UniLumos: Fast and Unified Image and Video Relighting with Physics-Plausible Feedback
Abstract: Relighting is a crucial task with both practical demand and artistic value, and recent diffusion models have shown strong potential by enabling rich and controllable lighting effects. However, as they are typically optimized in semantic latent space, where proximity does not guarantee physical correctness in visual space, they often produce unrealistic results, such as overexposed highlights, misaligned shadows, and incorrect occlusions. We address this with UniLumos, a unified relighting framework for both images and videos that brings RGB-space geometry feedback into a flow matching backbone. By supervising the model with depth and normal maps extracted from its outputs, we explicitly align lighting effects with the scene structure, enhancing physical plausibility. Nevertheless, this feedback requires high-quality outputs for supervision in visual space, making standard multi-step denoising computationally expensive. To mitigate this, we employ path consistency learning, allowing supervision to remain effective even under few-step training regimes. To enable fine-grained relighting control and supervision, we design a structured six-dimensional annotation protocol capturing core illumination attributes. Building upon this, we propose LumosBench, a disentangled attribute-level benchmark that evaluates lighting controllability via large vision-LLMs, enabling automatic and interpretable assessment of relighting precision across individual dimensions. Extensive experiments demonstrate that UniLumos achieves state-of-the-art relighting quality with significantly improved physical consistency, while delivering a 20x speedup for both image and video relighting. Code is available at https://github.com/alibaba-damo-academy/Lumos-Custom.




Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper is about “relighting” images and videos—changing how light falls on a person or scene—without changing what’s actually in the picture. Imagine you took a photo at noon, but you want it to look like sunset, with warm light from the right and long shadows. Or you filmed a short clip indoors and want it to look like it’s lit by a cool, bluish spotlight. The authors introduce UniLumos, a new AI system that can do this quickly, realistically, and consistently for both images and videos.
