- The paper presents Gistify, a task that requires generating minimal, self-contained code files that replicate original runtime behavior.
- It evaluates models using metrics like execution fidelity, line execution rate, and line existence rate across various open-source repositories.
- Experiments show that agentic models leveraging runtime feedback outperform static approaches, underscoring limitations of current LLMs.
Gistify: Evaluating Codebase-Level Understanding via Runtime Execution
Introduction and Motivation
The "Gistify! Codebase-Level Understanding via Runtime Execution" paper introduces the Gistify task, a new evaluation paradigm for coding LLMs that targets codebase-level understanding through runtime execution. Unlike prior benchmarks that focus on isolated code snippets or repository-level tasks solvable via heuristics or retrieval, Gistify requires models to generate a single, minimal, self-contained file that faithfully reproduces the runtime behavior of a given entrypoint command on a codebase. This task is motivated by the practical workflow of developers who, when faced with unfamiliar repositories, start from a concrete execution point and iteratively reason about dependencies and control flow to extract the core functionality.
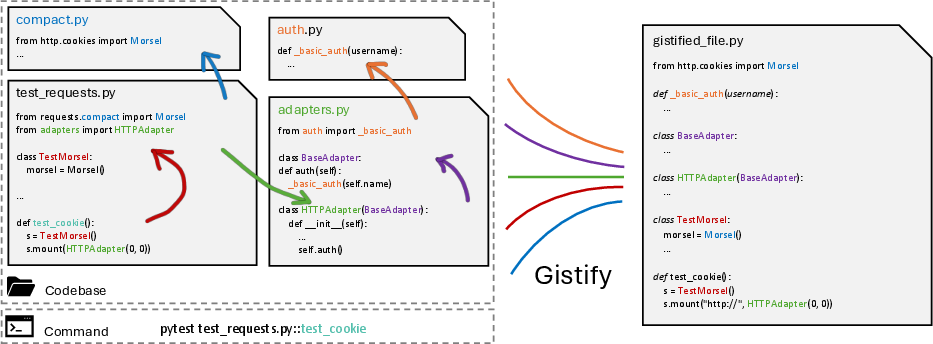
Figure 1: The Gistify task: given a codebase and a command of entrypoint, the goal is to generate a minimal, self-contained gistified code file that faithfully reproduces the original runtime behavior using code from the given codebase.
Gistify is designed to be broadly applicable, requiring only a repository and an entrypoint command, and is agnostic to the presence of GitHub issues or pull requests. The task is challenging for current LLMs, especially as codebases grow in size and complexity, often exceeding the context window of even the largest models.
Task Definition and Evaluation Metrics
The Gistify task requires the agent to generate a gistified file that satisfies four core requirements:
- Self-Containment: All necessary code from the codebase must be inlined so the file is executable independently.
- Execution Fidelity: The file must produce identical outputs to the original codebase under the specified command.
- Minimalism: Only code essential to the execution must be retained; unused code is pruned.
- Grounded Preservation: No hallucinated or fabricated code; all content must be directly derived from the codebase.
Evaluation is performed using three metrics:
- Execution Fidelity: Binary indicator of whether the gistified file produces the same output as the original codebase for the entrypoint command.
- Line Execution Rate: Fraction of lines in the gistified file that are actually executed, measuring minimality.
- Line Existence Rate: Proportion of code in the gistified file that is directly preserved from the original codebase, measuring groundedness and absence of hallucination.
Experimental Setup
Experiments are conducted using three agentic frameworks—mini-SWE-Agent, SWE-Agent, and Copilot—paired with four LLMs: GPT-5-mini, GPT-5, Claude-3.7-Sonnet, and Claude-Sonnet-4. The evaluation spans five widely used open-source repositories (requests, pylint, flask, scikit-learn, seaborn) and an additional repository (debug-gym) to ensure diversity and avoid overlap with existing benchmarks.
Models are prompted to generate gistified files for 25 tests per repository, with a 128K token context window and a cap of 50 agent steps per task. Both settings with and without execution tools (e.g., python, pytest) are evaluated to isolate the effect of runtime feedback.
Main Results
Across all models and frameworks, performance on Gistify remains limited. The best-performing configuration (Copilot with Claude-4) achieves only 58.7% average execution fidelity, indicating that reliably producing correct gistified files is still challenging for state-of-the-art LLMs. Notably, performance degrades sharply on harder subsets characterized by long execution traces and high code coverage.
Distinct model families exhibit different strengths: Claude-4 achieves the highest line existence rates (faithful code extraction), while GPT-5 produces more concise outputs (higher line execution rates). Smaller models (e.g., GPT-5-mini) benefit significantly from richer tool scaffolding, with performance increasing from 17% (bash-only) to 58% (Copilot framework).
