VCode: a Multimodal Coding Benchmark with SVG as Symbolic Visual Representation
Abstract: Code has emerged as a precise and executable medium for reasoning and action in the agent era. Yet, progress has largely focused on language-centric tasks such as program synthesis and debugging, leaving visual-centric coding underexplored. Inspired by how humans reason over sketches, we advocate SVG code as a compact, interpretable, and executable visual representation. We introduce VCode, a benchmark that reframes multimodal understanding as code generation: given an image, a model must produce SVG that preserves symbolic meaning for downstream reasoning. VCode covers three domains - general commonsense (MM-Vet), professional disciplines (MMMU), and visual-centric perception (CV-Bench). To assess symbolic fidelity, we propose CodeVQA, a novel evaluation protocol in which a policy model answers questions over rendered SVGs; correct answers indicate faithful symbolic preservation. Empirically, frontier VLMs struggle to generate faithful SVGs, revealing a persistent gap between language-centric and visual-centric coding. To close this gap, we introduce VCoder, an agentic framework that augments VLMs along two axes: (i) Thinking with Revision, which iteratively analyzes discrepancies and refines SVG code; and (ii) Acting with Visual Tools, where detectors and parsers supply structured cues such as objects, shapes, and text beyond the model's intrinsic capacity. Across benchmarks, frontier VLMs with strong reasoning capabilities score well overall yet remain limited in professional knowledge and 3D reasoning. VCoder delivers a 12.3-point overall gain over the top-performing Claude-4-Opus. Human studies show that both humans and VLMs perform worse on rendered SVGs, their consistency reveals the promise of symbolic visual representation. The benchmark and code are available at https://github.com/CSU-JPG/VCode.








Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
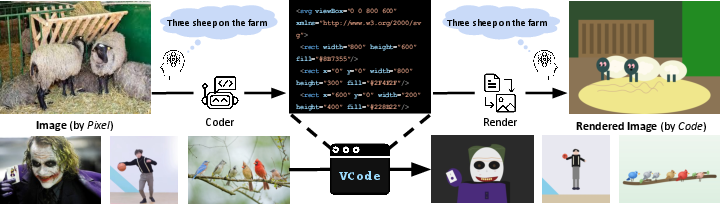
This paper introduces VCode, a new way to test how well AI can “understand” pictures by turning them into code. Instead of using regular images made of pixels (tiny colored dots), the AI writes SVG code—simple instructions like “draw a circle here” or “write this word there.” SVG is like a neat, editable sketch that focuses on what’s in the picture and where things are, not on tiny color details. The big idea: if an AI can rewrite a photo as clean, correct SVG, it probably understands the important parts of the scene.
What questions did the researchers ask?
They mainly asked:
- Can AI models look at a real-world image and write SVG code that captures its key meaning (like what objects are there, how many, where they are, and the relationships between them)?
- Does this SVG “sketch” preserve enough information for other tasks, like answering questions about the scene?
- How can we help AI do better at this “visual coding”—for example, by letting it revise its code or use extra vision tools?
How did they do it?
Here’s the approach in everyday terms:
The VCode benchmark: images → SVG → questions
- Step 1: The AI sees a normal image (like a photo) and writes SVG code to describe it (shapes, positions, text).
- Step 2: That SVG code is rendered back into a simplified image (like a clean sketch).
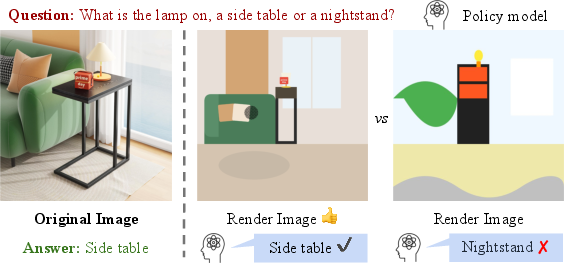
- Step 3: A “quiz AI” answers questions about the scene using only the rendered SVG image. If it gets the answers right, it means the SVG captured the important information.
