- The paper extends scaling limit frameworks by incorporating momentum methods and adaptive step-sizes in SGD.
- It uses Gaussian approximations and case studies like Spiked Tensor PCA to detail when SGD-M dynamics converge to online SGD.
- Preconditioning methods such as unit normalization are shown to stabilize convergence in high-dimensional, noisy environments.
High-Dimensional Limit Theorems for SGD: Momentum and Adaptive Step-Sizes
The paper "High-dimensional limit theorems for SGD: Momentum and Adaptive Step-sizes" (2511.03952) explores the high-dimensional behavior of Stochastic Gradient Descent (SGD) with Polyak Momentum (SGD-M) and adaptive step-sizes. The aim is to provide a scaling limit framework that helps compare online SGD with its popular variants.
Introduction
SGD and its variants, like momentum-based adjustments and adaptive step-sizes, form the backbone of large-scale optimization in machine learning. The high-dimensional setting introduces distinct dynamics as the problem dimension increases alongside the step-size. In this regime, scaling laws and limit theorems become pivotal to understanding and optimizing the behavior of these algorithms across complex data landscapes.
Contributions
The paper extends previous works on the effective dynamics of SGD to accommodate momentum methods and adaptive step-sizes. Notably, it establishes when the dynamics of SGD-M converge to those of conventional online SGD, given appropriate time rescaling and step-size choices. Conversely, due to high-dimensional effects, incorrectly choosing step-sizes for SGD-M may degrade performance compared to online SGD.
Two case studies—Spiked Tensor PCA and Single Index Models—demonstrate the derived limits. Interestingly, examples of adaptive step-size SGD further stabilize learning dynamics, illustrating how preconditioners can mitigate high-dimensional effects, such as exploding or vanishing gradients.
Methodology
The authors compute scaling limits and effective dynamics by analyzing the stochastic Gaussian approximations across iterative variables of the learning algorithms. For SGD-M, the incorporation of momentum complicates the dynamics, requiring meticulous adjustments at the level of gradient estimations and preconditioner designs.
Results
For Spiked Tensor PCA, the analysis reveals conditions under which SGD-M dynamics coincide with online SGD. The adaptation through SGD-U (unit-normalized gradients) shows potential improvements in convergence stability, particularly under challenging noise models. This illustrates that preconditioning with normalization can broaden the range of admissible step-sizes that promote convergence.
Similarly, in Single Index Models, the paper demonstrates how, under an adaptive scheme, the dynamics align closer to population minima, underscoring advantages in practical learning scenarios where data dimensions are large.
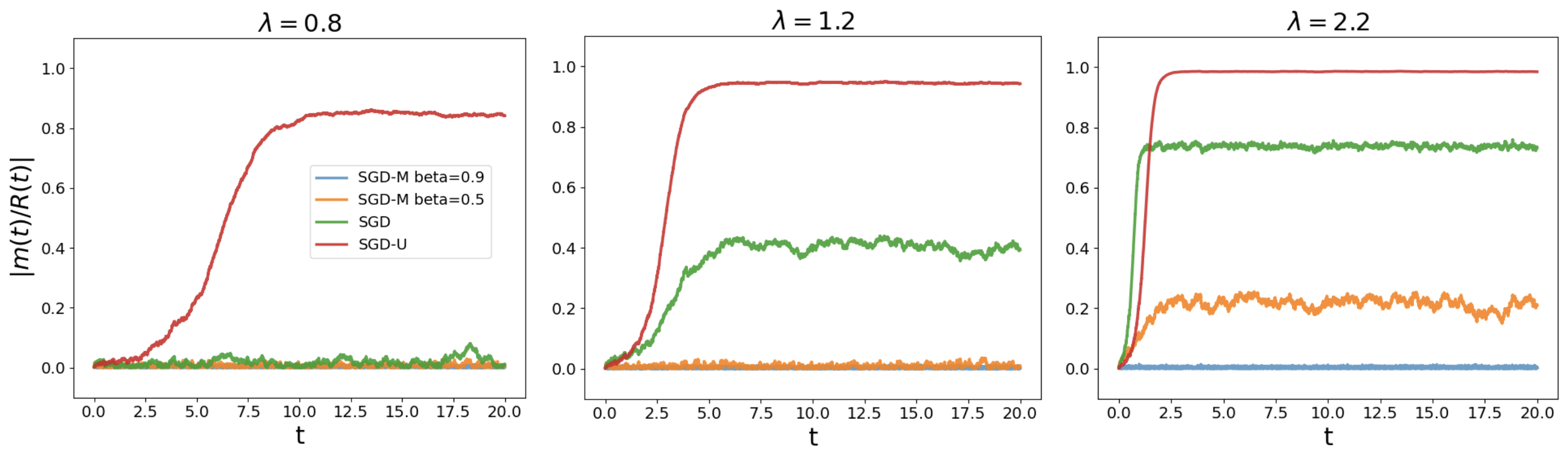
Figure 1: Matrix PCA in dimension n = 10000 for lambda values showcasing different behavior for SGD-U and SGD-M. Each lambda corresponds to a particular noise regime affecting alignment.
Limitations
While the theoretical framework is robust, there are approximations inherent to the finite dimensional truncations of the theoretical models. These may diverge slightly from empirical observations in datasets with non-standard distributions or extreme outliers.
Future Work
Future research directions include expanding the current models to capture a wider array of problem domains, such as generative modeling and reinforcement learning, where high-dimensional scaling limits could unveil new insights. Additionally, exploring other types of adaptive preconditioners that can dynamically adjust to the data's statistical properties could provide richer scalability and robustness in training modern deep networks.
Conclusion
The research underscores key insights in the deployment of momentum and adaptive algorithms in high-dimensional settings. By characterizing when and how these methods align with their online or batch counterparts, the work provides practitioners with guidelines to enhance performance and stability using scaling insights. Ultimately, the framework posited offers a potential pathway to systematically improve the implementation of SGD variants in real-world high-dimensional problems.