Published 5 Nov 2025 in cs.LG, cs.CV, cs.IT, math.IT, math.ST, stat.ML, and stat.TH | (2511.03256v1)
Abstract: Entropy Minimization (EM) is beneficial to reducing class overlap, bridging domain gap, and restricting uncertainty for various tasks in machine learning, yet its potential is limited. To study the internal mechanism of EM, we reformulate and decouple the classical EM into two parts with opposite effects: cluster aggregation driving factor (CADF) rewards dominant classes and prompts a peaked output distribution, while gradient mitigation calibrator (GMC) penalizes high-confidence classes based on predicted probabilities. Furthermore, we reveal the limitations of classical EM caused by its coupled formulation: 1) reward collapse impedes the contribution of high-certainty samples in the learning process, and 2) easy-class bias induces misalignment between output distribution and label distribution. To address these issues, we propose Adaptive Decoupled Entropy Minimization (AdaDEM), which normalizes the reward brought from CADF and employs a marginal entropy calibrator (MEC) to replace GMC. AdaDEM outperforms DEM*, an upper-bound variant of classical EM, and achieves superior performance across various imperfectly supervised learning tasks in noisy and dynamic environments.
The paper decouples classical entropy minimization into CADF and GMC, addressing reward collapse and easy-class bias in deep neural networks.
It introduces AdaDEM, which normalizes CADF using the L1-norm and employs a dynamic marginal entropy calibrator to eliminate hyperparameter tuning.
Empirical results demonstrate AdaDEM’s superior performance in test-time adaptation, semi-supervised learning, unsupervised domain adaptation, and reinforcement learning.
Decoupled Entropy Minimization: Theory, Algorithms, and Empirical Analysis
Introduction and Motivation
Entropy Minimization (EM) is a foundational self-supervised learning principle, widely adopted for reducing class overlap, bridging domain gaps, and calibrating uncertainty in deep neural networks (DNNs). Despite its broad utility in clustering, semi-supervised learning (SSL), unsupervised domain adaptation (UDA), and test-time adaptation (TTA), classical EM exhibits inherent limitations that restrict its effectiveness. This work rigorously reformulates EM, decoupling it into two distinct components: the Cluster Aggregation Driving Factor (CADF) and the Gradient Mitigation Calibrator (GMC). The analysis reveals two critical failure modes—reward collapse and easy-class bias—arising from the coupled formulation, and introduces Adaptive Decoupled Entropy Minimization (AdaDEM) to address these issues without hyperparameter tuning.
Theoretical Reformulation of Entropy Minimization
Classical EM minimizes the conditional entropy of model predictions:
H(z)=−i=1∑Cpi(z)logpi(z)
where pi(z) is the softmax probability for class i given logits z. The authors decouple this into:
H(z)=CADF−i=1∑Cpi(z)zi+GMClogi=1∑Cezi
CADF rewards dominant classes, promoting peaked output distributions, while GMC penalizes high-confidence predictions, regularizing the optimization. The partial derivatives with respect to logits reveal that CADF amplifies rewards for high-probability classes, whereas GMC imposes penalties proportional to confidence.
Limitations of Classical EM
Two major limitations are identified:
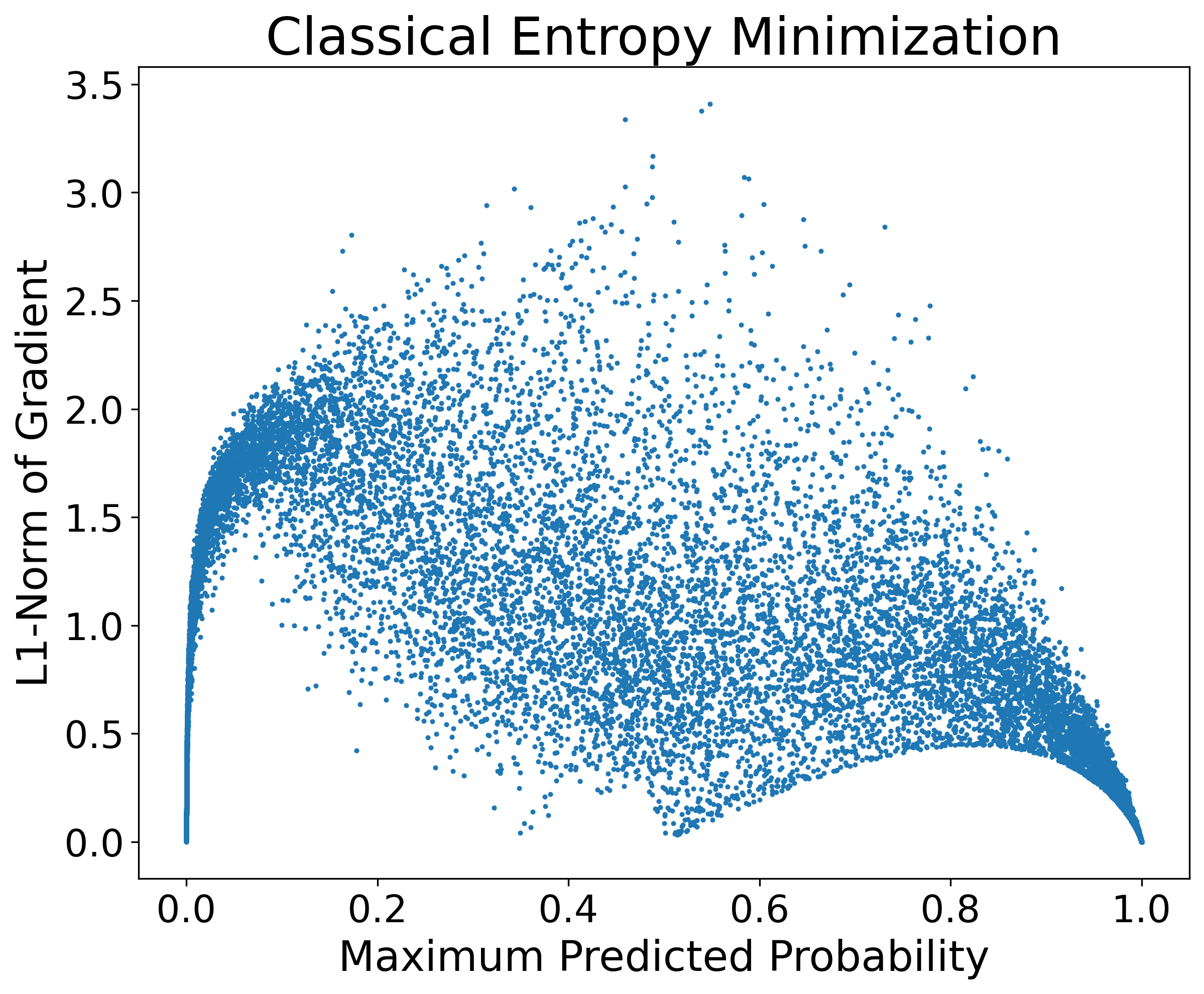
Reward Collapse: As predicted probabilities approach 1.0, the gradient magnitude for high-certainty samples collapses to zero, impeding their contribution to learning.
