Delegate Pricing Decisions to an Algorithm? Experimental Evidence
Abstract: We analyze the delegation of pricing by participants, representing firms, to a collusive, self-learning algorithm in a repeated Bertrand experiment. In the baseline treatment, participants set prices themselves. In the other treatments, participants can either delegate pricing to the algorithm at the beginning of each supergame or receive algorithmic recommendations that they can override. Participants delegate more when they can override the algorithm's decisions. In both algorithmic treatments, prices are lower than in the baseline. Our results indicate that while self-learning pricing algorithms can be collusive, they can foster competition rather than collusion with humans-in-the-loop.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What this paper is about (in simple terms)
Imagine two shops selling the same product. Each round, both shops pick a price. If one is cheaper, it gets all the customers; if prices are the same, they split customers. Now imagine the shop owner can either set prices themselves or let a computer program (an “algorithm”) do it.
This paper tests whether people running these shops will let an algorithm set their prices, and if doing so makes prices go up (which is bad for customers) or go down (which is good for customers).
What questions the researchers asked
They focused on two main questions:
- Are people more willing to use a pricing algorithm if they can still change its suggestion (override it), compared to handing over full control?
- When people can choose whether to use the algorithm, do market prices end up higher (more collusion) or lower (more competition)?
Here, “collusion” means both shops keep prices high without directly talking to each other—like silently agreeing to not compete too hard.
What they did and how it worked
To make this clear, think of a video game tournament with many short matches:
- Two players (representing two shops) repeatedly choose prices from 0 to 5.
- Customers will buy at prices up to 4. If both choose 4, they each make good money. But if one secretly lowers to 3 while the other stays at 4, the discounter makes even more—at least for that round.
- Matches last an unknown number of rounds (each round has a 95% chance the match continues), which encourages thinking about the long run, not just one round.
They ran three versions (treatments) of this game with 300 participants:
- Baseline: People set prices themselves. No algorithm available.
- Outsourcing: At the start of each match, players can hand over all pricing decisions to the algorithm for the whole match (no overrides).
- Recommendation: At the start of each match, players can ask the algorithm for price suggestions but can override them at any time.
About the algorithm:
- It’s a “reinforcement learning” program—think of it like someone who learns a game by trial and error, the way you get better at a video game by playing it a lot.
- It was trained beforehand (not learning during the experiment) and discovered a simple strategy called “win-stay, lose-shift”:
- If both shops charged the high, profitable price last round, keep doing it.
- If the other side undercuts you, punish for one round by choosing a low price, then try to go back to the high price.
- When two such algorithms face each other, they usually keep prices high (they “tacitly collude”).
Other details:
- Participants played five matches each, with new partners across matches.
- In the two algorithm treatments, people could see past results of the algorithm to understand it might raise profits.
- After each match, participants in the algorithm treatments guessed whether their opponent used the algorithm (they were paid for accurate guesses).
What they found and why it matters
Here are the main results, explained simply:
- People used the algorithm a lot, but they preferred control:
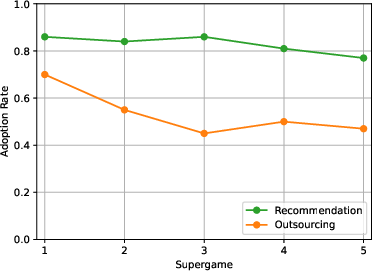
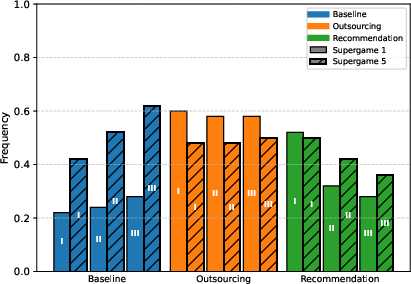
- Adoption (using the algorithm) was higher when they could override its suggestions (Recommendation) than when they had to hand over full control (Outsourcing).
- Over time, people used the algorithm less in both treatments, especially in Outsourcing.
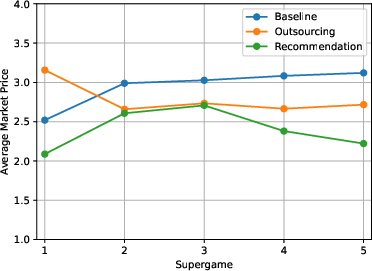
- Prices did not end up higher when people could choose whether to use the algorithm. In fact:
- Early on, fully delegating (Outsourcing) led to higher prices in the first match (because algorithms facing each other tend to keep prices high).
