Machine Learning for Electron-Scale Turbulence Modeling in W7-X
Abstract: Constructing reduced models for turbulent transport is essential for accelerating profile predictions and enabling many-query tasks such as uncertainty quantification, parameter scans, and design optimization. This paper presents machine-learning-driven reduced models for Electron Temperature Gradient (ETG) turbulence in the Wendelstein 7-X (W7-X) stellarator. Each model predicts the ETG heat flux as a function of three plasma parameters: the normalized electron temperature radial gradient ($\omega_{T_e}$), the ratio of normalized electron temperature and density radial gradients ($\eta_e$), and the electron-to-ion temperature ratio ($\tau$). We first construct models across seven radial locations using regression and an active machine-learning-based procedure. This process initializes models using low-cardinality sparse-grid training data and then iteratively refines their training sets by selecting the most informative points from a pre-existing simulation database. We evaluate the prediction capabilities of our models using out-of-sample datasets with over $393$ points per location, and $95\%$ prediction intervals are estimated via bootstrapping to assess prediction uncertainty. We then investigate the construction of generalized reduced models, including a generic, position-independent model, and assess their heat flux prediction capabilities at three additional locations. Our models demonstrate robust performance and predictive accuracy comparable to the original reference simulations, even when applied beyond the training domain.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper builds fast, simple machine-learning models to predict how heat moves through a super-hot gas (plasma) inside Wendelstein 7-X (W7-X), a fusion device called a stellarator. The focus is on a kind of tiny, fast turbulence called electron temperature gradient (ETG) turbulence, which can carry heat out of the plasma and make it harder to reach fusion conditions. The idea is to replace super-expensive computer simulations with quick formulas that are accurate enough to be useful.
What questions did the researchers ask?
They set out to answer three main questions, using clear, simple formulas:
- Can we predict the electron heat flux (how much heat flows) from ETG turbulence using just three key knobs that describe the plasma?
- Can we build these formulas efficiently by letting machine learning choose the most informative examples from a large simulation database?
- Do these formulas work well at many positions across the plasma and even at new positions they weren’t trained on?
The three key plasma knobs are:
- The electron temperature gradient, written as
ω_Te: how quickly electron temperature changes from the center to the edge (steeper means more turbulence). - The ratio of the temperature gradient to the density gradient,
η_e: this balances “push” from temperature and “pull” from density. - The electron-to-ion temperature ratio,
τ: how hot electrons are compared to ions; largerτtends to calm ETG turbulence.
How did they study it? (Methods explained simply)
Think of the plasma like a stormy ocean full of tiny whirlpools. Simulating every swirl precisely is possible, but it’s extremely slow and costly. Instead, the researchers built “reduced models”—compact formulas that mimic the results of heavy simulations.
Their formula is a scaling law (a power-law) that looks like this:
Q_eis the electron heat flux.Q_GBis a standard way to measure flux called “gyro-Bohm units” (think of it like using kilometers instead of miles).c_0, p_1, p_2, p_3are numbers the model learns; they tell you how strongly each knob affects the heat flux.
To build and test these models, they:
- Started at seven “radial locations” (distances from the center), from 0.2 to 0.8, inside the plasma.
- Built small starter models using a “sparse grid” (like sampling a huge map at only strategic points rather than everywhere).
- Used “active learning” to improve the models: the computer looked through a big database of previous high-quality simulations and picked the examples that would teach the model the most. A helpful analogy: a student asks for practice problems that are most likely to fill the gaps in their understanding.
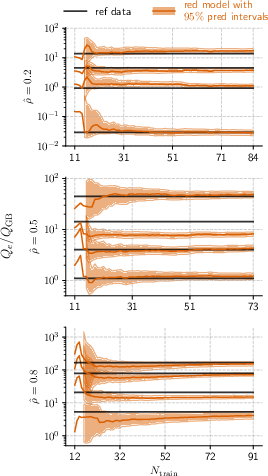
- Estimated uncertainty using “bootstrapping”: they repeatedly re-built the model by resampling the training data (like shuffling and re-dealing a deck many times) to see how predictions vary. They reported 95% prediction intervals (ranges where the true answer is likely to fall).
- Stopped adding new training points when uncertainty and recent prediction errors dropped below chosen targets.