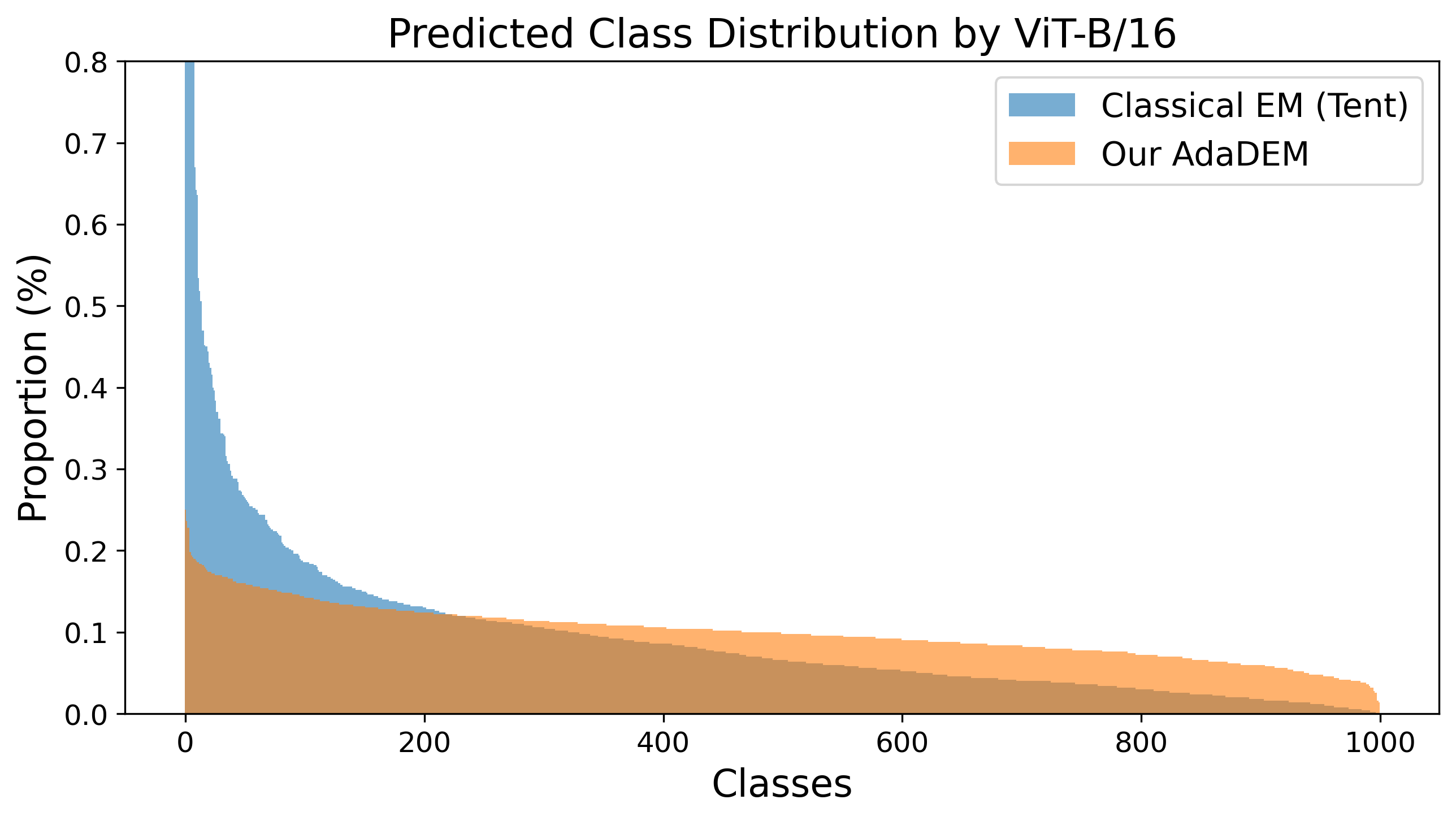
Easy-Class Bias: The model systematically favors dominant/easy classes, misaligning output and true label distributions, especially under noise or imbalance.
Figure 1: (Left) Reward collapse in classical EM; (Right) Easy-class bias in output distributions after adaptation.
Decoupled Entropy Minimization (DEM) and Hyperparameterization
To mitigate these issues, DEM introduces temperature τ to soften CADF and weight α to scale GMC:
H(z)=−i=1∑Cpτi(z)zi+αlogi=1∑Cezi
where pτi(z) is the softmax with temperature τ. DEM* searches for optimal (τ∗,α∗) via TPE, establishing an upper bound for classical EM performance.
Figure 2: (Left) Reward curves for varying τ; (Center) Correlation between optimal τ and average predicted probability; (Right) TTA results across domains.
Figure 3: (Left) Reward curves for varying α; (Center) Effects of α on static/dynamic shifts; (Right) TTA results for optimal α.
Adaptive Decoupled Entropy Minimization (AdaDEM)
AdaDEM eliminates hyperparameter tuning by:
Normalizing CADF Rewards: Uses the L1-norm of CADF gradients (δ) to normalize sample contributions, directly addressing reward collapse.
Marginal Entropy Calibrator (MEC): Replaces GMC with a dynamically estimated marginal entropy, penalizing dominant/easy classes without requiring label priors.
H(z)=−δ1i=1∑C(pi(z)−pkit)zi
where pkit is the moving average of marginal class probabilities.
Empirical Evaluation
AdaDEM and DEM* are evaluated on TTA, SSL, UDA, and RL tasks, consistently outperforming classical EM and prior SOTA methods.