What questions does the paper try to answer?
The researchers focus on a few simple questions:
- How can we change lighting in images and videos so it looks physically believable (shadows, highlights, and reflections make sense)?
- Can we make this work for both single images and full videos, keeping frames smooth over time (no flickering)?
- Can we give the AI clear, controllable instructions about lighting (like direction, intensity, color), and measure how well it follows them?
- Can we make the system fast—so it works much quicker than typical diffusion models?
How does UniLumos work?
To understand the approach, think of relighting like setting up a stage: the actors (the scene content) stay in place, but the lighting changes. UniLumos has three big ideas to make this work well.
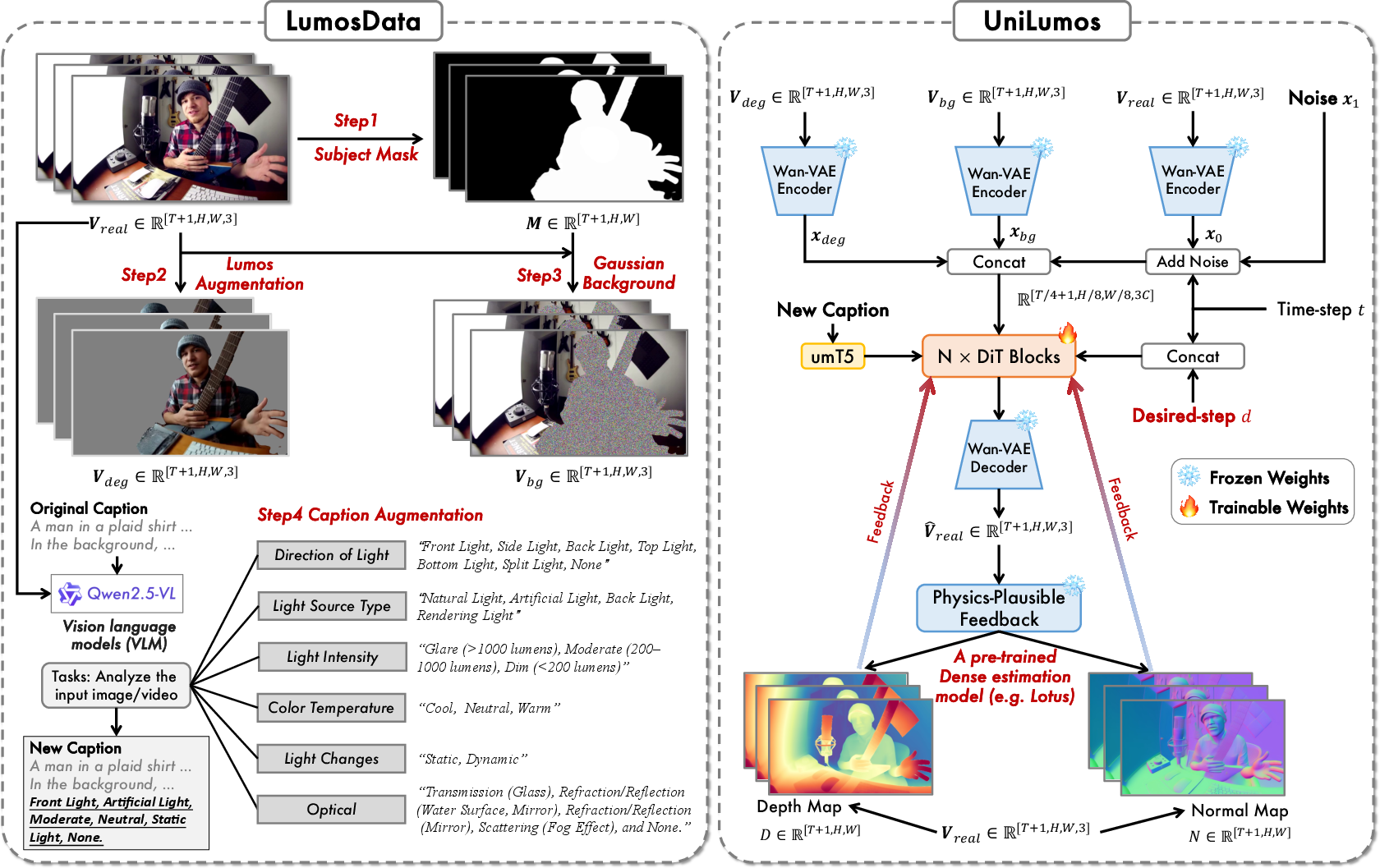
1) Physics-plausible feedback: checking with “invisible” structure
- Problem: Many AI image models make nice-looking pictures, but sometimes the lighting is wrong physically—shadows fall the wrong way, or highlights don’t match the shape of objects.
- Solution: After UniLumos generates a picture or video, it also estimates:
- Depth: how far each pixel is from the camera (like a distance map).
- Surface normals: which way each little surface is facing (like tiny arrows pointing out from the surface).
- These two maps don’t change much with lighting; they describe the scene’s real shape. UniLumos uses them as feedback to correct itself during training, so the lighting it adds matches the actual structure. For example, shadows align with the shape, and light direction feels right.
Think of it like a sculptor checking the curves of a statue under a lamp: the lamp’s light should match the statue’s shape. If the shadow doesn’t match the shape, something’s off.
2) Fast generation with “path consistency learning”
- Normal diffusion models improve images step-by-step, which can be slow.
- UniLumos uses a technique called path consistency learning to “learn bigger strides” safely. It practices taking a few large steps instead of many tiny ones, without losing quality.
- This makes UniLumos up to 20 times faster than some previous methods, while keeping the relighting realistic.
An analogy: If you’re crossing a stream, most people hop from stone to stone. Path consistency teaches you how to skip stones without falling in.
