Scaling Image Geo-Localization to Continent Level
Abstract: Determining the precise geographic location of an image at a global scale remains an unsolved challenge. Standard image retrieval techniques are inefficient due to the sheer volume of images (>100M) and fail when coverage is insufficient. Scalable solutions, however, involve a trade-off: global classification typically yields coarse results (10+ kilometers), while cross-view retrieval between ground and aerial imagery suffers from a domain gap and has been primarily studied on smaller regions. This paper introduces a hybrid approach that achieves fine-grained geo-localization across a large geographic expanse the size of a continent. We leverage a proxy classification task during training to learn rich feature representations that implicitly encode precise location information. We combine these learned prototypes with embeddings of aerial imagery to increase robustness to the sparsity of ground-level data. This enables direct, fine-grained retrieval over areas spanning multiple countries. Our extensive evaluation demonstrates that our approach can localize within 200m more than 68\% of queries of a dataset covering a large part of Europe. The code is publicly available at https://scaling-geoloc.github.io.


































Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
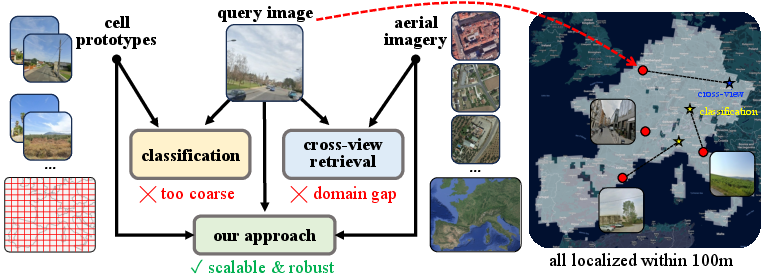
This paper is about figuring out where a photo was taken—down to about a street block—without using GPS. The authors built a new method that can locate a ground-level photo within around 100–200 meters across huge areas, like entire continents. They combine two ideas: teaching the computer to recognize “areas” of the map, and matching ground photos to aerial images (like satellite or plane photos). Together, this lets them be both accurate and able to work over very large regions.
Key Questions the Paper Tries to Answer
- How can we accurately find the location of a photo (within about 100–200 meters) when we don’t have its GPS coordinates?
- How can we do this not just in one city, but across multiple countries or an entire continent?
- Can we combine different techniques to get both accuracy and scalability?
How the Method Works (in everyday language)
Think of the Earth as a big grid made of tiny squares. Each square covers a small area on the ground (roughly a few hundred meters across). The method creates a short “code” (like a fingerprint) for:
- each grid square using ground photos,
- and for aerial images (tiles) that cover the same squares.
Here’s the key idea:
- Area summaries (prototypes): The system learns a “summary code” for each square that captures what ground-level photos in that area tend to look like. Imagine a summary that says: “This area usually has brick buildings and narrow streets” or “This area has wide highways and forests.”
- Aerial image codes: It also makes codes for aerial tiles (from planes or satellites) that cover the same squares. These tiles are available almost everywhere, even where ground photos are rare.
- Combining them into “cell codes”: For each square (cell), the method blends the area’s summary code (from ground photos) with its aerial code. This gives a strong, combined “cell code” for that place.
When a new ground photo comes in:
- The system turns the photo into its own code.
- It compares that code against all the cell codes in the database.
- The most similar cell code points to the square where the photo was likely taken.
Why this helps:
- Pure “ground-to-ground” matching needs a gigantic library of ground photos (millions to hundreds of millions), which gets slow and heavy to store.
- Pure “classification” (only choosing a square) can be fast but often too coarse (off by many kilometers).
- Pure “ground-to-aerial” matching sometimes struggles because a street view and a top-down view look very different.
- By combining area summaries with aerial codes, the system gets the precision of ground photos with the coverage and scalability of aerial imagery.
A few more simple details:
- The grid squares come from a system called S2 cells. Smaller cells mean finer location accuracy; bigger cells are coarser.
- “Embeddings” or “codes” are just compact descriptions of images the computer can compare quickly.
- The system is trained so that codes from the same place (ground photo, aerial tile, area summary) become similar, and codes from different places become different.