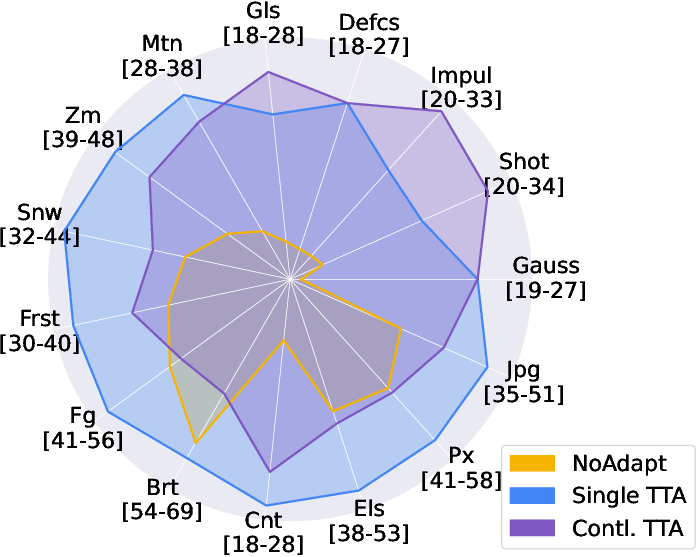
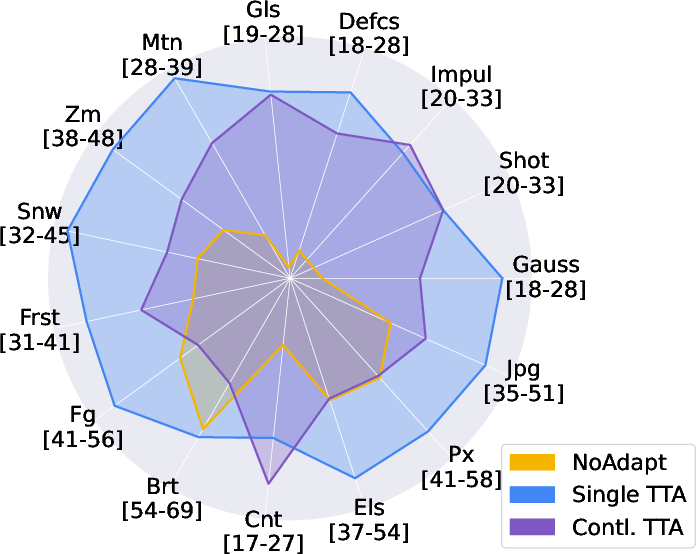
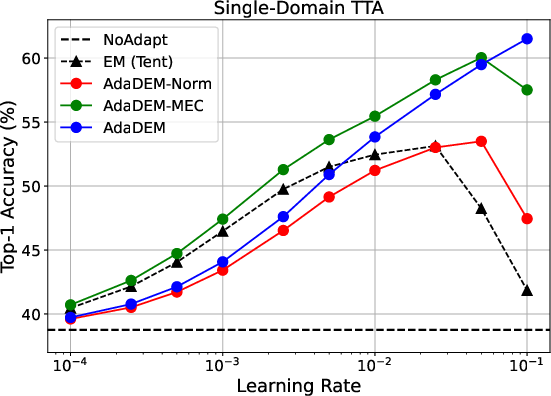
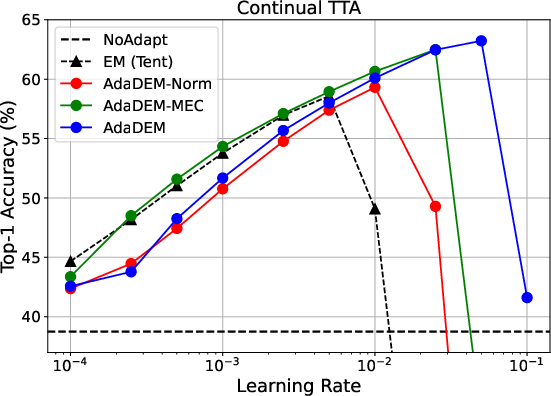
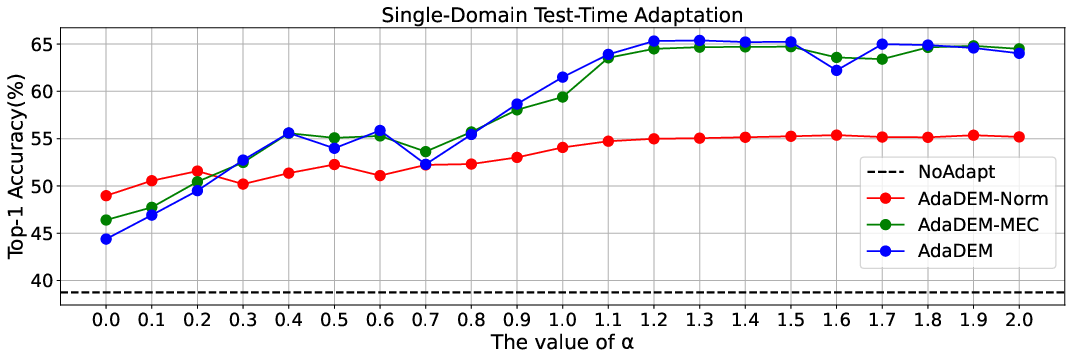
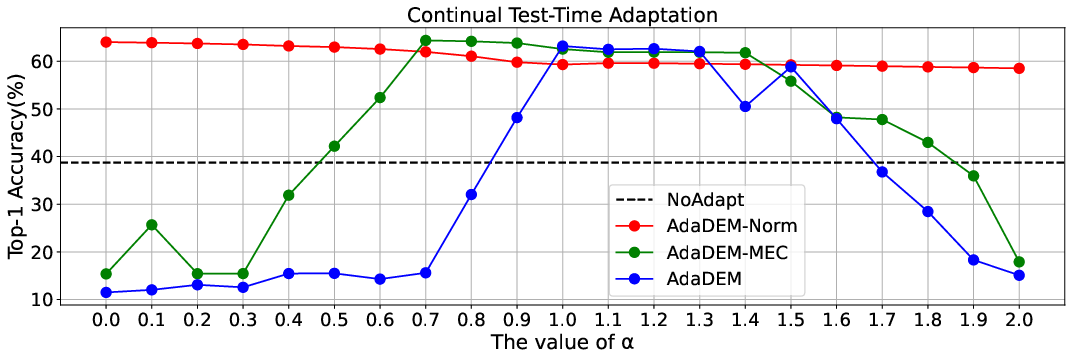
Figure 4: (Left) Ablation studies for single-domain and continual TTA; (Right) AdaDEM exhibits 10x expanded learning rate tolerance compared to classical EM.
Test-Time Adaptation
AdaDEM yields substantial gains in both single-domain and continual TTA, improving robustness to distribution shifts and reducing catastrophic forgetting.