3) Clear lighting instructions and fair evaluation
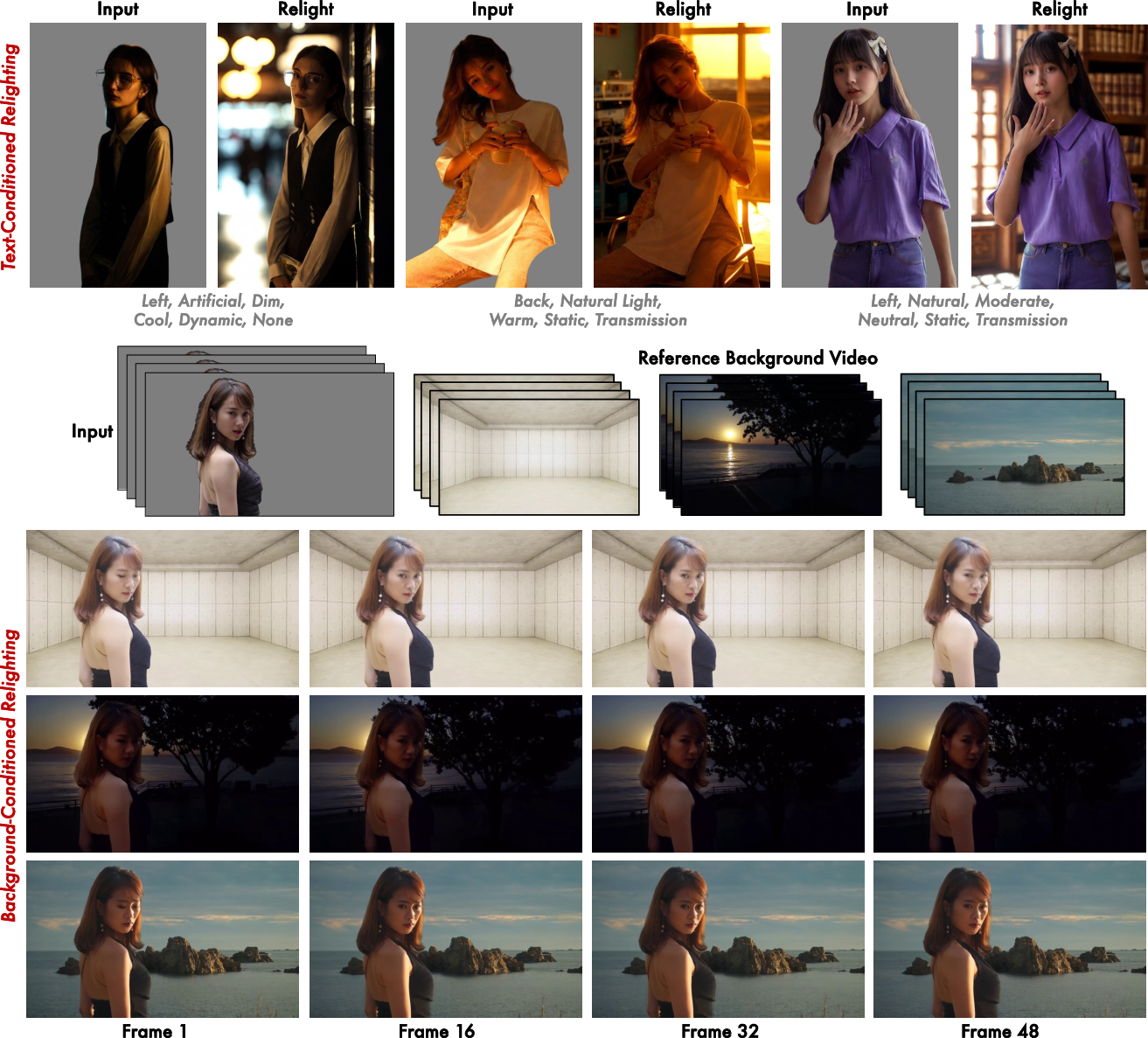
- The team builds LumosData, a dataset where each example comes with a structured “lighting description” using six attributes:
- Direction (where the light comes from)
- Light source type (sun, lamp, spotlight, etc.)
- Intensity (how bright)
- Color temperature (warm/orange vs cool/blue)
- Temporal dynamics (how lighting changes over time)
- Optical effects (like reflections, glow, or lens flares)
- They also create LumosBench, a test that uses a vision-LLM (an AI that understands both pictures and text) to check whether the generated results actually match the lighting instructions. This makes evaluation automatic, specific, and understandable.
This is like giving a lighting engineer a clear checklist—and then having a smart judge verify each item one by one.
What did they find?
The results show several important wins:
- Better realism: UniLumos produces more believable shadows, highlights, and light directions compared to other methods.
- Smoother videos: Lighting stays consistent across frames, reducing flicker and weird changes.
- More control: The system follows detailed lighting instructions more accurately (direction, color, intensity, etc.).
- Much faster: Thanks to the new training method, it runs about 20× faster for both images and videos.
- Strong numbers: On many quality and consistency scores (image similarity, temporal smoothness, geometry alignment), UniLumos beats previous relighting methods.
The authors also test what happens if they remove parts of the system:
- Without geometry feedback (depth and normals), quality and physical accuracy drop.
- Without the “fast stride” training (path consistency), it’s slower to sample and less efficient.
- Training on only images or only videos makes results worse; training on both is best.
Why does this matter?
Good relighting matters for moviemaking, gaming, virtual reality, advertising, and photo editing. With UniLumos:
- Artists and creators can change mood and time-of-day quickly (e.g., “golden hour from the left”).
- Videos look stable, not flickery, even with complex lighting changes.
- It’s practical: fast enough to use in production pipelines.