Main Findings and Why They Matter
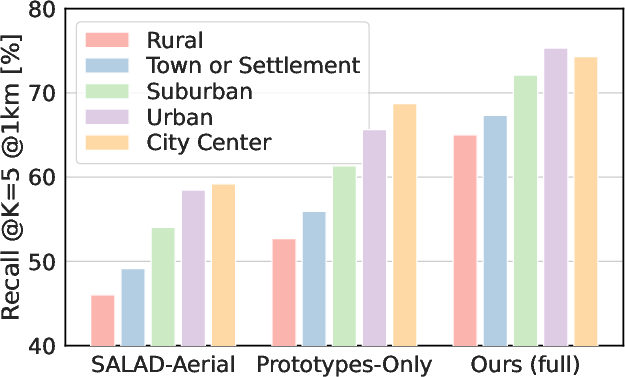
Across large parts of Europe, the method:
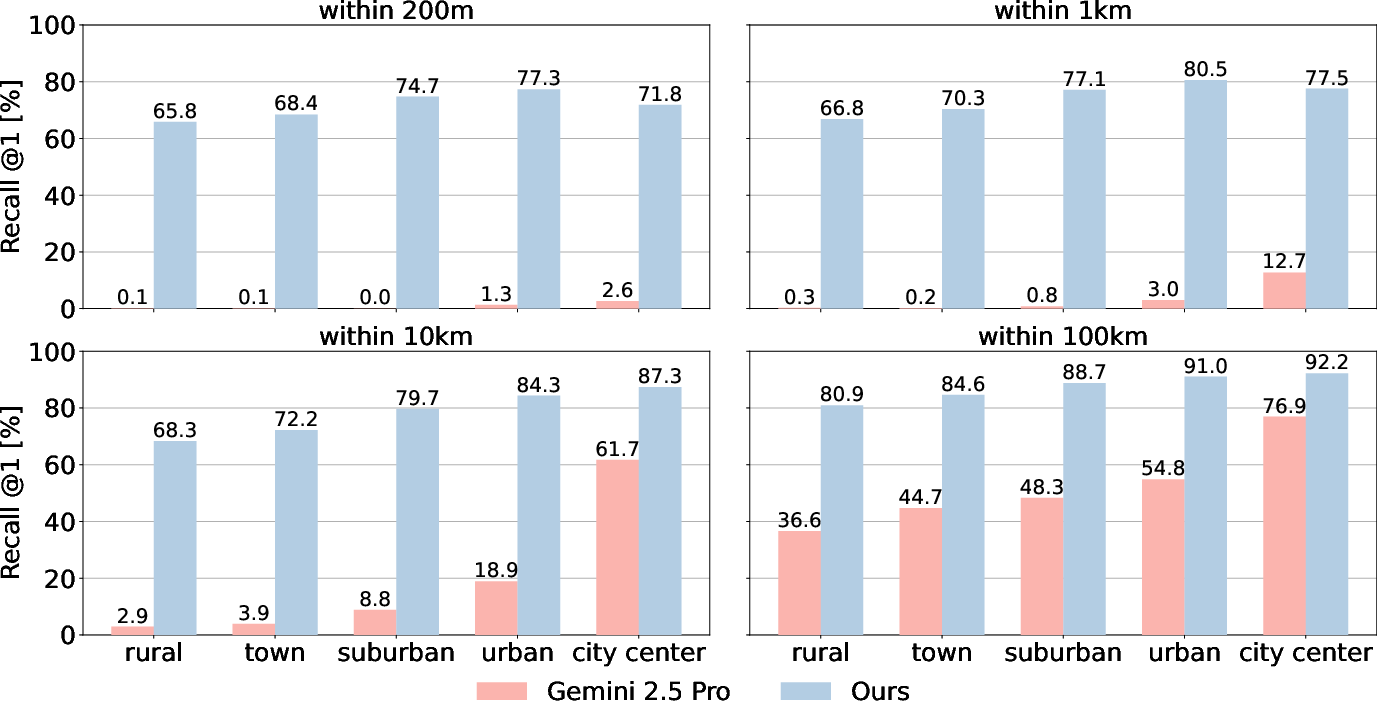
- Localizes more than 68% of test photos within 200 meters.
- Localizes about 59% within 100 meters over an area of roughly 433,000 square kilometers (that’s huge).
Other key results:
- On a three-country region (Belgium, Germany, Netherlands), the hybrid approach beats standard methods:
- Compared to classic ground-to-ground matching, it reaches similar accuracy with a database that’s 30–60 times smaller.