Enabling execution tools yields only modest gains, suggesting that current LLMs do not yet fully leverage runtime feedback for codebase-level reasoning. Agentic models, which dynamically decide what to read and refine their reasoning through multi-step trajectories, consistently outperform static approaches.
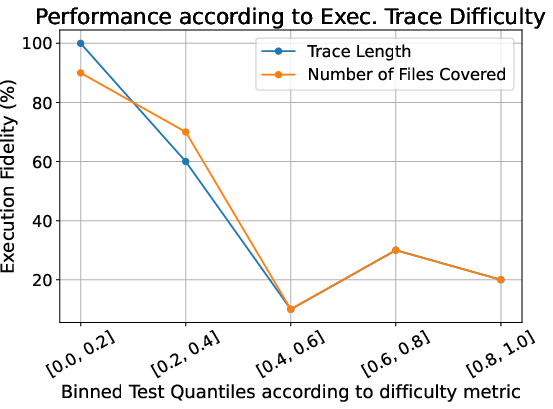
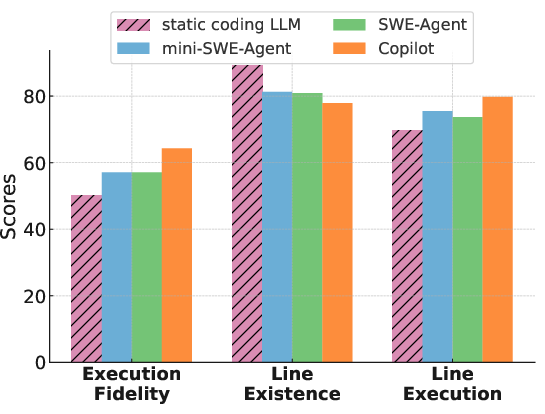
Figure 2: (Left) Difficulty of the Gistify task as a function of execution trace complexity. (Right) Performance comparison of static and agentic coding LLMs, showing agentic models outperform static ones even when the latter receive all relevant files.
Error Analysis
A detailed error analysis reveals that different models fail for different reasons:
- File Creation Failure: Model fails to generate any gistified file, often due to exceeding step limits.
- Missing Test Function: The gistified file omits or restructures the required test function, a common failure mode for GPT-5 variants.
- Import Errors: Incorrectly importing from the original repository instead of inlining code.
- Pytest Runtime Errors: Failures during execution due to syntax or fixture errors, most common for Claude-4.
A strong correlation is observed between the fidelity of the test function in the gistified file and overall execution fidelity (correlation=0.76, p=0.01). Providing the correct test function in the prompt significantly boosts both test F1 score and execution fidelity, highlighting the importance of faithfully preserving the test logic.
Prompt-based strategies (explicit tracing or recursive reading) and the use of global information tools (e.g., RepoGraph, gold execution traces) both improve performance. Access to gold tracing information yields the largest gains, indicating that global context is critical for runtime reasoning.
Interestingly, restricting execution tools to only the gistified file (Edit and Execute) outperforms unrestricted bash access, as the latter leads to longer, less focused agent trajectories and more frequent step limit terminations.
Tests with longer and more complex execution traces are significantly harder to gistify, with performance dropping from 43% to 21% on a hard subset. This suggests that Gistify can be tuned to create challenging evaluation scenarios by selecting for high-coverage tests.
Static coding LLMs, even when provided with all relevant files, are outperformed by agentic models. This demonstrates the importance of dynamic, multi-step reasoning and file selection over simply increasing context size.
Implications and Future Directions
Gistify exposes fundamental limitations in current LLMs' ability to reason over large codebases and accurately model runtime execution. The task's design—requiring minimal, self-contained, and faithful code extraction—prevents shortcut solutions and directly tests codebase-level understanding.
The practical implications are significant: gistified files can serve as valuable artifacts for debugging, error localization, refactoring, and code review. By distilling complex functionality into a compact, executable form, they facilitate both automated and human understanding of large systems.
Theoretically, Gistify motivates research into more effective agentic strategies, improved use of runtime feedback, and better integration of global code context. Future developments may include:
- Enhanced agentic frameworks with more sophisticated planning and state tracking.
- Training paradigms that incorporate execution traces and code coverage signals.
- Methods for scalable codebase summarization and modularization.
- Benchmarks that further stress-test codebase-level reasoning by increasing execution trace complexity or introducing adversarial code structures.
Conclusion
Gistify establishes a rigorous, execution-driven benchmark for codebase-level understanding, revealing that even the strongest LLMs and agentic frameworks struggle with tasks requiring deep reasoning over runtime behavior and inter-file dependencies. The task's minimal, self-contained outputs are not only challenging to produce but also valuable for downstream applications. Progress on Gistify will require advances in agentic reasoning, tool integration, and execution-aware modeling, making it a meaningful target for future research in code intelligence.