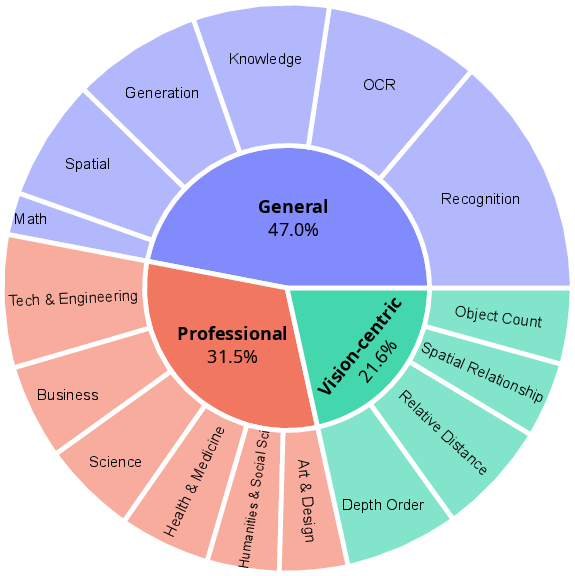
They test this on three kinds of tasks:
- General commonsense (MM-Vet): everyday scenes and relationships.
- Professional/college-level topics (MMMU): trickier subjects that need specialized knowledge.
- Visual perception (CV-Bench): counting, depth (near vs. far), and spatial relationships (left/right, in front/behind).
How they measured success
They checked performance in two simple ways:
- Similarity score: Does the SVG render “feel” similar to the original image in meaning? Think of it like comparing two summaries for the same story.
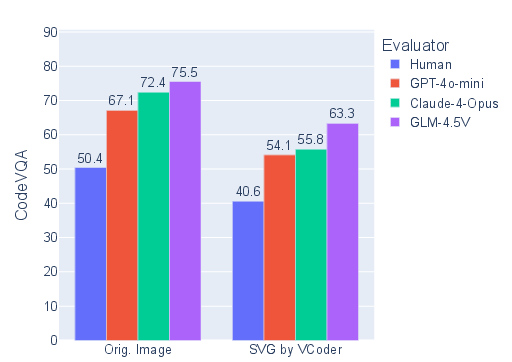
- Quiz score (CodeVQA): How often does the quiz AI answer the questions correctly using only the SVG render? This directly tests whether the SVG preserved the right details.
They also looked at how long the SVG code is. Shorter is better if it still captures the meaning (like a good summary).
VCoder: helping AI do better with two ideas
To improve results, they built VCoder, a test-time “helper” around existing vision-LLMs (AIs that can see images and read/write text):
- Thinking with Revision:
- The AI compares its rendered SVG image with the original photo, notices what’s wrong (for example, “the lamp is too far left” or “there are three sheep, not two”), and fixes the code in a few rounds.
- It’s like drafting, checking, and redrafting a sketch until it’s closer to the real scene.
- Acting with Visual Tools:
- The AI uses extra tools that detect helpful details:
- What objects are present (categories like “cat,” “lamp”)
- Where they are (bounding boxes—coordinates in the image)
- What shape they have (outlines/masks for irregular shapes)
- What text is in the image (OCR to read signs/labels)
- These cues guide the SVG code, making it more accurate without guessing every detail.
- The AI uses extra tools that detect helpful details:
What did they find, and why is it important?
Key results in simple terms:
- Today’s top AIs are good at language and reasoning, but they still struggle to turn real images into faithful SVG code. They often miss fine details like 3D layout (what’s in front/behind) or exact counts.
- Professional/college-level image questions are especially hard—mixing expert knowledge with accurate drawing is tough.
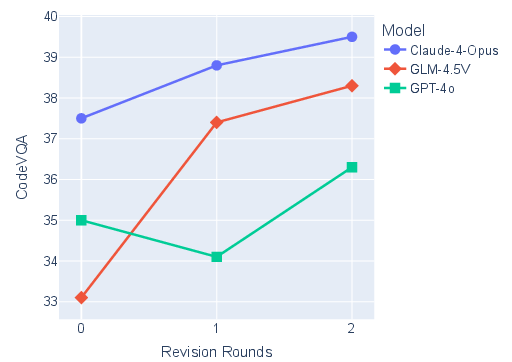
- The new VCoder approach makes a big difference. By revising code and using visual tools, it improved the overall score by about 12 points over a strong baseline model. That’s a meaningful jump.
- Longer SVG code usually means richer detail and better results, but the goal is to be both accurate and concise.
- Humans and AIs both do worse when answering questions on the simplified SVG renders than on the original photos. But their patterns are similar, suggesting that SVG is a promising “symbolic sketch” for both people and machines to reason with.
Why this matters:
- It shows a gap between “language coding” (writing programs from text) and “visual coding” (writing code that represents images). Closing this gap could help AIs plan, reason, and act in the world more reliably.