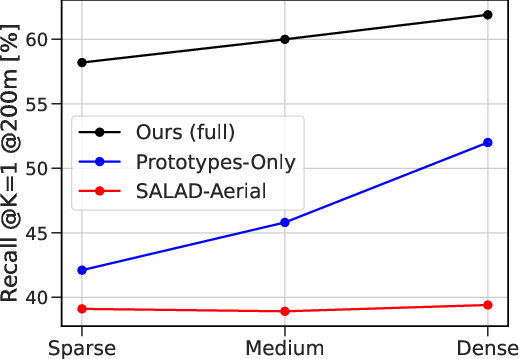
- Compared to pure cross-view (ground-to-aerial) matching, it’s significantly more accurate.
- Compared to pure classification, it’s much more precise at the block level.
- It scales to a larger region of Western Europe (10 countries) and still performs well.
- It can even generalize to new countries (UK and Ireland) without retraining by using only aerial tiles in the database, still retrieving a good number of correct locations.
- Bigger, stronger image backbones (like DINOv3) and higher image resolution improve accuracy further.
Why this is important:
- Many photos don’t have GPS data (older pictures, privacy-stripped files), and being able to locate them helps journalism, investigations, and verifying content online.
- It can help detect misleading or AI-generated images by checking if a claimed location matches the visual evidence.
- It provides reliable starting points for advanced tasks that need an initial location within roughly 100 meters.
Implications and Potential Impact
This research shows we can break the old trade-off: either be accurate but only in small areas, or be global but imprecise. By combining ground-area summaries and aerial image matching, the system is both accurate and scalable. That opens the door to:
- Better tools for newsrooms, law enforcement, and researchers to check where images were taken.
- Stronger pre-training signals for mapping and remote sensing applications.
- More robust location cues for navigation and augmented reality, especially when GPS isn’t available or reliable.
In short, the paper presents a practical way to “find places” from photos across huge regions, with accuracy fine enough to be useful in the real world.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
The following list captures the main uncertainties and unexplored aspects that could guide future research.
- Data dependence on proprietary StreetView: Results hinge on large-scale, proprietary Google StreetView imagery (vehicle- and time-specific camera models), limiting reproducibility and raising questions about performance with publicly available or crowdsourced datasets and different camera rigs.
- Geographic scope and cultural diversity: Evaluation focuses on Western Europe (plus UK+IE with aerial-only databases). It remains unclear how the approach generalizes to other continents with markedly different road networks, building styles, vegetation, and imaging conditions (e.g., Africa, Asia, Americas).
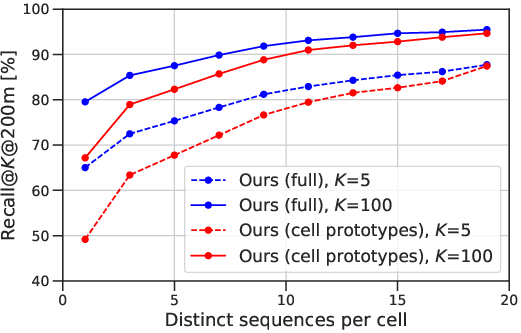
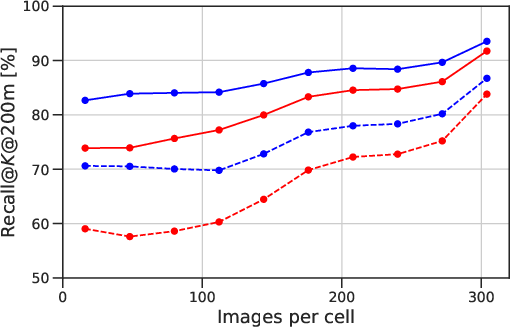
- Rural and low-coverage regions: Failure patterns increase in sparsely imaged rural areas; strategies to improve performance where ground imagery is scarce (e.g., adaptive cell sizing, road-network-aware cells, or additional modalities) are not explored.
- Handling unlocalizable queries: The method does not estimate query localizability or uncertainty; open questions include how to detect and abstain on ambiguous/textureless/occluded images and how to provide calibrated confidence or a spatial probability distribution.
- Prototype granularity and memory limits: Training stores prototypes at L=15 due to memory constraints and upsamples to L=16; scaling to finer grids (e.g., sub-100 m cells globally) remains an open systems and modeling problem (e.g., prototype compression, product quantization, factorization, or streaming prototypes).
- Fusion design (prototype + aerial): Fusion is a simple sum with a global calibration factor; it is unknown whether learning query- or cell-conditioned fusion (e.g., attention, gating, per-cell/per-query weights) could yield better robustness and precision.
- Calibration factor learning: The scalar calibration is set heuristically to match average similarities; opportunities to learn it end-to-end, adapt it per cell/region, or predict it per query are unexplored.
