- The paper demonstrates that Grokipedia closely mirrors Wikipedia in semantic and stylistic terms but diverges structurally, evidenced by lower citation and heading densities.
- It employs diverse NLP metrics across lexical, semantic, stylistic, and structural dimensions to quantify alignment between matched article pairs.
- The findings highlight Grokipedia's narrative expansion at the expense of verifiability, emphasizing challenges for AI-generated content credibility.
Multi-Dimensional Comparison of Grokipedia and Wikipedia: Textual and Structural Alignment
Introduction
This study presents a comprehensive computational analysis of Grokipedia, an AI-generated encyclopedia developed by xAI, in comparison to Wikipedia, the canonical human-edited online encyclopedia. The analysis is motivated by claims that Grokipedia offers a "truthful" alternative to Wikipedia, purportedly correcting ideological and structural biases through automated content generation. The research addresses the empirical question: to what extent does Grokipedia diverge from or replicate Wikipedia in terms of textual, semantic, structural, and stylistic properties? The study leverages a large-scale matched corpus of 1,811 article pairs, drawn from the 2,000 most-edited English Wikipedia pages, to quantify cross-platform similarities and differences using a suite of established NLP metrics.
Data Collection and Methodology
The dataset comprises 1,811 matched article pairs, each exceeding 500 words of clean prose, ensuring topical breadth and textual substance. Articles were extracted using platform-specific HTML parsing strategies to maximize content fidelity and exclude non-prose elements (e.g., infoboxes, navigation, scripts). Feature extraction encompassed:
- Structural features: Paragraphs, headings, hyperlinks, images, references, and derived ratios (e.g., references per 1,000 words).
- Stylistic and readability features: Sentence length, lexical diversity (type-token ratio), Flesch–Kincaid grade, Gunning–Fog index, and POS composition.
- Lexical and semantic similarity: TF–IDF cosine, unigram Jaccard, n-gram overlap, SentenceTransformer embedding cosine, and BERTScore.
- Structural and stylistic similarity: Section heading overlap, paragraph length similarity, and normalized stylistic profile distance.
Similarity metrics were grouped into four domains: lexical, semantic, structural, and stylistic. A composite similarity index was computed as the mean of these sub-scores.
Grokipedia articles are systematically longer than their Wikipedia counterparts, with an average of 14,200 words versus 9,400 for Wikipedia. This length inflation is not accompanied by increased lexical diversity; in fact, Grokipedia exhibits slightly lower type-token ratios. Readability, as measured by the Flesch–Kincaid grade, is higher for Grokipedia, indicating more syntactically complex and less accessible prose. Reference, link, and heading densities are all substantially lower in Grokipedia, suggesting a preference for narrative expansion over citation-based verification or detailed structural organization.
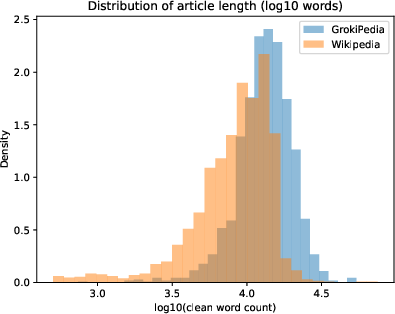
Figure 1: Distribution of clean word counts by platform (log scale).
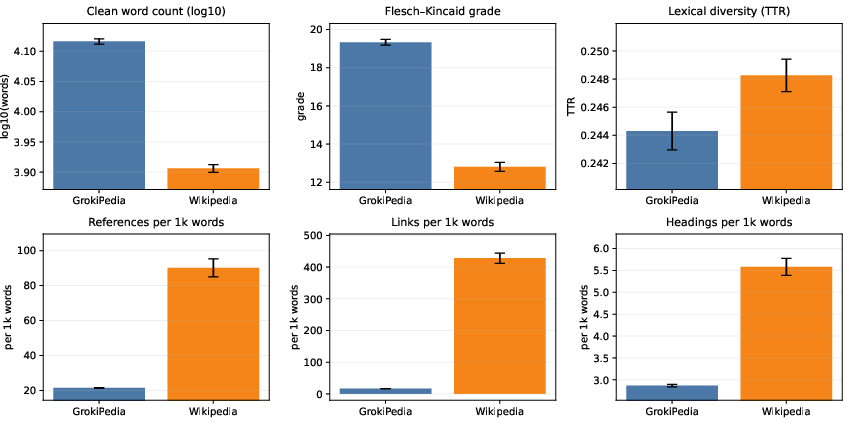
Figure 2: Platform differences for key descriptives (means ± standard error): (A) clean word count (log10), (B) Flesch–Kincaid grade, (C) lexical diversity (TTR), (D) references per 1k words, (E) links per 1k words, (F) headings per 1k words.
Lexical and semantic similarity metrics indicate strong alignment between Grokipedia and Wikipedia. The mean TF–IDF cosine similarity is 0.505, and the mean semantic embedding cosine is 0.825. Stylistic similarity is also high (mean 0.835), reflecting close alignment in sentence structure and POS composition. However, structural similarity is markedly lower (mean 0.216), indicating that Grokipedia diverges in sectioning, paragraph organization, and reference structure.
Correlation analysis among similarity metrics reveals that lexical and semantic measures are tightly clustered, while structural and stylistic similarities are more independent, reflecting the distinct editorial logics of the two platforms.