What could this change in the future?
- Smarter visual reasoning: Using SVG as a clean, symbolic picture could help AIs reason about scenes (counts, positions, relationships) more like people do with sketches.
- Better tools and agents: Robots, design assistants, and data-extraction tools could use SVG to understand and edit scenes precisely (change a shape, move an object, fix a layout).
- Easier editing and explainability: Because SVG is readable and editable, it’s easier to correct, inspect, or adapt than raw pixels—useful for safety, accessibility, and education.
- Next steps: Train AI models directly for this kind of visual coding, scale up data, and teach them to use tools autonomously so they can capture both the big picture and fine details.
In short, this paper argues that “drawing with code” (SVG) is a powerful bridge between seeing and thinking. It provides a new test, a strong baseline method, and evidence that symbolic visuals can push AI toward more human-like understanding.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a consolidated, actionable list of what remains missing, uncertain, or unexplored in the paper.
Benchmark design and coverage
- Small scale and limited diversity: VCode contains only 464 single-image items repurposed from MM-Vet, MMMU, and CV-Bench; it lacks breadth (e.g., scenes with complex layouts, rare categories, occlusions) and depth (e.g., long-tail distributions, multilingual text).
- No video or temporal reasoning: The benchmark excludes multi-frame/video settings, leaving open how SVG-based symbolic coding handles motion, temporal consistency, and dynamic occlusions.
- Excludes multi-image and interactive tasks: Many real-world applications require cross-image reasoning or tool/GUI interaction; the benchmark does not test such scenarios.
- Limited domain coverage: No evaluation on specialized domains (e.g., medical, satellite, document understanding beyond simple OCR, CAD/architectural drawings) where symbolic abstraction could be critical.
- Question–representation mismatch: CodeVQA uses questions not curated for symbol-recoverable content; some items depend on texture/shading/style cues inherently hard to encode in SVG, potentially penalizing faithful symbolic renderings.
- Missing classical vision/vectorization baselines: No comparison to non-LLM baselines (e.g., Potrace, vectorization pipelines, scene graph extractors, chart/diagram parsers) that could establish lower bounds or complementary strengths.
Evaluation protocol and metrics
- Unformalized symbolic information measure: The paper introduces conceptually but evaluates via proxies (SigLIP similarity, CodeVQA). A formal, geometry-aware definition and metric of “symbolic fidelity” is absent.
- Embedding similarity validity: SigLIP cosine similarity may be insensitive to geometric/layout errors, color mismatches, or counting mistakes; its error modes and calibration for SVG renderings are not studied.
- Policy-model dependence in CodeVQA: Results hinge on the chosen policy/evaluator (e.g., GPT-4o-mini). Sensitivity to model choice, prompting, and updates is only qualitatively shown; a robust, auditor-agnostic metric is lacking.
- Potential answer leakage via SVG text: The framework allows arbitrary <text> elements; safeguards against “cheating” (e.g., embedding the answer in small/hidden text) are not specified or enforced.
- Limited human evaluation reporting: Human studies lack details on sample size, protocols, inter-annotator agreement, and statistical significance; no calibrated human upper/lower bounds per subtask.
- No geometry/layout-specific metrics: Absent are object-level precision/recall, count accuracy, spatial relation accuracy, IoU/layout alignment, color palette fidelity, or scene-graph agreement metrics that directly test symbolic structure.
- Token-length metric ambiguity: “Code tokens” are reported without standardizing tokenizers across models; no compression/efficiency vs. fidelity Pareto analysis to quantify minimality of representations.
Methodological limitations (VCoder)
- Tool reliance and error propagation: VCoder critically depends on external detectors/segmenters/OCR (Florence-2, SAM-2, OpenOCR); robustness to tool errors, domain shift, or alternative tool choices remains unquantified.
- Unspecified tool configs: Thresholds (confidences, NMS), mask simplification parameters, and polygonization strategies are not documented; the fidelity–complexity trade-offs of shape simplification are not evaluated.
- Computational cost and latency: No measurements of run time, GPU hours, API costs, number of revision rounds, or context window utilization; scalability and practicality for real-world deployment are unknown.
- Stopping criteria and stability: The revision loop’s convergence criteria, failure modes, and stability across seeds/tasks are not analyzed; risks of oscillation or degradation with more iterations remain open.
- Generalization beyond chosen models: VCoder gains are shown primarily on Claude-4-Opus; portability to weaker/stronger open models, or to fully local pipelines, is not established.