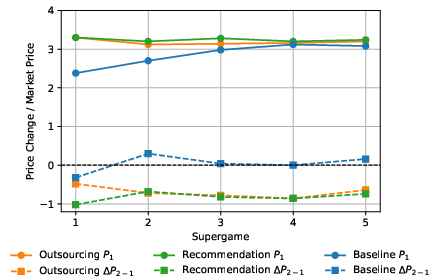
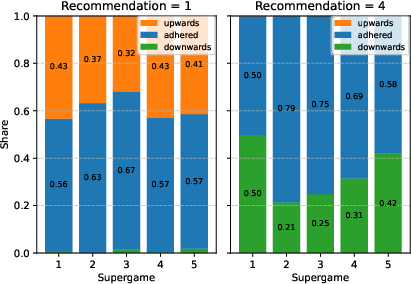
- But in later matches, prices in both algorithm treatments fell. People often overrode the algorithm’s high recommended prices or strategically undercut them.
- By the final match, markets without any algorithm (Baseline) had higher prices than both algorithm treatments. In other words, letting people choose whether to use the algorithm—and letting them override it—made markets more competitive, not less.
- People could tell, better than random guessing, whether the other side used the algorithm—especially in Outsourcing where behavior was more predictable.
Why this matters:
- Regulators worry that pricing algorithms could silently learn to keep prices high. That can happen when all firms use the same kind of algorithm with no human involvement.
- But this study shows that when humans choose whether to adopt algorithms—and can override them—prices don’t necessarily go up. Sometimes they even go down.
What this means going forward
- For businesses: Algorithms can be powerful, but human oversight changes the outcome. When people can override, they’re more willing to try algorithms—but they also stop the algorithm from keeping prices high if it doesn’t pay off for them.
- For policymakers: Don’t assume that “adding algorithms” always means higher prices. The real-world impact depends on whether people must fully delegate or can stay “in the loop.” Policies that encourage human oversight (rather than forced full automation) may limit the risk of algorithm-driven collusion.
- For researchers: It’s important to study not just how algorithms behave, but also how humans decide to use them. Endogenous adoption (people choosing whether to use the tool) can flip the expected result—from more collusion to more competition.
In short: Even though the pricing algorithm, when left alone, can learn to keep prices high, giving humans the choice to adopt it and the option to override it often leads to lower prices and more competition.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise list of what remains missing, uncertain, or unexplored in the study that future research can address:
- External validity of the lab environment
- Two-player, homogeneous-good, zero-cost, inelastic-demand duopoly with a small discrete price grid may not generalize to realistic markets with more firms, product differentiation, positive and heterogeneous costs, capacity or inventory constraints, continuous pricing, menu costs, or demand shocks.
- The continuation probability is fixed at 0.95; sensitivity of findings to lower discount factors or stochastic horizons remains untested.
- Results from student samples in German labs may not translate to professional pricing managers or different cultural contexts.
- Market structure and competition scope
- No evidence for settings with N > 2 competitors; how mixed adoption equilibria, coalition dynamics, or free-riding evolve in oligopolies is unknown.
- No exploration of multi-market contact, cross-market reputations, or platform-mediated environments (e.g., marketplaces with many small sellers).
- Algorithm class, heterogeneity, and learning dynamics
- Only one offline-trained Q-learning policy (effectively WSLS/perfect tit-for-tat with one-period punishment) is used; robustness to alternative algorithm families (SARSA, actor-critic, policy-gradient/deep RL, model-based RL, bandits, rule-based heuristics, LLM-based agents) is unknown.
- The algorithm does not learn or adapt during the experiment; whether online learning, meta-learning, or opponent modeling would mitigate human undercutting or increase collusion is an open question.
- All firms face the same algorithm; effects of heterogeneous algorithms, parameterizations, or different third-party providers (including hub-and-spoke scenarios, shared data, or cross-client coupling) are not examined.
- Punishment design is fixed (one-period reversion to price 1). Comparative statics over punishment depth, duration, noise tolerance, or forgiveness rules (e.g., grim trigger, generous tit-for-tat, stochastic punishments) are missing.
- Delegation design and commitment granularity
- Adoption is only decided once per supergame; no mid-supergame switching, staged commitment, or dynamic opt-in/out mechanisms are considered.
- Only two human-control regimes are tested (full outsourcing vs. overrideable recommendations). Realistic intermediate regimes (guardrails, bounded price bands, approval workflows, auditing/justification requirements, override costs/frictions) are not studied.
