- The paper comprehensively surveys deep text hashing methods that encode texts into binary codes for efficient semantic retrieval.
- It details semantic extraction techniques, including reconstruction-based and pseudo-similarity methods, to enhance retrieval performance.
- It discusses hash code quality considerations such as balance, few-bit representation, and low quantization error in large-scale text data.
"A Survey on Deep Text Hashing: Efficient Semantic Text Retrieval with Binary Representation" (2510.27232)
Introduction
The exponential growth of textual data on the internet necessitates efficient methods for large-scale semantic retrieval. Deep text hashing addresses this by projecting texts into compact binary hash codes, enabling rapid semantic similarity calculations using Hamming distances and reducing storage costs. This approach integrates deep learning techniques, leveraging neural networks to generate semantically rich binary codes surpassing the performance of traditional hashing. This survey provides a systematic overview of deep text hashing, focusing on semantic extraction techniques, hash code quality, evaluation results on benchmark datasets, practical applications, and challenges.
Deep Text Hashing Framework
Nearest Neighbor Search
In high-dimensional spaces, finding exact nearest neighbors is computationally expensive. Approximate Nearest Neighbors (ANN) search methods, including hashing, address efficiency by evaluating subsets of data. Hashing techniques are particularly advantageous due to their speed and low memory usage. Methods like Locality Sensitive Hashing (LSH) map similar data into the same hash bucket with varying success depending on the complexity of the data.
Fundamentals
Deep text hashing transforms high-dimensional text data x∈Rd into binary vectors h∈{−1,1}b. The process involves using deep neural networks to encode data into a lower-dimensional binary space, with goals like code compactness, balance, and low quantization error.
Search Techniques
The basic search framework maps texts to binary vectors using trained models, deploying fast search technologies using ranking or hash table lookups. Hash table lookups optimize search by accessing buckets corresponding to the hash code, with multi-index hashing helping reduce the number of operations (Figure 1).
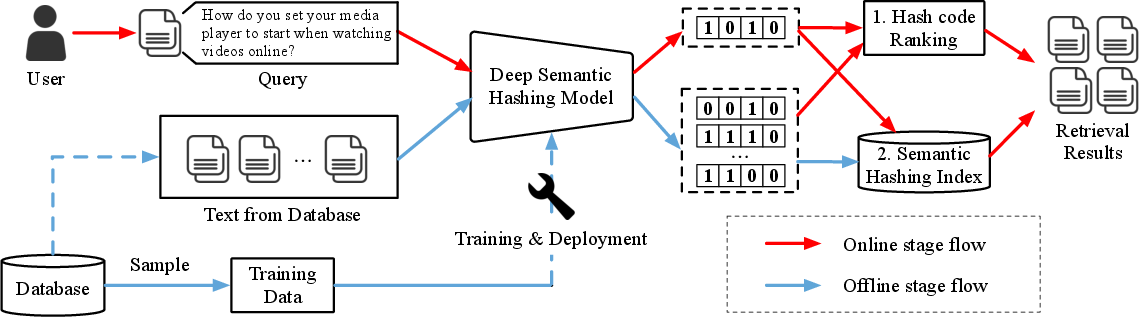
Figure 1: The basic search framework for deep text hashing.
Deep text hashing methods derive from semantic extraction to ensure similar semantics map close in Hamming space. Strategies include:
- Reconstruction-based Methods: Utilize autoencoder frameworks with reconstruction objectives, sometimes deploying VAE to impose distributional constraints on latent representations for effective hash code generation.
- Pseudo-similarity-based Methods: Fabricate pseudo-similarity as supervisory signals through clustering or weak supervision methods intertwined with hash code generation for task-specific learning.
- Maximal Mutual Information: Maximizes mutual information between latent and label variables, providing a more principle-based learning signal.
- Semantic from Categories: Integrates label-based category information to enhance supervision through classification objectives, aligning hash codes with defined semantic groups (Figure 2).
- Semantic from Relevance: Utilize pair-wise learning from relevance signals to capture nuanced text relationships, supporting fine-grained semantic differentiation.
Figure 2: An illustration of two mainstream deep text hashing frameworks employing the VAE architecture. (1) VDSH follows Gaussian priors; (2) NASH aligns with Bernoulli priors.
Hash Code Quality Considerations
Key focus areas include:
- Few-bit Code: Optimize code length for efficient retrieval while balancing semantic information retention.
- Code Balance: Even distribution of hash codes to minimize retrieval bias and optimize Hamming distance calculations.
- Low Quantization Error: Minimize information loss during the transition from continuous to binary representations, leveraging advanced activation function strategies.
Innovations and Advancements
Recent advancements tackle open-world scenarios, leveraging robustness enhancements and adapting to evolving domain requirements through dynamic hashing techniques. Integration with LLMs suggests pathways for scaling semantic richness without compromising on computational efficiency—addressing index construction and retrieval speed through sophisticated backend solutions.
Conclusion
Deep text hashing provides critical improvements in retrieving semantically relevant data efficiently at scale. As text data continues to grow, these methods will require continuous evolution, exploring adaptive frameworks and integrations with LLMs, further enhancing the capacity to handle diverse and dynamic datasets efficiently. Streamlined evaluation benchmarks will facilitate the development of more refined models, ensuring practical applicability across domains.