- Overfitting risk: The tool set and prompts may be implicitly tuned to the benchmark distribution; cross-benchmark generalization (e.g., new questions, unseen domains) is untested.
Representation-level questions (SVG as symbolic vision)
- Limits of SVG for natural images: Many cues (texture, shading, translucency, fine-grained material properties) are difficult to encode symbolically; the boundary of representability and its impact on downstream reasoning remains uncharacterized.
- 3D reasoning in 2D SVG: The benchmark shows persistent 3D failures; how to encode depth/occlusion/3D topology in a primarily 2D vector format (e.g., layered scene graphs, meshes, NeRF-to-vector hybrids) is unexplored.
- Alternative symbolic formats: No comparison to other executable symbolic representations (e.g., TikZ, HTML5 Canvas, scene graphs, SVG+CSS constraints, relational DSLs) that might afford better geometric/semantic fidelity or brevity.
- Learning symbolic abstraction: The paper proposes test-time agents but not training paradigms for end-to-end learning of vision-to-symbol mapping; data generation, supervision signals, and curricula for scalable training are left open.
Experimental design and reporting
- Reproducibility concerns: Heavy reliance on closed-source APIs (both coders and evaluators) risks result drift as models update; seeds, temperatures, and decoding settings are not fully specified.
- Dataset provenance and licensing: The legal and licensing status for repurposed images and questions is not discussed; redistribution terms and usage constraints are unclear.
- Contamination risks: Baseline models or tools may be trained on the source benchmarks; no contamination checks are reported, potentially biasing results.
- Failure analysis: There is no systematic categorization of SVG errors (syntax failures, render errors, mis-localization, wrong counts, missing text, color/shape errors) to guide targeted improvements.
- Safety considerations: Executing SVGs can be unsafe if scripts/styles are allowed; the sandboxing of the rendering environment and permitted SVG subset are not specified.
Broader scope and future applications
- Downstream utility beyond VQA: Whether SVG renderings materially help planning, editing, robotics, accessibility, or teachability (e.g., code-level edits) is not validated with task-specific metrics.
- Interactive/closed-loop use: How agents perform when they can iteratively query the scene (e.g., request region-level crops/tools) or execute environment actions is untested.
- Multilingual and low-resource text: OCR and text encoding are English-centric; robustness to multilingual scripts, handwriting, and dense documents is not explored.
- Robustness and adversarial stress-testing: Sensitivity to clutter, lighting changes, adversarial patterns, heavy occlusion, perspective distortions, and extreme class imbalance remains unmeasured.
Practical Applications
Overview
Below are actionable, real-world applications derived from the paper’s findings and methods—using SVG as a symbolic visual representation (VCode), the CodeVQA evaluation protocol, and the VCoder agentic framework (Thinking with Revision + Acting with Visual Tools). Each application is categorized as Immediate (deployable now) or Long-Term (requires additional research, scaling, or tooling). Where relevant, sector links, potential tools/products/workflows, and feasibility assumptions are noted.
Immediate Applications
These applications can be piloted or deployed today with current vision–LLMs (VLMs), off-the-shelf detectors/segmenters/OCR, and existing engineering stacks.
- SVG-first diagram and UI asset pipelines (software, web, design systems)
- What: Convert screenshots, mockups, and bitmap diagrams into structured SVG assets for faster iteration and better accessibility.
- Tools/products/workflows: “SVGify” service; CI job that takes Figma/sketch exports → VCoder pipeline (detector/segmenter/OCR) → SVG → CodeVQA sanity checks → publish to component library.
- Assumptions/dependencies: Current VLMs plus Florence-2, SAM-2, OCR; consistent rendering; performance degrades on highly photorealistic scenes.
- Automated diagram QA and regression testing (software, documentation, publishing)
- What: Use CodeVQA to automatically check whether generated or edited diagrams preserve intended semantics (counts, labels, relationships).
- Tools/products/workflows: Git hooks/CI (SVG diff + CodeVQA queries like “How many nodes?” “Is A left of B?”); SigLIP similarity thresholds.
- Assumptions/dependencies: A policy model for VQA (e.g., GPT-4o-mini) and rule-based checks; test coverage design.
- Faster, cheaper annotation for vision datasets (CV, robotics, autonomy)
- What: Generate polygonal masks, bounding boxes, and structured labels directly in SVG to seed/accelerate human annotation.