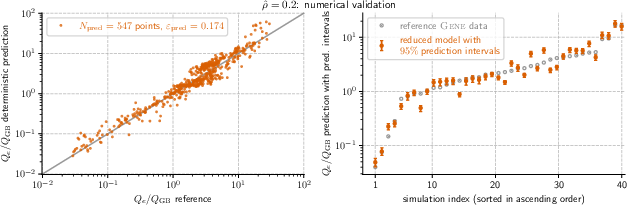
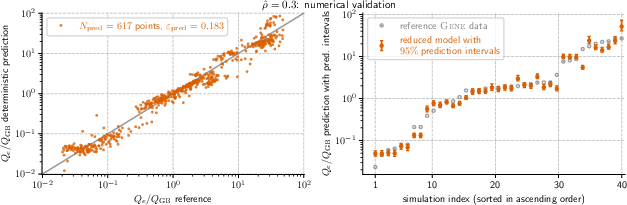
- Finally, they checked how well the models predicted heat flux at hundreds of “new” points they didn’t train on.
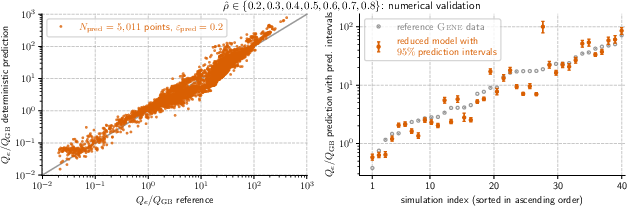
They also tried “generalized models,” including a single position-independent model, and tested these at three extra locations (0.1, 0.55, 0.75), including one outside the original training range.
What did they find?
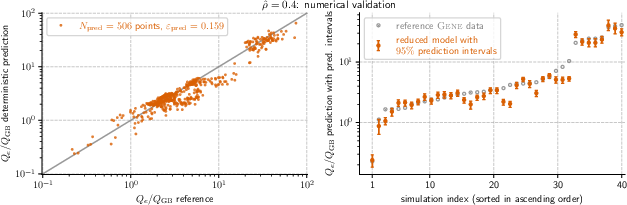
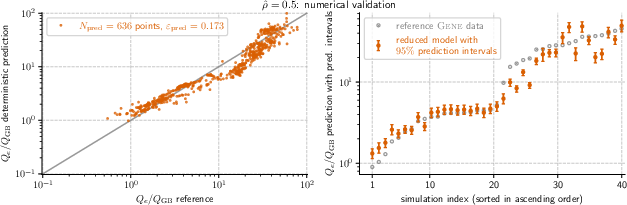
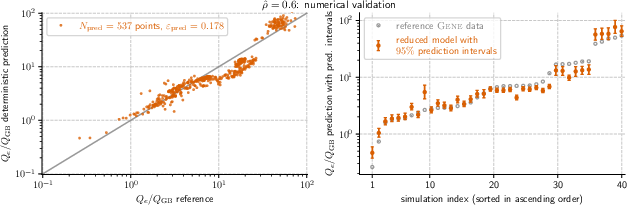
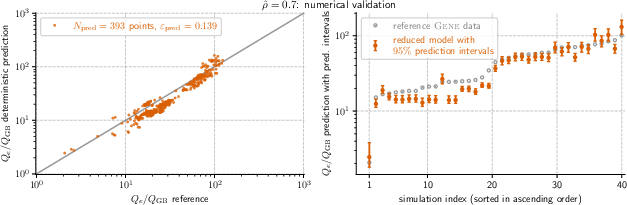
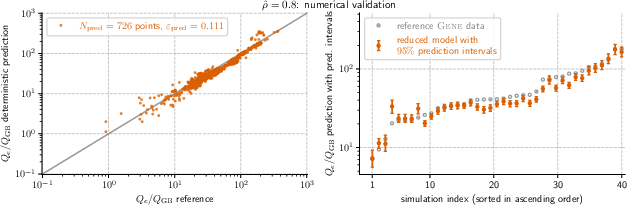
- The models were accurate and robust. Across the seven main positions, the prediction errors on new data were typically between about 0.12 and 0.18 (a standard fusion modeling error measure where smaller is better).
- They needed relatively few training points (about 73 to 138) per position, yet could predict hundreds of new cases per position.