- Border handling and geometry: Prototype interpolation uses a fixed 50 m ground frustum; the choice of frustum depth, FOV assumptions, and orientation handling is not validated across diverse scenes. More principled, geometry-aware interpolation (e.g., using DEMs, occlusion priors, or road topology) remains open.
- Orientation estimation: Inference uses north-aligned aerial tiles and unknown query yaw; the model does not explicitly estimate or leverage ground-view orientation at test time. Joint localization-and-orientation inference could reduce domain gap.
- Temporal robustness and seasonality: Training/eval uses different years, but the impact of season, illumination, construction changes, and imagery age gaps is not systematically analyzed. Robustness to historical images (a stated motivation) is untested.
- Overhead imagery variability: The approach assumes high-resolution aerial/satellite (60 cm/px). Generalization to regions with coarser, cloudy, seasonal, or outdated overhead imagery, and the benefit of multi-temporal or multi-sensor (SAR, elevation) data, are open questions.
- Multi-scale overhead context: Only a single tile size/level is used at inference; the benefits of multi-scale or pyramid aerial features (as in prior cross-view work) are not quantified.
- Beyond appearance-only cues: The method does not exploit text (OCR), road signs, language cues, OSM/vector maps, elevation models, or semantics; quantifying gains from lightweight multimodal integration is an open direction.
- Within-cell refinement: Localization returns a best cell; there is no sub-cell refinement (e.g., re-ranking with local features, geometric verification, or fine-grained cross-view correlation). A post-retrieval refinement stage could reduce 100–200 m errors.
- Retrieval efficiency at global scale: kNN over 4.8M cells is tractable, but global coverage would grow this multiple-fold. Indexing choices (ANN structures, PQ/OPQ compression, latency/throughput on commodity hardware) are not characterized.
- Continual and incremental updates: How to update prototypes and aerial databases as imagery changes (new StreetView runs, new tiles, seasonal updates) without full retraining remains unaddressed (e.g., streaming fine-tuning, elastic cells).
- Training compute and accessibility: Training requires 128 TPUv2s and millions of prototypes; pathways to replicate on modest hardware (e.g., curriculum training, distillation, mixed precision, prototype sharding strategies for GPUs) are not provided.
- Hard-negative mining trade-offs: The method avoids expensive mining via multi-similarity loss, but it is unknown whether selective mining (across cells or aerial tiles) could further improve discrimination without prohibitive cost.
- Cell partitioning design: Fixed S2 grids are used; alternative partitions (road-network aligned, population/imagery-density adaptive, semantic clusters) may better balance precision, memory, and generalization—this is not explored.
- Cross-domain generalization (pedestrian/phone): Performance drops on Trekker and GoogleUrban show sensitivity to viewpoint/sensor differences; systematic domain adaptation (few-shot, test-time adaptation, style transfer, lens/FOV estimation) remains open.
- Handling panoramas and multi-view queries: The model trains on perspective crops from panoramas; direct use of panoramas or aggregating multi-view/query bursts (including temporal sequences) could improve robustness but is untested.
- Learning to reject or defer: There is no mechanism to defer to human verification or a higher-precision module; designing a cascaded system with principled abstention and handoff (e.g., to geometric verification) is a gap.
- Security and robustness: The model’s sensitivity to adversarial perturbations, spoofing (e.g., synthetic facades), or data poisoning in crowd-sourced imagery is not studied.
- Fairness and bias: Coverage and accuracy disparities across urban/rural, affluent/less-connected regions, and different countries are not audited; methodologies to ensure equitable performance are an open need.
- Hierarchical inference: Although the approach blends classification and retrieval, a full hierarchical pipeline (coarse global localization → regional → local cell → refinement) with learned transitions is not evaluated.
- Using weak priors: Many real-world inputs come with noisy GPS, compass, or map-matched priors; how to incorporate such priors to reduce search space and improve precision is unaddressed.
- Output interpretability: Prototypes appear to encode semantic regions (PCA visualization), but there is no interpretability or attribution analysis; understanding what features drive decisions (and failure modes) could aid debugging and trust.
- Evaluation breadth: Metrics focus on recall@200 m/1 km; additional evaluations (calibrated confidence, CDF of errors, per-country/per-density breakdowns, latency/throughput, memory-accuracy trade-offs) would better characterize deployment viability.
- Licensing and reproducibility: While code is promised, reliance on non-public imagery and special permissions impedes open benchmarking; constructing an open, large-scale, multi-modal benchmark to fairly compare methods is an open community task.
Practical Applications
Immediate Applications
The following applications can be deployed now, leveraging the paper’s hybrid geo-localization method (classification prototypes + aerial embeddings), which provides continent-scale coverage with 100–200m precision and manageable database footprints.