Semi-Supervised Learning
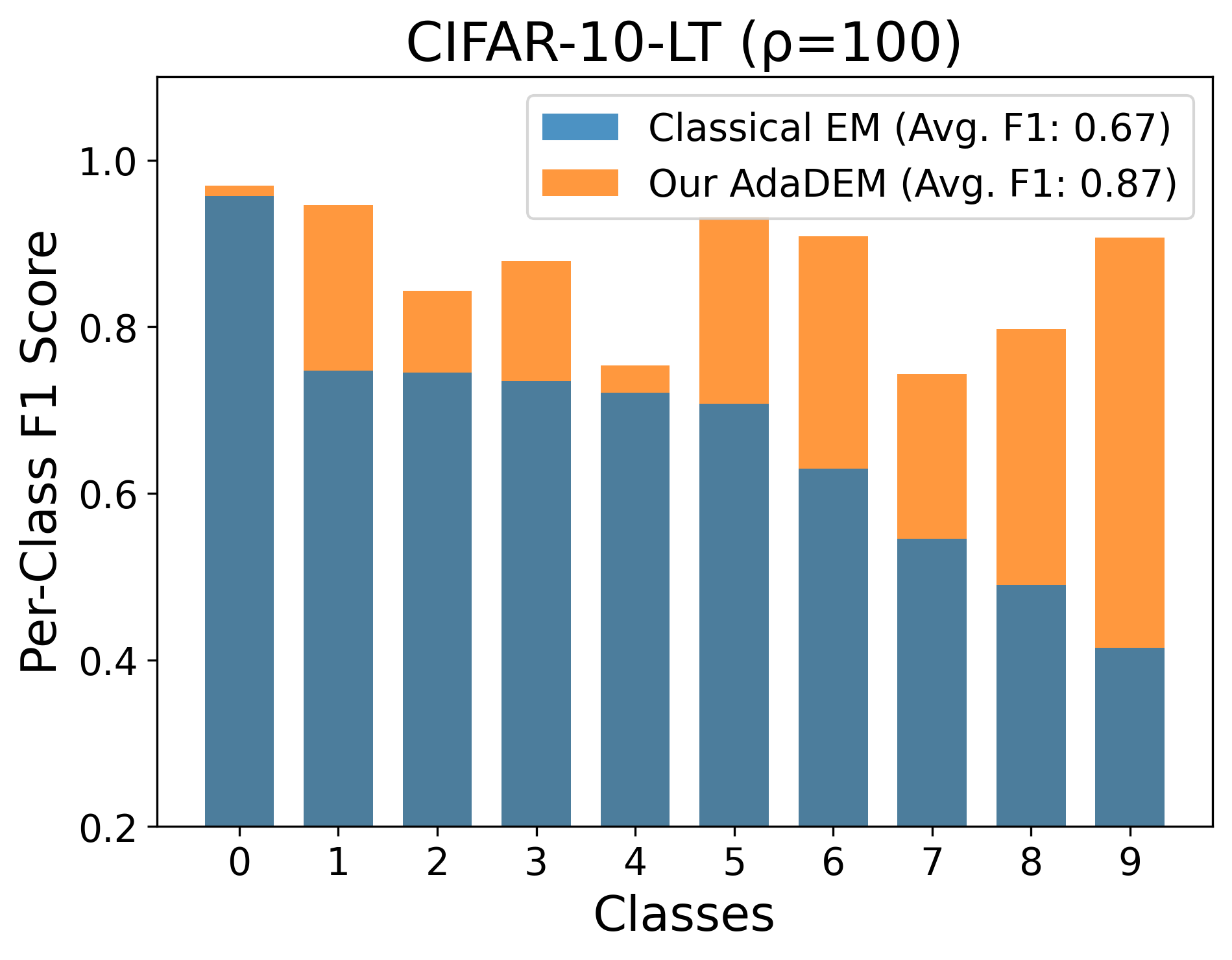
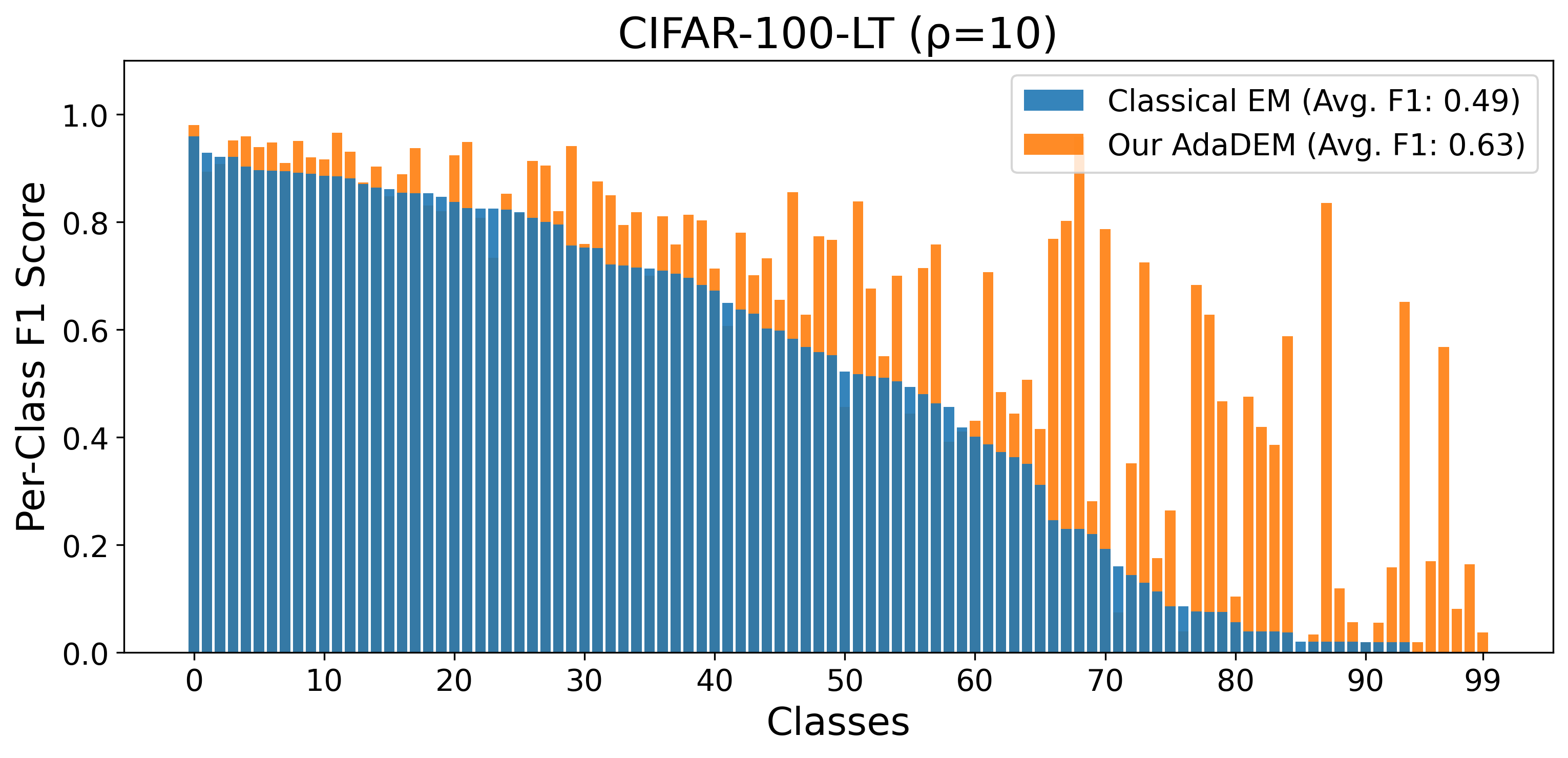
AdaDEM enhances performance across SSL benchmarks, especially under severe class imbalance, outperforming classical EM and improving existing SSL algorithms when integrated.