- The uncertainty (95% prediction intervals) narrowed as they added informative training points—showing the active learning strategy worked.
- The learned exponents made physical sense:
- The electron temperature gradient
ω_Tehad a positive exponent: steeper temperature gradients tend to drive more turbulence and more heat flux. (η_e − 1)also had a positive exponent: larger temperature gradients compared to density gradients generally boost ETG turbulence.τhad a negative exponent: hotter electrons relative to ions tend to calm ETG turbulence and reduce heat flux.
- The electron temperature gradient
- The models worked not only at the trained positions but also at new positions, including one outside the original range—showing good generalization.
Why does this matter?
Running full turbulence simulations can take a long time and a lot of computing power. These reduced models give fast, reliable estimates of heat flux using only three simple inputs. That means:
- Scientists can quickly scan many scenarios (“parameter scans”) to see what settings keep heat inside the plasma.
- They can do “uncertainty quantification” (testing how sensitive predictions are to measurement errors).
- They can optimize designs and operating conditions faster—important for planning and improving fusion experiments.
- The approach (active learning + uncertainty estimation) can be reused for other kinds of turbulence and other fusion devices.
In short, this paper shows a practical way to speed up fusion research: use smart machine learning to capture the essential physics of small-scale electron turbulence in compact, trustworthy formulas. This helps move us closer to efficient, well-controlled fusion plasmas in devices like W7-X.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a consolidated list of what remains missing, uncertain, or unexplored in the study, framed to guide concrete next steps for future work.
- Physics scope is restricted to electron-scale, adiabatic-ion, local (flux-tube) simulations at a single field line; the impact of kinetic ions, multi-scale coupling (ITG/TEM–ETG interactions), and global effects remains unquantified.
- Only the field line through the outboard mid-plane (bean-cross-section) is used; poloidal/toroidal field-line dependence in W7-X (and associated geometry variations) is not captured or modeled.
- The reduced model inputs are limited to three parameters (, , ); potentially influential factors such as shear, collisionality, , separate density gradient , trapped-particle fraction, local magnetic shear/curvature, and other geometry metrics are excluded; their incremental value is unknown.
- The functional form is a single monomial scaling law; no exploration of interaction terms, cross-terms, piecewise regimes, breaks in scaling, or non-power-law representations (e.g., rational functions, splines) that could capture regime transitions or threshold behavior.
- The use of presumes a fixed threshold; applicability and accuracy near marginality () and for are not assessed.
- Electromagnetic ETG effects (finite- physics) are not modeled in the reduced law despite being varied in initial sparse grid data; the breakdown point of the electrostatic model is unknown.
- Impurities are neglected and (hydrogen ions) is assumed; sensitivity of scaling (including collisional effects) to non-unity and impurity content is untested.
- The database excludes simulations with transient heat-flux behavior; model fidelity for transient or non-stationary conditions (e.g., during profile evolution) remains unknown.
- Active learning is performed “offline” within a fixed pre-existing database; the method cannot propose new simulations in unseen regions, leaving coverage gaps in sparsely sampled or unrepresented parts of the input space.
- The construction of the AL test set (every fourth point after sorting by flux) may bias selection toward flux extremes and does not guarantee uniform or stratified coverage of the input space; the effect of alternative acquisition/test-set designs is not studied.
- Stopping criteria for AL (fixed thresholds max_dev = max_rel_err = 0.15) are chosen heuristically; sensitivity to these thresholds and principled acquisition strategies (e.g., expected improvement, BALD, query-by-committee) are not evaluated.
- Bootstrapped prediction intervals (PIs) assume i.i.d. samples and do not account for potential temporal or iterative correlations in database points generated by the coupled Gene–KNOSOS–Tango workflow; calibration under dependence is unvalidated.
- Empirical coverage of the reported 95% PIs on held-out data is not reported; whether the intervals are well-calibrated (nominal coverage) and sharp (narrow) is unknown.
- Uncertainty in high-fidelity labels (numerical discretization, collision operator approximations, resolution limits, box-size effects) is not quantified or propagated into model training and prediction intervals.
- Validation is limited to the same integrated-framework database; there is no evaluation against independent datasets (e.g., different codes/configurations) or against experimental heat-flux inferences, leaving external validity untested.