- No explicit adoption costs (licensing fees, integration costs, switching costs) or endogenous penalties for mispricing are modeled, which likely affect adoption and prices.
- Information, transparency, and framing
- Participants receive strong prior information about the algorithm’s collusive potential and past performance from a different study; external validity of these priors and their effect on adoption/pricing is unclear.
- No treatments vary algorithm transparency/explainability, performance uncertainty, noise in recommendations, or disclosure about rival adoption.
- Moral/ethical framing is explicitly neutral; how moral salience, compliance warnings, or legal-risk salience would interact with adoption and pricing is left open.
- Observability and belief dynamics
- Beliefs about rival adoption are elicited only after supergames; the role of within-supergame belief updating is not measured, and the causal link from beliefs to override/undercut behavior is not established.
- Observability of algorithm use is not manipulated; how partial observability or noisy inference about rivals’ adoption affects strategies remains unexplored.
- Mechanisms behind declining adoption and pro-competitive outcomes
- Although overrides and undercutting are highlighted as drivers, the paper does not causally disentangle mechanisms (e.g., strategic exploitation of algorithm rigidity vs. learning about rival behavior vs. disappointment with profits).
- Heterogeneity in participants (risk preferences, algorithm aversion, trust, cognitive reflection, competitiveness) is not tied to adoption, overriding, or pricing trajectories.
- The algorithm’s inability to adapt to human undercutting suggests design vulnerabilities; whether adaptive strategies could restore collusion or whether human-in-the-loop consistently disciplines algorithms is unresolved.
- End-game and dynamic considerations
- With indefinite horizons, end-of-supergame behavior still may influence undercutting incentives; the study does not analyze end-game cycles, late deviations, or hazard-rate beliefs.
- No exploration of how path-dependence or early miscoordination affects later adoption/override choices across supergames (e.g., persistence, hysteresis).
- Scope of outcomes analyzed
- Focus is primarily on prices; comprehensive welfare analysis (consumer surplus, producer surplus, total welfare) and distributional outcomes (adopters vs. non-adopters) are not fully reported.
- Profit-based comparisons by adoption status and within market types (HH, AH, AA) are not used to isolate incentives that drive switching or sustained adoption.
- Policy levers and regulatory design
- The finding that human overrides can discipline collusion is suggestive but not tested under realistic policy levers (mandated human-in-the-loop, audit logs, explainability, intervention thresholds, default settings).
- No analysis of legal-risk exposure, detection probabilities, or fines—key factors that could strongly affect adoption and override behavior.
- Demand and environment uncertainty
- The environment is stationary and deterministic; how demand volatility, observation noise, or partial observability affect both algorithm learning and human override incentives is unknown.
- Communication and signaling
- No communication is allowed; in practice, firms may coordinate via public signals, algorithm-provider channels, or market announcements. Interactions between algorithmic strategies and (even limited) human communication are untested.
- Generalizability across interfaces and UX
- The recommendation interface provides a default price; the impact of UI/UX design (salience, nudges, default stickiness, explanation granularity) on acceptance and override rates has not been systematically varied.
- Timing and speed
- Real-world algorithms can reprice at high frequency; the implications of speed asymmetries (algorithm vs. human) for undercutting, deterrence, and adoption are not explored.
- Extensions to platform and intermediary roles
- The study does not model platform governance, data sharing by intermediaries, or provider-side incentives (e.g., designing algorithms that maximize client profits vs. market-wide stability), all central to hub-and-spoke risks.
- Robustness to price space and granularity
- The small discrete price set (0–5) may constrain strategies; whether results persist with finer or continuous pricing, alternative reserve prices, or cost shocks is unclear.
- Learning spillovers across supergames
- While rematching reduces reputation effects, it also removes realistic long-term rival relationships; how fixed pairings or observable histories influence adoption and price paths is an open question.
These gaps suggest concrete next steps: introduce oligopoly and heterogeneity (firms and algorithms), vary commitment/override frictions and information/transparency, test online/adaptive algorithms, incorporate costs/legal risk/noise, manipulate observability and UI/UX, and move toward field or professional-subject validations with richer market institutions.
Practical Applications
Practical Applications of the Paper’s Findings
The paper shows that self-learning pricing algorithms trained to collude in self-play can foster competition when humans control adoption and retain override capabilities. Adoption is higher with override than full delegation, but it declines with experience; algorithm-influenced prices start higher and then fall rapidly due to human undercutting and overrides. These results suggest concrete design, governance, and policy choices that can mitigate anti-competitive risks while deriving operational value from pricing algorithms.
