- The paper introduces a novel PCM-based directional coupler design replacing traditional MZIs to achieve high-contrast, low-loss, and compact photonic circuits.
- It employs a progressive NAS routine with pruning techniques to achieve over 80% matrix fidelity while dramatically reducing active device count and on-chip footprint.
- Experimental and simulated results demonstrate up to 85% footprint reduction and over 50% power savings, validating the approach for efficient DNN acceleration.
LightPro: Fully Programmable Linear Photonic Processor for Scalable Optical AI Acceleration
Introduction
The paper "LightPro: A Linear Photonic Processor with Full Programmability" (2510.27013) proposes a scalable and fully programmable silicon photonic (SiPh) processor architecture targeting the fundamental need for efficient matrix-vector multiplication (MVM) within deep neural networks (DNNs). The approach addresses critical scalability and integration challenges associated with conventional Mach–Zehnder Interferometer (MZI)-based networks (such as the Clements mesh), including excessive optical loss, phase/crosstalk noise, high active power requirements, and prohibitive on-chip footprint. The LightPro paradigm substitutes the core MZI blocks with non-volatile, compact, and programmable phase-change material (PCM)-based directional couplers (DCs), integrating them with columns of tunable phase shifters. The resulting architecture is co-optimized with a dedicated neural architecture search (NAS) strategy, incorporating model-driven pruning and reconfiguration techniques to ensure application-specific efficiency without sacrificing computational fidelity.
Device and Architecture Foundations
The backbone of LightPro is a PCM-based silicon photonic DC whose coupling coefficient is reconfigurably set by tuning the phase state of Sb2Se3 PCM overlays via thermal microheaters. By transitioning the PCM between amorphous and crystalline states, designers gain access to a wide, non-volatile range of coupling ratios, thus enabling high-contrast, low-loss, and area-efficient programmable beam splitters. The phase-matching design, including waveguide/PCM width and offset adjustments, is key to maximizing contrast while minimizing insertion loss and crosstalk.
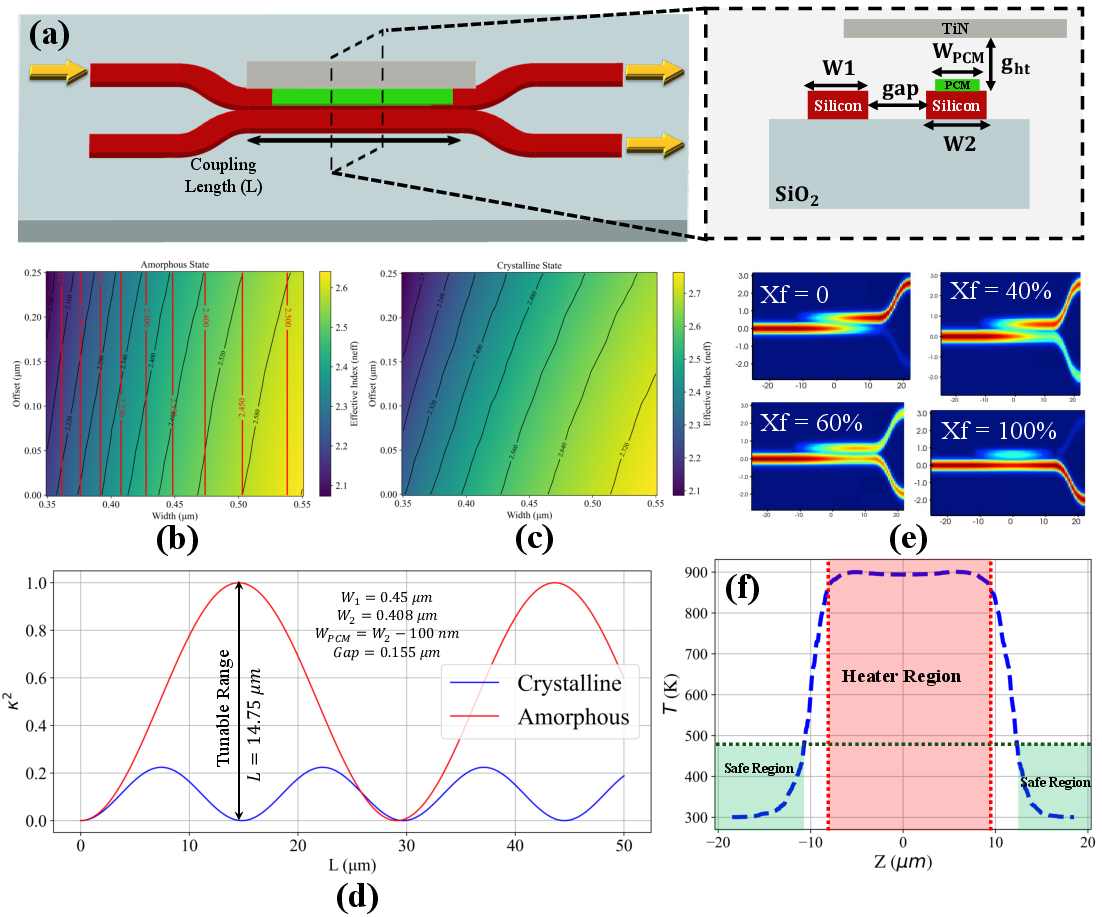
Figure 1: Device-level view of the tunable PCM-based directional coupler, demonstrating the impact of phase state on effective refractive index and the resulting coupling behavior.
