- The paper shows that subspace alignment, rather than global similarity, is critical for enabling subliminal transfer in transformer models.
- It utilizes synthetic datasets and varied seed initializations to isolate how covert communication channels can emerge within model subspaces.
- The study provides actionable mitigation strategies, including projection penalties, to enhance model security without affecting primary performance.
Introduction
Transformer models have become pivotal in advancing state-of-the-art performance in a range of tasks, including language, vision, and multimodal processing. Despite their efficacy, the deployment of these models carries certain risks related to subliminal learning and covert communication channels within their architecture. Subliminal learning refers to the ability of a neural model to embed hidden traits within its representations, allowing another model to decode these traits without impacting primary task performance. This phenomenon poses substantial security risks by enabling undetectable model-to-model communication or data leakage.
Previous studies have indicated that subliminal transfer is feasible when both the teacher and student models share the same architecture and initialization. However, these studies primarily associated transferability with global representational similarity, measured using Centered Kernel Alignment (CKA). This work challenges that notion by demonstrating that subliminal transfer critically depends not on global similarity, but on alignment within specific subspaces associated with hidden traits. Experiments reveal that even with global CKA values above 0.9, models initialized with different random seeds exhibit reduced subliminal transfer, underscoring the importance of subspace-level analysis.
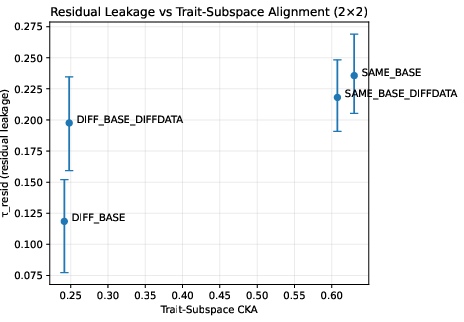
Figure 1: Depiction of subspace alignment in transformer models illustrating τresidual impact on subliminal transfer.
Methodology
Dataset Construction
The study utilizes synthetic datasets designed to disentangle public and private labels, ensuring independence between these labels and minimizing confounding effects. These datasets enable controlled examination of subliminal transfer through sequences generated by sampling tokens from a fixed vocabulary. This synthetic approach follows best practices in controlled leakage studies, facilitating precise examination of subliminal learning dynamics.
Model Training and Evaluation
The teacher model is constructed using BERT-tiny for multi-task fine-tuning, incorporating linear projections for both public and private tasks. Students are distilled from the teacher model with variations in initialization—either cloning from teacher weights or employing fresh random initializations—followed by knowledge distillation (KD) process. Subliminal transfer is quantified using linear probes measuring leakage along defined subspaces, with statistical robustness ensured through bootstrapping.
Subspace-Level Analysis
Key insights are derived from probing analyses and subspace-specific metrics, including CKA focused on trait-discriminative subspaces. This approach reveals that transfer viability is linked with subspace alignment rather than global similarity, overturning previous assumptions about the role of high global CKA values as indicators of subliminal transfer potential.
Experimental Results
Seed Alignment and Subliminal Transfer
Results indicate that subliminal transfer substantially diminishes in models with different initialization seeds, despite high global representational similarity. The critical factor enabling subliminal transfer is the alignment within a specific subspace rather than global CKA values, challenging prior assumptions in the domain.
Diagnostic Protocol and Mitigation Strategies
The study introduces subspace-level CKA analysis as an effective protocol for detecting and mitigating covert-channel risks. Additionally, security controls such as projection penalties show promising results in reducing subliminal leakage without impacting primary task accuracy, offering practical techniques for enhancing model security.
Implications and Future Directions
The findings show that independently initialized Transformer models possess inherent resilience against subliminal transfer, highlighting the importance of initialization choices in secure AI deployments. This has implications for federated learning, coalition intelligence analysis, and other domains where secure and robust AI communication is necessary.
Future research should explore the scalability of subspace diagnostics in larger models and natural datasets, as well as integrate these protocols into automated testing processes for continuous deployment. Extending mitigation strategies to encrypted and federated learning contexts could enhance their applicability in adversarial scenarios, contributing to the development of secure, regulation-compliant AI systems.
Conclusion
This research demonstrates the pivotal role of seed-induced uniqueness in resisting subliminal transfer within Transformer models. By focusing on subspace alignment rather than global similarity, this work provides a novel perspective on model security, offering practical methodologies for mitigating covert communication channels. These insights are vital for deploying resilient AI architectures and underscore the necessity of subspace-aware diagnostics in ensuring the secure operation of AI systems in high-stakes environments.