- The paper introduces Constraint-Projected Learning (CPL), a framework that projects neural network outputs onto constraint sets to enforce conservation, entropy, and shock conditions.
- It employs differentiable projection operators that integrate seamlessly with backpropagation, achieving near-zero violations as validated on Burgers’ equation with minimal performance overhead.
- Combining Total-Variation Damping (TVD) with a rollout curriculum, the method stabilizes long-horizon predictions, ensuring physically consistent and accurate neural PDE solutions.
Constraint-Projected Neural PDE Solvers: Eliminating Hallucinations via Law-Constrained Optimization
Introduction
The paper introduces Constraint-Projected Learning (CPL), a framework for training neural PDE solvers that strictly enforces physical laws at every update, thereby eliminating both hard and soft hallucinations. Hallucinations in neural solvers manifest as violations of conservation, entropy, or admissibility, leading to physically implausible predictions even when statistical accuracy is high. CPL addresses this by projecting network outputs onto the intersection of constraint sets defined by conservation, Rankine–Hugoniot (RH) balance, entropy, and positivity, ensuring that every prediction is physically admissible. The projection is differentiable and computationally efficient, adding only ~10% overhead, and is compatible with standard backpropagation.
CPL reframes the optimization landscape by restricting updates to the lawful manifold C, defined as the intersection of all constraint sets. The update rule is:
θk+1=ΠC(θk−η∇θL)
where ΠC is the projection operator. This geometric approach ensures non-expansiveness and stability, as projections onto convex (or locally convex) sets cannot amplify errors. Each constraint—finite-volume conservation, RH balance, entropy admissibility, positivity, and divergence-free structure—is implemented as a differentiable projector, allowing seamless integration with gradient-based learning.
Discretization: From Differential Laws to Finite Constraints
Physical laws are translated from strong (differential) form to weak (integral) form, enabling enforcement over finite regions rather than pointwise. The domain is discretized into control volumes, and conservation is enforced via finite-volume residuals:
Rin=ΔtUˉin+1−Uˉin+∣Ci∣1f∈∂Ci∑∣f∣Φi,fn−Sˉin
where Φi,fn is the numerical flux. Local conservation implies global conservation due to the telescoping property of fluxes.
Shock and Entropy Constraints
Rankine–Hugoniot Condition
Shocks are enforced via the RH jump condition:
[[F(U)⋅n]]=sn[[U]]
This is implemented as a penalty on the mismatch at detected shock interfaces, ensuring correct propagation and steepness of discontinuities.
Entropy Admissibility
The entropy constraint selects the physically valid weak solution:
∂tη(U)+∇⋅q(U)≤0
Discretized as a cell-wise penalty on positive entropy residuals, this ensures thermodynamic consistency.
Stability Constraints: Positivity and Total-Variation Damping
Positivity is enforced via clamping or softplus transformations, preventing negative densities or pressures. Total-Variation Damping (TVD) penalizes increases in spatial roughness:
LTVD=⟨max(0,TV(Un+1)−TV(Un))⟩
This suppresses non-physical oscillations without blurring genuine shocks.
Divergence-Free Projection
For incompressible or magnetically balanced systems, the Helmholtz projection ensures divergence-free fields:
v⊥=Pv,P=I−∇Δ−1∇⋅
This is implemented via FFT or multigrid solvers and is 1-Lipschitz, preserving stability.
Implementation: Training Loop and Diagnostics
The training loop integrates all constraints:
- Forward pass: U=net(x,t)
- Compute residuals for conservation, RH, entropy, TVD, and bounds.
- Assemble total loss with adaptive weights.
- Gradient update.
- Sequential projection through all constraint operators.
Reliability is measured via mass/energy drift, entropy violations, shock alignment, TVD growth, and bound violations, summarized in a Physics Violation Score (PVS).
Berger-Limited Reconstruction and Empirical Results
The Berger limiter is used for shock sharpening, selectively steepening discontinuities while maintaining monotonicity and admissibility. On Burgers’ equation (ν=0.01, N=128), CPL alone achieves:
- MSECPL=1.31×10−6
- MAECPL=4.2×10−4
- ∣Mass drift∣≈4.8×10−10
- ⟨ERH⟩≈4.4×10−10
Berger activates in 19% of cells, steepening shocks with negligible impact on conservation or entropy errors.