- Media and journalism verification
- Description: Geolocate images lacking GPS or EXIF to validate the claimed location of news photos, detect inconsistencies in user-generated content, and flag mis/disinformation.
- Sectors: Media, policy, public sector, cybersecurity.
- Tools/workflows: “GeoVerify” API for newsroom CMS; batch validation service for wire agencies; confidence scores and top-K candidates; analyst UI showing aerial tile overlays for human-in-the-loop verification.
- Dependencies/assumptions: Access to recent aerial/satellite imagery; legal/licensing clarity for imagery use; region-specific indexes prebuilt; domain adaptation for smartphone/cropped images (benefits from DINOv3-L and 448px fine-tuning).
- Law enforcement and digital forensics
- Description: Geolocate images in criminal investigations (e.g., fraud, trafficking, vandalism), even when EXIF is missing or tampered; triage large media dumps by region.
- Sectors: Public safety, defense, legal.
- Tools/workflows: Forensic toolkit plugin; evidence management system integration; batch processing pipeline with confidence thresholds and human review.
- Dependencies/assumptions: Privacy and evidentiary chain-of-custody requirements; regional database coverage; handling of occlusions and urban/rural discrepancies.
- Disaster response and emergency management
- Description: Rapidly infer the location of citizen-submitted images during floods, fires, or earthquakes when GPS is disabled or absent; prioritize resources by location clusters.
- Sectors: Public sector, NGOs, utilities.
- Tools/workflows: Incident management dashboard; streaming ingestion + geolocation; map overlays indicating confidence and error bounds; triage queues.
- Dependencies/assumptions: Recent aerial imagery; robust handling of extreme weather appearance shifts; capacity for real-time or near-real-time indexing and inference.
- Photo management and cloud galleries
- Description: Automatically suggest locations for photos without GPS tags (after edits, privacy settings, or legacy images), improving organization and search.
- Sectors: Consumer software, cloud storage.
- Tools/workflows: “Where was this taken?” feature; background geotagging job; on-device/offline presets for privacy; vector search over S2 cell codes.
- Dependencies/assumptions: On-device models may need dimensionality reduction; smartphone image domain shifts (benefit from 448px fine-tuning); user consent and privacy controls.
- Mapping/GIS dataset enrichment
- Description: Geotag large image archives or crowdsourced datasets to improve map coverage and metadata, especially in rural areas with sparse ground imagery.
- Sectors: GIS, mapping, government, research.
- Tools/workflows: Batch geotagging service; QA re-ranking overlay with aerial tiles; integration with S2-based tiling in GIS workflows.
- Dependencies/assumptions: Licensing for aerial tiles; region-specific databases; QA procedures for low-confidence cases.
- Insurance claims and compliance audits
- Description: Validate the location of damage or inspection photos, reducing fraud and improving audit trail integrity (e.g., site visits, infrastructure inspections).
- Sectors: Finance, insurance, energy, utilities, construction.
- Tools/workflows: Claims processing integration; policy compliance reports; anomaly detection by comparing claimed vs inferred locations.
- Dependencies/assumptions: Adequate aerial coverage; handling of close-up/occluded shots; clear consent and data retention policies.
- Real estate and travel platforms
- Description: Auto-geotag user-uploaded property or travel photos and improve search by neighborhood and POI proximity; enhance content discovery.
- Sectors: Real estate, travel, e-commerce.
- Tools/workflows: Upload-time geotagging; listing verification; neighborhood proximity filters; POI-based re-ranking.
- Dependencies/assumptions: Urban/rural performance balance; photo viewpoints vary (pedestrian vs road); business rules for confidence thresholds.
- GNSS-denied navigation fallback (regional)
- Description: Provide approximate geolocation from images when GPS is jammed/blocked; a prior for downstream 6-DoF localization or map-based relocalization.
- Sectors: Robotics, automotive, defense, industrial.
- Tools/workflows: Module delivering 100–200m priors to SLAM/localization stacks; edge inference with compact descriptors; ANN-based retrieval.
- Dependencies/assumptions: Prebuilt indexes for operating regions; inference latency constraints; viewpoint generalization (pedestrian/vehicle).
- Cultural heritage and archives
- Description: Localize historical photos and scanned images to reconstruct past urban/rural scenes; support digital humanities research.
- Sectors: Academia, museums, public sector.
- Tools/workflows: Archive geotagging pipeline; curator tools for manual validation; change-over-time map layers.
