyzed. Provide provenance tracking from QA improvements back to specific injected triples/chains; study which rules/triples contribute most to gains and where failures persist.
- Ethical/privacy implications of “no external data” are unexamined: the model’s pretraining may contain sensitive data. Discuss privacy risks, memorization, and compliance when mining and reinjecting implicit knowledge.
Glossary
- AdvBench: A dataset of harmful instructions used to evaluate model safety under adversarial prompts. "We use harmful instructions from the AdvBench dataset to measure the proportion of safe responses, reported as the "Raw Safe" metric."
- ARC: A standardized science exam benchmark (AI2 Reasoning Challenge) used to assess reasoning capabilities of models. "we evaluate the general capabilities of our model variants compared to the raw model on the MMLU, TriviaQA, and ARC datasets."
- Axioms: Formal rules in an ontology that enable automated reasoning and consistency checking. "Axioms (Rules): Ontologies are equipped with built-in rules which enable automated reasoning and consistency checking within knowledge graphs."
- Catastrophic forgetting: A phenomenon where fine-tuning on new data causes a model to forget previously learned knowledge. "indiscriminately injecting all extrapolated triples perturbs the training distribution and triggers catastrophic forgetting,"
- Causal-perplexity: A perplexity measure computed in a causal next-token prediction manner to gauge confidence. "we design the metrics , a causal-perplexity(introduced in Section~\ref{sec:perplexity})-based confidence score,"
- ConfirmValue: A perplexity-based confidence metric that quantifies the model’s confirmation of an ontology triple. "To reduce hallucination from one-time generation of models, we design the metrics , a causal-perplexity(introduced in Section~\ref{sec:perplexity})-based confidence score, to evaluate model's confirmation extent towards a single ontology triple."
- Cross-entropy: A measure of difference between two probability distributions, used in defining perplexity. "where is the cross-entropy between the true distribution between the true distribution and the model's predicted distribution ."
- Explicit injection: An approach that injects knowledge via explicit reasoning chains and synthesized QA pairs. "The simplest and most straightforward approach is to leverage our reliable and extrapolated triples to construct explicit reasoning chains, which are then used to synthesize questionâanswer pairs;"
- False-positive rate (FPR): The proportion of incorrect positives among all negatives, used in threshold tuning. "we sweep and compute the true-positive and false-positive rates."
- Gap triples: Reliable but unfamiliar ontology triples with low ConfirmValue chosen for injection during fine-tuning. "These low-ConfirmValue triples are labelled $\mathcal T_{\text{gap}$ , which are supposed to be injected into the model during the subsequent model's fine-tuning stage."
- Hyperparameter sensitivity analysis: A study assessing how model performance varies with changes to key thresholds or parameters. "\subsection{Hyperparameter Sensitivity Analysis.}"
- Hyponymy: A hierarchical relationship where one concept is a subclass of another. "The most common and important relationships in ontologies are Hyponymy (Is-subclass-of) and Synonymy (Is-synonym-of)."
- Implicit injection: An approach that guides models to produce concept-aware answers using ontology hints in natural question templates. "Implicit Injection: To mitigate homogeneity in synthesized QA data from single-prompt reasoning chains, we follow prior work \cite{OntoTune} to generate more natural and diverse training corpus."
- Jailbreak Safe: A safety metric measuring the proportion of safe outputs under adversarial prompt suffixes. "reported as the "Jailbreak Safe" metric."
- Knowledge graph: A structured representation of entities and relationships that supports reasoning and consistency checks. "Such rules allow ontologies to automatically detect and resolve inconsistencies, ensuring the integrity of the knowledge graph."
- LLaMA-Factory: A framework used to train and evaluate LLMs (including MMLU assessment in this paper). "We employ the Low Rank Adaptation(LoRA) technique to fine-tune raw model based on the LLaMA-Factory~~\cite{zheng2024llamafactory} framework."
- LoRA: Low-Rank Adaptation; a parameter-efficient fine-tuning technique that inserts trainable low-rank adapters. "We employ the Low Rank Adaptation(LoRA) technique to fine-tune raw model..."
- Low-resource domain adaptation: Adapting models to specialized domains using minimal supervision or data. "our approach for low-resource domain adaptation of LLMs."
- Med42-v2: A LLaMA-3-8B variant extensively fine-tuned for medical tasks. "we additionally include Med42-v2âa Llama-3-8B variant that has been extensively fine-tuned for medical tasks and is widely used in the healthcare community."