- The structured lighting instructions and the LumosBench test help the community measure and improve lighting control in a clear, fair way.
Key terms explained simply
Here are a few important terms in everyday language:
- Diffusion model: An AI that starts with noisy static and learns to “clean it up” into a picture or video.
- Latent space: A compressed internal representation the model uses; close points here don’t always mean physically correct images.
- Flow matching: A way of training the model to learn the “direction” from noise to the final image, which can speed things up.
- Path consistency learning: Teaching the model to take fewer, bigger steps from noise to image without messing up the result.
- Depth map: A picture showing how far things are—brighter might mean closer, darker farther.
- Surface normal map: A picture showing which way each tiny surface faces—crucial for correct shadows and highlights.
Bottom line
UniLumos is a fast, unified system for changing lighting in both images and videos. It checks itself against the scene’s 3D-like structure (depth and surface orientation) to keep shadows, highlights, and light direction physically believable. It also defines lighting clearly with six attributes and introduces a fair, automatic way to judge whether the lighting matches the instructions. This combination makes relighting more accurate, more controllable, and much faster—useful for creative industries and future research.
Knowledge Gaps
Below is a single, actionable list of knowledge gaps, limitations, and open questions left unresolved by the paper:
- Reliability of RGB-space geometry supervision: The approach depends on monocular depth/normal estimators (e.g., Lotus) for pseudo ground truths; sensitivity to estimator errors, lighting changes, and domain shifts is not quantified, nor is uncertainty modeling or estimator calibration addressed.
- Missing explicit light transport constraints: The method does not enforce physically grounded shading models (e.g., BRDFs, energy conservation, global illumination, interreflections), leaving highlight behavior, cast shadows, and color bleeding under complex materials largely unconstrained.
- Material awareness: Depth/normals alone cannot capture specularities, transparency, subsurface scattering, or roughness; there is no mechanism to estimate or control material properties for more physically faithful relighting.
- Background and mutual illumination: Training inpaints backgrounds to avoid entanglement, but real-world relighting requires consistent subject–environment interactions (mutual illumination, reflections, shadow casting on the scene); evaluation on full-scene relighting is missing.
- Temporal dynamics of lighting: The six-dimensional protocol includes temporal dynamics, yet there is no explicit model of moving light sources, time-varying shadows, and dynamic occlusions, nor stress tests on long sequences or fast motions.
- Mask dependency and robustness: The pipeline assumes accurate subject masks; sensitivity to segmentation errors, partial occlusions, and multi-subject scenes is not analyzed, and no joint segmentation–relighting strategy is provided.
- Conditioning implementation details: How the six-dimensional attributes are encoded and injected into the model is under-specified; no ablation demonstrates where and how each attribute enters the network and how disentangled the controls remain during generation.
- VLM-based annotation accuracy: The automatic labeling of lighting attributes using VLMs lacks validation against human or instrumented ground truth; error rates, bias across domains, and the impact of VLM mislabeling on training are unreported.
- VLM-based evaluation robustness: LumosBench relies on VLM judgments; calibration across different VLMs, susceptibility to prompt framing, and agreement with human ratings are not quantified, nor are standardized ground-truth tests provided.
- Metrics for physical plausibility: Beyond depth/normal L2 errors, there are no quantitative metrics for shadow alignment, illumination direction error, highlight roll-off, or exposure/energy consistency; synthetic benchmarks with known lighting are absent.
- HDR and photometric calibration: The system operates in SDR RGB space; handling HDR content, camera response functions, exposure, and physically meaningful units for intensity and color temperature remains unexplored.
- Generalization to complex domains: Robustness across diverse scene types (indoor/outdoor, nighttime, adverse weather), complex geometries, and extreme illumination is not systematically evaluated.
- Dataset availability and bias: The internal dataset and the IC-Light–generated synthetic pairs used for training are not released; potential bias or contamination (training on outputs of a baseline compared against) is not addressed via alternative training data or controls.
- Geometry estimator choice and integration: There is no comparison across geometry estimators, uncertainty-aware loss weighting, or exploration of end-to-end trainable geometry heads; the impact of estimator quality on final relighting is unstudied.
- Path consistency trade-offs: The speed–quality frontier under different step budgets (1-, 2-, 4-, 8-step) is not fully characterized; failure modes and theoretical guarantees of geometry-supervised shortcut models remain open.
- Scaling limits: Performance at higher resolutions (e.g., 1080p–4K) and longer videos (minutes rather than seconds) is not reported, including memory, latency, and quality degradation trends.