- Dependencies/assumptions: Changes in landscape over time; matching degraded images; reliance on contemporary aerial basemaps.
- OSINT analyst tooling (regional scale)
- Description: Rapid geolocation of social media images for incident verification, conflict analysis, or humanitarian monitoring.
- Sectors: Policy, NGOs, security.
- Tools/workflows: Analyst console with top-K candidates, interactive map browsing, similarity explanations; batch ingestion from social feeds.
- Dependencies/assumptions: Cross-domain robustness (smartphone, compression, blur); ethical use, consent, and safety considerations.
- Education and games
- Description: Power geography learning tools and location-based quizzes (e.g., GeoGuessr-style) with fine-grained, continent-level localization.
- Sectors: Education, gaming.
- Tools/workflows: Classroom apps; challenge modes with confidence ratings; interactive map feedback.
- Dependencies/assumptions: Coverage constraints; curated regions for consistent experiences.
- Academic research enablement
- Description: Benchmarking for geolocalization and cross-view retrieval; pre-training for remote sensing tasks; construction of new large-scale datasets with consistent S2 tiling.
- Sectors: Academia (CV, RS, GIS).
- Tools/workflows: Open-source code (as provided), reproducible S2 cell databases, multi-similarity loss recipes, backbone comparisons.
- Dependencies/assumptions: Access to aerial/ground datasets; compute resources; region-specific splits.
Long-Term Applications
These applications require further development, scaling, or research—e.g., global coverage, on-device inference, stronger cross-domain generalization, or integration with broader systems.
- Global-scale geolocation service (Earth-wide coverage)
- Description: A universal geoloc API providing meter-level location estimates for any image worldwide.
- Sectors: Software, media, public sector, enterprise.
- Tools/workflows: Global S2 hierarchy at L=16+; dynamic, up-to-date aerial databases; hierarchical ANN indices; adaptive calibration across regions.
- Dependencies/assumptions: Massive compute and storage; aerial coverage and update cadence; standardized legal frameworks for imagery use.
- On-device, privacy-preserving geolocation
- Description: Edge models running locally (phone/camera firmware) to geotag images without server-side data sharing.
- Sectors: Consumer devices, privacy tech.
- Tools/workflows: Model compression and quantization; distilled prototypes; regional packs; intermittent syncing of aerial tiles.
- Dependencies/assumptions: Tight memory/latency constraints; battery impact; opt-in privacy models; varying device capabilities.
- Integration into content provenance frameworks (e.g., C2PA)
- Description: Verify location claims as part of digital content authenticity pipelines; link geolocation confidence to provenance manifests.
- Sectors: Media, policy, cybersecurity.
- Tools/workflows: Provenance validators that cross-check claimed coordinates vs inferred; audit logs with confidence and error bounds.
- Dependencies/assumptions: Standardization across platforms; handling adversarial examples; legal implications of automated flags.
- Autonomous systems fallback in GNSS-denied environments (global)
- Description: Worldwide visual geolocation priors for autonomous cars, drones, and robots to maintain operation under GPS outages.
- Sectors: Robotics, automotive, aerospace, defense.
- Tools/workflows: Multi-sensor fusion pipelines; continuous map alignment; failover modes using visual priors; domain-adaptive training for diverse viewpoints.
- Dependencies/assumptions: Global aerial databases; robust cross-domain models (night, weather, terrain); safety certification.
- AR/XR place-anchoring and global relocalization
- Description: Fine-grained image-based priors enabling consistent real-world anchors for AR/XR, bootstrapping 6-DoF relocalization globally.
- Sectors: AR/VR, entertainment, retail.
- Tools/workflows: AR cloud services; hierarchical relocalization (coarse-to-fine); scene-change detection and map refresh.
- Dependencies/assumptions: Scalability with dynamic environments; occlusion handling; cross-device camera variations.
- Map maintenance, change detection, and asset management
- Description: Use discrepancies between prototypes and recent imagery to detect construction, closures, or environmental changes; manage utility/infrastructure assets.
- Sectors: GIS, energy, utilities, smart cities.
- Tools/workflows: Periodic re-indexing; delta detection dashboards; automated work orders linked to spatial anomalies.
- Dependencies/assumptions: Time-series aerial updates; false positive control; integrating ground truth validation.
- Environmental monitoring and citizen science at scale
- Description: Geolocate citizen images of flora/fauna, pollution, or hazards; enrich ecological datasets with spatial accuracy.
- Sectors: Environment, academia, NGOs.
- Tools/workflows: Mobile apps with on-device geoloc; scientific curation pipelines; quality filters for confidence and error thresholds.
