- The paper presents Quantum Reinforcement Learning as a solution to DRL's slow convergence and high resource demands in 6G networks.
- It details how quantum phenomena like superposition and entanglement boost exploration efficiency and accelerate policy learning.
- The case study in dynamic spectrum access highlights QRL’s ability to achieve faster optimal policy convergence compared to classical DRL.
Quantum Reinforcement Learning for 6G and Beyond Wireless Networks
The paper "Quantum Reinforcement Learning for 6G and Beyond Wireless Networks" (2511.01070) explores the integration of Quantum Reinforcement Learning (QRL) within the forthcoming 6G wireless networks. As 6G technology promises significant enhancements over 5G—covering aspects like data throughput, latency reduction, and massive IoT support—traditional AI techniques face challenges in meeting the demanding specifications of this network paradigm. This review-oriented article seeks to demonstrate the potential of QRL to surmount these challenges by leveraging the unique capabilities of quantum computing.
Introduction
6G networks are projected to revolutionize wireless communications with data rates magnitudes higher than those in 5G and latency reduced to just 0.1 ms, among other enhancements. This evolution necessitates intelligent systems capable of rapidly adapting to dynamic network conditions. The authors discuss how DRL, while useful, is limited in terms of learning speed and latency, which poses significant limitations in the high-frequency, rapidly-changing environments anticipated in 6G. By contrast, the quantum properties of superposition and entanglement in QRL offer the potential to improve training efficiency and adaptability.
Deep Reinforcement Learning (DRL) Challenges in 6G
DRL, a branch of AI characterized by agents learning optimal policies from episodic interactions with the environment, has propelled innovations in fields like autonomous systems and complex decision-making tasks. Despite its strengths in handling high-dimensional problems, the paper highlights several challenges DRL faces in 6G:
- Complex Network Environments: The high density and dynamic nature of 6G environments pose significant challenges for DRL algorithms, which traditionally require extensive fine-tuning and training data.
- Latency and Convergence: The long convergence times associated with DRL models are incompatible with the ultra-low latency requirements of 6G.
- Resource Intensity: DRL's dependence on large neural networks leads to substantial computational and energy costs, often surpassing what embedded or edge devices can handle.
Motivation for Quantum Reinforcement Learning
QRL is presented as a promising solution to the limitations of DRL in 6G networks. The motivations for adopting QRL in this context include:
- Quantum Superposition: This allows QRL agents to simultaneously evaluate multiple paths, significantly speeding up the learning process.
- Quantum Entanglement: Enables more complex and non-local state representations, enhancing decision-making capability.
- Efficient Exploration: Utilizing quantum parallelism to explore state-action spaces more efficiently than classical exploration strategies.
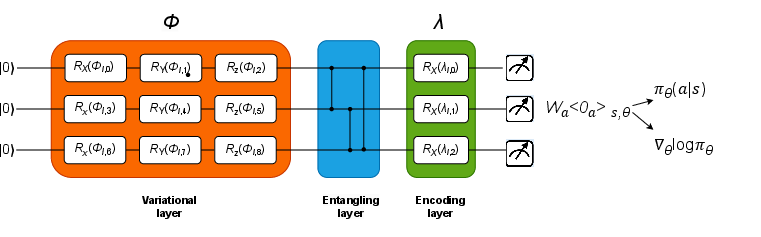
Quantum Computing Fundamentals
QRL leverages several quantum mechanics principles:
- Qubits: Exploiting superposition, qubits can represent multiple states, dramatically expanding the state space beyond classical capacity.
- Quantum Gates: Controlled operations manipulate qubit states, enabling complex transformations analogous to classical neural network layers.
- Entanglement and Measurement: These phenomena allow QRL models to maintain complex relationships and make probabilistic measurements, respectively.
Quantum Reinforcement Learning Architectures
The architectures employed in QRL range from Fully Quantum Architectures (FQA) relying entirely on quantum circuits to Hybrid Quantum-Classical Architectures (HQCA) that integrate classical components for practical feasibility. FQA benefits from end-to-end quantum processing, potentially offering superior speedups, although constrained by current hardware capabilities. HQCA, meanwhile, is more attainable with current technology, using quantum layers to enhance classical learning pipelines.
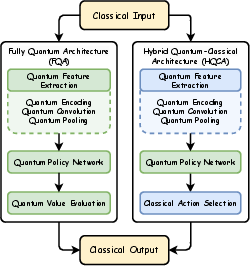
Figure 1: FQA and HQCA.
Applications in 6G
The applications of QRL extend across several facets of 6G:
Case Study: QRL-based Dynamic Spectrum Access
A key example provided is the use of QRL in managing dynamic spectrum access in D2D communications. The study demonstrates the superiority of QRL over conventional DRL approaches, achieving optimal policies significantly faster due to enhanced exploration capabilities powered by quantum parallelism.
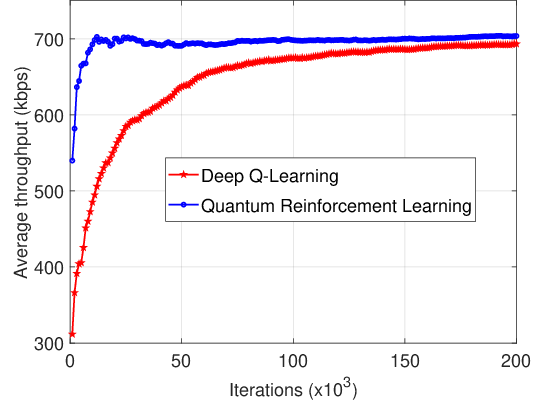
Figure 3: Convergence of quantum RL and DRL.
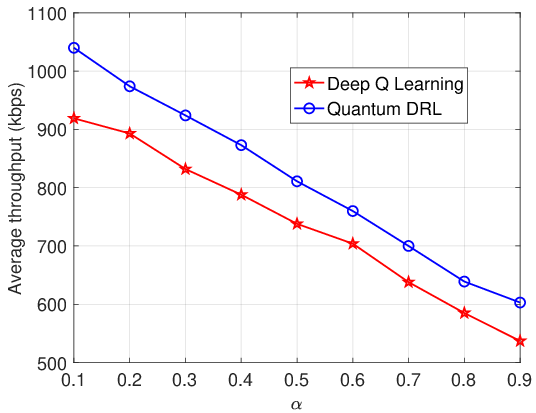
Figure 4: Average throughput vs. probability of UEs accessing the shared spectrum.
Future Directions
The paper suggests several future research directions for QRL in 6G:
- Enhancing 6G Security: Addressing vulnerabilities in 6G through QRL-driven cryptography and security measures.
- Space-Air-Ground-Sea Communications: Employing QRL to manage the intricate dynamics and resource scheduling in integrated networks.
- Ultra-Reliable and Low-Latency Communications (URLLC) and other applications such as massive MIMO, orchestration of radio resources, and integrated technology development.
Conclusion
The research identifies QRL as a potentially transformative technology for overcoming the limitations of current AI in wireless network applications. By merging quantum computing's advanced computational capabilities with reinforcement learning, QRL may facilitate the enhancement of network efficiency, resilience, and adaptability vital for realizing the ambitious goals set for 6G.