- Tools/products/workflows: Semi-automated annotation with VCoder outputs as first pass; editor GUI to accept/fix polygons; auto-export to COCO/YOLO formats.
- Assumptions/dependencies: SAM-2 quality adequate; human-in-the-loop review; domain-specific taxonomies.
- Document and chart understanding with structured vector outputs (enterprise, finance, legal, education)
- What: Convert scanned diagrams, org charts, flowcharts, and infographics to SVG with readable text nodes; query them via CodeVQA for analytics and RPA.
- Tools/products/workflows: Ingestion pipeline (OCR + VCoder) → SVG store → CodeVQA templates (e.g., “What’s the critical path?” “Total nodes by type?”).
- Assumptions/dependencies: OCR accuracy; diagram types with regular structure; compliance/privacy controls.
- Accessibility upgrades for technical content (education, public sector, publishing)
- What: Replace/augment bitmap diagrams with SVG containing tags, roles, and text for screen readers and zoomable, crisp rendering.
- Tools/products/workflows: Authoring assistants that generate accessible SVG (alt text, titles, aria attributes); CodeVQA checks for label completeness.
- Assumptions/dependencies: Accessibility standards alignment (WCAG/ADA); editorial acceptance.
- Lightweight, bandwidth-efficient graphics for web/mobile (software, media)
- What: Convert icons, logos, line-art, and many diagrams from raster to vector to reduce page weight and improve responsiveness.
- Tools/products/workflows: Batch processing pipeline with SigLIP/CodeVQA gates to ensure semantic fidelity; A/B testing on performance.
- Assumptions/dependencies: Works best for non-photorealistic content; quality thresholds tuned to reduce visual drift.
- Privacy-preserving visual sharing and analysis (enterprise, healthcare admin, research)
- What: Share abstracted SVG representations (counts, geometry, relationships) instead of original images to minimize exposure of identifiable details.
- Tools/products/workflows: VCoder abstraction presets (e.g., mask silhouettes, label-only); CodeVQA-based “utility vs. privacy” fitness functions.
- Assumptions/dependencies: Clear policy for acceptable abstraction level; domain review for re-identification risk.
- Benchmarking and procurement of multimodal models (industry R&D, academia)
- What: Use VCode and CodeVQA to evaluate candidate VLMs on symbolic visual fidelity, not just text QA or synthetic charts.
- Tools/products/workflows: Internal eval harness; leaderboard; model selection guided by domain subsets (e.g., 3D spatial, OCR-heavy).
- Assumptions/dependencies: Stable budget/APIs; model choice may affect token costs due to long SVGs.
- Agent design pattern: revision + tool-use for visual code (software agents, MLOps)
- What: Adopt VCoder’s “Thinking with Revision” and “Acting with Visual Tools” as a reusable pattern to improve any multi-step generation task with render-and-compare loops.
- Tools/products/workflows: Prompt libraries; diff-explaining templates; render-feedback APIs; detectors/segmenters as callable tools.
- Assumptions/dependencies: Tool orchestration layer; cost controls for iterative loops.
- Synthetic data generation and augmentation (CV training, robustness)
- What: Produce vector abstractions of scenes and render diverse styles/perturbations; use SVG-to-raster renders to augment training sets.
- Tools/products/workflows: SVG parameter sampling (colors, shapes, layout) → renderer farm → dataset registry; CodeVQA to guarantee semantic constraints.
- Assumptions/dependencies: Careful distributional matching; value higher for tasks needing shape/layout invariance.
- QA over user interfaces and GUIs (software testing, RPA)
- What: Convert GUI screenshots to SVG/DOM-like structures; ask CodeVQA questions to validate layout rules (e.g., “Is the submit button below the form?”).
- Tools/products/workflows: Screen capture → VCoder → layout assertions; integrate into nightly UI tests.
- Assumptions/dependencies: Accuracy on fine-grained UI elements; consistent styling conventions.
- Educational tooling for geometry and graphics (education, edtech)
- What: Turn student sketches/photos into editable SVG; run CodeVQA for auto-grading of geometric relations (parallel, perpendicular, counts).
- Tools/products/workflows: Classroom tooling; SVG editor with automated hints; rubric-aligned CodeVQA question sets.
- Assumptions/dependencies: Scope constrained to geometric/diagrammatic content; teacher oversight.
Long-Term Applications
These ideas need stronger visual-centric coding, better 3D reasoning, domain training, or standards integration before reliable deployment.
