Mathematical exploration and discovery at scale
Abstract: AlphaEvolve is a generic evolutionary coding agent that combines the generative capabilities of LLMs with automated evaluation in an iterative evolutionary framework that proposes, tests, and refines algorithmic solutions to challenging scientific and practical problems. In this paper we showcase AlphaEvolve as a tool for autonomously discovering novel mathematical constructions and advancing our understanding of long-standing open problems. To demonstrate its breadth, we considered a list of 67 problems spanning mathematical analysis, combinatorics, geometry, and number theory. The system rediscovered the best known solutions in most of the cases and discovered improved solutions in several. In some instances, AlphaEvolve is also able to generalize results for a finite number of input values into a formula valid for all input values. Furthermore, we are able to combine this methodology with Deep Think and AlphaProof in a broader framework where the additional proof-assistants and reasoning systems provide automated proof generation and further mathematical insights. These results demonstrate that LLM-guided evolutionary search can autonomously discover mathematical constructions that complement human intuition, at times matching or even improving the best known results, highlighting the potential for significant new ways of interaction between mathematicians and AI systems. We present AlphaEvolve as a powerful new tool for mathematical discovery, capable of exploring vast search spaces to solve complex optimization problems at scale, often with significantly reduced requirements on preparation and computation time.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
A simple guide to “Mathematical exploration and discovery at scale”
1) What is this paper about?
This paper introduces AlphaEvolve, an AI tool that helps discover new mathematical ideas. It combines two things:
- A LLM (an AI that can write and edit code)
- An “evolution” process that tries many versions of code, keeps the best ones, and improves them over time
The goal is to find clever mathematical constructions (like special sets or shapes) that solve hard problems or beat known records. The authors tested AlphaEvolve on 67 math problems and showed that it can rediscover known results, sometimes find better ones, and even help produce proofs with other AI tools.
2) What questions are the authors trying to answer?
In simple terms, they ask:
- Can AI automatically discover good mathematical constructions, not just calculate or prove things?
- Can it scale up to many different problems with little setup time?
- Can it spot patterns from small examples and write a general formula that works for all sizes?
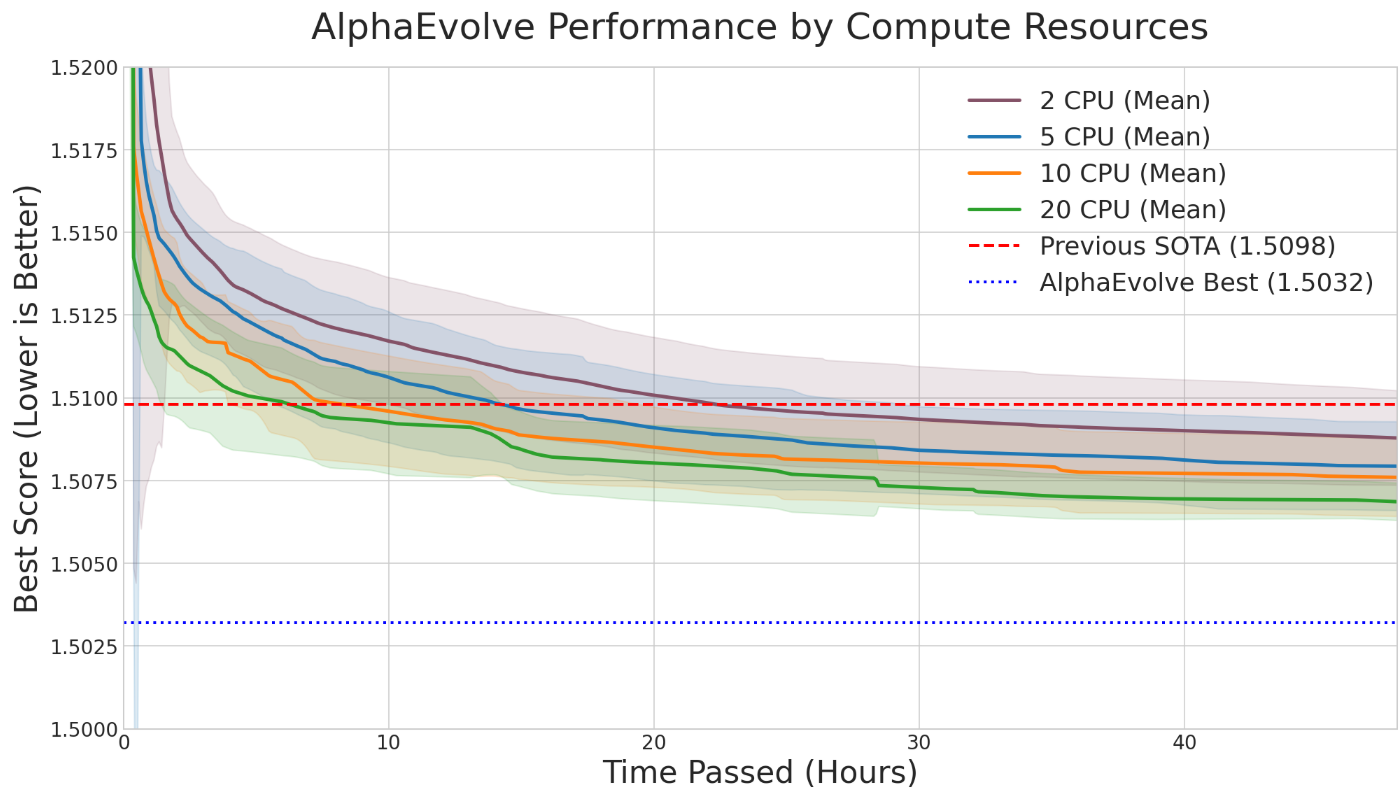
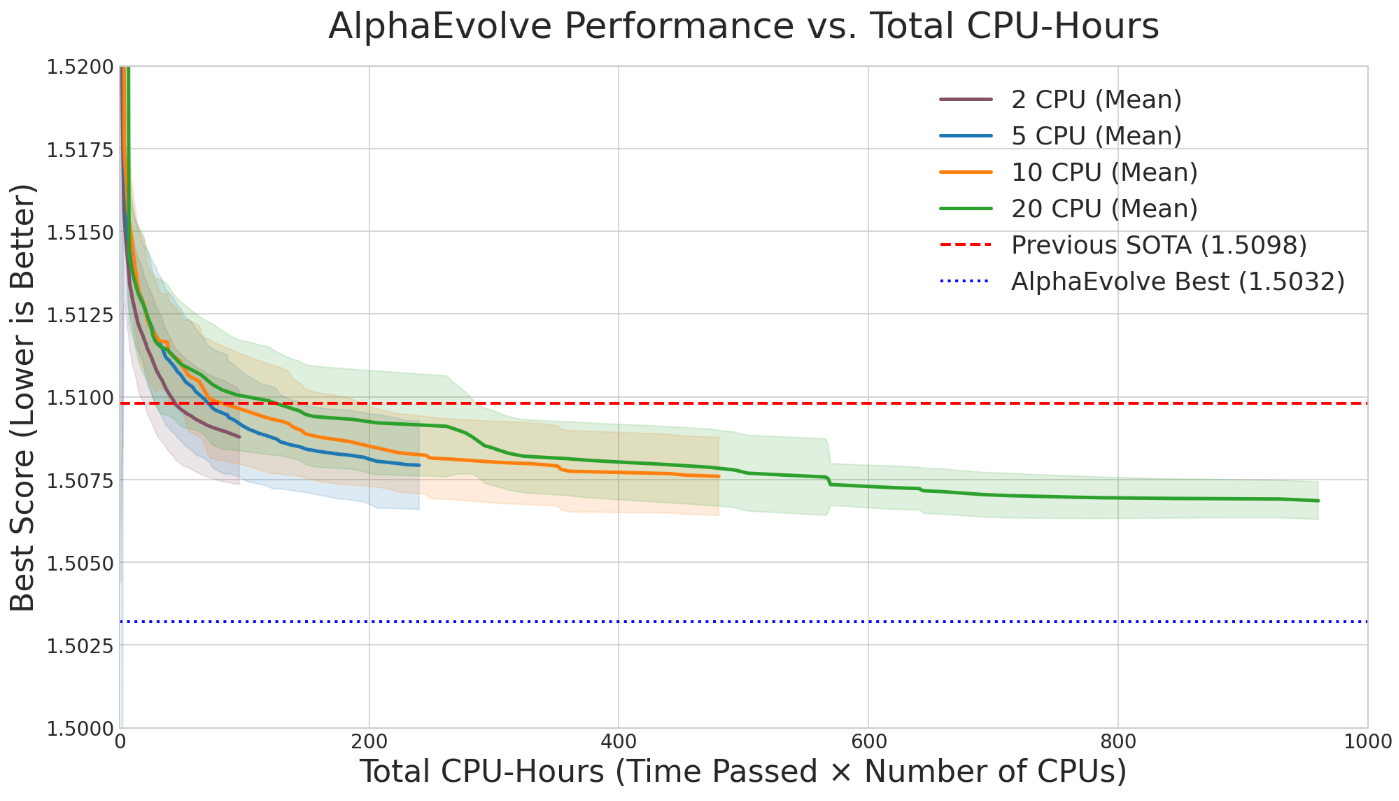
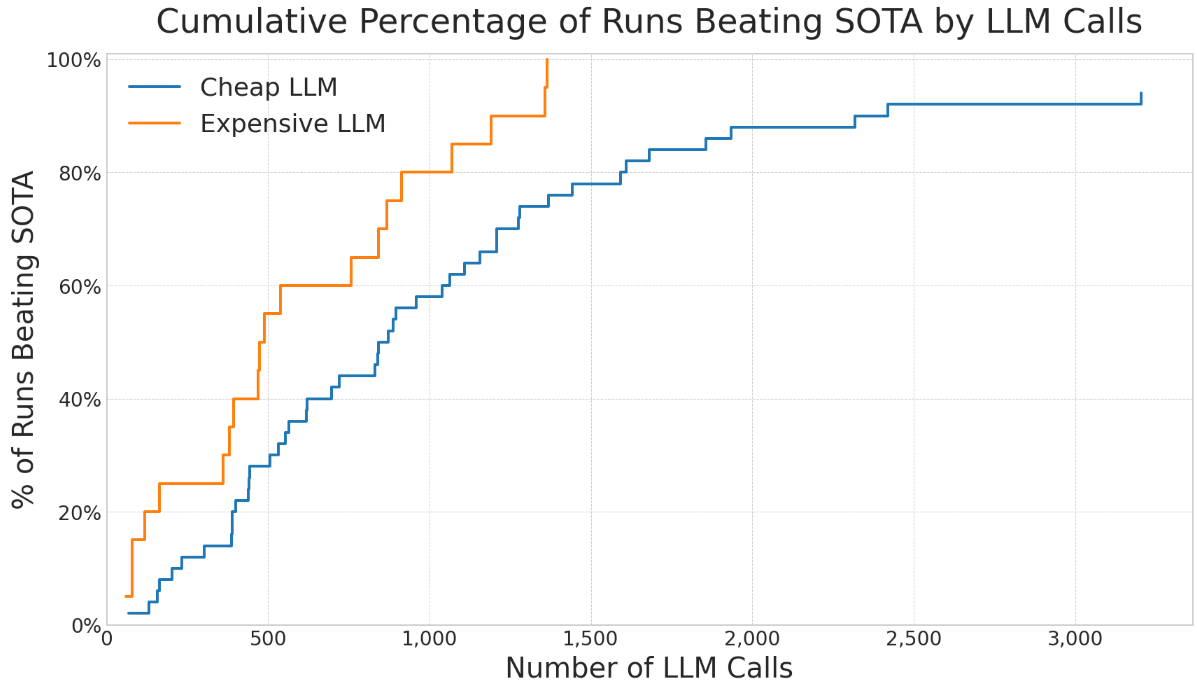
- How do choices like “which AI model to use” or “how much computing power to spend” affect success?
- When does this approach work well, and when does it struggle?
3) How does AlphaEvolve work?
Think of it like a team of robot inventors writing code to build math objects. The process runs in a loop:
- The Generator (an AI model) takes good programs and writes new, slightly different ones — like making “mutations” in evolution.