LightPro's system-level architecture leverages these devices by implementing weight matrices derived from DNNs trained on fast Fourier transformed datasets. Singular value decomposition (SVD) is used to factor each weight matrix into a product of two unitary matrices and a diagonal matrix; only the unitary matrices are mapped to the photonic core, exploiting the universality of cascaded DCs and phase shifters for implementing arbitrary unitary transformations.
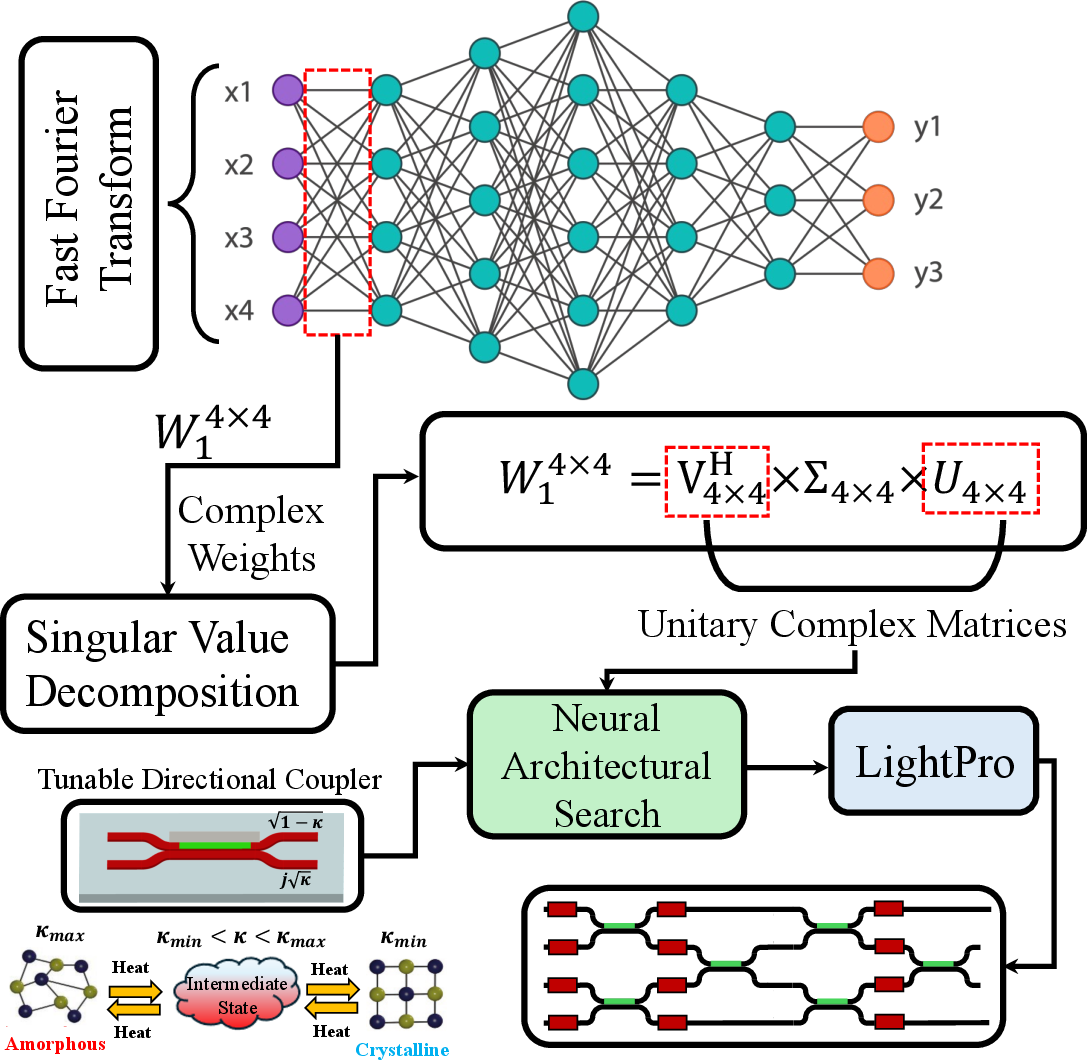
Figure 2: End-to-end mapping pipeline from high-frequency dataset features to decomposed weight matrices and ultimately to PCM-programmed photonic mesh for MVM.