- MedMCQA: A large-scale medical multiple-choice QA benchmark used for evaluation. "MedMCQA~\cite{pal2022medmcqa}"
- MedQA: A medical exam-style multiple-choice QA benchmark used for evaluation. "MedQA~\cite{Jin_Pan_Oufattole_Weng_Fang_Szolovits_2021}"
- Mixed injection: A variant that combines implicit and explicit knowledge injection strategies. "As a further variant, we simultaneously inject knowledge via both implicit and explicit ways, which is termed mixed injection."
- MMLU: A multi-task language understanding benchmark evaluating knowledge across many subjects. "Specifically, MMLU is assessed using the LLaMAFactory framework,"
- Ontology: A structured representation of domain concepts, relationships, and rules enabling shared understanding and reasoning. "Ontology is a type of structured framework that captures concepts, their interconnections, and rules within a specific domain which enables a shared understanding of a domain's knowledge."
- Ontology chain: A sequence of ontology relations used as hints to support reasoning in generated answers. "Hint with Ontology Chain"
- Ontology rule: A formal relational constraint used to derive or validate ontology facts (e.g., R1, R2). "We introduce two ontology rules (as shown in Table \ref{tab:rules}) to externally detect inconsistencies in the extracted model's knowledge."
- OntoTune: An ontology-aligned post-training method used as a supervised baseline. "outperforming post-training methods that rely on large-scale supervised data, such as TaxoLlama\cite{DBLP:journals/corr/abs-2403-09207} and OntoTune\cite{OntoTune}."
- Parameter-efficient fine-tuning (PEFT): Methods that specialize models with minimal trainable parameters (e.g., LoRA, adapters). "Parameter-efficient fine-tuning (PEFT) methods~\cite{peft2023}, including LoRA~\cite{lora2022} and adapters~\cite{adapter2020}, successfully specialize open-source LLMs..."
- Perplexity: A measure of predictive uncertainty; lower values indicate better predictions. "Formally, perplexity is defined as the exponential of the cross-entropy between the true distribution:"
- PubMedQA: A biomedical QA benchmark featuring yes/no/maybe questions over PubMed abstracts. "PubMedQA~\cite{Jin_Dhingra_Liu_Cohen_Lu_2019}"
- Self-distilled fine-tuning: Training a model on its own generated outputs to reinforce targeted knowledge. "and re-injection of the refined knowledge back into the model by self-distilled fine-tuning."
- SubclassOf: An ontology relation indicating that one concept is a subclass of another. "R2 & "
- SynonymOf: An ontology relation indicating that two concepts are exact synonyms. "Taking raw triple as an example,"
- Synonymy: A relationship indicating semantic equivalence between concepts. "Synonymy indicates that two concepts are semantically equivalent."
- TaxoLLaMA: An ontology-informed fine-tuning approach and baseline that injects taxonomic structure. "This trend is further validated when comparing TaxoLLaMA (which uses explicit ontology injection) and OntoTune (which adopts implicit injection)."
- True-positive rate (TPR): The proportion of correct positives among all actual positives, used in threshold tuning. "we sweep and compute the true-positive and false-positive rates."
- Youden index: A statistic defined as used to select optimal thresholds. "The optimal threshold is the cut-off that maximizes the Youden index ,"
Practical Applications
Immediate Applications
Below are applications that can be deployed now using the Evontree framework’s methods and findings.
- Healthcare — Ontology-guided fine-tuning of clinical QA assistants
- Action: Improve domain performance of open LLMs (e.g., Llama3-8B) for medical question answering by extracting internal medical ontologies, validating with ConfirmValue, identifying gap triples, and performing implicit ontology-guided self-distilled fine-tuning with LoRA.
- Tools/Workflows: “Clinical QA Booster” pipeline; ConfirmValue-based gap detection; implicit injection via concept-centric prompts with ontology-chain hints; lightweight LoRA adapters.
- Assumptions/Dependencies: Access to domain ontologies (SNOMED CT, UMLS, MeSH); model supports logprob/perplexity; compute for PEFT fine-tuning; implicit injection chosen for safety and general capability preservation.
- Finance — Privacy-preserving LLM adaptation using financial ontologies
- Action: Adapt general LLMs to financial compliance, AML/KYC, product taxonomy Q&A using FIBO or internal taxonomies without exposing proprietary data.
