- The paper introduces a compact 3D-CNN architecture that leverages focal loss and targeted data augmentation to achieve 94.17% accuracy and a robust F1-score in event-based HAR.
- The paper demonstrates enhanced privacy by processing only intensity changes with event-based sensors, thereby minimizing the capture of identifiable personal information.
- The paper shows improved efficiency and generalization over traditional 3D-CNN baselines, making it suitable for edge deployment in practical applications.
Lightweight 3D-CNN for Event-Based Human Action Recognition with Privacy-Preserving Potential
Introduction
This paper introduces a compact 3D convolutional neural network (3D-CNN) tailored for human action recognition (HAR) using event-based vision data. The motivation stems from the privacy limitations of conventional frame-based cameras, which capture identifiable personal information, and the computational demands of deep HAR models. Event cameras, which record only changes in pixel intensity, offer an inherently privacy-preserving sensing modality. The proposed network is designed to efficiently model spatiotemporal dynamics while maintaining a lightweight architecture suitable for edge deployment. The methodology incorporates focal loss with class reweighting and targeted data augmentation to address class imbalance and enhance generalization.
Traditional HAR approaches relied on hand-crafted spatiotemporal features, such as STIPs and dense trajectories, but suffered from sensitivity to viewpoint and illumination. Deep learning methods, including Two-Stream CNNs, TSN, I3D, and C3D, improved accuracy by learning spatiotemporal representations but at the cost of increased computational complexity and privacy concerns due to reliance on RGB frames. Privacy-preserving alternatives, such as RF and radar-based systems, offer competitive accuracy for constrained gesture sets but lack the granularity of camera-based methods.
Event-based vision for HAR is an emerging field, leveraging neuromorphic sensors that provide asynchronous, high-dynamic-range data. Prior work has explored converting event streams into dense representations for processing with 2D/3D CNNs, but these models are often computationally expensive. Lightweight deep learning models, such as MobileNet and TSM, have demonstrated favorable accuracy-latency trade-offs for edge deployment, but their adaptation to event-based HAR remains underexplored.
Methodology
The proposed pipeline consists of preprocessing event data, feeding it into a lightweight 3D-CNN, and training with focal loss and class reweighting. The event data is derived from RGB videos converted into event streams, accumulated into 2D matrices at 30 fps, and uniformly downsampled to 10 frames per video for consistent input dimensions. The training dataset is compiled from the Toyota Smart Home and ETRI datasets, balanced across six activity classes.
Network Architecture
The network comprises five sequential 3D convolutional blocks with increasing channel sizes (1, 16, 32, 64, 128, 256), each followed by BatchNorm3d, ReLU, and MaxPool3d (kernel size (1,2,2)). The classification head includes dropout, global average pooling, and a fully connected layer. Focal loss is employed to address class imbalance, with AdamW optimizer and early stopping for regularization. The design prioritizes minimal parameter count and efficient inference, with optional self-attention for enhanced feature representation.
Training Strategy
Training is conducted on an NVIDIA RTX 3090 Ti GPU, with batch size 32, learning rate 0.0009, and early stopping based on F1 score improvements. Data augmentation is applied to underrepresented classes using random flips, rotations, affine transforms, and Gaussian blur.
Experimental Results
The proposed model achieves a test accuracy of 94.17% and an F1-score of 0.9415, outperforming benchmark 3D-CNN architectures (C3D, ResNet3D, MC3_18) by up to 3%. The best validation F1-score is 0.9409, indicating strong generalization. Training time is 322 minutes, shorter than two of the three baselines.