- Occlusion and cast shadow correctness: While improved plausibility is claimed, there is no dedicated evaluation of occlusion boundaries and cast shadow placement/direction against ground truth.
- Multi-light-source control: The protocol includes “light source type,” but controlling multiple sources, mixing types, and resolving competing attributes (e.g., warm key light + cool fill) is not demonstrated or measured.
- Perceptual control calibration: The mapping from attribute values to perceived changes (e.g., intensity or color temperature steps) is not psychophysically validated; user studies for control granularity and predictability are missing.
- Test-time geometry feedback: The model is trained with geometry supervision but performs geometry-free inference; exploring lightweight test-time feedback or self-consistency checks to improve OOD robustness is left open.
- Cross-attribute disentanglement: It is unclear whether changing one attribute (e.g., direction) keeps others (e.g., intensity, color temperature) stable; no measurements of attribute independence or interaction effects are provided.
- Fair baseline comparisons: Some baselines are training-free or frame-wise; matching inference budgets, ensuring comparable conditioning, and analyzing where baselines fail versus UniLumos is not exhaustively documented.
- Failure case analysis: The paper lacks systematic failure modes (e.g., glossy surfaces, strong backlight, fine shadow details) and guidance on when UniLumos should not be used or needs auxiliary cues.
- Multi-subject and complex scene compositions: Handling scenes with multiple masked subjects, inter-subject occlusions, and consistent relighting across all subjects is not addressed.
- Integration with inverse rendering: Opportunities to hybridize with lightweight inverse rendering (e.g., coarse reflectance/depth priors) for stronger physical guarantees without heavy inputs remain unexplored.
Practical Applications
Immediate Applications
The following applications can be deployed with today’s tooling and compute, leveraging UniLumos’ fast, geometry-free inference and its structured control/evaluation assets (LumosData and LumosBench).
- Bold, physically plausible post-production relighting for film, TV, and commercials [Industry: Media/Entertainment, Software]
- What: Replace re-shoots or heavy CG with controllable, temporally coherent relighting (e.g., “golden hour,” “hard key from camera-left,” “cool backlight”).
- How/Tools: Plugins or scripts for Adobe After Effects/Premiere, DaVinci Resolve, Nuke; a cloud/API “Relight as a Service.”
- Workflow: Provide subject mask + text prompt or reference video; batch process or interactive preview with few-step sampling.
- Dependencies/Assumptions: GPU availability for speed; subject masking quality; studio approval workflows; licensing for the Wan backbone and training assets.
- Catalog-scale lighting harmonization for e-commerce product photos/videos [Industry: Retail, Advertising, Software]
- What: Normalize product lighting across catalogs for consistent brand look or locale-specific variants (warm vs. cool lighting).
- How/Tools: Batch relighting pipeline integrated with digital asset management (DAM); structured prompts from LumosBench attributes ensure consistency.
- Dependencies/Assumptions: Accurate product/foreground masks; QC to avoid misrepresenting material appearance; compute budget for large volumes.
- Fast, controllable relighting for social content and creator tools [Daily Life; Industry: Social Media, Creator Platforms]
- What: One-click “cinematic lighting” filters and reference-driven transfers for short-form videos with stable temporal consistency.
- How/Tools: Mobile SDKs, TikTok/Snap/Instagram effects, CapCut/VN app integrations; text or reference-driven presets using the 6D attribute schema.
- Dependencies/Assumptions: On-device acceleration or cloud offload; guardrails to prevent deceptive before/after misuse.
- Live streaming and video conferencing lighting enhancement [Daily Life; Industry: Streaming, Communications]
- What: Improve perceived lighting on faces and subjects in real time or near-real time at 480p–720p.
- How/Tools: OBS/Streamlabs filters; Zoom/Teams plugins; few-step inference with lower step budgets for latency.
- Dependencies/Assumptions: Low-latency GPU; stable masks for moving subjects; user consent and disclosure.
- AR try-on and UGC compositing with matched lighting [Industry: AR/VR, Advertising]
- What: Relight captured subjects to match a target environment or campaign style for more believable AR overlays and try-ons.
- How/Tools: Reference-video-conditioned relighting; Unity/Unreal integration for marketing previews.
- Dependencies/Assumptions: Clear subject segmentation; brand safety reviews; mobile optimization if on-device.