- Dependencies/assumptions: Domain adaptation for diverse content; volunteer consent and ethics; seasonal appearance variations.
- Real-time OSINT at global scale
- Description: Geolocate large volumes of social media imagery during crises; provide situational awareness with location clustering and confidence metrics.
- Sectors: Policy, humanitarian, security.
- Tools/workflows: Streaming ingestion; scalable ANN retrieval; analyst triage; automated alerts by region themes.
- Dependencies/assumptions: Huge throughput; cross-platform data agreements; misinformation and adversarial content handling.
- Multi-modal geolocation (image + text + audio)
- Description: Fuse visual signals with captions, audio, and metadata to improve geolocation accuracy and robustness.
- Sectors: Software, media, academia.
- Tools/workflows: Vision-LLMs; cross-modal retrieval; conflict resolution heuristics; provenance-aware fusion.
- Dependencies/assumptions: Access to multi-modal data; privacy compliance; robust alignment across modalities.
- Coverage for data-poor regions via aerial-only databases
- Description: Extend applicability to areas without ground imagery using only aerial tiles; improve recall through enhanced cross-view training.
- Sectors: GIS, public sector, NGOs.
- Tools/workflows: Aerial-only indexes; specialized augmentations for appearance gaps; adaptive calibration by terrain type.
- Dependencies/assumptions: Quality and resolution of aerial/satellite imagery; domain gap mitigation; altitude and terrain effects.
- Crowdsourced mobile mapping integration
- Description: Use user-submitted images to update prototypes and improve local recall; continuous learning from fresh content.
- Sectors: Mapping, consumer, transport.
- Tools/workflows: Federated or privacy-preserving updates; drift detection; regional reweighting (urban vs rural).
- Dependencies/assumptions: Incentives and consent; safeguarding against malicious contributions; infrastructure for continuous retraining.
- Remote sensing pre-training and downstream tasks
- Description: Use learned prototypes and cross-view embeddings to pre-train models for land use, segmentation, object detection in aerial imagery.
- Sectors: Remote sensing, agriculture, environment.
- Tools/workflows: Transfer learning pipelines; task-specific fine-tuning; benchmark suites across continents.
- Dependencies/assumptions: Availability of labeled downstream datasets; transfer effectiveness across resolutions and sensors.
- Financial risk modeling and compliance analytics
- Description: Geolocate images tied to assets/events to strengthen geospatial risk assessments (e.g., floodplain exposure, site compliance).
- Sectors: Finance, insurance, ESG.
- Tools/workflows: Risk dashboards integrating geoloc confidence; audits with geo-evidence trails; climate resilience reporting.
- Dependencies/assumptions: Accurate geospatial layers; regulatory acceptance of automated geoloc evidence; model transparency.
Notes on feasibility and assumptions common across applications:
- Coverage and recency of aerial/satellite imagery strongly affect accuracy; rural areas are more challenging when ground imagery is sparse.
- Smartphone and pedestrian viewpoints require fine-tuning (the paper shows large gains with DINOv3-L16 at 448px).
- Building region-specific indexes is needed; generalization to unseen areas via aerial-only databases reduces performance.
- Legal/licensing and privacy constraints apply to both ground-level and aerial data; human-in-the-loop review is advisable for high-stakes use.
- Compute and storage requirements are manageable at continental scale (tens of GB for indexes), but global deployment requires substantial infrastructure and scalable ANN retrieval.