- The Evaluator (a checking program) runs each new program and gives it a score based on how well it solves the problem.
- The best programs survive, and the cycle repeats.
There are two main modes:
- Search mode: Instead of directly building a solution, AlphaEvolve evolves programs that are good at searching for solutions fast — like designing better treasure maps rather than digging randomly.
- Generalizer mode: AlphaEvolve tries to find a single program that works for many sizes of a problem, not just one. It learns patterns from smaller cases and tries to write a general formula.
AlphaEvolve can also work with other AI tools:
- Deep Think: turns a discovered pattern into a clear, step-by-step proof and formulas.
- AlphaProof: formalizes the proof in a proof assistant (Lean) to check it with complete rigor.
Key ideas explained with everyday language:
- “Heuristic”: a clever shortcut or strategy.
- “Evolutionary search”: keep trying slightly better versions and keep the best — like breeding faster racehorses.
- “Finite field”: math where numbers wrap around (like a clock) and you can still add, subtract, multiply, and divide (except by zero).
- “Kakeya/Nikodym sets”: carefully chosen collections of points that contain lines in many directions — they’re puzzles about how small such sets can be.
4) What did AlphaEvolve find?
Here are the main takeaways from the experiments:
- It worked across many areas: analysis, combinatorics, geometry, and number theory.
- On most of the 67 problems, it matched the best-known results; in several, it improved them.
- It sometimes discovered patterns that could be turned into formulas valid for all sizes, not just specific cases.
- It helped inspire new human-written math papers.
Highlights:
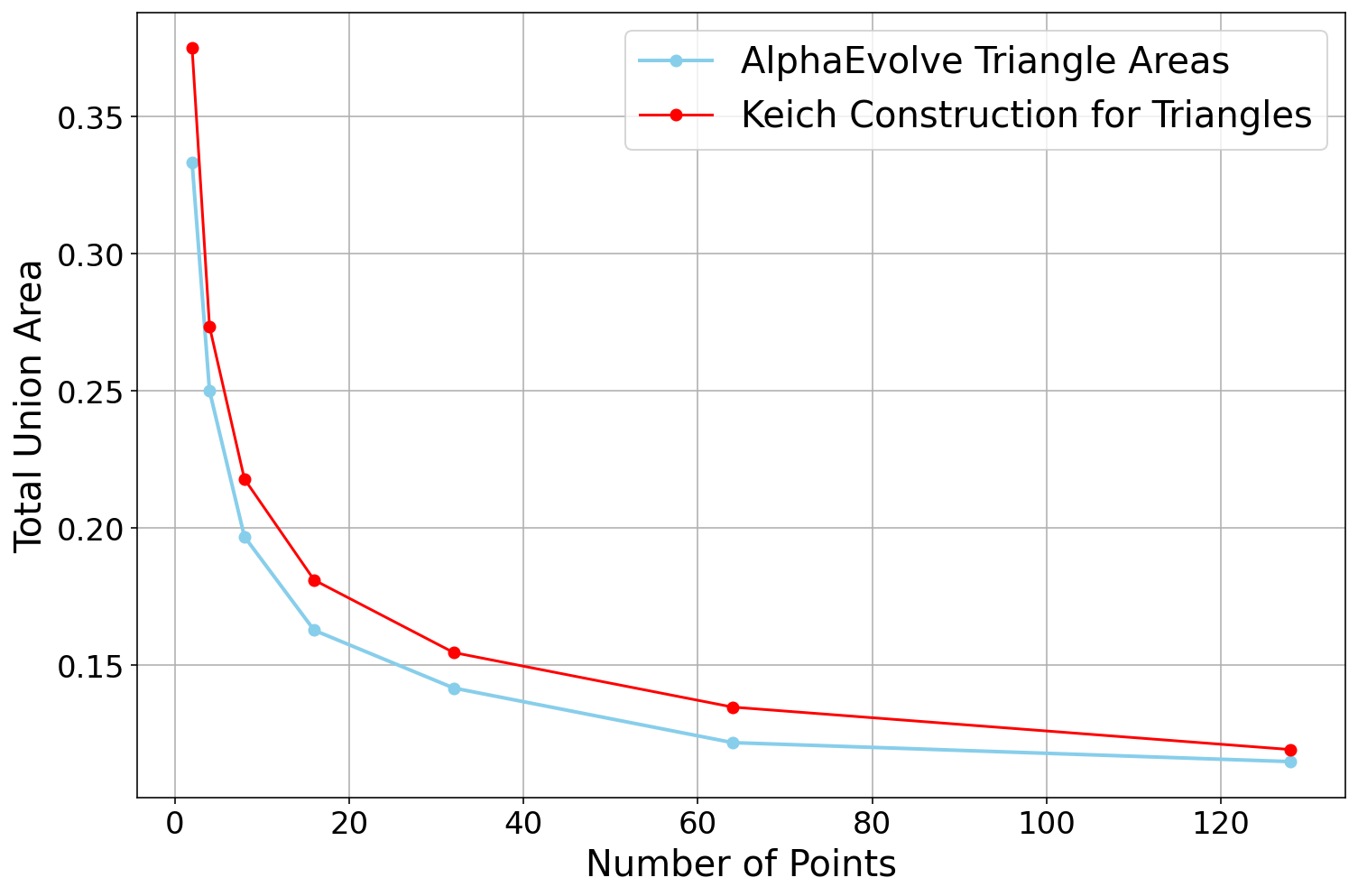
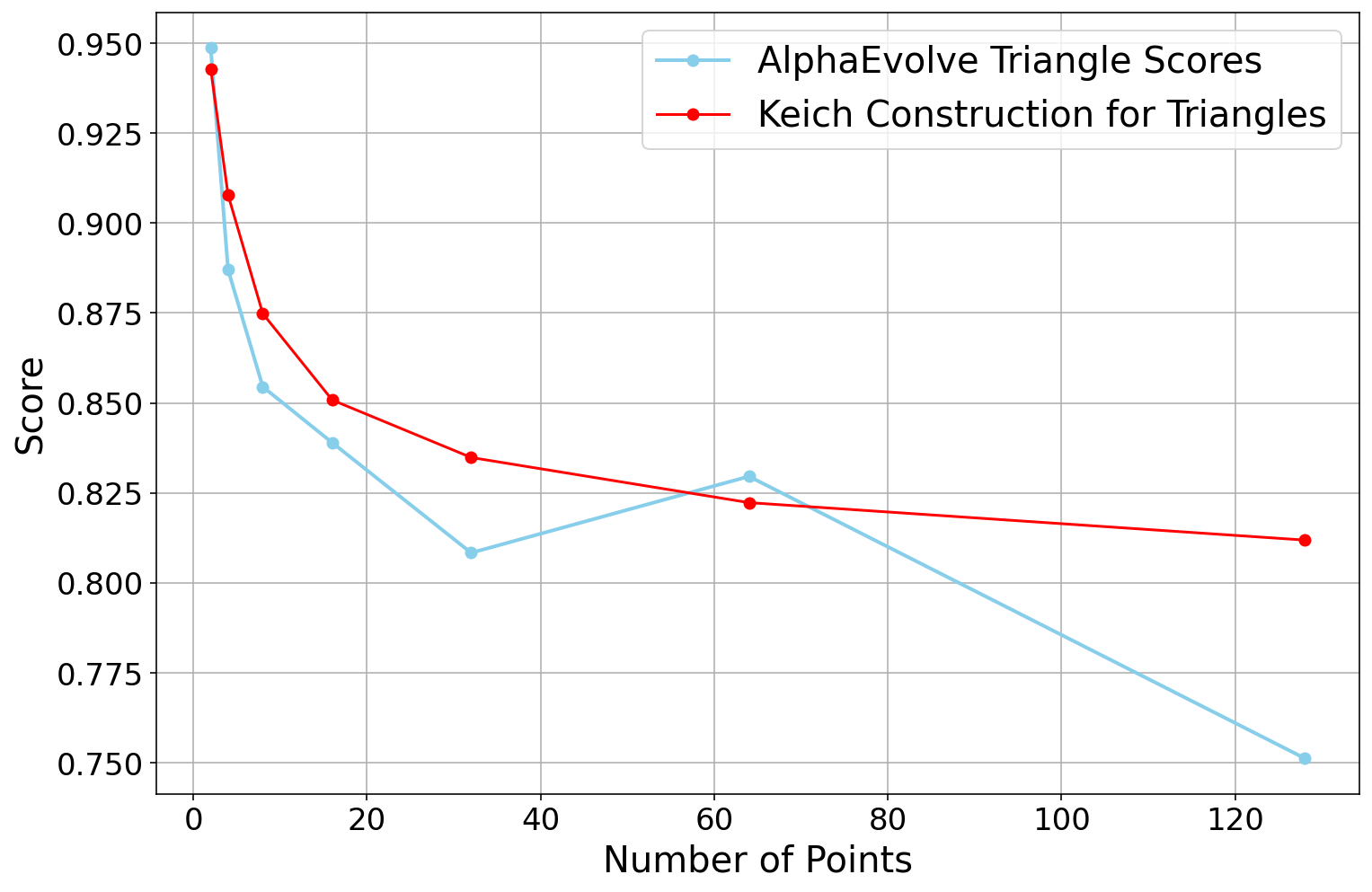
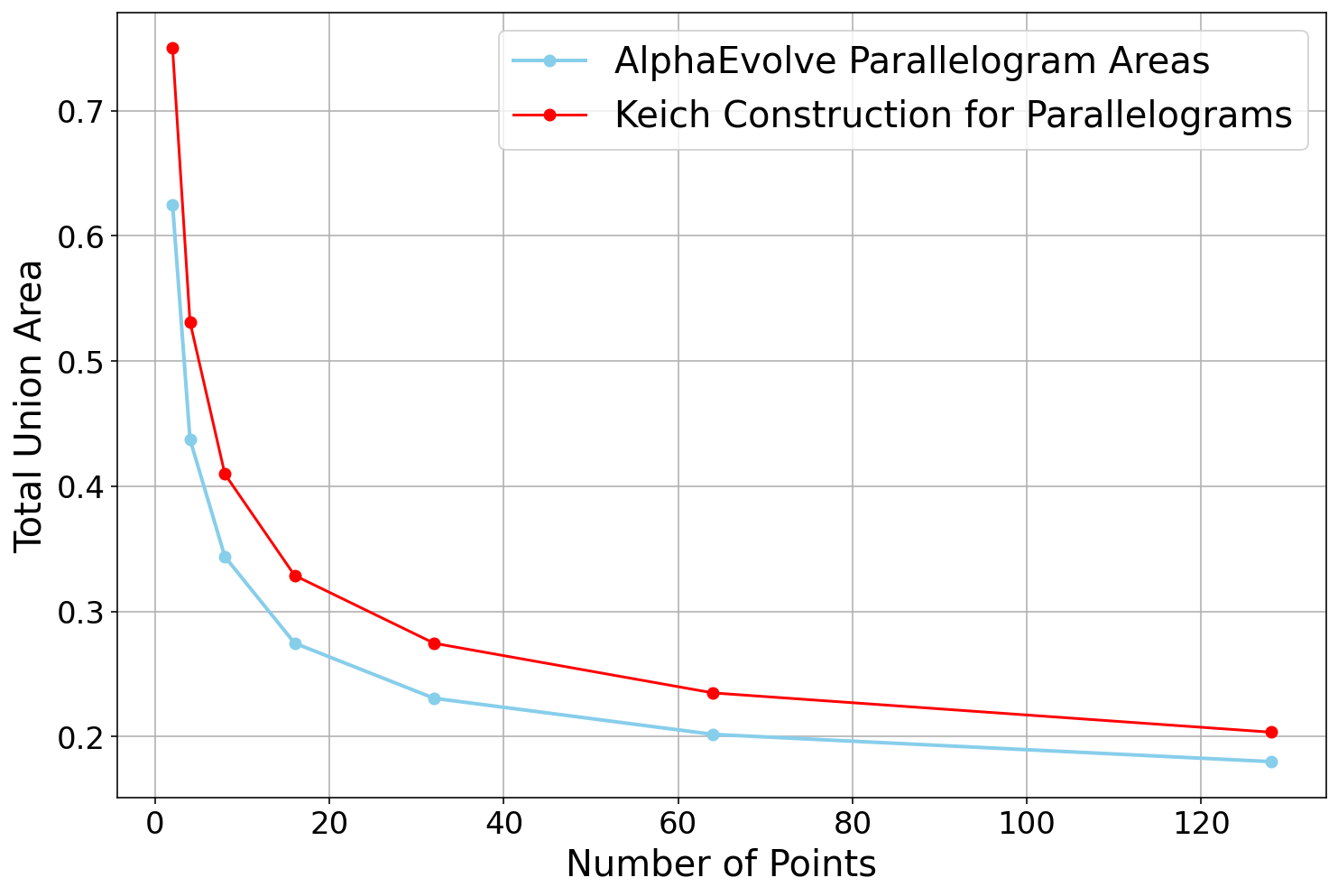
- Finite field Kakeya sets (3D, 4D, 5D):
- AlphaEvolve found new constructions that slightly improve known results by tightening the “lower-order terms” (the smaller parts of a big formula). In plain terms: the leading idea matched the best known, and AlphaEvolve sharpened the details.