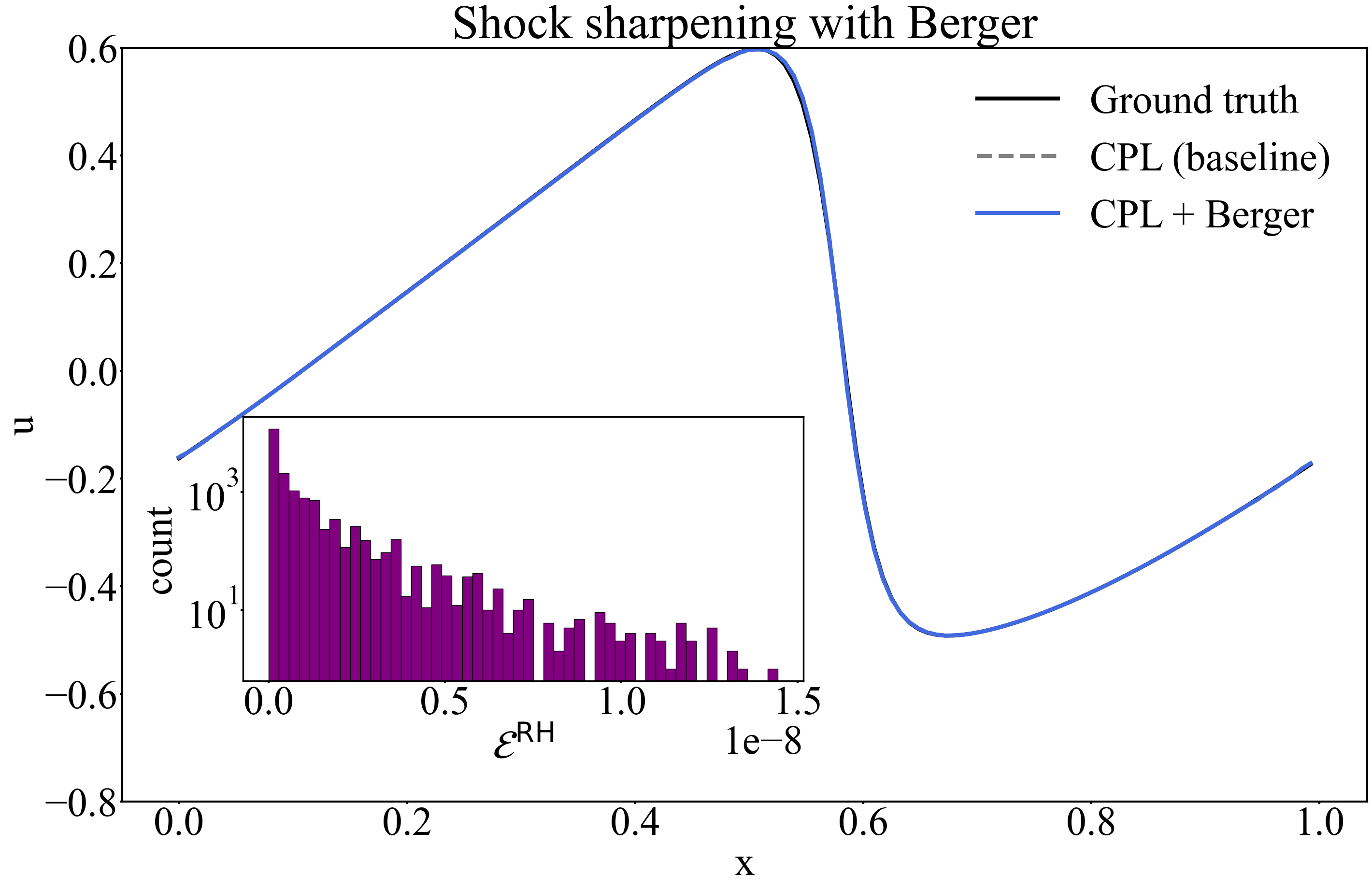
Figure 1: The Berger limiter steepens the shock front, matching the reference solution while conserving fluxes and maintaining entropy admissibility.