- Data augmentation under controlled illumination for vision models [Academia; Industry: Robotics, Autonomous Systems, Retail]
- What: Generate lighting-diverse training datasets to improve robustness of detection/segmentation across harsh shadows, color temperatures, and intensities.
- How/Tools: Use 6D lighting attributes to systematically span conditions; integrate into MLOps pipelines.
- Dependencies/Assumptions: Maintain label validity post-relighting; ensure no shift in class semantics; track provenance.
- Attribute-level evaluation and regression testing for relighting products [Academia; Industry: ML Platforms, QA]
- What: Use LumosBench to score how well models follow specific lighting attributes (direction, intensity, color temperature, etc.) and catch regressions.
- How/Tools: Automated VLM-based scoring and interpretable dashboards; integrate into CI for creative tooling vendors.
- Dependencies/Assumptions: VLM reliability; domain-specific calibration; governance around automated metric use.
- Previsualization for cinematography and game cutscenes [Industry: Media/Entertainment, Gaming]
- What: Quickly iterate lighting designs on rehearsal footage or animatics without physically re-lighting sets.
- How/Tools: Text/reference-driven relighting presets mapped to common lighting setups (e.g., three-point, rim light scenarios).
- Dependencies/Assumptions: Final on-set lighting may deviate; use relighting as creative guide, not ground truth.
- Real estate and interior marketing with standardized lighting looks [Industry: Real Estate, Marketing]
- What: Produce consistent daylight/warm-ambient variants for listings and walkthroughs while preserving geometry and textures.
- How/Tools: Batch pipeline with attribute presets; per-room styles (daylight neutral, evening warm).
- Dependencies/Assumptions: Compliance with advertising standards; disclosures to avoid misrepresentation.
- Canonical-light normalization for ID photos and face analytics [Industry: Fintech, Security; Policy-sensitive]
- What: Normalize illumination to a canonical standard to reduce lighting variance in verification workflows.
- How/Tools: Controlled attribute presets tied to ID standards; pipeline validation against error/false positive impacts.
- Dependencies/Assumptions: Careful bias testing; provenance and disclosure; possible regulatory review due to security implications.
- Teaching aids for cinematography and computer graphics courses [Academia, Education]
- What: Interactive demonstrations of how light direction, hardness, color temperature, and temporal dynamics affect perception.
- How/Tools: Classroom apps using the 6D controls; side-by-side relit exemplars; LumosBench to quantify student assignments.
- Dependencies/Assumptions: Institutional compute or cloud credits; simplified UIs for educators/students.
Long-Term Applications
The following require additional research, scaling, validation, or ecosystem collaboration (e.g., real-time 4K, new hardware, standards/policy alignment).
- Real-time, broadcast-quality relighting at 4K/60 fps for virtual production and live events [Industry: Media/Entertainment]
- What: On-stage relighting for LED volumes or live concerts with sub-50 ms latency.
- Path to readiness: Model distillation, hardware acceleration (FP8/INT8), multi-GPU pipelines; joint optimization with camera ISP.
- Dependencies/Assumptions: High-bandwidth I/O; heat/power constraints; SMPTE/production pipeline integration.
- Lighting co-pilot that drives physical lights via DMX/CRMX from virtual previews [Industry: Cinematography, Stage Lighting]
- What: Translate relighting previews (6D attributes) into control signals for robotic fixtures to reproduce the target look physically.
- Path to readiness: Calibrate attribute-to-fixture mappings; closed-loop vision feedback; safety interlocks.
- Dependencies/Assumptions: Accurate scene-light calibration; standardization across lighting rigs; operator-in-the-loop.
- AR glasses and mobile AR with lighting-aware scene harmonization on-device [Industry: AR/VR, Consumer Hardware]
- What: Real-time relighting of captured subjects to match virtual content and vice versa for seamless mixed reality.
- Path to readiness: Compact models, dedicated NPUs, energy-efficient sampling; robust masks in egocentric video.
- Dependencies/Assumptions: On-device privacy guarantees; ergonomic power budgets.
- Standardized lighting metadata and compliance auditing for synthetic media [Policy; Industry: Platforms, Regulators]
- What: Adopt the six-dimensional lighting schema as a transparency layer for generative content metadata and audit.
- Path to readiness: Align with C2PA/content provenance; platform-level disclosure policies; independent auditing with LumosBench-like tests.
- Dependencies/Assumptions: Multi-stakeholder consensus; measurable impact on user trust.
- Medical tele-imaging and dermatology lighting normalization under clinical validation [Healthcare; Policy]
- What: Reduce lighting variance in patient-submitted photos for longitudinal comparisons.