- Vision-as-code world models for robots and agents (robotics, embodied AI)
- What: Maintain a symbolic SVG-like scene map (objects, topology, constraints) that supports planning and verifiable actions.
- Tools/products/workflows: Perception → symbolic scene compiler → planner; continuous revision via render-and-compare; verified action policies.
- Assumptions/dependencies: Robust 3D/spatial reasoning; temporal persistence; safety certification.
- Photoreal-to-CAD/diagram conversion for industry (manufacturing, AEC/BIM, utilities)
- What: Convert site photos into vector floor plans, P&IDs, wiring diagrams, or simplified CAD layers.
- Tools/products/workflows: Domain-specific ontologies; constraints solvers; human-in-the-loop CAD validation; downstream BIM ingestion.
- Assumptions/dependencies: High-precision shape/scale estimation; alignment with surveyed measurements.
- Medical imaging abstractions for communication and QA (healthcare)
- What: Transform radiology images or pathology slides into symbolic overlays highlighting structures, counts, and relations for reporting and audit.
- Tools/products/workflows: Medical-grade detectors/segmenters; regulatory-grade evaluation; clinician review loops with CodeVQA.
- Assumptions/dependencies: Clinical validation; strict safety and privacy compliance; domain-tuned models.
- Autonomous driving scene abstraction and verification (automotive)
- What: Generate certifiable, symbolic representations of driving scenes (objects, lanes, occlusions) to support explainable planning and safety cases.
- Tools/products/workflows: Multi-sensor fusion → vector scene graph; CodeVQA for safety assertions (“Is pedestrian in crosswalk?”).
- Assumptions/dependencies: Real-time constraints; high recall on edge cases; certification pathways.
- Digital twins with symbolic overlays (energy, manufacturing, facilities)
- What: Use camera feeds to maintain symbolic layers (flows, states, counts) over physical assets for monitoring and predictive maintenance.
- Tools/products/workflows: Video-to-SVG change detection; rule engines querying CodeVQA (“Any valve open beyond threshold?”).
- Assumptions/dependencies: Reliable object-state detection; integration with SCADA/CMMS; operator trust.
- Standardized accessible graphics in public information (policy, govtech, education)
- What: Mandate vectorized, accessible diagrams for public reports, maps, and instructions with machine-checkable semantics.
- Tools/products/workflows: Authoring requirements; CodeVQA test suites for compliance; publishing platforms that prefer SVG.
- Assumptions/dependencies: Policy adoption; training for content creators; language/locale support.
- Compliance and audit of complex diagrams in filings (finance, legal, pharma)
- What: Verify that flowcharts, risk graphs, or trial schemas in filings match textual claims and regulatory constraints.
- Tools/products/workflows: Cross-modal checking (text → expected relations; SVG → observed relations) with CodeVQA-based assertions.
- Assumptions/dependencies: High precision on domain-specific glyphs/notation; regulator buy-in.
- Multimodal compilers and IDEs (software, AI tooling)
- What: “Compile” images/sketches into structured code (SVG/HTML/DSL) with revision loops and testable specs; enable semantic diffs and merges.
- Tools/products/workflows: IDE plugins; spec-driven prompts; render-and-compare tests in CI; typed schema for visual DSLs.
- Assumptions/dependencies: Longer context windows; stable intermediate DSLs; developer adoption.
- Privacy-preserving analytics standards (policy, security, data governance)
- What: Formalize sharing of symbolic scene abstractions (SVG + provenance) to enable analytics without raw image exposure.
- Tools/products/workflows: Data agreements that define acceptable abstraction; utility–privacy scoring via CodeVQA; governance dashboards.
- Assumptions/dependencies: Risk modeling for re-identification; standardization bodies engagement.
- On-device symbolic perception for low-bandwidth scenarios (edge/IoT)
- What: Encode scenes as compact vectors and transmit only semantic updates in constrained networks (drones, sensors).
- Tools/products/workflows: Tiny detectors; SVG delta streaming; remote CodeVQA for health checks.
- Assumptions/dependencies: Efficient on-device models; robust compression of shapes; intermittent connectivity handling.
- AI safety and verification via symbolic outputs (cross-sector)
- What: Prefer symbolic visual outputs that can be inspected, tested, and formally verified over opaque image embeddings.
- Tools/products/workflows: Safety cases built on CodeVQA assertions; formal properties for graphical invariants; audit trails of revisions.
