- The paper presents a novel NVFP4-based method that uses unbiased double-block quantization to reduce weight oscillation and manage outlier inaccuracies.
- It introduces OsciReset to stabilize weights and OutControl to retain gradient accuracy during low-precision training.
- Experimental results demonstrate improved training and validation performance, reducing the gap with full-precision methods for cost-effective LLM training.
Summary of "TetraJet-v2: Accurate NVFP4 Training for LLMs with Oscillation Suppression and Outlier Control"
Introduction
The paper presents TetraJet-v2, a comprehensive approach to training LLMs using fully quantized 4-bit representations. This approach leverages NVFP4 for activations, weights, and gradients, ensuring efficient computation while mitigating common issues such as weight oscillation and outlier inaccuracies. The need for low-precision training stems from the prohibitive cost of training large models, which can exceed hundreds of millions of dollars. NVFP4 offers advantages over previous formats due to its microscale quantization, which reduces quantization errors for tensors containing outliers.
Challenges in Low-Precision Training
Two main challenges are identified: weight oscillation and outlier features. Weight oscillation involves quantized weights fluctuating between bins without significant changes in high precision weights, negatively impacting model performance. Outlier features refer to activation channels with large magnitudes that can't be accurately represented at low precision. TetraJet-v2 proposes solutions to these issues, including unbiased double-block quantization, OsciReset to suppress weight oscillation, and OutControl for outlier accuracy retention.
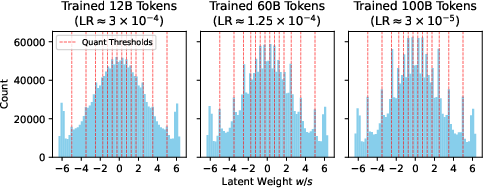
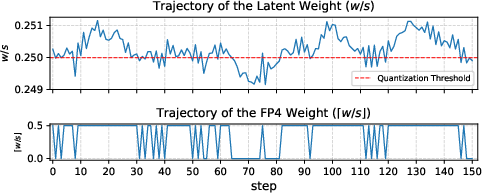
Figure 1: The distribution of latent weight w/s in OLMo2-150M blocks.11.att_proj in NVFP4 training without oscillation suppression.
TetraJet-v2's NVFP4 Linear Layer Design
TetraJet-v2 employs an unbiased double-block quantization method to accurately convert high precision matrices to NVFP4 format. The proposed approach divides matrices into smaller groups to assign scaling factors efficiently, optimizing representation accuracy while minimizing runtime complexity.
The NVFP4 Linear Layer design involves quantizing inputs with unbiased stochastic rounding to ensure gradient estimation aligns with the high precision model structure. This approach, combined with finer outer-block scaling, improves training stability compared to previous methods.
Oscillation Suppression with OsciReset
OsciReset is introduced to address oscillation by resetting the master weights to the center of the quantization bin, mitigating detrimental fluctuations at low learning rates. The methodology identifies oscillating weights and applies adjustments to stabilize them without degrading global optimization performance.
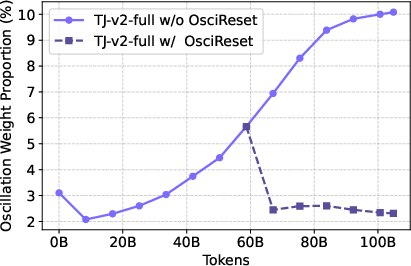
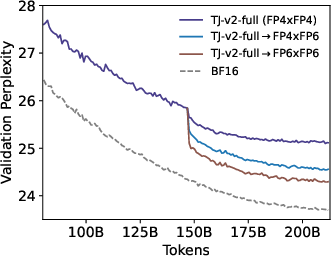
Figure 2: The change of the oscillation proportion with/without OsciReset on OLMo2-150M.
Outlier Control with OutControl
OutControl uses random Hadamard transformations to manage outliers during backpropagation, maintaining gradient accuracy. Additionally, outlier channels with larger variance are statically selected for higher precision retention, enhancing both forward and backward computations.