Immediate Applications
Below are actionable applications that can be deployed now, organized by sector and function. Each item notes key dependencies or assumptions that affect feasibility.
- Industry (e-commerce, retail, fuel, hospitality)
- “Recommendation-mode” pricing systems (human-in-the-loop by default)
- Deploy algorithms that pre-fill suggested prices rather than fully set them; require human confirmation for execution.
- Tools/workflows: price suggestion UI, override toggle, “autopilot off by default,” configurable escalation for high first-round prices.
- Dependencies/assumptions: effectiveness relies on interface design that enables frequent overrides; assumes pricing teams can handle incremental workload; assumes algorithms are frozen (no live learning) and trained offline.
- Override analytics and KPIs to track competitive pressure
- Instrument dashboards to monitor adoption rate, override frequency, price changes from round 1 to round 2, and undercutting behavior.
- Tools/products: “Override Analytics Dashboard,” “First-Round Price Risk Monitor,” “Undercutting Heatmap.”
- Dependencies/assumptions: clean logging and time-stamped audit trails; alignment with data governance and privacy policies.
- Progressive rollout and early-phase safeguards for autopilot modes
- If full delegation is needed, impose short pilot phases with strict price change thresholds; alert pricing managers to initial supra-competitive recommendations.
- Tools/workflows: controlled pilots, kill-switches, continuous supervision alerts.
- Dependencies/assumptions: organizational willingness to stage rollouts; real-time alerting infrastructure; capacity to revert to human control quickly.
- Competitor algorithm-use inference from observed price paths
- Exploit differential patterns (e.g., high first-round prices followed by rapid declines) to estimate competitor adoption and delegation mode.
- Tools/products: “Competitor Adoption Signal” powered by price-path analytics; scenario simulators conditioned on adoption beliefs.
- Dependencies/assumptions: availability of fine-grained competitor price data; model trained to market-specific dynamics; risk of misclassification in highly noisy markets.
- Diversification of algorithm providers to lower hub-and-spoke risks
- Avoid reliance on common third-party repricers across competitors; encourage vendor heterogeneity or differentiated algorithm configurations.
- Tools/workflows: procurement checklists, vendor risk assessments.
- Dependencies/assumptions: market offers multiple providers; contractual leverage to require configurational uniqueness.
- Policy and regulation
- Guidance favoring human-overridable pricing systems
- Issue best-practice advisories: “recommendation-mode preferred,” “override required,” “algorithm must be frozen at deployment.”
- Tools/workflows: compliance checklists; supervisory audits of control features.
- Dependencies/assumptions: regulatory authority to set soft standards; industry cooperation for voluntary codes.
- Mandatory audit trails and early-phase monitoring
- Require firms to log algorithm recommendations and overrides; monitor first-round pricing for supra-competitive spikes.
- Tools/products: standardized logging schemas; regulator dashboards for anomalous early-period prices.
- Dependencies/assumptions: standardization of log formats; privacy and legal constraints; regulator capacity for analytics.
- Algorithmic pricing sandbox/testing regimes
- Pre-deployment tests in synthetic markets with mixed human-algorithm participation; report outcomes to regulators.
- Tools/workflows: sandbox protocols; test harnesses; standardized performance disclosures.
- Dependencies/assumptions: sandbox infrastructure; shared test datasets; cooperation from firms and vendors.
- Investigative frameworks that treat adoption as endogenous
- Incorporate human delegation choices and override rates into antitrust analyses, especially for suspected hub-and-spoke scenarios.
- Tools/workflows: case templates and investigative playbooks.
- Dependencies/assumptions: access to firm-level logs and adoption policies; legal pathways for data collection.
- Academia and research
- Experimental paradigms with endogenous adoption and override
- Replicate and extend to heterogeneous costs, demand elasticity, more than two firms, and varied continuation probabilities.
- Tools/workflows: open experimental code (oTree) and trained algorithm artifacts; pre-registered protocols; cross-lab replications.
- Dependencies/assumptions: funding and lab capacity; generalizability to different market structures.
- Algorithm-aversion measurement in strategic settings
- Study how override availability and interface design affect trust, adoption, and outcomes in repeated games.
- Tools/workflows: behavioral instrumentation; belief elicitation calibrated to strategic uncertainty.
- Dependencies/assumptions: robust subject pools; standardized scoring rules.
- Daily life (small sellers on Amazon/Shopify and similar platforms)
- Use suggestion-only repricers
- Configure third-party repricers to recommendation mode; manually approve price changes to avoid tacit collusion exposure.