Neural Architecture Search and Pruning
To systematically identify optimal mesh configurations, a progressive NAS routine is introduced. Beginning with an empty network, the algorithm iteratively appends device columns (either DCs or phase shifters) and jointly optimizes tunable parameters with respect to a fidelity objective comparing implemented and target unitary matrices. The process continues until the network meets a preset fidelity threshold (e.g., F>0.98).
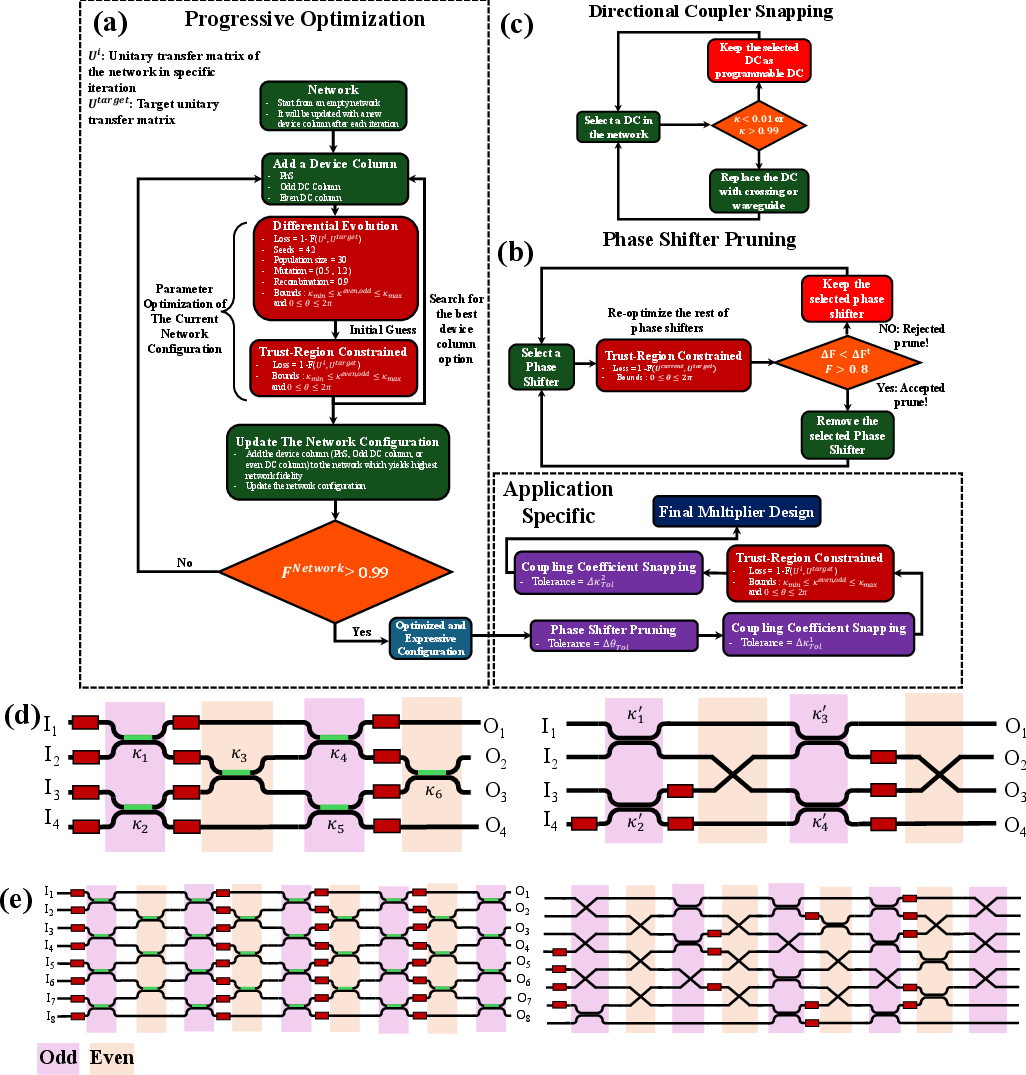
Figure 3: Workflow of progressive NAS-driven topology construction, device placement, and parameter optimization, followed by pruning and device snapping.