- Path to readiness: Clinical trials to assess diagnostic impact; bias/failure case audits; FDA/CE regulatory pathways.
- Dependencies/Assumptions: Strict provenance, consent, and disclaimers; domain-specific retraining.
- Large-scale, attribute-controlled simulation for robotics and autonomous driving [Industry: Robotics, Automotive; Academia]
- What: Systematically vary lighting (direction, intensity, color temperature) to harden perception stacks against glare/shadows.
- Path to readiness: Integrate with CARLA/AirSim/Unreal pipelines; automated labeling QA; performance transfer studies.
- Dependencies/Assumptions: Maintain physical plausibility at high speeds; link to sensor models (HDR, polarizers).
- Forensic tooling: illumination-consistency analysis and relighting detection [Policy; Industry: Trust & Safety]
- What: Detect manipulated videos by probing inconsistencies between lighting and geometry; produce explainable reports.
- Path to readiness: Train detectors with relit/synthetic datasets from LumosData pipelines; benchmark on real-world cases.
- Dependencies/Assumptions: Adaptive adversaries; false positive costs; cooperation with platforms.
- Cross-modal inverse rendering hybrids (2D relighting + explicit 3D) [Academia; Industry: Graphics]
- What: Fuse UniLumos’ geometry-aligned supervision with NeRF/inverse rendering for editable, physically-based scene re-lighting.
- Path to readiness: Joint training with sparse multi-view; learned BRDF priors; scene-scale generalization.
- Dependencies/Assumptions: More compute and data; new benchmarks for edit fidelity vs. physical accuracy.
- Creative A/B testing at scale with causal lighting studies [Academia; Industry: Marketing Science]
- What: Measure causal effects of lighting attributes on engagement or perception across demographics.
- Path to readiness: Experimental design pipelines using the 6D controls; stratified deployment; privacy-preserving analytics.
- Dependencies/Assumptions: Ethical review; sample representativeness; confound control beyond lighting.
- Content moderation aids for “harmful misrepresentation via relighting” [Policy; Industry: Platforms]
- What: Automated tagging and disclosure when lighting manipulation materially alters context (e.g., crime-scene footage).
- Path to readiness: Policy definitions; thresholding on LumosBench-like scores; user-facing disclosures.
- Dependencies/Assumptions: Context-sensitive harm assessments; appeals and human-in-the-loop review.
- On-device personal photo library relighting with energy-aware scheduling [Daily Life; Industry: Mobile]
- What: Batch improve lighting on legacy albums (vacations, events) during idle/charging windows with consistent style presets.
- Path to readiness: Tiny models, power-aware job schedulers, UX for bulk operations.
- Dependencies/Assumptions: Storage and privacy controls; rollback/versions; user education.
Notes on Core Assumptions and Dependencies Across Applications
- Performance and compute: Reported ~20x speedup relies on few-step sampling and a capable GPU; real-time or 4K use will need distillation/quantization and possibly multi-GPU or NPU acceleration.
- Input quality: Foreground masks and prompts/reference clips strongly affect results; background inpainting (if used) must avoid artifacts that bias lighting judgments.
- Domain generalization: While results are strong on varied scenes, edge cases (extreme HDR, complex occlusions, reflective materials) may still fail; human QA advised in high-stakes outputs.
- Training-time assets: Geometry feedback uses depth/normal estimators (e.g., Lotus) during training; inference is geometry-free but benefits depend on the estimator’s accuracy and training coverage.
- Evaluation reliability: VLM-based LumosBench scoring is fast and interpretable but may require domain calibration and spot human audits.
- Ethics, safety, and compliance: Relighting can materially change perception; many deployments demand disclosure, provenance (e.g., C2PA), bias testing, and contextual policy guidance.
Glossary
- Ablation study: A controlled analysis that removes or alters specific components to assess their impact on performance. "Ablation study."
- AdamW: An optimizer that decouples weight decay from the gradient-based update, improving generalization in deep networks. "We use the AdamW optimizer with the learning rate of 1e-5"
- BiRefNet: A high-resolution segmentation model used to obtain precise subject masks. "using BiRefNet~\cite{zheng2024birefnet}"
- Color temperature: A measure (in Kelvin) describing the warmth or coolness of light. "color temperature"
- DiT blocks: Diffusion Transformer blocks; transformer layers tailored for diffusion backbones. "This combined tensor is injected into the DiT blocks of the Wan backbone."