- Tools/workflows: platform settings for “manual approval,” alerts for high initial recommendations.
- Dependencies/assumptions: platform features exist; time to review recommendations; support for audit logs.
Long-Term Applications
These applications will require further research, scaling, standard-setting, or technology development.
- Industry and software
- Collusion-aware RL and compliance-by-design pricing
- Develop algorithms that penalize WSLS-like collusive patterns and optimize for compliance and consumer welfare metrics alongside profit.
- Tools/products: “Compliance-Constrained RL,” “Collusion-Resistance Scorer,” explainability modules that flag one-period punishment strategies.
- Dependencies/assumptions: consensus on compliance objectives; technical methods to constrain emergent strategies; willingness to trade off profit.
- Multi-agent, human-in-the-loop training frameworks
- Train algorithms against human strategies rather than only self-play; tune behavior to anticipate overrides and undercutting.
- Tools/workflows: human-in-the-loop training environments; active learning from observed human overrides.
- Dependencies/assumptions: scalable collection of human interaction data; ethical approval and privacy; computational cost.
- Policy and platform governance
- Certification and standardization for pricing algorithms
- Third-party certification for algorithmic pricing systems (control features, logging, collusion-resistance, frozen deployment).
- Tools/products: certification audits, standardized reporting formats, “algorithm fingerprints” to detect common-provider contagion.
- Dependencies/assumptions: standard-setting bodies; adoption by major platforms; reliable technical testing suites.
- Liability and disclosure frameworks
- Clarify responsibility for pricing outcomes when firms use third-party repricers; require disclosures of algorithm provider and mode (recommendation vs full delegation).
- Tools/workflows: disclosure registries; case law building on hub-and-spoke risks.
- Dependencies/assumptions: legislative action; industry lobbying; compliance burdens.
- Cross-sector extensions (energy retail, ride-hailing, telecom)
- Human oversight requirements for dynamic pricing sectors prone to tacit coordination
- Impose “recommendation-mode” defaults in consumer-critical sectors; continuous monitoring for synchronized price spikes.
- Tools/workflows: sector-specific guardrails and dashboards; coordinated audits.
- Dependencies/assumptions: sector regulator mandates; interoperability of logs and monitoring tools.
- Academic infrastructure and consumer tools
- Regulator-run algorithmic collusion testbeds
- Synthetic market environments to evaluate pricing algorithms under human oversight, mixed adoption, and varied market conditions.
- Tools/workflows: open benchmarks; shared datasets; regulatory research units.
- Dependencies/assumptions: funding; open collaboration; standardized measures of competitive harm.
- Consumer-facing price-tracking and alerts
- Detect patterns consistent with algorithmic coordination (e.g., synchronized high initial prices, rapid decline) and inform watchdogs.
- Tools/products: public-interest analytics; transparency portals.
- Dependencies/assumptions: access to time-resolved price data; robust anomaly detection; user trust.
Key Assumptions and Dependencies Across Applications
- Experimental environment differs from real markets: duopoly, discrete prices, zero marginal costs, inelastic demand, high continuation probability (), and fixed, identical algorithms across firms.
- Algorithm was trained offline (self-play Q-learning) and deployed with a fixed WSLS strategy; many commercial systems vary by sector and may learn online or use different architectures.
- Override availability increases adoption and can foster competition through undercutting; effectiveness depends on interface design, team capacity, incentives, and organizational culture.
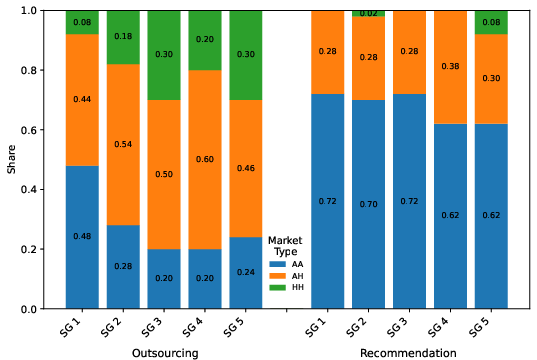
- Mixed markets (human + algorithm) are common and crucial to outcomes; full-algorithm markets in the lab colluded, but selective adoption with human oversight led to lower prices over time.
- Belief accuracy about competitor adoption was higher under full delegation than recommendation—market intelligence systems may benefit from these behavioral regularities, but observability of competitor prices and market noise will affect reliability.