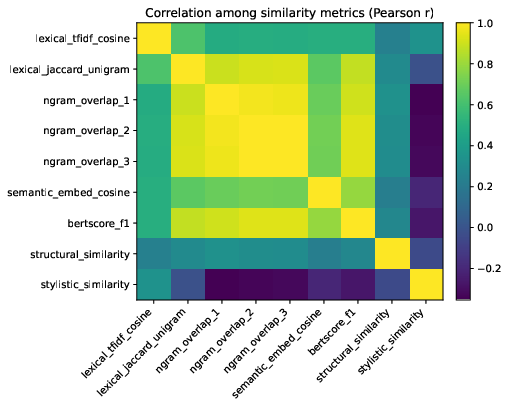
Figure 3: Correlation among similarity metrics (Pearson's r) across 1,811 article pairs.
Distributional Properties of Similarity Metrics
The empirical distributions of similarity scores are predominantly unimodal and right-skewed for lexical and semantic metrics, indicating that most Grokipedia articles are moderately to highly aligned with their Wikipedia counterparts in content and style. Structural similarity, by contrast, is more dispersed, reflecting Grokipedia's greater variability in organizational patterns.
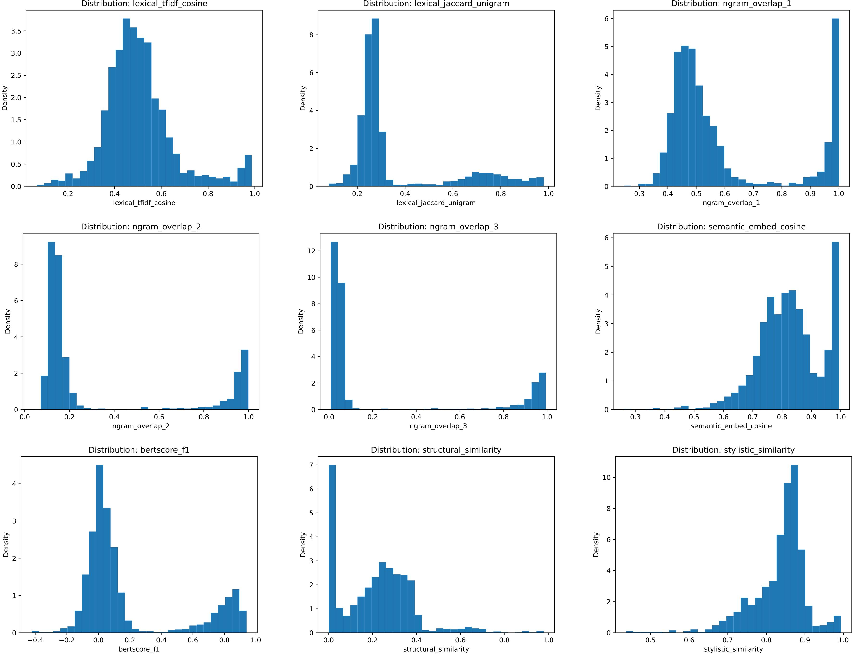
Figure 4: Empirical distributions of similarity scores across metrics. Each panel corresponds to one of the nine metrics.
Interpretation and Implications
The results demonstrate that Grokipedia, despite its AI-driven authorship, functions primarily as a synthetic derivative of Wikipedia. High semantic and stylistic similarity scores indicate that Grokipedia reproduces much of Wikipedia's linguistic and conceptual structure. However, Grokipedia's articles are longer, less lexically diverse, and contain fewer references and structural markers, suggesting a generative process that prioritizes rhetorical expansion over evidentiary rigor.
This divergence has significant epistemological implications. Wikipedia's editorial model foregrounds transparency, provenance, and contestation, with visible edit histories and citation requirements. Grokipedia, by contrast, offers fluency and narrative coherence at the expense of verifiability and structural transparency. The opacity of Grokipedia's generative pipeline precludes provenance auditing and renders bias latent within model parameters, rather than explicit and correctable through community deliberation.
The findings also highlight the limitations of surface-level similarity metrics. While Grokipedia mirrors Wikipedia in form and tone, the study does not address factual accuracy, ideological framing, or the presence of hallucinated content—dimensions that are critical for evaluating the epistemic reliability of AI-generated knowledge.
Limitations and Future Directions
The analysis is constrained by its focus on the most-edited Wikipedia articles, which are disproportionately controversial and socially salient. The similarity metrics employed quantify textual and structural alignment but do not capture deeper factual or ideological divergences. Both platforms are dynamic, and Grokipedia's content-generation pipeline remains opaque, limiting causal inference regarding model bias or editorial intervention.
Future research should extend beyond textual similarity to assess factual divergence, ideological asymmetry, and user trust. Comparative studies of reader perceptions and credibility judgments across human-edited and AI-generated encyclopedias are warranted. Additionally, the development of methods for auditing provenance and detecting latent bias in generative models is an urgent priority for the governance of synthetic knowledge.
Conclusion
This study provides a rigorous, multi-dimensional comparison of Grokipedia and Wikipedia, revealing that Grokipedia is highly aligned with Wikipedia in semantic and stylistic terms but diverges in structural organization and evidentiary scaffolding. Grokipedia's generative process yields longer, more complex, but less verifiable articles, reflecting a shift from collective accountability to computational authority. As AI-generated content becomes increasingly prevalent in knowledge production, ensuring transparency, provenance, and contestability remains a central challenge for both technical and institutional innovation.