- The paper introduces the curvature rate λ as a scalar measure for input-space sharpness, shifting focus from parameter-space metrics.
- It utilizes differentiation dynamics to quantify exponential growth of input derivatives, validated through experiments on Two Moons and MNIST.
- The study shows that curvature rate regularization boosts confidence calibration without sacrificing accuracy, simplifying network tuning.
Introduction to Curvature Rate λ
The paper "The Curvature Rate λ: A Scalar Measure of Input-Space Sharpness in Neural Networks" presents a novel scalar measure for assessing curvature in neural networks, specifically transitioning the focus from parameter-space metrics to input-space dynamics. Traditionally, curvature has been analyzed using Hessian eigenvalues in parameter space, which are computationally expensive and sensitive to reparameterization. The proposed curvature rate λ offers a direct input-space alternative based on the exponential growth rate of higher-order input derivatives, facilitating an interpretable and parameterization-invariant approach to quantify functional sharpness.
Theoretical Framework
Differentiation Dynamics
Curvature is characterized through differentiation dynamics, reflecting how a function evolves under repeated differentiation. The curvature rate λ is mathematically formalized as:
λX(f)=n→∞limsupn1logvn
where vn=∥Dnf∥X represents the norm of the n-th input derivative, typically estimated using small n. A positive λ indicates the exponential growth of derivatives, suggesting high-frequency features in the decision boundary of neural networks.
Classical Connections
This formulation unifies multiple classical concepts:
- Analytic Functions: For functions such as (1−x)−1, λ correlates with the inverse radius of convergence.
- Bandlimited Signals: For signals with spectral cutoff Ω, λ equals logΩ.
These parallels support the hypothesis that λ can effectively describe geometric properties across various function classes, extending to neural networks.
Experimental Validation
Neural Networks: Two Moons and MNIST
Empirical validation is performed on analytic functions and neural network benchmarks like Two Moons and MNIST. On Two Moons, models with 30% label noise demonstrated a systematic difference in λ values when trained with and without regularization, revealing insights into late-stage overfitting dynamics:
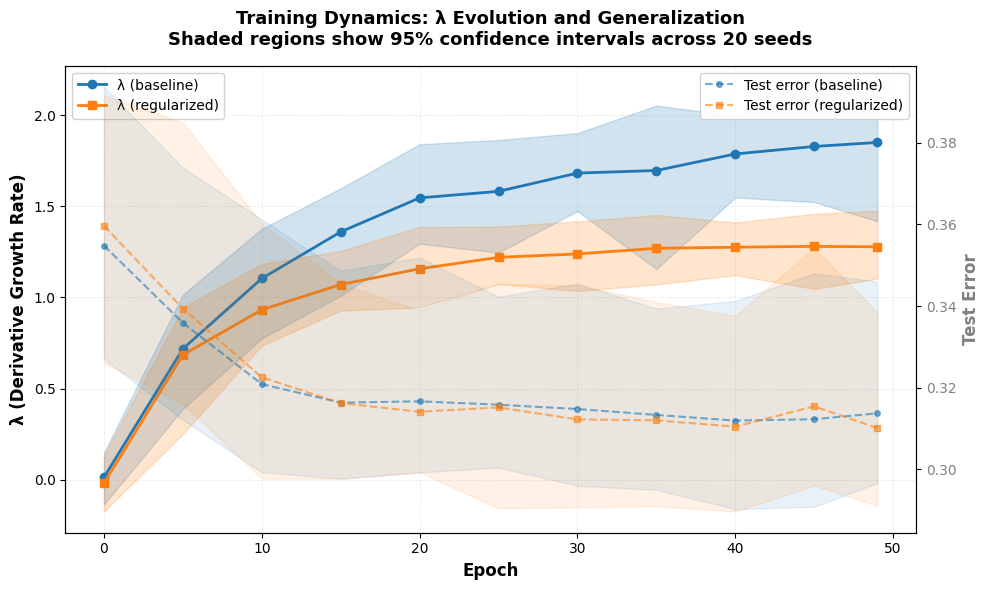
Figure 1: Training dynamics reveal that unregularized models continue sharpening after generalization plateaus.
In contrast, MNIST evaluations highlight that a dataset's intrinsic curvature scale determines the optimal λ range, with negative λ values signaling relative smoothness suitable for MNSIT's visual nature.
Practical Effects of Curvature Rate Regularization
Comparison to SAM
CRR was juxtaposed with Sharpness-Aware Minimization (SAM), indicating that while both methods achieve similar test accuracy, CRR significantly enhances confidence calibration by directly influencing input-space geometry rather than parameter-space changes:
Table: Comparison of Sharpness-Aware Minimization (SAM) and Curvature Rate Regularization (CRR) on MNIST.
The ability to modulate curvature directly through CRR suggests pathways for enhancing not only accuracy but also the reliability of confidence estimates, which is crucial for applications requiring high degrees of trust in model predictions.
Discussion and Implications
The findings indicate that curvature rate λ serves as an effective descriptor of input-space smoothness, distinct from traditional parameter-space flatness metrics. The regularization achieved through CRR fundamentally adjusts how models perceive input variations, enhancing calibration without compromising on accuracy. The broader implication is the simplification of complex Hessian metrics into a single interpretable scalar, potentially aiding in more straightforward tuning and monitoring during training.
Conclusion
By establishing λ as a scalar measure of curvature and illustrating its practical utility through CRR, the paper effectively bridges analytic principles with neural network dynamics. This scalar measure not only offers insights into generalization and model calibration but also suggests new research directions in robustness and task-dependent tuning strategies.