- Spatial generalization across radius is explored only via (i) regressing coefficients vs. and (ii) a position-independent model, with limited data at additional radii () and one outside the original range; systematic interpolation/extrapolation error across is not quantified.
- The reduced models are tied to the standard W7-X configuration; portability to other W7-X magnetic configurations or to other stellarators (with different quasi-symmetries/geometry) is unassessed.
- The choice of normalization ( with and global ) may hide local geometric dependencies; alternative normalizations or explicit inclusion of local geometric metrics has not been explored.
- Coefficient uncertainty (e.g., larger confidence intervals at ) indicates sensitivity to data scarcity and/or model misspecification; root-cause analysis and data acquisition strategies to reduce parameter uncertainty are not provided.
- Model selection is not benchmarked against more flexible surrogates (Gaussian processes, random forests, neural networks) or against physics-informed regression with constraints (e.g., monotonicity), so the optimality of the simple scaling form is unknown.
- The approach predicts only ; extensions to multi-output surrogates (e.g., particle flux, momentum flux) needed for integrated transport modeling are not developed or evaluated.
- The generalization claim “beyond the training domain” largely refers to predictions beyond the final AL-selected set but still within the database’s range; true out-of-distribution performance (e.g., new operational regimes) is not quantified.
- The influence of database composition (four OP1.2b scenarios: ECRH/NBI) on model bias is not analyzed; robustness to different heating schemes, density/temperature ranges, and profile shapes is untested.
- Computational trade-offs in uncertainty estimation (e.g., number of bootstrap resamples M vs. PI quality) and guidance for deployment in many-query tasks (UQ, optimization) are not provided.
- Data-space coverage diagnostics (e.g., fill distance, discrepancy) and targeted sampling to improve uniformity across the 3D input domain at each radius are not reported.
Practical Applications
Immediate Applications
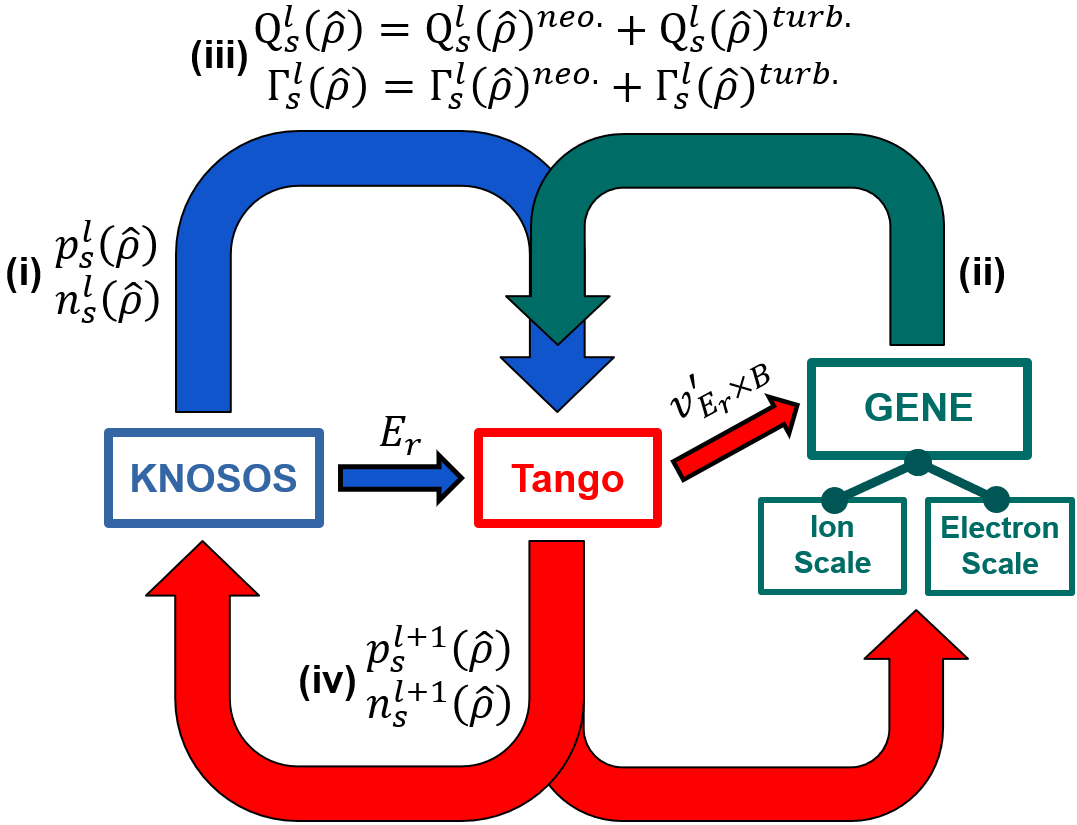
The paper introduces uncertainty-aware, machine-learning reduced models for electron-scale (ETG) heat flux in the W7-X stellarator, trained with sparse-grid initialization and active learning on an existing GENE–KNOSOS–Tango database. The following applications can be deployed now, given current capabilities and demonstrated accuracy.