- Tools/Workflows: “Explainable Compliance Assistant” using subclass/synonym rules (R1, R2), ConfirmValue thresholds, and implicit injection; LoRA adapters for controlled deployment.
- Assumptions/Dependencies: Availability of mature financial ontologies; internal taxonomy access; calibration of ConfirmValue thresholds per model; legal/licensing compliance.
- Legal — Ontology-aligned legal reasoning assistants
- Action: Enhance consistency in legal concept hierarchies (e.g., “tort” → “negligence”) and synonym resolution using ontology rules; generate concept-aware reasoning Q&A for training.
- Tools/Workflows: “Legal Ontology Tuner” leveraging subclass transitivity and synonym propagation; implicit injection to avoid safety degradation.
- Assumptions/Dependencies: Access to curated legal ontologies/taxonomies; validation staff for spot-checking reliable triples.
- Enterprise Knowledge Management — Taxonomy alignment and LLM grounding
- Action: Align LLM outputs with internal product/service taxonomies and synonyms; detect and fill knowledge gaps where the model’s ConfirmValue is low.
- Tools/Workflows: “Knowledge Gap Finder” for ontology extraction and gap selection; “Ontology-Guided Fine-Tuning Toolkit” for implicit injection; MLOps integration for threshold calibration.
- Assumptions/Dependencies: Stable internal taxonomies; gated access to model logprobs; change-management process for continuous updates.
- Education — Concept map–aware tutoring in STEM courses
- Action: Create course-specific tutors in biology/chemistry by building ontology trees of core concepts and subtypes; generate high-quality, concept-aware answers via ontology chain hints.
- Tools/Workflows: “Curriculum Ontology Tutor”; templates for functions/subtypes; implicit injection with self-distilled answers.
- Assumptions/Dependencies: Instructor-provided ontologies or textbook-derived ontological scaffolds; careful threshold selection to avoid over-injection.
- Information Retrieval/Search — Ontology-aware query expansion and classification
- Action: Use synonym propagation and subclass transitivity to expand queries and improve hierarchical classification in search pipelines.
- Tools/Workflows: “Ontology-Aware Search Expansion” module built on R1/R2; ConfirmValue gating to avoid propagating noisy relations.
- Assumptions/Dependencies: Domain ontologies for IR; access to LLM for relation validation; integration with existing search stack.
- Biomedical Curation — Semi-automated KG repair and enrichment
- Action: Extract and validate subclass/synonym relations from LLMs, identify reliable triangles (R1), extrapolate transitive relations (R2), and feed trustworthy new triples to curators.
- Tools/Workflows: “Ontology Consistency Auditor”; “KG Repair Engine” with ConfirmValue calibration; curator-in-the-loop review.
- Assumptions/Dependencies: Editorial policies; ontologies like MeSH/SNOMED; curated QA for spot checks.
- Safety and Evaluation — Confidence-aware filtering of synthetic training data
- Action: Use ConfirmValue with Youden index thresholding to filter synthetic triples/Q&A; reduce hallucinations in data augmentation pipelines.
- Tools/Workflows: “Prompt Verification” tool; ConfirmValue dashboards per prompt; multi-paraphrase prompt sets for robust scoring.
- Assumptions/Dependencies: Multiple paraphrased prompts; model-specific threshold calibration; monitoring for distribution shift.
- Public Sector/Policy Analytics — Domain adaptation with minimal sensitive data exposure
- Action: Improve LLMs for public health, procurement, regulation Q&A using openly available ontologies; avoid ingesting sensitive records.
- Tools/Workflows: Lightweight LoRA fine-tuning with ontology chain hints; internal validation using ConfirmValue; audit trails of injected knowledge.
- Assumptions/Dependencies: Access to public ontologies; governance around model changes; transparency requirements.
- Software Teams — Internal taxonomy alignment for developer support
- Action: Align LLM code assistants with internal libraries/types using API/class hierarchies treated as ontologies; improve synonym handling (aliases, type names).
- Tools/Workflows: “Ontology-Aligned Code Assistant” using ConfirmValue-guided injection; subclass transitivity across type hierarchies.
- Assumptions/Dependencies: Stable codebase ontologies; secure sandboxed fine-tuning; regular refresh cycle.
Long-Term Applications
The following applications will likely require further research, scaling, or development before broad deployment.
- Self-evolving enterprise LLMs with MLOps integration
- Vision: Continuous monitoring of internal knowledge via ConfirmValue, automatic detection of gap triples, rule-based extrapolation, and scheduled implicit injections.