Once a general-purpose network architecture is established, application-specific optimization removes nonessential phase shifters using toleranced pruning thresholds while ensuring >80% fidelity (chosen because accuracy loss remains negligible above this boundary per empirical evaluation). Similarly, DCs with near-0 or near-1 coupling coefficients are replaced with passive waveguide sections (snapping), further minimizing footprint and insertion loss.
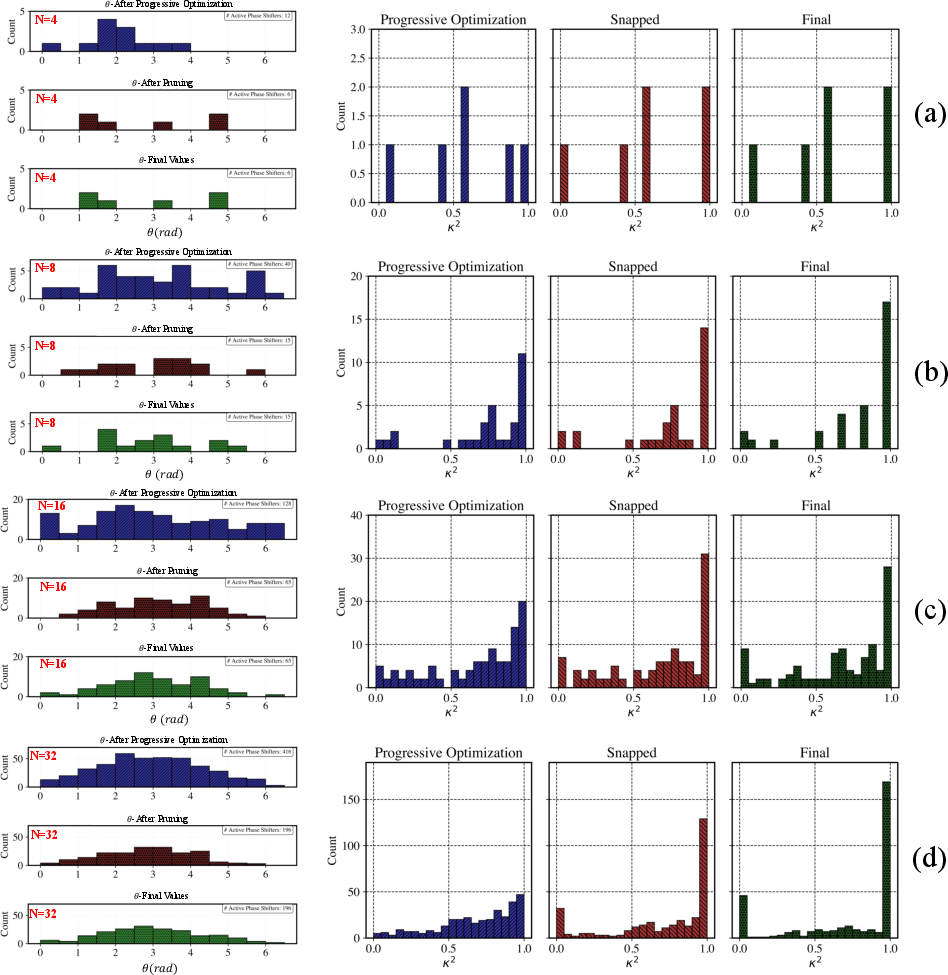
Figure 4: Distributions of phase shifts and coupling coefficients in the network, before and after NAS optimization and pruning.