- In 3D, for primes where p ≡ 1 mod 4, it found a construction beating a previous bound by a small but meaningful amount.
- In 4D and 5D, it found results consistent with the best top-level terms and improved the smaller terms.
- Deep Think explained some of the deeper number theory behind the constructions (like connections to elliptic curves).
- Finite field Nikodym sets:
- AlphaEvolve’s ideas, combined with human simplification, led to a stronger general construction: for fixed dimension d ≥ 3, you can make the set very close to the whole space but still save about pd−1·log p points with an improved constant. This improved on known results and is being written up by one of the authors.
- When given a tiny hint (“you should aim for roughly q2 − q3/2 in 2D when q is a square”), AlphaEvolve performed much better — showing expert guidance can unlock big progress.
- Meta-insights about how to use the tool:
- More parallel computing = faster results, but higher total cost.
- Bigger, smarter LLMs usually help, but mixing in cheaper models can add diversity and sometimes works well for the cost.
- Better “verifiers” (the scoring rules) matter a lot — if the rules are sloppy, the AI might “cheat” by exploiting loopholes instead of solving the real problem.
- Continuous scoring (smooth scores instead of all-or-nothing) often helps the search.
- Good prompts and expert tips significantly improve outcomes.
- Showing less data can improve generalization — giving small, clean examples can push the AI to discover deeper patterns rather than memorize.
- Training on families of related problems at once often leads to more general and powerful strategies.
Limitations:
- It doesn’t crack everything. Some problems were too hard or didn’t improve.
- Sometimes the search process becomes hard to interpret, even if the final object is clear.
- It works best on problems where you can “score” candidates smoothly and climb toward better solutions.
- Fully formal proofs are only sometimes possible (they depend on what is already in the proof libraries).
5) Why does this matter?
This work shows a new way for humans and AI to do mathematics together:
- The AI explores huge spaces of possibilities quickly and finds promising constructions.
- Humans (and other AI tools) can turn those into clean proofs and deeper understanding.
- This can save a lot of time on problems that are within reach but would take many hours of trial-and-error by hand.
- It suggests a future where:
- AI discovers candidates,
- another AI derives and explains the proof,
- and a proof assistant verifies it — making a full “discovery-to-proof” pipeline.
Big picture impact:
- A scalable tool for “constructive mathematics at scale”: building explicit examples that push the limits.
- A way to classify problem difficulty (some might be “AlphaEvolve-hard”).
- A blueprint for combining different AI systems with human insight to accelerate real mathematical discovery.
In short, AlphaEvolve doesn’t replace mathematicians. It acts like a powerful lab partner: it searches widely, finds patterns, and proposes constructions, while humans guide, interpret, and prove. Together, they can push the boundaries of what we know — faster and at larger scale than before.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a consolidated list of the main knowledge gaps, limitations, and open questions the paper leaves unresolved. Each item is phrased to be actionable for follow-up research.
- Lack of standardized benchmarks: no shared, publicly versioned suite of mathematical problems (with agreed scoring, compute budgets, and baselines) to enable fair, repeatable comparison across methods and labs.
- Reproducibility under randomness: limited guidance on seeds, run counts, and statistical reporting (e.g., mean/variance, confidence intervals) needed to make the stochastic outcomes verifiable and comparable.
- Incomplete ablation coverage: ablations focus on a single fast problem (autocorrelation) and two knobs (threads, LLM choice); no systematic study across diverse problem families, objective smoothness, dimensionality, or search-space size.
- Missing scaling laws: no quantitative characterization of how solution quality improves with LLM quality, number of calls, search time, population size, or parallelism across problem classes.
- Verifier robustness and “cheating”: no principled toolkit for designing verifiers that are provably robust against loopholes (e.g., discretization artifacts, approximate positivity), or for certifying absence of exploitability.
- Discretization/regularization bias: no analysis of the approximation error when infinite-dimensional problems are projected to finite-dimensional ones, nor guarantees that discovered constructions transfer to the continuous/infinite setting.
- Formalization bottlenecks: AlphaProof/Lean integration works only for “simple enough” proofs; no method to (i) automatically derive formal proofs from evolved programs, (ii) diagnose missing library lemmas, or (iii) prioritize library extensions to unblock formalization at scale.
- From constructions to general theorems: no pipeline to turn families of discovered instances into conjectures and then into universally quantified, machine-checked proofs (especially for universal upper bounds rather than existential constructions).
- Interpretability of evolved heuristics (search mode): evolved search procedures are often opaque; no technique to extract, simplify, and canonize the discovered algorithm into a human-readable strategy or closed-form formula.
- Generalizer mode reliability: risk of overfitting to the evaluated set of , , or ; no use of held-out parameter ranges or distributional tests to confirm true generalization before proof attempts.
- Dependence on expert prompting: performance heavily depends on subject-matter hints; no quantitative protocol to measure and reduce reliance on human expertise, or to automatically elicit/use minimal guidance.