- Potential Product: “Self-Evolving Knowledge System” integrated with observability, rollback, and safety gates.
- Dependencies: Robust pipelines for threshold tuning, drift detection, and governance; scalable compute; auditability.
- Ontology-driven RAG + model editing
- Vision: Combine ontology constraints with retrieval augmentation; enforce subclass/synonym consistency in retrieval and on-the-fly edits; prioritize reliable chains in answers.
- Potential Product: “Ontology-Gated RAG” with policy modules to block contradictory knowledge.
- Dependencies: Runtime access to ontologies; efficient rule reasoning; model APIs for controlled edits.
- Healthcare CDS integrated with EHR ontologies
- Vision: Ontology-guided clinical decision support that reasons across SNOMED/ICD hierarchies; continuously learns via safe self-evolution without sensitive data ingestion.
- Potential Product: “Ontology-Guided CDS Assistant” with provenance and transparency.
- Dependencies: Integration with EHR systems; regulatory validation; rigorous safety/usability testing.
- Adaptive learning analytics and curriculum mapping
- Vision: Detect learners’ conceptual gaps by mapping Q&A performance to ontological hierarchies; generate targeted, ontology-hinted exercises.
- Potential Product: “Adaptive Concept Map Tutor” with competence graphs and personalized plans.
- Dependencies: High-quality educational ontologies; fairness considerations; longitudinal evaluation.
- Robotics and autonomous systems — hierarchical task knowledge injection
- Vision: Inject action/task ontologies into LLM-planners for robots, using subclass transitivity to structure plans and synonym handling for instructions.
- Potential Product: “Task Ontology Injector” for robot planning LLMs.
- Dependencies: Mature task ontologies; integration with planning stacks; safety verification.
- Energy and Infrastructure — grid operations assistants
- Vision: Utilize power system ontologies (assets, faults, procedures) to adapt LLMs for operator support without using sensitive operational logs.
- Potential Product: “Grid Operator Assistant” with ontology-based reasoning hints and continuous self-evolution.
- Dependencies: Sector-specific ontologies; robust safety testing; human-in-the-loop operations.
- Clinical trials and pharmacovigilance — consistent event classification
- Vision: Inject pharmacological/ontology knowledge (ATC, MedDRA) to standardize adverse event categorization and reasoning across documents and reports.
- Potential Product: “Pharmacovigilance Ontology Assistant” with audit trails.
- Dependencies: Access to regulated ontologies; compliance workflows; inter-annotator agreement studies.
- Cross-lingual ontology alignment and multilingual LLM adaptation
- Vision: Extend synonym/subclass propagation across languages; align multilingual ontologies to adapt LLMs without extensive labeled data.
- Potential Product: “Cross-Lingual Ontology Booster.”
- Dependencies: Multilingual ontologies; language-specific ConfirmValue calibration; evaluation benchmarks.
- Standards and policy for low-data domain adaptation
- Vision: Establish guidelines and standards for ontology-guided fine-tuning, confidence thresholds, and safety evaluation to reduce privacy risks in public-sector and healthcare AI.
- Potential Product: “Regulatory Framework for Structured-Knowledge Adaptation.”
- Dependencies: Multi-stakeholder collaboration; reference implementations; conformance tests.
- Knowledge Graph operations — automated repair, enrichment, and governance
- Vision: Large-scale KG maintenance driven by LLMs with rule-based validation, reliable triangle selection, and ConfirmValue gating; human oversight for high-stakes changes.
- Potential Product: “KG Repair and Governance Suite.”
- Dependencies: Scalable rule engines; curator dashboards; integration with existing KG ecosystems.
Notes on feasibility across applications:
- The approach depends on access to high-quality ontologies and simple rules (synonym and subclass). Domains lacking mature ontologies will need ontology creation efforts.
- ConfirmValue requires logprob access and careful prompt design; thresholds are model-specific and must be calibrated (Youden index recommended).
- Implicit injection showed better performance and safety than explicit; workflows should prefer implicit methods and monitor safety metrics continuously.
- LoRA enables lightweight adaptation, but organizations still need basic GPU capacity and MLOps for controlled deployment and rollback.
- Reliability hinges on robust “Reliable Triple Selection” (triangle rule) and “Gap Triple Selection”; indiscriminate injection can harm performance or safety.
Collections
Sign up for free to add this paper to one or more collections.