Fidelity and Expressivity
Extensive simulations with mesh sizes up to 32×32 demonstrate that the pruned LightPro architecture can express arbitrary complex unitary matrices through parameter retuning, maintaining an average fidelity above $0.97$ for 100 sampled random targets. When specialized to fixed-weight inference tasks, pruning and device snapping enable dramatic hardware reductions with negligible loss in computational accuracy.
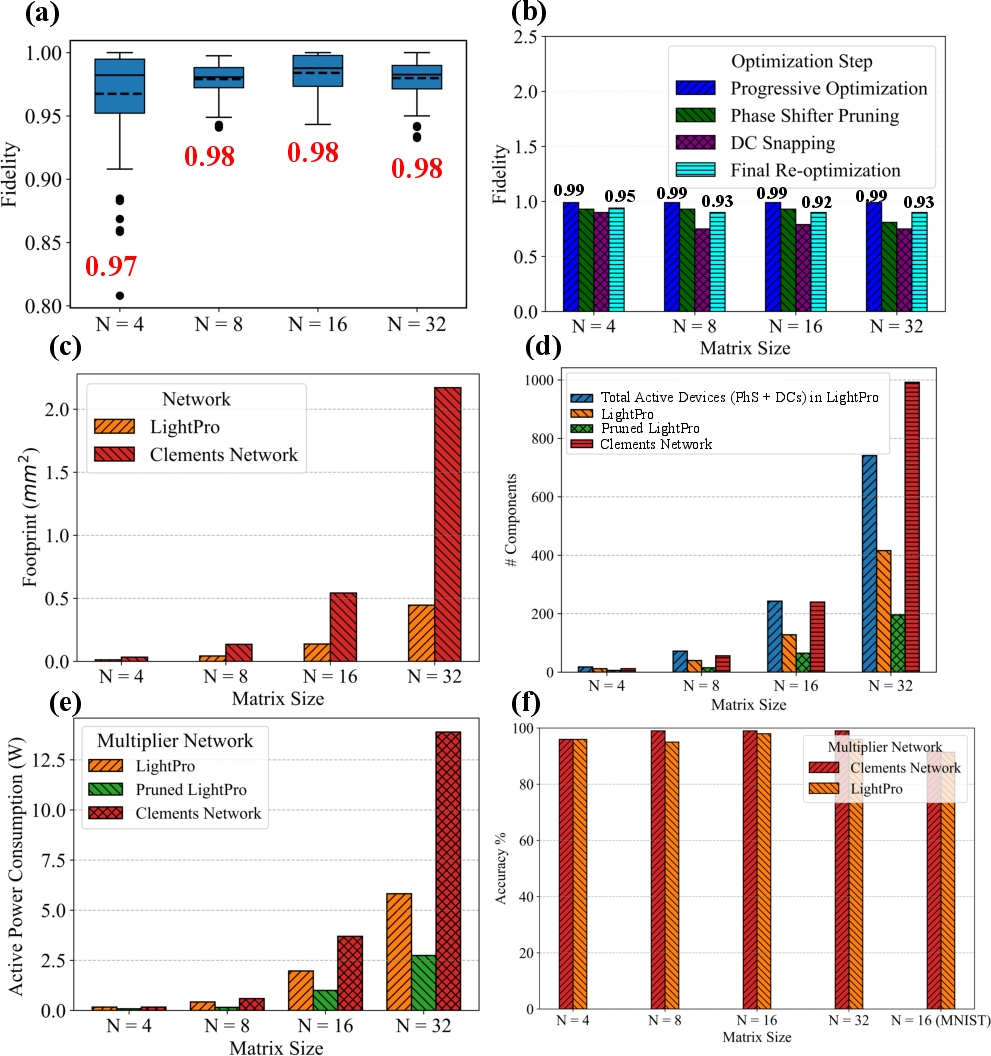
Figure 5: (a) Fidelity boxplots across random unitary matrix realizations; (b) fidelity versus optimization/pruning stages; (c) on-chip footprint comparisons; (d) active device counts; (e) phase shifter active power consumption; (f) inference accuracy post-pruning across datasets and network widths.