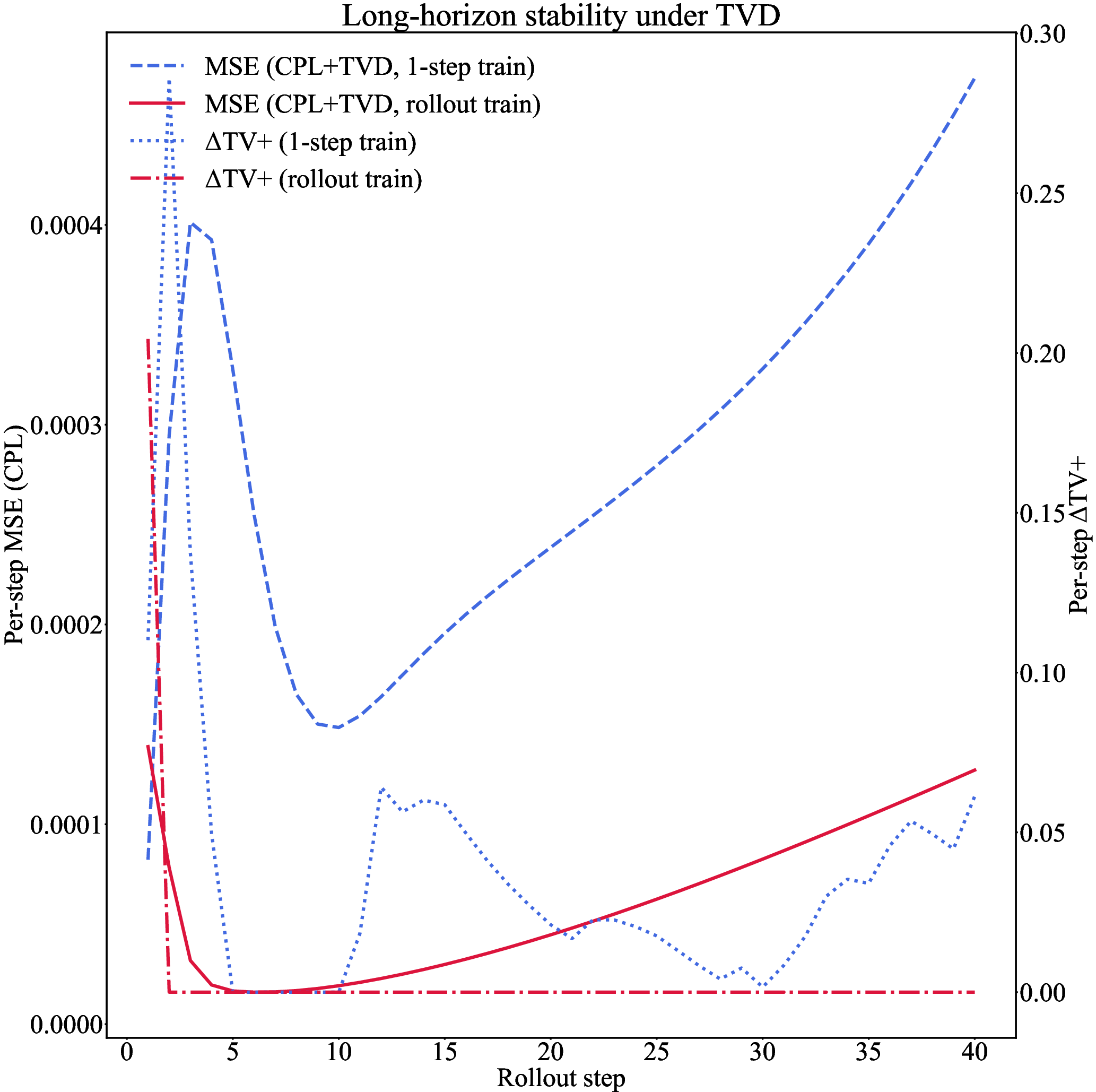
Long-Horizon Stability via TVD and Rollout Curriculum
TVD suppresses the accumulation of small-scale oscillations over long rollouts. Training with a rollout curriculum (increasing prediction steps R) further stabilizes the solution:
Quantitative Suppression of Hallucinations
CPL+TVD eliminates hard violations (mass, RH, negative densities) to machine precision and suppresses soft violations (entropy, roughness) to negligible levels. The fraction of cells with positive entropy residuals is $0.23$–$0.31$, with small mean magnitude (∼10−3–10−2). The projection step ensures that raw outputs are immediately corrected, preventing the amplification of deviations.
Universality and Scalability
The CPL mechanism is universal for any constraint expressible as a projection. TVD is agnostic to the underlying PDE. Performance constants depend on the geometry of the constraint sets, but the learning principle is portable across domains. Extension to multi-dimensional Euler, MHD, or reactive flows requires only appropriate projectors (e.g., HLLC fluxes, entropy pairs).
Conclusion
Constraint-Projected Learning, combined with TVD and rollout curriculum, yields neural PDE solvers that are accurate, stable, and physically consistent over long horizons. CPL enforces conservation and admissibility by construction, TVD suppresses non-physical roughness, and rollout training imparts temporal discipline. Empirical results on Burgers’ equation demonstrate near-zero violation of physical laws and bounded error over extended rollouts. The framework is extensible to higher-dimensional and more complex systems, contingent on the availability of differentiable projectors. Future work will focus on efficient projection solvers and adaptive TVD for stiff or multiscale problems.
The approach demonstrates that neural solvers can be trained to respect physical laws indefinitely, transforming scientific machine learning from data-driven regression to law-constrained evolution.