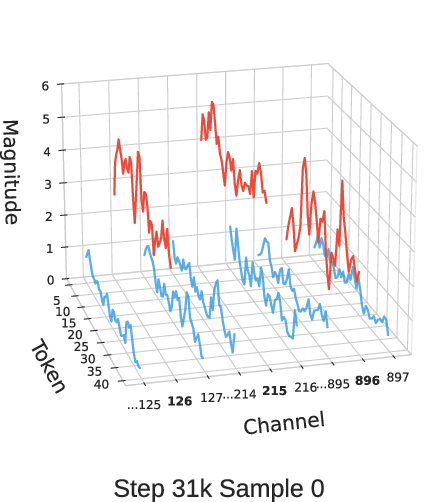
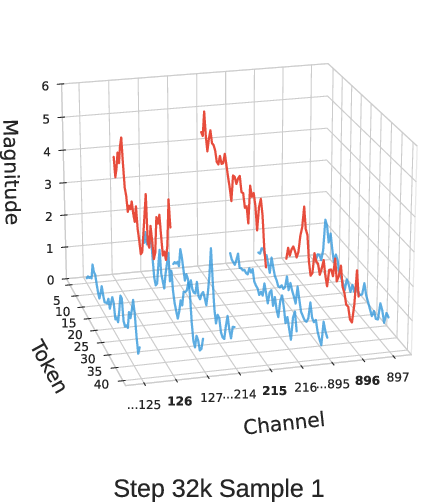
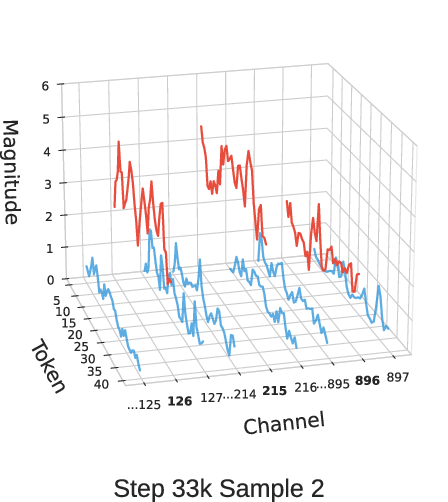
Figure 3: Activation magnitudes of MLP input at layer 10 for different GSM8K samples across OLMo2-370M training checkpoints at different steps.
Experimental Evaluation
TetraJet-v2 was evaluated across varying model sizes and token scales, consistently outperforming existing FP4 training methods. Extensive experiments demonstrated reduced performance gaps between FP4 and full-precision training. For example, TetraJet-v2-full achieved significant improvements in both training and validation perplexity across multiple datasets and model settings.
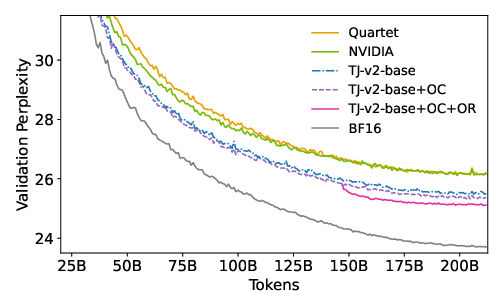
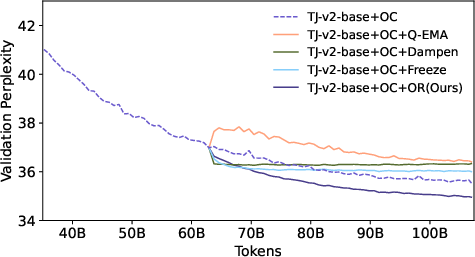
Figure 4: Validation loss curve of OLMo2-370M with about 200B tokens for comparing different methods.
Conclusions and Future Directions
TetraJet-v2 offers a viable path to efficient and accurate low-precision training for LLMs, reducing the computational costs associated with large-scale models. Future work should focus on extending these methods to larger models and token sets and implementing them on practical low-precision hardware to fully leverage the NVFP4 format's benefits. The potential of mixed-precision formats like FP6×FP4 could offer further improvements and should be explored.