Area and Power
The most notable hardware results include up to 85% reduction in on-chip footprint and over 50% reduction in active phase shifter power consumption relative to equivalently sized MZI-based Clements meshes. The non-volatility of the PCM-based DCs eliminates static energy draw, and pruning reduces phase shifter usage by up to 67%. Even under cumulative pruning, accuracy loss on Gaussian and FFT-MNIST benchmarks is consistently below 5%.
Experimental Verification
A pruned 4×4 LightPro mesh was experimentally emulated using a commercial iPronics SmartLight processor, which provides a versatile MZI-based hardware programmable mesh. The experimental outcomes, when compared with both circuit simulations and mathematical MVM outputs, exhibited close agreement, validating both the device-level operation and the end-to-end model/hardware co-design process.
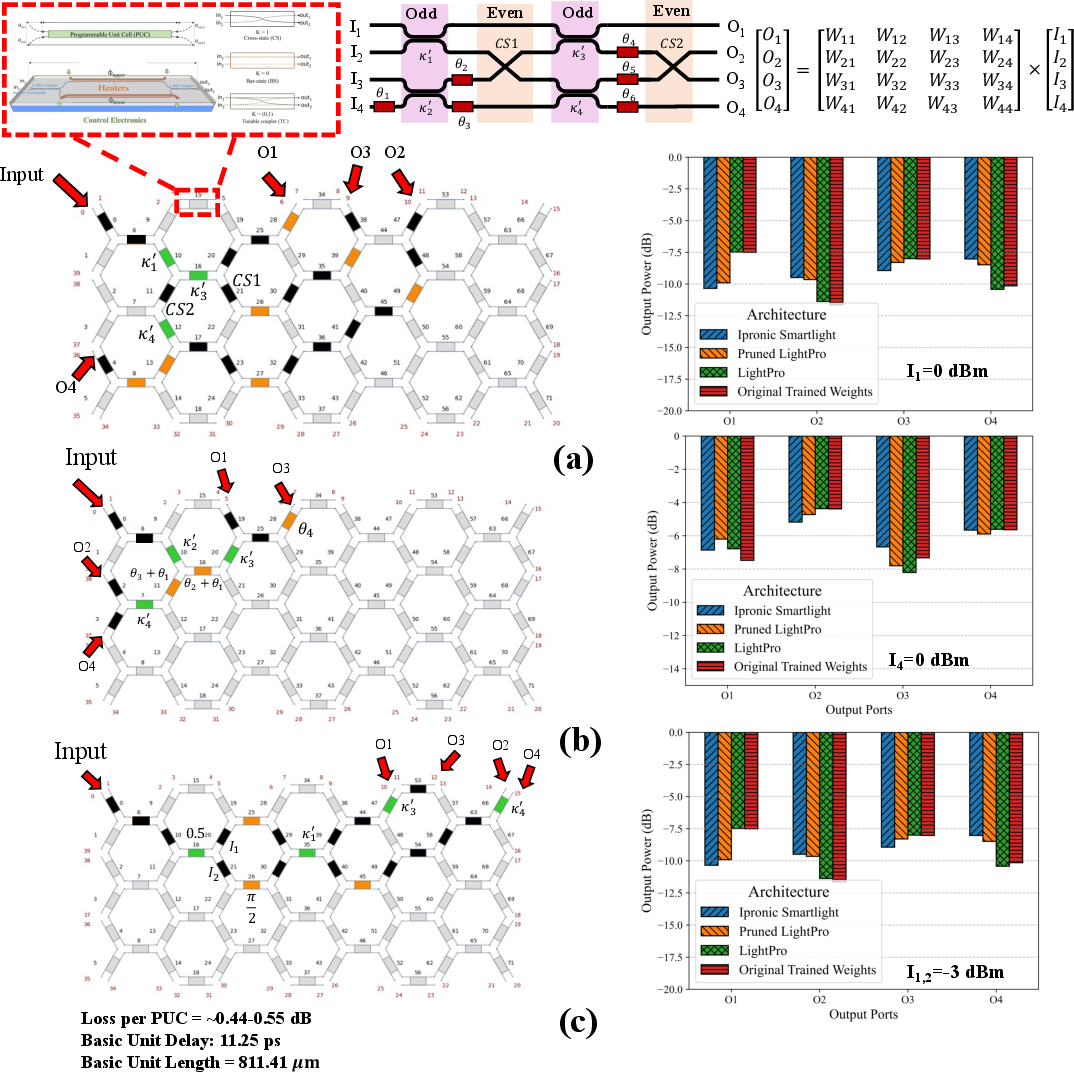
Figure 6: Experimental validation of LightPro and its pruned implementation using real device output measurements for multiple input vector configurations.