- Assumptions/dependencies: Tooling for formal verification; regulatory frameworks valuing symbolic traceability.
- Advanced tutoring with diagrammatic reasoning (education, edtech)
- What: Tutors that can parse and reason over student-uploaded diagrams (physics FBDs, circuits, geometry) and give stepwise feedback.
- Tools/products/workflows: Domain libraries (units, constraints); interactive SVG editors; mastery-based CodeVQA tasks.
- Assumptions/dependencies: High reliability on domain notation; integration with LMS/assessment policies.
Notes on Feasibility and Risks
- Current limitations: Professional knowledge and 3D/spatial relations are still challenging; SVG fidelity lags raw-image VQA; long-context code generation can be costly.
- Dependencies: External tools (detectors, segmenters, OCR), robust rendering, policy VQA models, domain ontologies, and human-in-the-loop for high-stakes use.
- Cost/performance: Revision loops increase latency and token usage; careful gating (SigLIP thresholds, early stopping) is needed.
- Ethics/privacy: Symbolic abstraction reduces but does not eliminate re-identification risk; domain review and governance are essential.
Glossary
- Acting with Visual Tools: An augmentation strategy where models call external vision utilities to provide structured cues for code generation. "Acting with Visual Tools, where detectors and parsers supply structured cues (objects, shapes, text) beyond intrinsic model capacity."
- adaptive simplification strategy: A method to reduce complex shapes into fewer points while preserving shape area/structure. "These masks are then downsampled into sparse coordinate points through an adaptive simplification strategy, which reduces the number of vertices while keeping the overall area nearly unchanged."
- agentic intelligence: Model capabilities oriented toward autonomous reasoning and taking actions in environments. "To advance reasoning and agentic intelligence, {code} has emerged as a powerful medium for interacting with digital environments"
- bounding boxes: Rectangular coordinates that localize objects in an image. "we rely on bounding boxes predicted by Florence-2~\cite{florence2}, expressed as absolute coordinates together with the image width and height."
- Code tokens length: The length (in tokens) of generated SVG code, used as a measure of representational efficiency. "Code tokens length. Beyond faithful representation, we argue that an effective coder should represent an image with as few code tokens as possible"
- CodeVQA: An evaluation protocol that assesses whether rendered SVGs support correct question answering. "To assess symbolic fidelity, we propose CodeVQA, a novel evaluation protocol in which a policy model answers questions over rendered SVG"
- cosine distance: A metric on embeddings measuring angular dissimilarity between vectors. "and compute their cosine distance:"
- CV-Bench: A visual perception benchmark focusing on counting, depth, and spatial relations. "visual-centric perception (CV-Bench~\cite{cvbench})."
- depth order: A perception subtask determining relative depth of objects in a scene. "depth order (30)"
- difference signal: A computed representation of discrepancy between a rendered image and the target image used to guide revisions. "we compute a difference signal $\Delta^{(t)} \gets \psi\big(\mathcal{V}, \widetilde{\mathcal{V}^{(t)}\big)$"
- downstream reasoning: Subsequent reasoning tasks that rely on the symbolic output produced by the model. "given an image, a model must produce SVG that preserves symbolic meaning for downstream reasoning."
- embedding consistency: Alignment of high-level representations of original and rendered images via encoder embeddings. "One way to measure this is through embedding consistency."
- Execute Pass: An evaluation criterion where generated code is considered correct if it passes execution-based tests. "Code & Execute Pass\"
- external perception toolboxes: Third-party detectors/segmenters that provide structured visual cues to the model. "We equip the coder with external perception toolboxesâe.g., object detectors and segmenters~\cite{florence2,sam2}âto supply structured cues"
- Florence-2: A vision model used here for object detection and localization cues. "Florence-2~\cite{florence2}"
- geometric primitives: Basic shapes (e.g., rectangles, circles) used to represent visual elements in SVG. "While regular geometric primitives are straightforward to express, a key challenge lies in representing irregular boundaries."
- indicator function: A function that returns 1 if a condition is true, else 0, used here to score correctness. "where is the indicator function."
- instance-weighted average: An averaging method that weights scores by the number of instances per subtask. "The Overall score is calculated as an instance-weighted average of the three subtasks (MM-Vet, MMMU, and CV-Bench) using their respective question counts."
- LLM-as-Judge: A scoring setup where a LLM evaluates correctness of open-ended answers. "and it can be a LLM-as-Judge in open-ending."