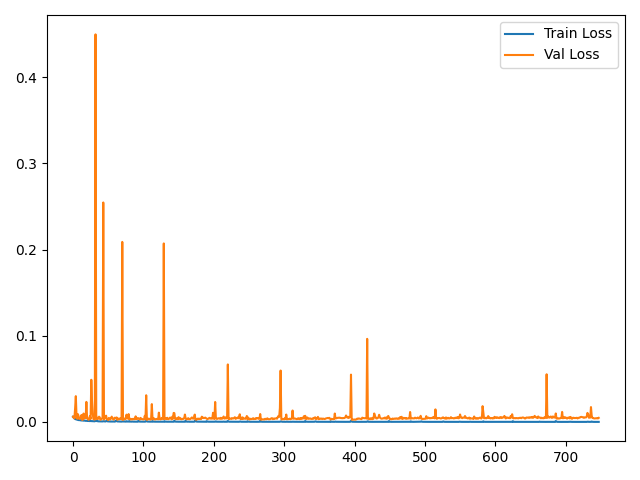
Figure 1: Training and validation loss graphs for the proposed method, demonstrating stable convergence and absence of overfitting.
The confusion matrix reveals high true positive rates across all classes, with minor misclassifications concentrated among visually or temporally similar activities.
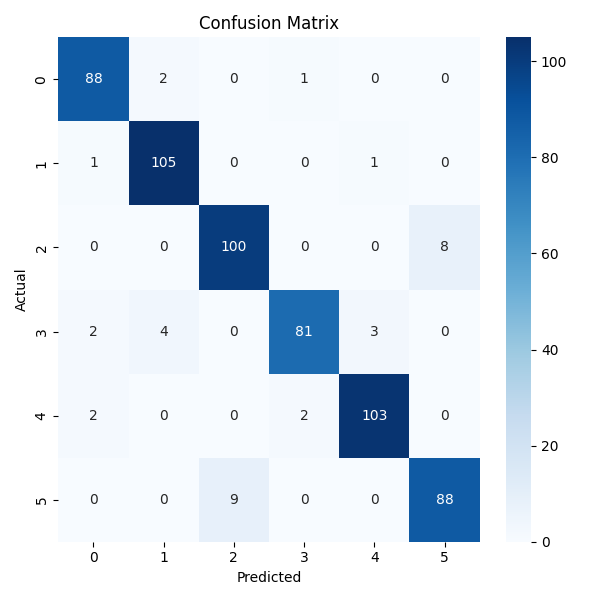
Figure 2: Confusion matrix for the proposed method, showing strong per-class accuracy and minimal misclassification.
Comparison with Baseline Models
The proposed method is benchmarked against C3D, ResNet3D, and MC3_18, with input layers modified for single-channel event data. All models are retrained from scratch for fair comparison. The proposed network outperforms all baselines in F1-score, accuracy, and validation loss, with competitive training time.
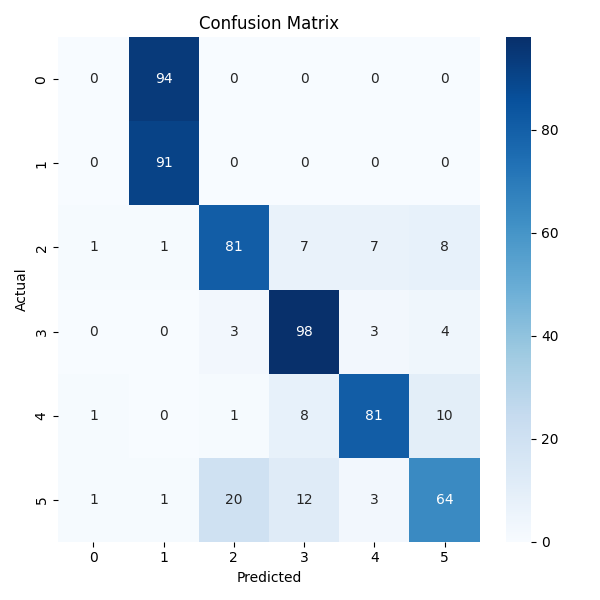
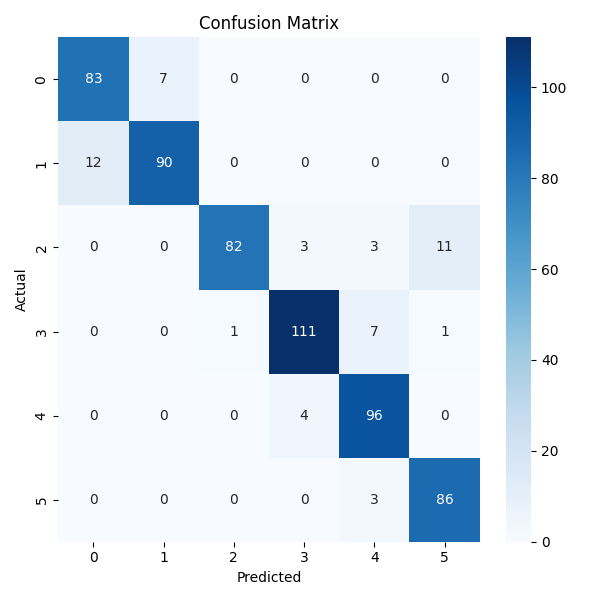
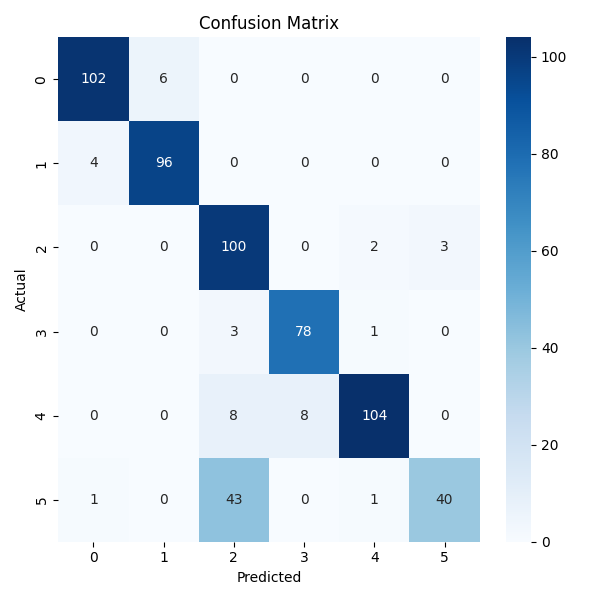
Figure 3: C3D architecture, illustrating the homogeneous 3D convolutional stack used for baseline comparison.
Confusion matrices for all models show the proposed method achieves the highest diagonal values, indicating superior classification performance.
Ablation Studies
Network size and frame rate are varied to assess their impact on performance. Halving the channel size results in a 4% drop in accuracy and F1-score, while doubling the size yields no improvement and increases training cost. Reducing the frame rate to 5 frames per video decreases accuracy to 89.33%, while increasing to 20 frames per video reduces accuracy by 2% and increases training time. The original configuration (10 frames, standard channel size) achieves optimal performance.
Strengths and Limitations
Strengths:
- Efficient spatiotemporal modeling with a compact 3D-CNN architecture.
- Effective handling of class imbalance via focal loss and targeted augmentation.
- Inherent privacy-preserving characteristics due to event-based input.
Limitations:
- Performance degrades under extreme class imbalance.
- Subtle or overlapping motion patterns remain challenging.
- Marginal gains from self-attention; transformer models limited by computational resources.
Implications and Future Directions
The results demonstrate that lightweight 3D-CNNs can achieve high accuracy and generalization for event-based HAR, with significant privacy-preserving potential. The approach is well-suited for edge deployment in healthcare, surveillance, and smart environments. Future work should explore advanced attention mechanisms, end-to-end event-stream processing (e.g., SNNs), and adaptive temporal resolution strategies to further enhance accuracy and efficiency.
Conclusion
This work presents a resource-efficient, privacy-preserving solution for human action recognition using event-based vision data. The proposed lightweight 3D-CNN outperforms established baselines in accuracy and generalization, with a design optimized for edge deployment. The methodology addresses key challenges in HAR, including privacy, class imbalance, and computational efficiency. Future research should focus on integrating advanced temporal modeling and expanding event-based datasets to further improve performance and applicability.