Theoretical and Practical Implications
LightPro effectively demonstrates that SiPh-based MVM accelerators can exploit PCM-enabled programmability to mitigate the scaling limits imposed by traditional interferometric meshes. By decoupling the need for continuously powered phase shifters and replacing bulk MZIs with compact, reconfigurable DCs, substantial improvements in area and energy efficiency are realized without sacrificing dense, single-frequency operation or computational expressivity.
The NAS-powered, hardware-aware co-design loop provides hardware/software codesign opportunities extending beyond photonic MVM hardware to general programmable unitary processors—including quantum information flows and signal processing tools.
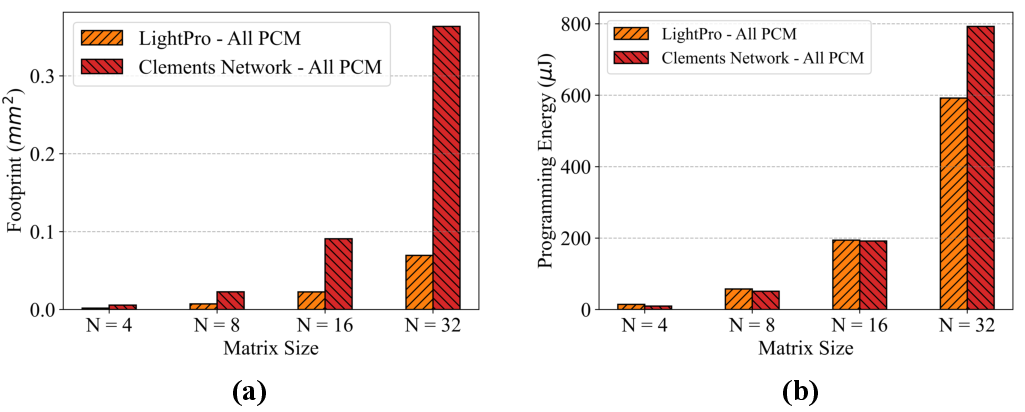
Figure 7: Footprint and programming energy evaluation when all phase shifters are implemented with PCM devices, revealing strong advantage over MZI-based alternatives.
Limitations and Future Directions
While the current study models Sb2Se3 as the PCM, the architecture is agnostic to material choice as long as the optical loss and refractive index contrast criteria are met. Progress in phase state discrimination, for example via nitrogen doping, will further enhance coupling coefficient resolution and network tunability. Process variations, thermal crosstalk, and PCM endurance remain system-level concerns, but early modeling and modest experimental validation substantiate LightPro's resilience and practical manufacturability.
The broader implication is that with improved photonic process control, higher-density integration, and full-stack co-design (including adaptive training protocols that match photonic mesh topology), LightPro-like architectures are primed to play a significant role in ultra-low-power AI and scientific computing domains.
Conclusion
LightPro establishes a systematic, experimentally-validated pathway for scalable and fully programmable photonic processors that exploit non-volatile PCM-based programmable elements and NAS-driven mesh synthesis to overcome the primary obstacles limiting mainstream adoption of photonic MVM accelerators. LightPro achieves strict performance metrics—area, active and programming energy, computational expressivity and fidelity—for both general-purpose and application-specialized workloads. The work points to a future where photonic AI accelerators, coordinated by intelligent software/hardware codesign, merge high-performance computing and energy efficiency unattainable by electronic means alone.