- Fast ETG heat-flux prediction for integrated modeling in W7-X
- Sector: Energy (fusion), Software
- What it enables: Replace many expensive GENE runs with c0–p scaling-law evaluations to predict Qe/Q_GB across 7 radial locations, with accuracy comparable to reference simulations (validation errors ~0.115–0.183).
- Tools/workflows: Drop-in module for transport solvers (e.g., Tango), Python library/API that computes Qe/Q_GB and 95% bootstrapped prediction intervals from inputs (ω_Te, η_e, τ, radius).
- Assumptions/dependencies: Valid for the W7-X standard configuration, adiabatic-ion, steady-state, electron-scale regime; trained ranges per Table summaries; Z_eff = 1 (no impurities); flux-tube assumption; outboard mid-plane field line; uncertainty intervals reflect resampling uncertainty but not model-form error.
- Uncertainty-aware many-query tasks (UQ, parameter scans, sensitivity studies)
- Sector: Energy (fusion), Software
- What it enables: Orders-of-magnitude faster ensemble evaluations for uncertainty quantification and parameter scans in profile evolution studies; supports decision-making with 95% prediction intervals via bootstrapping.
- Tools/workflows: Batch evaluation pipelines; coupling to UQ frameworks; campaign analysis dashboards.
- Assumptions/dependencies: Reliable input distributions for ω_Te, η_e, τ; predictions most trustworthy within training domain; intervals depend on data representativeness.
- Experimental planning and scenario triage in W7-X operations
- Sector: Energy (fusion), Operations
- What it enables: Rapid ranking of heating and density-gradient scenarios by expected ETG-driven heat flux; focus scarce run time on scenarios with targeted transport levels.
- Tools/workflows: “What-if” planners using the reduced model to explore gradients and τ; highlight regions with wide prediction intervals for targeted new simulations/measurements.
- Assumptions/dependencies: Requires timely estimates of ω_Te, η_e, τ from diagnostics; applicability limited to OP1.2b-like regimes and electron-scale transport effects.
- Active learning for simulation database curation
- Sector: Energy (fusion), Software/Computational Science
- What it enables: Use the paper’s label-independent acquisition metric (max relative prediction-interval deviation) to select the next most informative simulation points from candidate sets—reducing GENE compute while improving model coverage.
- Tools/workflows: Active-learning loop that proposes (ω_Te, η_e, τ) candidates; automates simulation scheduling; updates reduced model iteratively.
- Assumptions/dependencies: Candidate pool must reflect intended operating space; acquisition does not require labels but utility hinges on out-of-sample generality.
- Cross-radial gap-filling with generalized models
- Sector: Energy (fusion)
- What it enables: Use the generic, position-independent model or coefficient-regression approach to obtain ETG heat-flux estimates at additional radii (e.g., ρ̂ = 0.1, 0.55, 0.75) when direct data are sparse.
- Tools/workflows: Hybrid radial interpolation/extrapolation within integrated modeling.
- Assumptions/dependencies: Degradation possible outside training radii; verify against limited reference data; treat predictions with wider uncertainty near edges of training domain.
- Curriculum and training materials for plasma turbulence and data-driven modeling
- Sector: Education, Academia
- What it enables: Teaching modules on sparse grids, active learning, uncertainty quantification, and turbulence surrogate building with real W7-X data.
- Tools/workflows: Interactive notebooks reproducing regression, bootstrapping, and active-learning steps; sample datasets; open-source code.