- Model-mixing strategies: anecdotal gains from mixing cheaper and stronger LLMs are not formalized; no principled schedule for when to inject diversity, how to allocate calls across models, or how this interacts with search phases.
- Resource allocation and budgeting: no decision-theoretic framework for optimal allocation of compute across (threads × LLMs × run-length × restarts), given a fixed budget and target success probability.
- Problem class characterization: no theory predicting which mathematical problems are amenable to AlphaEvolve (beyond “hill-climbable” smooth scores), nor a formal definition and diagnostics for “AlphaEvolve-hard” inequalities.
- Convergence and sample complexity: no guarantees on convergence, runtime to near-optimal constructions, or bounds on the number of LLM calls required as a function of search-space complexity.
- Transfer and curriculum: evidence suggests benefits from training on related instances, but no systematic methodology for curriculum design, transfer learning, or reusable “building-block” heuristics across problem families.
- Multi-objective optimization: claims of optimizing multiple metrics are not backed by a Pareto-front method, trade-off controls, or diagnostics for stability under competing objectives.
- Verification-at-scale of discovered constructions: beyond spot-checking and occasional formalization, no automated, scalable verification pipeline (e.g., proof obligations generated from code, randomized testing with adversarial inputs).
- Cataloging failure modes: failures are reported qualitatively; no taxonomy and quantitative analysis of when and why the system fails (e.g., rugged landscapes, deceptive gradients, symmetry-induced plateaus).
- Search-space design: limited guidance on constructing mutation operators, representation choices (direct construction vs. heuristic search), and constraints that provably bias toward interpretable, generalizable programs.
- Data and “less is more” phenomenon: the observed benefit of limiting examples is anecdotal; no controlled experiments to determine when restricting context improves generalization and when it harms it.
- Novelty detection vs. rediscovery: no automated method to detect that a discovered construction is genuinely new relative to the literature, or to steer search away from known templates.
- Integration with symbolic tools: ad hoc use of Deep Think; no principled orchestration for when to hand off to theorem-provers/solvers, how to translate evolved code to symbolic representations, or how to iterate proofs back into improved search.
- Robustness to non-smooth/discrete objectives: acknowledged struggles with non-smooth or brittle objectives; no algorithmic remedies (e.g., surrogate modeling, adaptive smoothing, relaxations) presented or evaluated.
- Handling number-theoretic subtleties: for constructions invoking elliptic curves or residue classes (e.g., ), no framework to detect, explain, and generalize such arithmetic conditions automatically.
- Coverage across primes/prime powers: several results hold only for primes with specific congruence classes or perfect-square fields; no strategy to extend constructions to all or to non-square systematically.
- Lower-order term control: improvements often affect lower-order terms; no path to optimizing leading constants or proving asymptotic optimality in higher dimensions for Kakeya/Nikodym.
- Continuous-to-symbolic distillation: no method to convert large, heuristic codebases into compact closed forms (e.g., via program synthesis/symbolic regression) with provable equivalence.
- Evaluation against human baselines: no controlled studies comparing time-to-discovery and quality between AlphaEvolve-assisted workflows and expert-only workflows across matched problem sets.
- Noise handling in evaluation: if evolved heuristics are stochastic, the evaluator does not account for variance or confidence estimation; no protocol for repeated trials, statistical tests, or robust selection under noisy scores.
- Safety and sandboxing: evolving arbitrary code that calls external tools (e.g., SAT solvers) raises safety and determinism concerns; no standard sandboxing, dependency control, or reproducibility guarantees for heterogeneous toolchains.
- Library growth strategy for formalization: no prioritized roadmap for extending mathlib (or analogous libraries) specifically targeting the proof patterns emerging from AlphaEvolve outputs.
- Open Nikodym/Kakeya questions: no automated approach yet for approaching conjectured asymptotics (e.g., ) or for bridging the gap in non-perfect-square fields beyond lower-order improvements.
- Hyperparameter self-tuning: the paper proposes enabling AlphaEvolve to choose its own hyperparameters but offers no concrete meta-optimization mechanism (e.g., bandits, Bayesian optimization, or evolutionary meta-search).
- Benchmarking multi-stage pipelines: the discovery–proof–formalization pipeline is demonstrated case-by-case; no metrics or datasets to evaluate end-to-end success rates, time, and failure diagnoses across many problems.
Glossary
- Absolutely integrable: A function whose absolute value has a finite integral over its domain. "The convolution of two (absolutely integrable) functions is defined by the formula"
- Asymptotic formula: An expression describing the leading behavior of a quantity as parameters grow large. "we could not even cross-reference the asymptotic formula claimed by Deep Think with our actual computed numbers"
- Autocorrelations: Convolutions where one function is the original or its reflection, measuring self-similarity across shifts. "we informally refer to such convolutions as autocorrelations."
- Block designs: Structured combinatorial arrangements of elements into blocks with balanced incidence properties. "due to connections with block designs, the polynomial method in combinatorics"
- Blocking sets: Sets of points in a finite projective plane that intersect every line. "In contrast, from the theory of blocking sets, $C^N_{\ref{nikodym}(2,q)$ is known to be at least "
- Cartesian products: The product of sets forming higher-dimensional structures; closure under products preserves a class of objects. "The classes of Kakeya and Nikodym sets can both be checked to be closed under Cartesian products"
- Characteristic: The smallest positive number of times the field’s unit must be added to itself to yield zero; for finite fields, related to the prime p. "in the regime when goes to infinity while the characteristic stays bounded"
- Convolution: An operation integrating the product of one function with a shifted version of another. "The convolution of two (absolutely integrable) functions is defined by the formula"
- Discretization: Approximating an infinite-dimensional problem by a finite-dimensional one through sampling or grid-based restriction. "via discretization or regularization"
- Elliptic curves: Algebraic curves defined by cubic equations, with rich arithmetic structure and a group law. "Deep Think revealed a link to elliptic curves"
- Euclidean space: The standard geometric setting of real coordinate spaces with familiar notions of distance and direction. "a strong analogy with the Kakeya conjecture in other settings such as Euclidean space."
- Extremizers: Objects that achieve the optimal value in an inequality or variational problem. "often with an interpretable description of the extremizers"
- Finite field: A field with a finite number of elements, typically denoted . "Let be a finite field of order ."