Figure 5: AdaDEM improves per-class and average F1 scores on class-imbalanced benchmarks.
Unsupervised Domain Adaptation
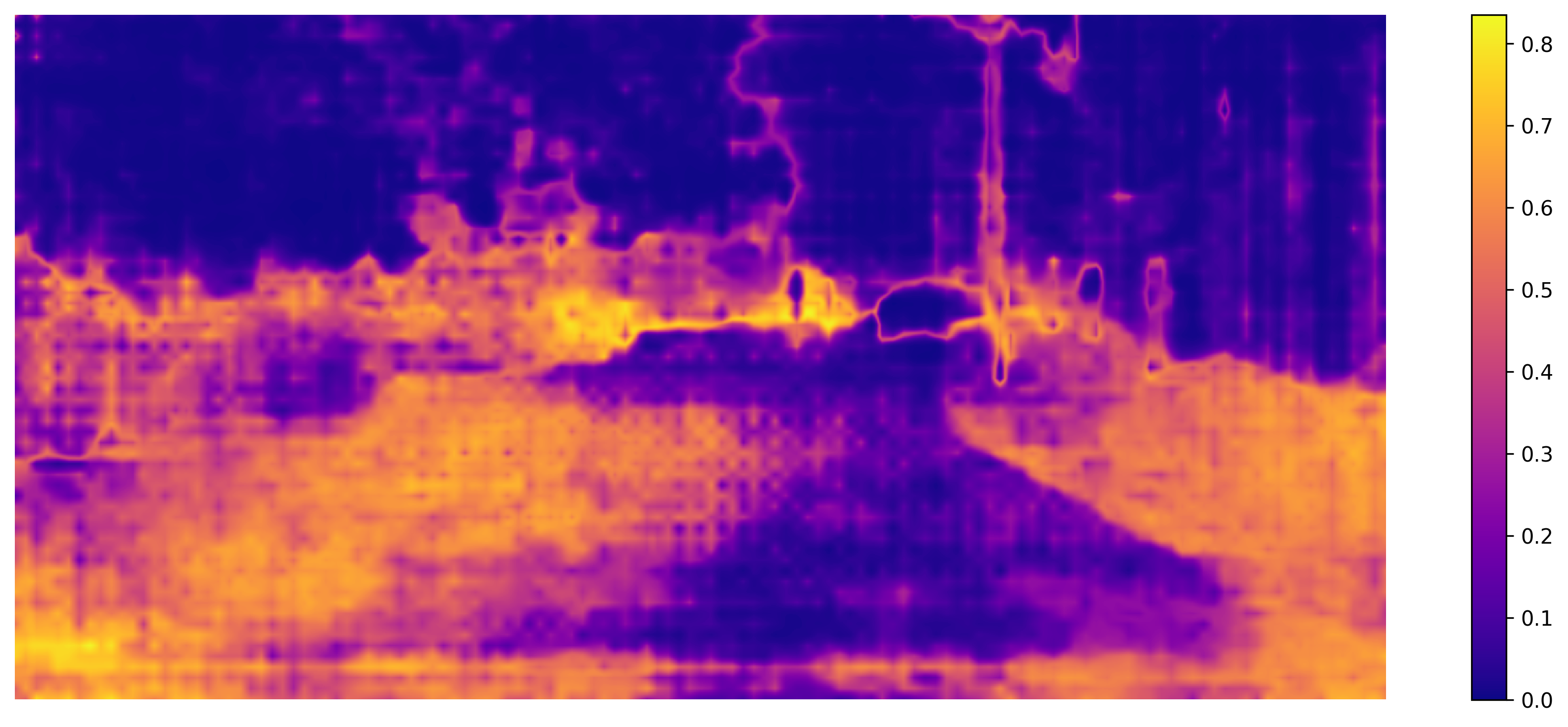
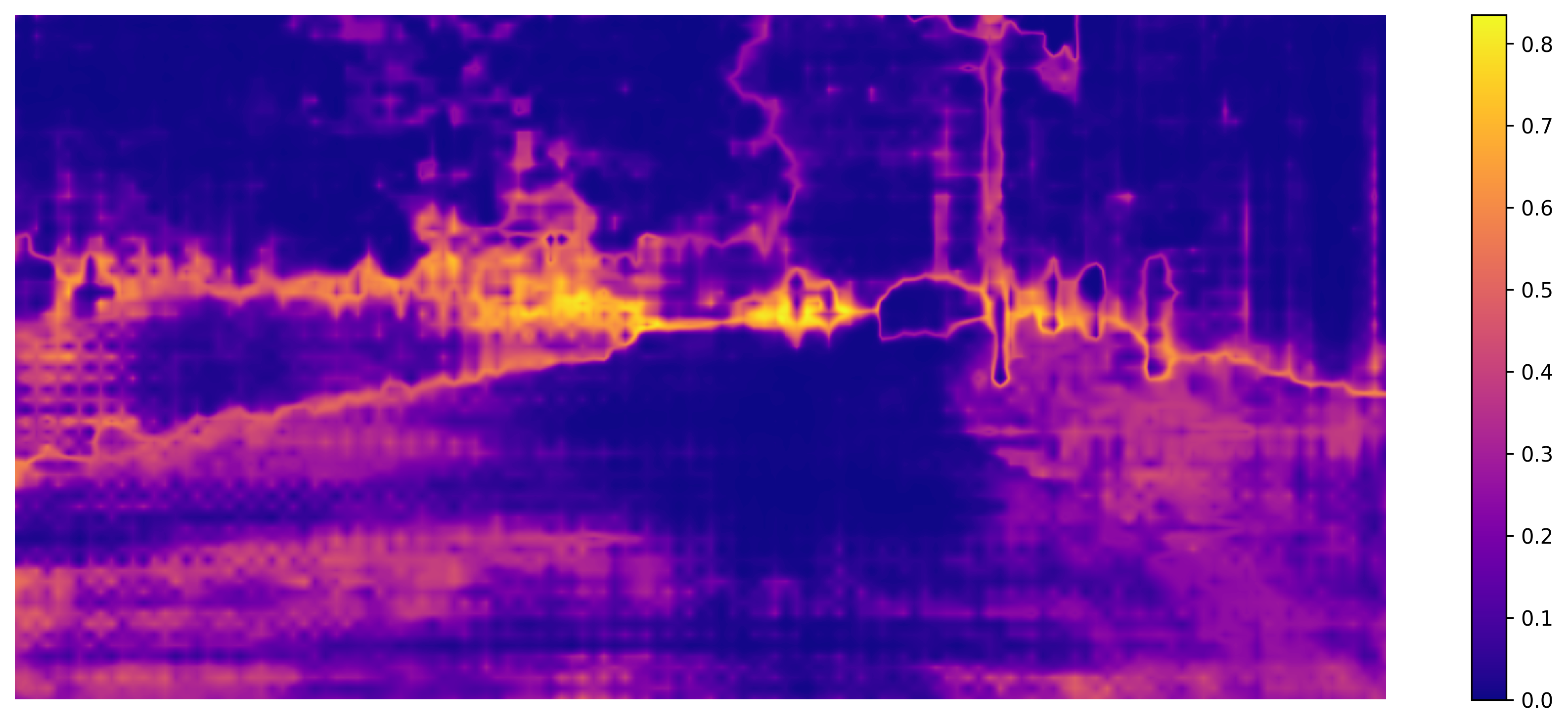
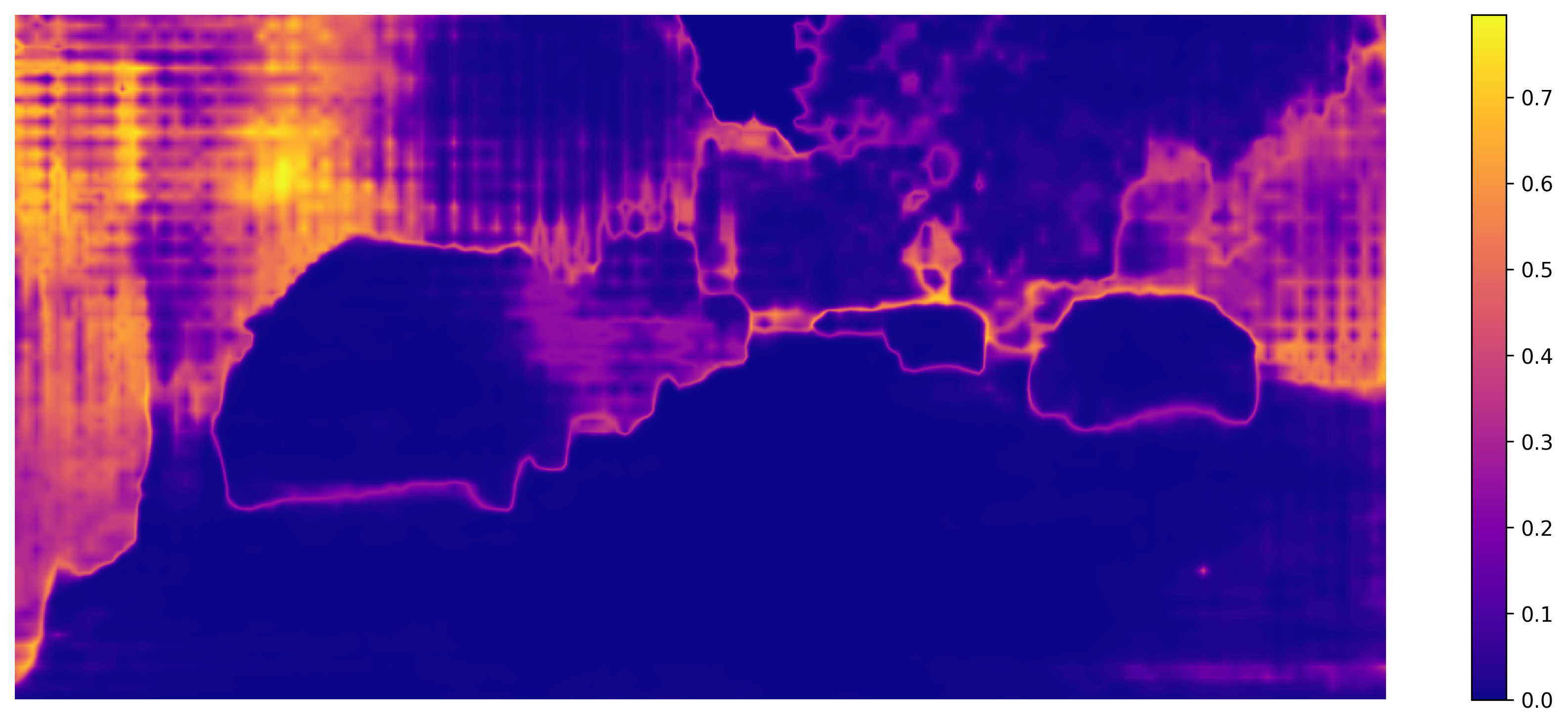
AdaDEM bridges domain gaps more effectively, improving mIoU in semantic segmentation and yielding sharper object boundaries.