- Assumptions/dependencies: Availability of sanitized datasets/code; proper attribution and data-use agreements.
- Benchmarking and reproducible baselines for stellarator ETG reduced models
- Sector: Academia
- What it enables: Common reference for comparing new ML architectures or physics-informed surrogates on W7-X ETG transport; accelerates method development.
- Tools/workflows: Standardized train/validation splits, published coefficients and confidence intervals, acquisition metrics.
- Assumptions/dependencies: Community access to the same database/splits; clarity on normalization (gyro-Bohm units) and preprocessing choices.
- HPC cost reduction for profile evolution studies
- Sector: Energy (fusion), Computing
- What it enables: Replace large portions of GENE runs with surrogate evaluations, reducing HPC hours while preserving accuracy and adding uncertainty quantification.
- Tools/workflows: Hybrid multi-fidelity workflows (surrogate as default; GENE for high-uncertainty or critical regions).
- Assumptions/dependencies: Governance policies for when to fallback to high-fidelity; monitoring of drift as operating space expands.
Long-Term Applications
These applications extend the paper’s methods beyond current constraints, requiring further validation, scaling, or scope expansion (e.g., physics coverage, device generality, real-time integration).
- Real-time supervisory control and MPC for stellarators using ETG surrogates
- Sector: Energy (fusion), Control Systems
- What it enables: Embed fast ETG transport estimates (with uncertainty) in model predictive control and scenario tracking for heating/current-drive scheduling and profile shaping.
- Tools/workflows: Surrogate-in-the-loop controllers with uncertainty-aware constraint tightening; real-time diagnostic pipelines to supply ω_Te, η_e, τ.
- Assumptions/dependencies: Low-latency, reliable estimates of gradients and τ; validated performance under distribution shift; integration with other channels (ion heat, particle, momentum).
- Whole-device digital twins with multi-physics surrogates
- Sector: Energy (fusion), Software
- What it enables: Fusion digital twins that couple ETG surrogates with ITG/TEM/MTM, neoclassical, core–edge coupling, MHD limits; rapid scenario optimization and anomaly diagnosis.
- Tools/workflows: Modular surrogate libraries with shared uncertainty interfaces; multi-scale orchestration; cross-validation against experiments.
- Assumptions/dependencies: Expanded databases (multi-channel, multi-scale, electromagnetic effects, impurities), robust cross-regime generalization, standardized uncertainty propagation.
- Design optimization of next-generation stellarators
- Sector: Energy (fusion), Engineering/Design
- What it enables: Use uncertainty-aware ETG transport surrogates inside optimization loops for coil and configuration design, targeting reduced transport and improved confinement.
- Tools/workflows: Multi-objective optimizers coupling geometry, profiles, and transport responses; active learning to adaptively sample in high-impact design regions.
- Assumptions/dependencies: Surrogates generalized to varying geometries/configurations; parameterization of geometry; coverage of relevant turbulence regimes and operating spaces.
- Cross-device/generalized ETG surrogates and transfer learning
- Sector: Energy (fusion), ML/AI
- What it enables: Extend surrogates from W7-X to other stellarators (HSX, LHD, TJ-II, future reactors) and high-performance tokamak regimes via transfer learning or meta-learning.
- Tools/workflows: Multi-device datasets; domain adaptation techniques; shared physics-informed architectures.
- Assumptions/dependencies: Availability of comparable, high-quality databases; harmonized normalizations and feature definitions; documented differences in magnetic geometry and collisionality.
- Multi-fidelity active learning that blends experiment and simulation
- Sector: Energy (fusion), Experimental Science
- What it enables: Jointly propose new high-fidelity simulations and targeted experiments to maximally reduce predictive uncertainty and close model-form gaps.
- Tools/workflows: Acquisition functions balancing cost, information gain, and safety; Bayesian decision-making under uncertainty.
- Assumptions/dependencies: Reliable uncertainty quantification that captures model-form error; coordination across experimental schedules and HPC allocations.
- Regulatory-grade uncertainty budgets for predictive modeling in fusion
- Sector: Policy/Regulation
- What it enables: Establish uncertainty-aware predictive tools for planning and safety analysis in advanced fusion facilities; support evidence for licensing and performance guarantees.