- Fractional part: The non-integer part of a real number. "where is the fractional part of "
- Function space: A space whose elements are functions, often infinite-dimensional. "(e.g., a function space)"
- Functional inequalities: Inequalities involving functions and operators (e.g., convolution) with optimal constants. "obtaining sharp constants on various functional inequalities involving autocorrelations"
- Inclusion-exclusion: A combinatorial counting technique using alternating sums over intersections. "number theoretic inclusion-exclusion computations."
- Infimum: The greatest lower bound of a set of real numbers. "expressed as a supremum or infimum of some score function"
- Kakeya conjecture: A conjecture about the minimal size/dimension of sets containing a line (or segment) in every direction. "a strong analogy with the Kakeya conjecture in other settings such as Euclidean space."
- Kakeya set: A set that contains a line in every direction (here in finite field settings). "A Kakeya set is a set that contains a line in every direction"
- Lean proof assistant: A formal verification system used to create machine-checked mathematical proofs. "This proof was then fully formalized in the Lean proof assistant using another AI tool, AlphaProof"
- little‑o notation: Asymptotic notation indicating a term that becomes negligible compared to another as a parameter grows. "It is conjectured that $C^N_{\ref{nikodym}(d,q) = q^d - o(q^d)$"
- Nikodym set: A set where every point lies on a line that is contained in the set except possibly at that point. "A Nikodym set is a set with the property that every point in is contained in a line that is contained in ."
- Polynomial method: A combinatorial technique that employs properties of polynomials to bound or construct discrete structures. "the polynomial method in combinatorics"
- Prime power: An integer of the form for a prime p and integer k≥1. "let be a prime power."
- Projective transformation: A bijection in projective space preserving lines, often relating configurations like Kakeya/Nikodym sets. "a projective transformation of a Nikodym set is essentially a Kakeya set"
- Quadratic residues: Elements that are squares modulo a prime, including 0 when working over a finite field. "S is the set of quadratic residues (including $0$)."
- Regularization: Techniques to stabilize or constrain optimization or estimation, often by adding penalties or smoothing. "via discretization or regularization"
- Supremum: The least upper bound of a set of real numbers. "expressed as a supremum or infimum of some score function"
- Unions of lines: A geometric notion concerning sets formed by collecting lines; used in conjectural implications. "In three dimensions the conjecture would be implied by a further conjecture on unions of lines"
Practical Applications
Immediate Applications
The following applications can be deployed now, provided a clear, deterministic evaluator (fitness function) and reasonable compute are available. Each item notes sectors, potential tools/workflows, and key dependencies.
- Evolving domain-specific heuristics for hard combinatorial optimization
- Sectors: software, logistics/transportation, manufacturing, energy, finance
- Use cases:
- Vehicle routing, crew rostering, timetabling, bin packing, cutting/stock layout, warehouse slotting
- Power grid unit commitment and economic dispatch (heuristic warm starts or cut generation for MIPs)
- Portfolio construction under constraints (position limits, turnover), scenario generation for stress testing
- Compiler optimization sequences, autotuning, query-planning heuristics in databases
- Tools/workflows: integrate AlphaEvolve in “search mode” to evolve search heuristics that operate inside existing solvers; evaluate on rolling instance sets; keep the best heuristic chain as a production module
- Assumptions/dependencies: robust, non-cheatable evaluator; simulators/solvers available; out-of-sample validation to prevent overfitting; compute budget and parallelism; expert prompting to seed productive search
- Rapid algorithm-prototyping for SAT/CSP and metaheuristic design
- Sectors: EDA/semiconductors, verification, cybersecurity, planning/AI
- Use cases: evolve restart/branching policies, neighborhood moves, acceptance criteria, hybrid SAT/SMT tactics; test-guided fuzzer evolution
- Tools/workflows: plug AlphaEvolve into solver harnesses with time-limited evaluation; “improver” functions chained over generations
- Assumptions/dependencies: deterministic harness and precise score; careful guardrails to avoid “reward hacking” (e.g., cheating via harness bugs)
- Research copilot for mathematics and theoretical CS
- Sectors: academia, education, software (symbolic math/CAS)
- Use cases: construction search for extremal objects; generalizer mode to propose formulas from small-n patterns; automated pipeline to natural-language proofs (Deep Think) and formalization (AlphaProof/Lean)
- Tools/workflows: AlphaEvolve → Deep Think → AlphaProof; problem repositories with standardized evaluators
- Assumptions/dependencies: mathlib/library coverage for formalization; human-in-the-loop for proof scrutiny; reproducibility harness (seeds, logs)
- AutoML/AutoRL: evolving search strategies rather than just model hyperparameters
- Sectors: software/ML, robotics, finance (backtesting), marketing analytics
- Use cases: evolve training curricula, augmentation policies, exploration schedules, reward shaping; search pipelines for feature engineering
- Tools/workflows: treat the training/evaluation loop as the deterministic evaluator; constrain wall time per candidate; score on multiple metrics (e.g., generalization, stability)
- Assumptions/dependencies: fixed datasets/simulators; protection against data leakage; multi-objective scoring to avoid degenerate solutions
- Robotics and motion planning heuristics (offline discovery, online deployment)
- Sectors: robotics, autonomous vehicles, warehousing
- Use cases: evolve sampling/planning heuristics (RRT*, PRM biasing), waypoint seeds, cost shaping for complex environments
- Tools/workflows: simulator-backed evaluator; export learned heuristic policies for embedded runtime
- Assumptions/dependencies: high-fidelity simulation; safety validation; transfer gap mitigation from sim to real
- Software engineering productivity: test generation, fuzzing, performance tuning
- Sectors: software, cybersecurity
- Use cases: evolve targeted fuzzers to maximize coverage/crash discovery; generate microbenchmarks and parameter schedules for performance regression detection
- Tools/workflows: CI pipeline step that runs AlphaEvolve with a coverage/crash score; rolling corpus maintenance
- Assumptions/dependencies: sandboxed execution; deterministic scoring; guard against trivial exploits (e.g., injecting test oracles)
- Resource-budget planning for AI search workloads
- Sectors: cloud/HPC, MLOps
- Use cases: apply the paper’s meta-analysis (threads vs. cost, model choice) to pick cost-optimal parallelism and model mix
- Tools/workflows: budgeting dashboards; “LLM portfolio” scheduling (mixing cheap and strong models for diversity)
- Assumptions/dependencies: telemetry to measure time-to-target; support for multi-model sampling
- Educational tools for inquiry-driven math and CS
- Sectors: education
- Use cases: course labs where students design evaluators and watch evolved constructions; interactive notebooks that propose, test, and (optionally) prove claims
- Tools/workflows: classroom instances of AlphaEvolve with curated problem sets; auto-grading via deterministic evaluators
- Assumptions/dependencies: instructor-provided evaluators; compute quotas; academic honesty policies for AI assistance
- Open problem repositories and benchmarking
- Sectors: academia, open science
- Use cases: publish problem+evaluator suites for reproducible experimentation; track “AlphaEvolve-hard” labels to triage research investment
- Tools/workflows: GitHub repositories; leaderboards that log seeds, code, and proofs
- Assumptions/dependencies: community governance; evaluator transparency; versioning for reproducibility
Long-Term Applications
The following require further research, scaling, formal-methods maturity, or broader integration into critical workflows.