Figure 6: AdaDEM reduces pixel entropy and sharpens segmentation boundaries compared to baselines.
Reinforcement Learning
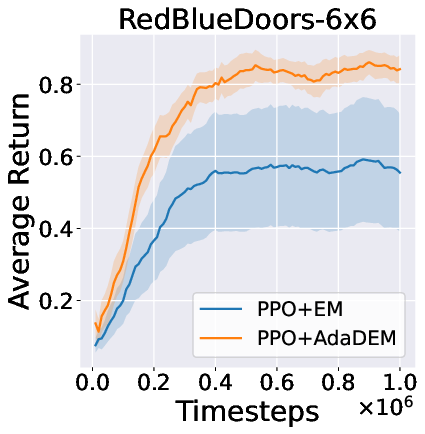
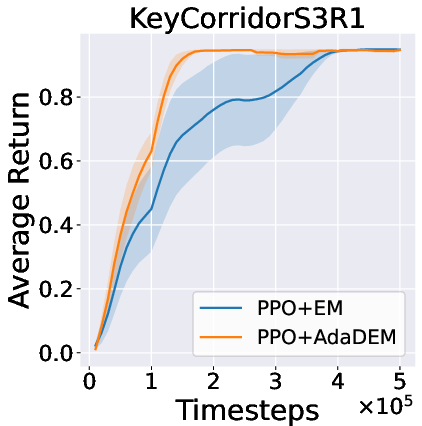
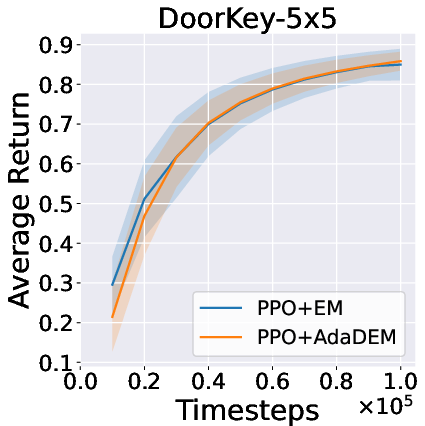
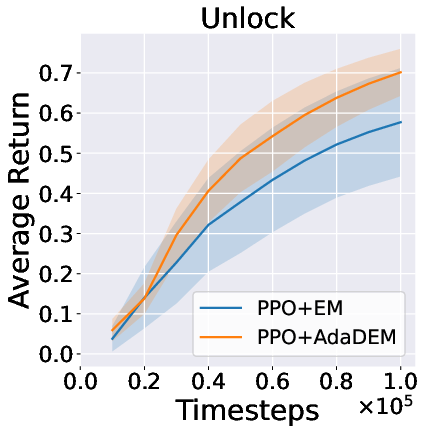
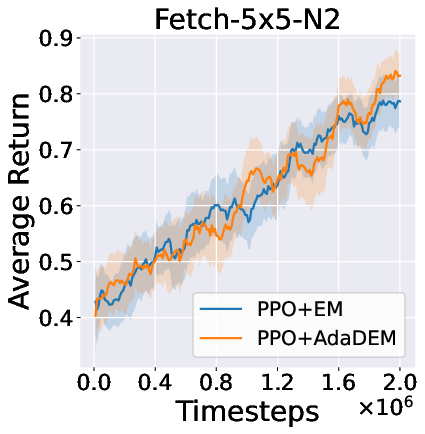
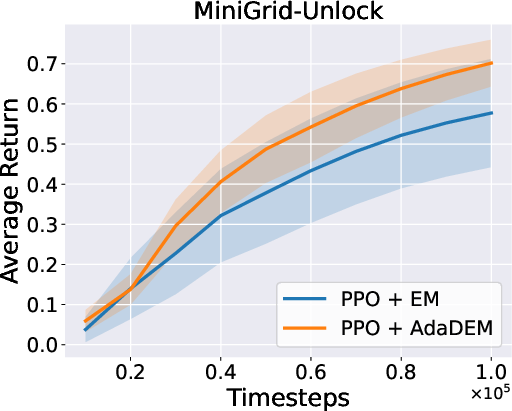
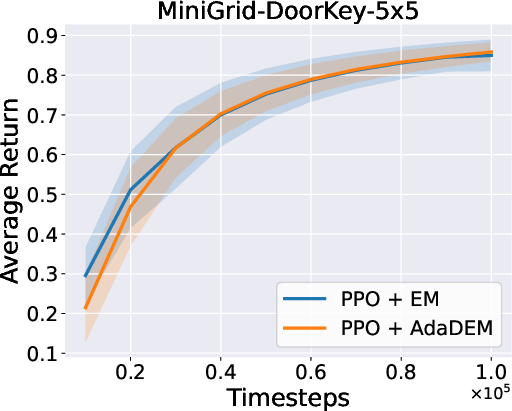