- Legal and regulatory feasibility depends on jurisdictional authority, standard-setting capacity, and industry cooperation; auditability and data access are recurring constraints.
These applications translate the paper’s central insight—collusion-prone algorithms can yield competitive outcomes when adoption is endogenous and humans can override—into concrete design, governance, and policy choices that industries and regulators can implement or pursue.
Glossary
- Algorithm aversion: Reluctance to rely on algorithms even when they outperform humans. Example: "This well-documented phenomenon, known as ``algorithm aversion'' may inhibit the adoption of pricing algorithms"
- Algorithmic commitment: The idea of using or being bound to an algorithm as a strategic commitment in games/markets. Example: "focusing on algorithmic commitment rather than adoption behavior"
- Algorithmic self-play: Training or evaluation setup where an algorithm plays against copies of itself. Example: "In algorithmic self-play, it colludes at the monopoly price and cannot be profitably exploited."
- Antitrust concerns: Legal and economic worries about anti-competitive behavior and market power. Example: "is sparking significant antitrust concerns."
- Binarized scoring rule: An incentive-compatible method to elicit beliefs by converting a scoring rule into a binary lottery. Example: "We incentivize belief elicitation using the binarized scoring rule"
- Bertrand market experiment: A laboratory setup modeling Bertrand price competition between firms. Example: "This Bertrand market experiment was first proposed by \cite{dufwenberg2000price} in a static environment"
- Continuation probability: The probability that an indefinitely repeated game continues to the next period. Example: "the continuation probability is relatively high."
- Discount factors: Parameters that weight future payoffs relative to current ones in repeated interactions. Example: "discount factors inherent in repeated-game analyses"
- Endogenous adoption: A setting where the decision to use an algorithm is chosen by participants rather than imposed externally. Example: "depend on endogenous adoption choices"
- Grim trigger: A strategy that cooperates until a deviation occurs and then punishes forever. Example: "with grim trigger strategies."
- Hub-and-spoke collusion: Collusion facilitated by a common intermediary (the “hub”) coordinating multiple firms (the “spokes”). Example: "enable hub-and-spoke collusion when supplied by a common provider"
- Humans-in-the-loop: Systems where humans retain oversight and can intervene in algorithmic decisions. Example: "with humans-in-the-loop."
- Incentive compatible: A property where the designed behavior is in each agent’s self-interest to follow. Example: "make collusion incentive compatible"
- Markov decision process: A mathematical framework for decision-making with state transitions and rewards. Example: "Q-learning algorithms are designed to solve Markov decision processes with an ex-ante unknown environment."
- Matching group: A subset of participants among whom rematching occurs across rounds to control interactions. Example: "within a matching group of ten participants."
- Monopoly price: The profit-maximizing price for a monopolist (or joint-profit maximizing price under collusion). Example: "cooperates at the monopoly price"
- Nash threat profits: The payoffs used as a punishment threat by reverting to a Nash equilibrium. Example: "the Nash threat profits for (the most severe credible punishment) are zero."
- Pure-strategy Nash equilibrium: A Nash equilibrium where players use deterministic strategies. Example: "the set of pure-strategy Nash equilibrium prices is"
- Perfect tit-for-tat: A strategy that exactly mirrors the opponent’s previous action. Example: "perfect tit-for-tat"
- Perfectly inelastic demand: Demand that does not change with price (up to a threshold). Example: "facing perfectly inelastic demand."
- Q-learning: A model-free reinforcement learning algorithm that learns action values to maximize cumulative reward. Example: "We use Q-learning algorithms that belong to the class of reinforcement learning algorithms"
- Reinforcement learning: A class of algorithms that learn via rewards from interacting with an environment. Example: "belong to the class of reinforcement learning algorithms"
- Stage game: The one-shot game that is repeated within a repeated-game (supergame) framework. Example: "as the stage game."
- Subgame-perfect Nash equilibrium: An equilibrium where strategies constitute a Nash equilibrium in every subgame. Example: "this strategy is a subgame-perfect Nash equilibrium."
- Supra-competitive: Prices or outcomes above the competitive level, often due to collusion. Example: "Prices 3 and 4 are supra-competitive and may indicate tacit collusion."
- Tacit collusion: Collusion sustained without explicit communication or agreement. Example: "is capable of sustaining tacit collusion"
- Win-stay lose-shift (WSLS): A strategy that repeats the previous action if successful, otherwise switches. Example: "win-stay lose-shift strategy (WSLS)"
Collections
Sign up for free to add this paper to one or more collections.