Glossary
- 6-DoF positioning: Estimating a camera’s full 3D position and orientation (six degrees of freedom) in space. "such as 6-DoF positioning based on 3D point clouds or 2D maps"
- Adam optimizer: A stochastic gradient-based optimizer that adapts learning rates per-parameter using first and second moment estimates. "We use the Adam~\cite{kingma2014adam} optimizer"
- aerial embeddings: Vector representations of overhead (aerial/satellite) image tiles learned by a neural encoder. "Prototypes and aerial embeddings are then combined into cell codes"
- aerial tiles: Fixed-size overhead image patches used as database elements for localization. "We define aerial tiles of fixed size and ground sampling distance"
- calibration factor: A scalar used to balance similarity magnitudes between different embedding sources. "The calibration factor $\inR$ is introduced"
- camera frustum: The 3D pyramidal region of space visible to a camera, used here to weight nearby cells. "the camera frustum of the query"
- cell codes: Combined descriptors per spatial cell formed by fusing classification prototypes with aerial embeddings. "We propose to perform retrieval over cell codes"
- contrastive learning: A training paradigm that pulls together matched (positive) pairs and pushes apart mismatched (negative) pairs in embedding space. "We follow a contrastive learning formulation"
- CosFace loss: A margin-based softmax loss for learning discriminative features in classification. "CosFace loss~\cite{wang2018cosface}"
- cosine schedule: A learning rate schedule that follows a cosine decay curve over training. "using a cosine schedule"
- cross-view retrieval: Matching images across drastically different viewpoints (e.g., ground vs. aerial). "cross-view retrieval between ground and aerial imagery"
- DCL: Decoupled Contrastive Learning, a variant of contrastive loss. "DCL~\cite{yeh2022decoupled}"
- DINOv2: A self-supervised Vision Transformer backbone frequently used for feature extraction. "DINOv2"
- DINOv3-L16: A large Vision Transformer variant from DINOv3 used as an encoder backbone. "DINOv3-L16"
- domain gap: The distributional difference between data sources (e.g., ground vs. aerial) that hinders direct matching. "suffers from a domain gap"
- EXIF metadata: Image header information (e.g., GPS, camera settings) stored in a standardized format. "EXIF metadata was accidentally stripped"
- farthest point sampling: A selection strategy that iteratively picks the next sample farthest from all selected ones to maximize coverage. "we select panoramas via farthest point sampling over both space and capture time"
- field-of-view (FOV): The angular extent of the observable scene captured by the camera. "field-of-view (FOV)"
- fish-eye cameras: Cameras with ultra wide-angle lenses producing strongly curved (fisheye) distortion. "fish-eye cameras"
- geotagged: Labeled with geographic coordinates (latitude/longitude). "geotagged ground-level images"
- GPS priors: Approximate location estimates from GPS used to constrain search. "require GPS priors"
- ground sampling distance: The real-world size represented by each image pixel in overhead imagery. "ground sampling distance"
- Ground-to-ground image retrieval: Localization by matching a query ground photo against a database of ground photos. "Ground-to-ground image retrieval"
- hard-negative mining: Selecting difficult non-matching examples to improve discriminative training. "hard-negative mining (using k-NN)"
- Haversine loss: A loss function based on the Haversine (great-circle) distance on the Earth’s sphere. "Haversine loss~\cite{haas2024pigeon}"
- Hierarchical loss: A loss that leverages a multi-level spatial hierarchy during classification. "Hierarchical loss~\cite{astruc2024openstreetview}"
- InfoNCE: A widely used contrastive loss based on normalized temperature-scaled cross-entropy. "InfoNCE~\cite{oord2018representation}"
- k-NN: k-nearest neighbors, used for retrieval or mining hard negatives. "k-NN"
- l2-normalized embeddings: Feature vectors scaled to unit L2 norm to stabilize similarity computations. "-normalized embeddings"
- multi-similarity loss: A ranking loss combining multiple similarity terms to better structure embeddings. "multi-similarity loss~\cite{wang2019multi}"
- near-nadir imagery: Overhead images captured with viewing angles close to vertical. "near-nadir imagery"
- optimal transport head: A feature aggregation module that uses optimal transport to pool patch embeddings. "optimal transport head introduced in SALAD"
- overhead imagery: Aerial or satellite images captured from above. "Overhead imagery is also easier to acquire"
- PCA visualization: Using Principal Component Analysis to project high-dimensional features for visualization. "PCA visualization of the learned prototypes"
- pinhole camera model: An idealized projection model used to render perspective crops from panoramas. "pinhole camera model"
- prototypes: Learned class-representative vectors summarizing visual characteristics of a spatial cell. "prototypes"
- Recall@@200m: The fraction of queries with at least one of the top-K results within 200 meters of ground truth. "Recall@@200m"
- rolling-shutter: A sensor readout where rows are captured sequentially, causing motion-induced distortions. "rolling-shutter"
- S2 cell library: A spherical geometry library that partitions the globe into hierarchical cells. "S2 cell library"
- SALAD: A VPR method that uses an optimal transport-based aggregation head for robust descriptors. "SALAD"
- TPUv2: Google’s second-generation Tensor Processing Unit hardware accelerator. "TPUv2"
- Vision Transformers: Transformer-based neural network architectures adapted for image understanding. "Vision Transformers~\cite{vit}"
- Visual Place Recognition (VPR): The task of recognizing the location of a scene from an image by retrieving similar places. "Visual Place Recognition (VPR)"
- roll, pitch, yaw: The three rotational degrees of freedom of a camera around its axes. "random roll, pitch, yaw, and FOV"
Collections
Sign up for free to add this paper to one or more collections.