- Autonomous scientific discovery loops (experiment design → execution → theory → proof)
- Sectors: pharmaceuticals/biotech, materials science, chemistry, physics
- Use cases: evolve experimental protocols/hypotheses with in-silico evaluators; integrate symbolic reasoning to propose mechanisms; formal verification of derived models
- Tools/workflows: closed-loop lab automation with AlphaEvolve-like searchers, scientific LLMs, and formal verification of safety/constraints
- Assumptions/dependencies: reliable surrogate models; robotic labs; rigorous safety gates; data governance
- End-to-end “discover–prove–formalize–deploy” pipelines for safety-critical software
- Sectors: aerospace, automotive, medical devices, industrial control
- Use cases: evolve controller/monitor designs, auto-generate correctness arguments, and produce machine-checked proofs (Lean/Isabelle/Coq) before deployment
- Tools/workflows: AlphaEvolve + Deep Think + industrial formal methods; certification-ready artifacts
- Assumptions/dependencies: expanded proof libraries; certification body acceptance; robust connections between natural-language reasoning and formal proof objects
- Standardized evaluators and anti-cheating testbeds for AI optimization
- Sectors: AI safety, standards/policy
- Use cases: benchmarking frameworks that detect reward hacking and verifier leakage; stress-tested evaluators for RL/LLM agents
- Tools/workflows: public suites with adversarial evaluator audits; certification marks for “robust evaluators”
- Assumptions/dependencies: consensus on robustness criteria; community red-teaming; regulatory interest
- General-purpose Heuristic Forge platforms (“AlphaEvolve-as-a-Service”)
- Sectors: cloud platforms, enterprise software
- Use cases: pluggable evaluators, multi-model LLM portfolios, scalable evolutionary orchestration, and artifact management for evolving heuristics across domains
- Tools/workflows: managed service with SDKs; policy controls (cost caps, safety checks); provenance and audit logging
- Assumptions/dependencies: cost efficiency; IP/licensing clarity for generated code; enterprise security
- Curriculum-level education transformation with AI-led research studios
- Sectors: education
- Use cases: students tackle open problems with AI partners; auto-assessment via proofs or counterexamples; living repositories of constructions and conjectures
- Tools/workflows: institution-scale compute pools; archived research trails; peer review aided by formal verification
- Assumptions/dependencies: equitable access; academic policies; faculty development
- Sector-specific “generalizer mode” deployment for parameterized problem families
- Sectors: manufacturing, energy, logistics, telecom
- Use cases: one program generalizes across plant sizes, grid topologies, fleet sizes, or network scales; low-maintenance deployment across changing operational regimes
- Tools/workflows: training on curated instance families; continuous evaluation and rollback; drift detection
- Assumptions/dependencies: representative training instances; monitoring for regime shifts; safe fallback strategies
- Formal-proof–backed compliance and policy automation
- Sectors: finance, privacy/legal tech, government
- Use cases: evolve policies/controls to satisfy regulatory constraints; produce machine-checked proofs of compliance against formalized regulations
- Tools/workflows: formal specification of rules; proof-carrying controls; automated audits
- Assumptions/dependencies: formalization of regulations; regulator buy-in; interpretability requirements
- Embedded/edge deployment of evolved planners in autonomous systems
- Sectors: robotics, drones, AVs, IoT
- Use cases: compress evolved heuristic chains into lightweight policies; provide bounded-time improvable planning on-device
- Tools/workflows: distillation/compilation pipelines; safety envelopes; online verification
- Assumptions/dependencies: real-time constraints; certification; runtime monitoring
- Research policy and funding triage via “AlphaEvolve-hardness” classifications
- Sectors: science policy, research management
- Use cases: prioritize problems amenable to computational exploration; identify topics demanding new theory vs. scalable computation
- Tools/workflows: public dashboards tagging problems; meta-analytics on compute vs. progress
- Assumptions/dependencies: community validation of labels; safeguards against metric gaming
- Cross-domain knowledge transfer via evolved algorithmic motifs
- Sectors: software, operations, data science
- Use cases: motifs discovered in one domain (e.g., arithmetic Kakeya constructions, packing heuristics) inspire new methods in others (e.g., sampling strategies, constructive relaxations)
- Tools/workflows: pattern libraries; motif-search over code representations
- Assumptions/dependencies: curated artifact sharing; IP/citation norms; interpretability to facilitate transfer
Notes on feasibility across all applications:
- Success depends strongly on evaluator design (continuous scores often help) and expert prompting; the paper shows large gains from small, well-placed hints.
- Mixing strong and cheap LLMs can balance diversity and cost, but high-end models generally improve quality on harder tasks.
- Formal verification is bottlenecked by library coverage; many proofs still need human review.
- Reproducibility requires logging seeds, prompts, and artifacts; evolutionary randomness otherwise complicates replication.
- Guard against “cheating” by hardening evaluators (no leaky approximations, sandboxed execution, adversarial tests).
Collections
Sign up for free to add this paper to one or more collections.