- Tools/workflows: Standardized validation protocols, traceable uncertainty decomposition (data, model form, numerical); benchmarks across devices.
- Assumptions/dependencies: Community standards, open datasets, and reproducibility; institutional acceptance of ML surrogates with documented limitations.
- Diagnostic inference and profile reconstruction
- Sector: Energy (fusion), Diagnostics
- What it enables: Invert surrogate relationships to infer gradients or τ from measured heat fluxes (and vice versa), providing rapid, uncertainty-aware profile estimates.
- Tools/workflows: Bayesian inversion with surrogate likelihoods; integration into real-time diagnostic pipelines.
- Assumptions/dependencies: Identifiability of parameters from available measurements; quantification of measurement noise and model-form uncertainty.
- Educational digital twins and public engagement
- Sector: Education, Public Outreach
- What it enables: Interactive platforms enabling students and the public to adjust gradients and see predicted transport responses and uncertainties; demystify turbulence and optimization.
- Tools/workflows: Web-based simulators using the reduced models; curriculum-aligned modules.
- Assumptions/dependencies: Simplified interfaces and visualizations; careful messaging around model scope and uncertainty.
- Data standards and model repositories for turbulence surrogates
- Sector: Academia, Policy, Software
- What it enables: Community-wide repositories of reduced models (coefficients, training ranges, uncertainty metadata) and datasets to accelerate research and technology transfer.
- Tools/workflows: FAIR-compliant data/model hubs; APIs; citation and versioning practices.
- Assumptions/dependencies: Sustained support for curation and governance; contributor agreements; interoperability with existing platforms.
- Cross-domain application of the methodology (active learning + bootstrapped uncertainty)
- Sector: Computational Science, Software
- What it enables: Apply the same pipeline to other expensive physics (e.g., CFD in aerospace, climate subgrid models, materials simulations) to build reliable surrogates with quantified uncertainty.
- Tools/workflows: Generalized active-learning libraries; plug-ins for domain solvers; workflow orchestration.
- Assumptions/dependencies: Existence of structured databases or the ability to run on-demand; careful adaptation of scaling-law forms or model classes to new physics.
Key global assumptions and dependencies across applications
- Physics scope: Electron-scale ETG-only; adiabatic ions; no impurities (Z_eff = 1); steady-state flux-tube limit; specific W7-X configuration and field line; training ranges as in the database.
- Data scope: Derived from four OP1.2b scenarios; transient runs excluded; performance may degrade under distribution shift (new regimes, stronger electromagnetic effects, core–edge coupling changes).
- Model form: Fixed scaling-law structure Qe/Q_GB = c0 ω_Te{p1} (η_e − 1){p2} τ{p3}; model-form error not captured by bootstrap intervals; consider hybrid strategies (surrogate + selective GENE runs).
- Operationalization: Real-time and cross-device uses require robust diagnostics for ω_Te, η_e, τ, and further validation; uncertainty must be propagated through integrated models and controllers.
Glossary
- Adiabatic-electron: An approximation where electrons respond adiabatically to potential fluctuations, neglecting kinetic electron dynamics. "a database of $200,000$ adiabatic-electron gyrokinetic runs."
- Adiabatic-ion simulations: Gyrokinetic simulations that treat ions as adiabatic (non-kinetic), focusing on electron-scale turbulence. "These adiabatic-ion simulations were performed using the plasma micro-turbulence gyrokinetic simulation code Gene"
- Bootstrapping: A resampling method that estimates uncertainty (e.g., prediction intervals) by repeatedly sampling with replacement from the training data. "we use bootstrapping to compute prediction intervals"
- Coulomb logarithm: A logarithmic factor in plasma collision rates representing the range of impact parameters for Coulomb interactions. "where is the Coulomb logarithm."
- Debye length: The characteristic electrostatic screening length in a plasma; here used in normalized form. "$\uplambda_{De} = 0.9859 \times B_{\rm ref} n^{-1/2}_{\rm e}$ is the normalized Debye length."
- Dimensionless radial coordinate (): A flux-surface-based, normalized radial coordinate used to specify position in toroidal plasmas. "The dimensionless radial coordinate $\hat{\rho} = \sqrt{\Psi}/{\Psi_{LCFS}$ is defined by the ratio between the value of a flux surface and that of the LCFS."