- Diffusion models: Generative models that synthesize data by denoising from noise through learned stochastic processes. "recent diffusion models have shown strong potential"
- Few-step training regimes: Training or inference configurations that use a small number of denoising/integration steps to accelerate generation. "few-step training regimes"
- Flow matching: A generative modeling approach that learns velocity fields mapping noise to data along interpolation paths. "Flow matching formulates generative modeling as learning velocity fields"
- Foreground subject mask: A binary mask indicating the target subject region for processing or supervision. "foreground subject mask"
- High dynamic range images: Images with a wide luminance range capturing both very dark and very bright details. "high dynamic range images"
- Image-to-video (I2V): A task that animates static images into videos with plausible motion. "For image-to-video (I2V) tasks"
- Inpainting: Filling or synthesizing content in masked or missing regions of an image/video. "we inpaint the background using Gaussian noise"
- Inverse rendering: Recovering scene properties (geometry, reflectance, lighting) from images to enable physically grounded rendering. "inverse rendering pipelines~\cite{zhang2021physg, zhang2022modeling, blattmann2023stable}"
- Logit-normal distribution: A distribution where the logit-transformed variable is normally distributed; used here for timestep sampling. "t \in [0, 1] is sampled from a logit-normal distribution."
- LPIPS: Learned Perceptual Image Patch Similarity; a perceptual metric comparing images using deep features. "LPIPS"
- LumosBench: An attribute-level benchmark that evaluates lighting controllability using vision-LLMs. "we propose LumosBench, a disentangled attribute-level benchmark"
- LumosData: A scalable data pipeline that constructs diverse relighting pairs with structured lighting annotations. "we introduce LumosData, a scalable data pipeline"
- Monocular depth: Depth estimated from a single RGB image without stereo or multi-view input. "monocular depth and normal maps capture intrinsic scene structure."
- Path consistency learning: A technique enforcing consistent predictions across larger integration steps to enable fast, few-step sampling. "we employ path consistency learning"
- Peak Signal-to-Noise Ratio (PSNR): A distortion-based metric (in dB) assessing reconstructed image quality relative to a reference. "Peak Signal-to-Noise Ratio (PSNR)"
- Pseudo-ground-truth: Supervision signals derived from estimators or proxies rather than true manual labels. "pseudo-ground-truth maps"
- R-Motion metric: A temporal smoothness metric (from VBench) measuring motion consistency across video frames. "we adopt the R-Motion metric"
- RGB-space geometry feedback: Supervision computed on decoded RGB outputs using depth/normals to align lighting with geometry. "RGB-space geometry feedback"
- Semantic latent space: A learned representation space where semantics are captured, but distances may not reflect physical correctness. "optimized in semantic latent space"
- Spherical harmonics coefficients: Compact coefficients representing environment lighting over the sphere for rendering. "spherical harmonics coefficients"
- Structural Similarity Index (SSIM): A metric assessing image similarity based on perceived structural information. "Structural Similarity Index (SSIM)"
- Surface normals: Per-pixel 3D orientation vectors of surfaces, used to guide shading and lighting effects. "depth and surface normals"
- Spatiotemporal priors: Learned priors that model joint spatial and temporal structure in video generation. "to directly learn spatiotemporal priors"
- Temporal coherence: Consistency of appearance and lighting across consecutive video frames without flicker. "aiming to improve temporal coherence"
- Temporal condition vectors: Conditioning embeddings that encode timestep or step-size information for the generative model. "appended as temporal condition vectors."
- Text-to-video (T2V): Generating videos conditioned on textual descriptions. "In the field of text-to-video (T2V) generation"
- Training-free framework: A method that composes or aligns pre-trained models at inference time without additional training. "a training-free framework"
- Two-step consistency: A constraint ensuring that two smaller integration steps agree with one larger step in velocity predictions. "enforce two-step consistency using:"
- VAE (Variational Autoencoder): A latent-variable generative model with encoder/decoder used here for video latents. "Wan-VAE Encoder~\cite{wan2025}"
- Velocity field: A vector field indicating the direction and rate of change from noise toward data along the generative path. "Given a velocity field "
- Vision-LLMs: Models that jointly process visual inputs and natural language for tasks like attribute evaluation. "vision-LLMs"
- Wan 2.1: A large-scale flow-matching video generation backbone used as the base model. "Built upon Wan 2.1~\cite{wan2025}"
Collections
Sign up for free to add this paper to one or more collections.