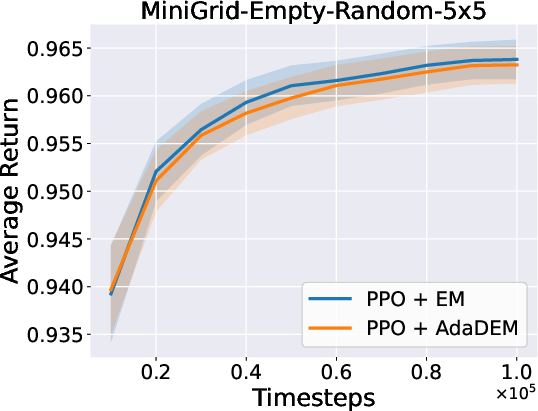
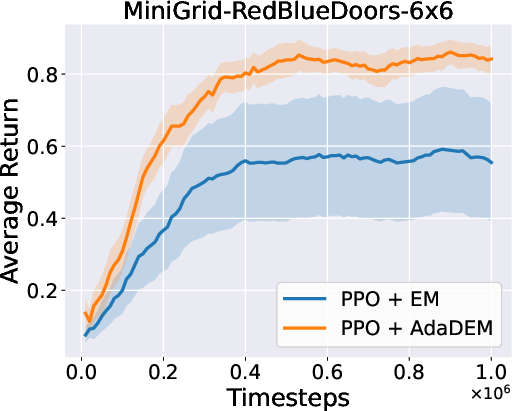
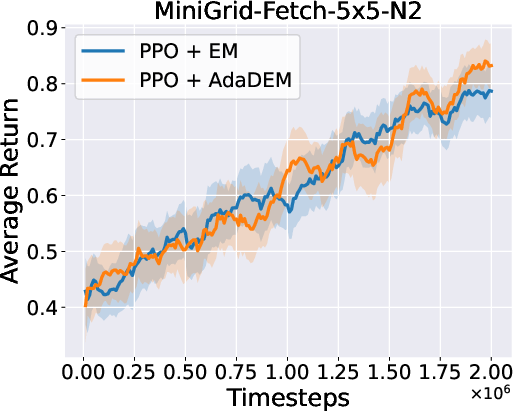
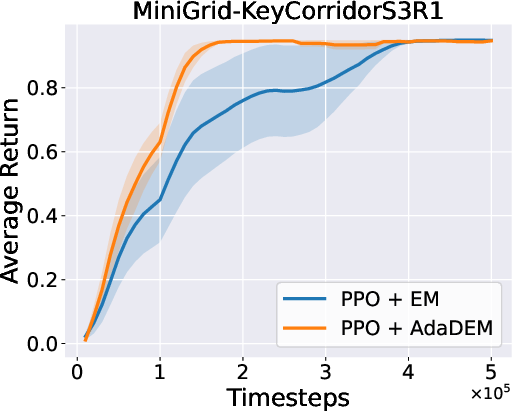
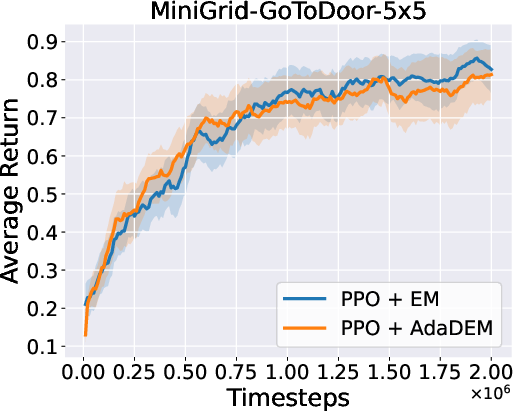
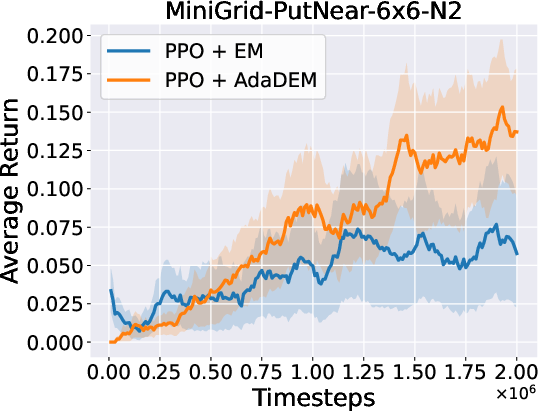
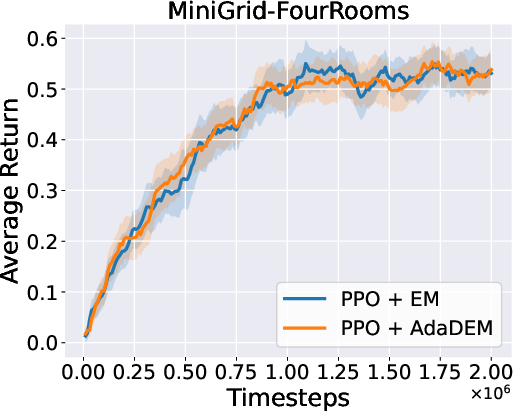
AdaDEM is compatible with entropy maximization strategies in RL, maintaining or improving average returns in Minigrid environments.