- Effective ion charge (): A weighted average ion charge state that captures impurity content and enters collisional models. " is the effective ion charge retained in the collision operator"
- Effective minor radius: A geometric measure of plasma size derived from toroidal flux, used for normalization. "and is the effective minor radius of the magnetic geometry, defined as $a = \sqrt{\Psi_{\rm LCFS}/{\pi B_{\rm ref}$."
- Electron cyclotron resonance heating (ECRH): Plasma heating using microwaves at the electron cyclotron frequency to heat electrons. "The naming convention reflects the type of heating in these scenarios, which are electron cyclotron resonance heating (ECRH) and neutral-beam injection (NBI)."
- Electron gyroradius: The Larmor radius of electron circular motion around magnetic field lines. "where is the electron gyroradius,"
- Electron heat flux: The radial transport of electron thermal energy per unit area. "where is the electron heat flux (in $\mathrm{W/m^{-2}$)"
- Electron Temperature Gradient (ETG) turbulence: Microturbulence driven by electron temperature gradients that governs electron heat transport. "This paper presents machine-learning-driven reduced models for Electron Temperature Gradient (ETG) turbulence in the Wendelstein 7-X (W7-X) stellarator."
- Flux-tube limit: A local simulation approach that follows a single magnetic field line with periodicity along it, assuming scale separation. "in the flux-tube limit"
- Gene-KNOSOS-Tango framework: An integrated workflow coupling gyrokinetic turbulence (GENE), neoclassical transport (KNOSOS), and a 1D transport solver (Tango) to evolve profiles self-consistently. "The high-fidelity data for active-learning-based iterative model refinement and numerical validation were generated using the Gene-KNOSOS-Tango simulation framework."
- Gyro-Bohm (GB) units: A normalization of transport fluxes based on gyro-Bohm scaling using characteristic gyroradius and thermal speed. "and $Q_{\mathrm{GB} = n_e T_e^{5/2} m_e^{1/2} / (e B_{\rm ref} a)^2$ is the flux in gyro-Bohm (GB) units."
- Gyrokinetic: A reduced kinetic theory that averages over fast gyromotion to model turbulence in magnetized plasmas. "gyrokinetic simulation code Gene"
- KNOSOS: A neoclassical transport code for toroidal plasmas used to compute collisional transport in stellarators and tokamaks. "the neoclassical transport code KNOSOS"
- Landau–Boltzmann operator: The linearized collision operator describing small-angle Coulomb collisions in kinetic equations. "which is the linearized Landau--Boltzmann operator in our simulations."
- Last closed flux surface (LCFS): The outermost magnetic surface that still closes on itself, enclosing the confined plasma. "the toroidal magnetic flux through the last closed flux surface (LCFS)."
- Neoclassical transport: Collisional transport arising from particle drifts in toroidal geometry, distinct from turbulent transport. "the neoclassical transport code KNOSOS"
- Neutral-beam injection (NBI): Heating and fueling by injecting high-energy neutral atoms that ionize in the plasma and transfer energy/momentum. "which are electron cyclotron resonance heating (ECRH) and neutral-beam injection (NBI)."
- Pedestal region: The edge transport barrier in H-mode plasmas characterized by steep gradients in temperature and density. "within the tokamak pedestal region"
- Sparse grid: A high-dimensional approximation technique exploiting anisotropy to reduce the number of required samples versus full grids. "structure-exploiting sparse grid approach"
- Stellarator: A toroidal magnetic confinement device with 3D fields generated by external coils, not relying on plasma current. "in the Wendelstein 7-X (W7-X) stellarator."
- Tokamak: An axisymmetric toroidal magnetic confinement device that uses a strong toroidal plasma current for part of the confining field. "primarily focused on tokamak core plasmas"
- Toroidal magnetic flux: Magnetic flux passing through a toroidal surface, used to define flux coordinates and device size measures. "denotes the toroidal magnetic flux through the last closed flux surface (LCFS)."
- Wendelstein 7-X (W7-X): A large optimized stellarator experiment in Greifswald, Germany. "This paper presents machine-learning-driven reduced models for Electron Temperature Gradient (ETG) turbulence in the Wendelstein 7-X (W7-X) stellarator."
Collections
Sign up for free to add this paper to one or more collections.