- Long-Context Code Inputs: The challenge of generating very long code sequences needed to represent images. "(i) Long-Context Code Inputs: fully representing an image typically requires thousands of tokens;"
- MCQ: Multiple-choice question format used for evaluation. "Text & MCQ\"
- MM-Vet: A benchmark evaluating integrated multimodal perception and reasoning capabilities. "MM-Vet~\cite{mmvet}"
- MMMU: A multi-discipline benchmark focusing on expert-level multimodal understanding. "MMMU~\cite{mmmu}"
- object detectors: Models that identify and localize objects in images, providing categories and boxes. "object detectors and segmenters~\cite{florence2,sam2}"
- OpenOCR: An OCR system used to extract and encode text into SVG. "We apply OpenOCR~\cite{openocr} to detect and transcribe text regions"
- OpenQA: Open-ended question answering evaluation format. "Text & OpenQA\"
- policy model: A model used to produce answers from images and questions in the evaluation protocol. "We define a policy model that outputs an answer given an image and a question ."
- polygonal paths: Simplified polygon representations of object boundaries for SVG. "The resulting polygonal paths provide the Coder with compact yet faithful shape descriptions"
- relative distance: A perception subtask assessing comparative distances between objects. "relative distance (30)"
- Render\,\,VQA: The evaluation pipeline that renders SVG then performs VQA over the rendering. "introduces CodeVQA (Render\,\,VQA), which judges whether the rendered SVG preserves the original imageâs symbolic meaning."
- Revise with Render Feedback: A step in the revision process where code is updated based on discrepancies after rendering. "(ii) Revise with Render Feedback."
- revision loop: Iterative process of detecting differences and refining code until satisfactory rendering. "This revision loop is repeated for , progressively refining the reconstruction"
- SAM-2: A segmentation model used to generate detailed masks for shapes. "SAM-2~\cite{sam2}"
- segmentation masks: Pixel-level regions corresponding to objects, used to capture shapes for SVG. "we employ SAM-2~\cite{sam2} to generate segmentation masks that capture detailed object contours."
- semantic similarity: The alignment of meaning between original and rendered images as measured by embedding-based metrics. "We also observe a positive correlation between semantic similarity (SigLIP) and CodeVQA."
- SigLIP: A pretrained visual encoder used to measure embedding similarity between images. "SigLIP~\cite{siglip,siglip2}"
- SigLIP score: A metric derived from SigLIP embeddings that quantifies image-render semantic alignment. "SigLIP score."
- stratified sampling: A sampling strategy ensuring balanced representation across sub-tasks. "through a stratified sampling process."
- superpixels: Groups of pixels forming perceptually meaningful atomic regions, used in some image representations. "encode them as pixels or superpixels."
- symbolic fidelity: The degree to which generated code preserves the semantic content of the original image. "To assess symbolic fidelity, we propose CodeVQA,"
- symbolic information representation: A formal representation of an image’s core semantic content used in the loss definition. "where denotes a symbolic information representation."
- symbolic visual representation: A representation that abstracts images into symbols suitable for reasoning and execution. "their consistency reveals the promise of symbolic visual representation"
- test-time scaling: Enhancing model performance at inference by increasing iterative reasoning or resources. "we enhance reasoning through test-time scaling and a revision strategy"
- Thinking with Revision: An iterative method where the model analyzes discrepancies and refines SVG code. "(i) Thinking with Revision, which iteratively analyzes discrepancies and refines SVG code;"
- VCode: A benchmark reframing multimodal understanding as generating SVG from natural images. "We introduce VCode, a benchmark that reframes multimodal understanding as code generation"
- VCoder: An agentic framework augmenting VLMs with revision and visual tools for better SVG generation. "we introduce VCoder, an agentic framework that augments VLMs along two axes"
- visionâLLM (VLM): A model that processes both visual and textual inputs/outputs. "we propose CodeVQA, a novel protocol in which a visionâLLM must answer core questions"
- visual encoder: A neural encoder producing feature embeddings for images. "We leverage a pretrained visual encoder such as SigLIP~\cite{siglip,siglip2}"
- vision-centric coding: Code generation that prioritizes visual structure and semantics rather than textual tasks. "revealing a persistent gap between language-centric and visual-centric coding."
- VQA (Visual Question Answering): Task of answering questions about images, used to evaluate SVG renderings. "single-image VQA instances"
Collections
Sign up for free to add this paper to one or more collections.