Figure 7: AdaDEM improves RL performance across Minigrid tasks.
Figure 8: Average return curves for AdaDEM and baselines in Minigrid environments.
Ablation and Sensitivity Analyses
AdaDEM demonstrates reduced sensitivity to optimizer choice and learning rate, robustly handling noisy, imbalanced, and dynamic environments.
Figure 9: AdaDEM and its variants show reduced learning rate sensitivity compared to classical EM.
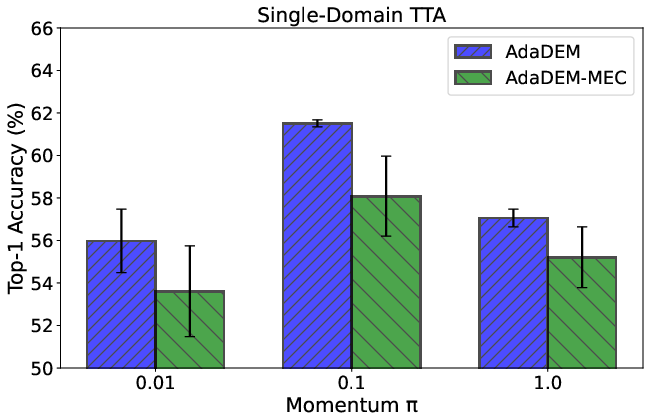
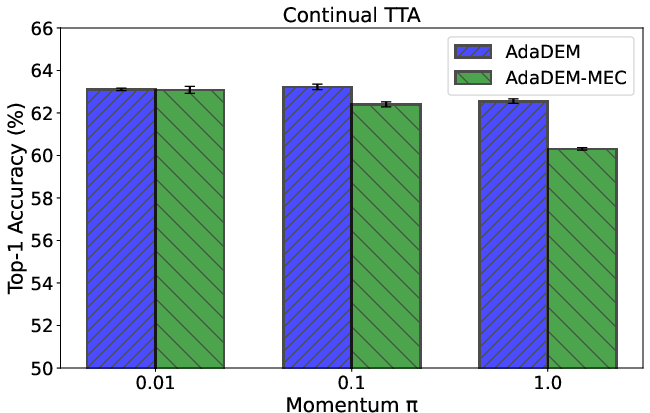
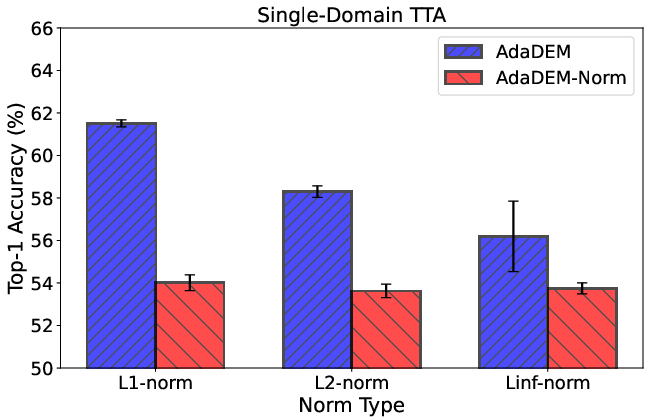
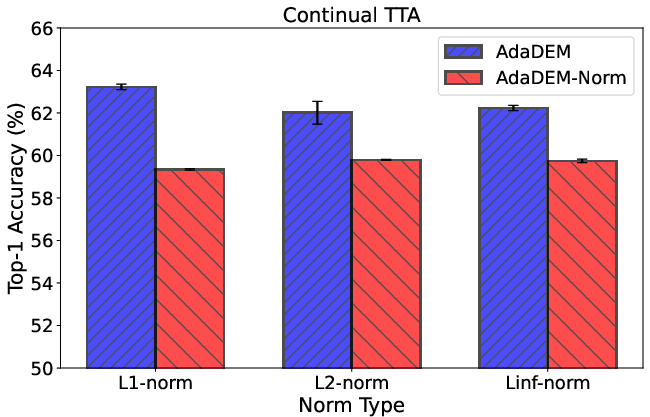
Ablation studies confirm the necessity of L1-norm normalization and dynamic marginal entropy estimation. Additional scaling of MEC and alternative norm types are explored, with L1-norm providing optimal stability.
Figure 10: Ablation of α scaling for MEC in AdaDEM.
Figure 11: Ablation of momentum parameter π for prior label distribution estimation in MEC.
Figure 12: Ablation of different norm types for CADF reward normalization.
Implementation Details
AdaDEM and DEM* are implemented as drop-in replacements for classical EM in existing frameworks. Pseudocode is provided for PyTorch-style integration, and hyperparameter search for DEM* is automated via TPE. AdaDEM requires no labeled data or hyperparameter tuning, strictly adhering to unsupervised learning paradigms.
Implications and Future Directions
The decoupling of EM into CADF and GMC provides a principled framework for analyzing and improving self-supervised objectives. AdaDEM's plug-and-play design enables robust adaptation in real-world, imperfectly supervised scenarios, including online learning, domain adaptation, and RL. The elimination of hyperparameter tuning and improved stability are particularly relevant for deployment in dynamic and resource-constrained environments.
Theoretically, the work motivates further exploration of disentangled self-supervised objectives and dynamic regularization strategies. Practically, AdaDEM's robustness to distribution shift and class imbalance suggests utility in federated, continual, and open-world learning settings.
Conclusion
Decoupled Entropy Minimization offers a rigorous theoretical and empirical advancement over classical EM, addressing reward collapse and easy-class bias through principled reformulation and adaptive normalization. AdaDEM achieves superior performance across diverse machine learning tasks, with strong robustness and practical deployability. While the approach does not resolve all challenges in self-supervised learning, it establishes a solid foundation for future research in adaptive, imperfectly supervised systems.