- The paper presents a novel framework that audits justified representation by adapting computational social choice principles to a continuous utility setting.
- It introduces efficient algorithms that reduce computational complexity and leverages semantic similarity models validated with strong AUC scores for robust utility estimation.
- Empirical evaluations demonstrate that algorithmic methods, including LLM-based synthesis, consistently outperform traditional moderator selections in ensuring fair representation.
Auditing Representation in Online Deliberative Processes
Overview and Motivation
This paper addresses the critical challenge of ensuring proportional representation in the selection of participant questions for expert panels in online deliberative processes. Conventional approaches—where moderators manually curate a subset of participant-proposed questions—often lack transparent or formal guarantees of representativeness, exposing the process to perceptible and quantifiable gaps. By applying principles from computational social choice, namely the justified representation (JR) axiom, the authors propose a rigorous, efficient framework that quantifies and audits representation in both moderator-selected and algorithmically-generated slates. The study further explores the role of LLMs in generating either extractive (direct selection) or abstractive (synthetic) question aggregates, rigorously evaluating their capacity to represent participant interests via the developed auditing mechanism.
The paper elevates the concept of justified representation (JR) from its origins in approval voting to a general utility setting, accommodating continuous-valued similarity scores rather than binary approvals. Let n denote the number of participants, m the total set of proposed questions, and k≪m the number of questions posed to the expert panel. The JR axiom requires that any coalition of at least n/k participants with shared interest must have at least one question in the final slate that substantively reflects their views. The generalization to α-JR allows for quantification: α-JR provides guarantees to coalitions down to size α⋅n/k, with α=1 recovering classic JR.
To aggregate and infer utility for arbitrary slates, the framework utilizes semantic similarity models—specifically, cosine similarity between sentence embedding vectors—to construct the utility function ui(q) mapping each participant–question pair. Such embedding-based approaches, validated empirically against benchmarks like the Quora Question Pairs (QQP) dataset, achieve AUC scores in the range $0.868$ to $0.876$, indicating strong alignment with human judgments of semantic equivalence.
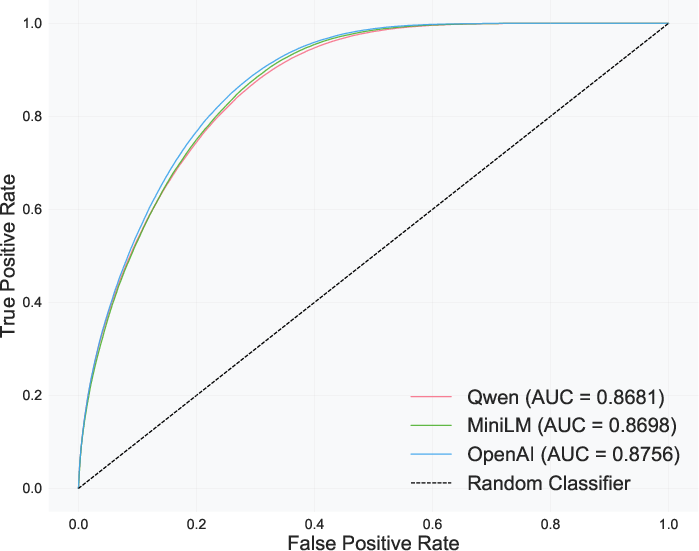
Figure 1: ROC curves indicating the binary classification performance of diverse embedding models on the QQP dataset, substantiating the reliability of cosine similarity as a utility proxy.
Algorithmic Auditing for Justified Representation
The core computational contribution involves two novel algorithms for auditing the JR value in the general utility setting. The naïve approach, while conceptually straightforward, operates in O(mn2) time by evaluating all relevant thresholds and combinations directly. An optimized approach reduces computational complexity to O(mnlogn) by leveraging order-statistics and sorting: participants are ordered based on their utility for the slate and candidate questions, allowing single-pass coalition identification and threshold updates.
The methodology ensures that for each slate W—whether human-curated, randomly sampled, selected via an integer program (IP), or synthesized by LLMs—the JR value is computed efficiently, enabling exhaustive audit even in large-scale deliberations. The authors demonstrate that utility inference is robust across embedding models by cross-validating slates generated by one embedding when evaluated under others.
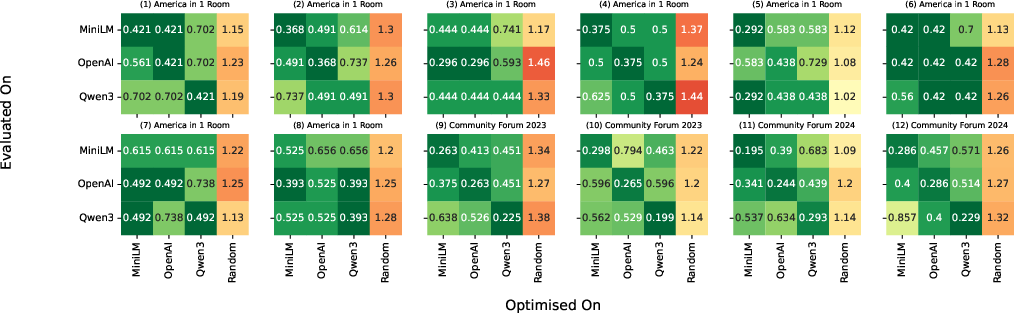
Figure 2: Heatmaps visualizing JR-value consistency across slates optimized and evaluated under various embedding models, establishing cross-model robustness of the auditing procedure.
Evaluation: Empirical Benchmarks and Integration
Empirical validation spans 12 sessions across three major deliberations: "America in One Room: Democratic Reform" (A1R), "Meta Community Forum on AI Chatbots" (CF'23), and "Meta Community Forum on AI Agents" (CF'24). Deliberative polls were conducted on a self-moderating platform, enabling systematic data capture and audit integration.
For extractive summarization, the study utilizes integer programming—formulated to minimize the size of the largest dissatisfied coalition—guaranteeing the optimal representative subset from participant questions. For abstractive summarization, LLMs are prompted to generate new questions intended to exhaustively summarize participant inputs. The platform supports interactive audit and visualization, allowing moderators to transparently compare candidate slates on representativeness metrics.
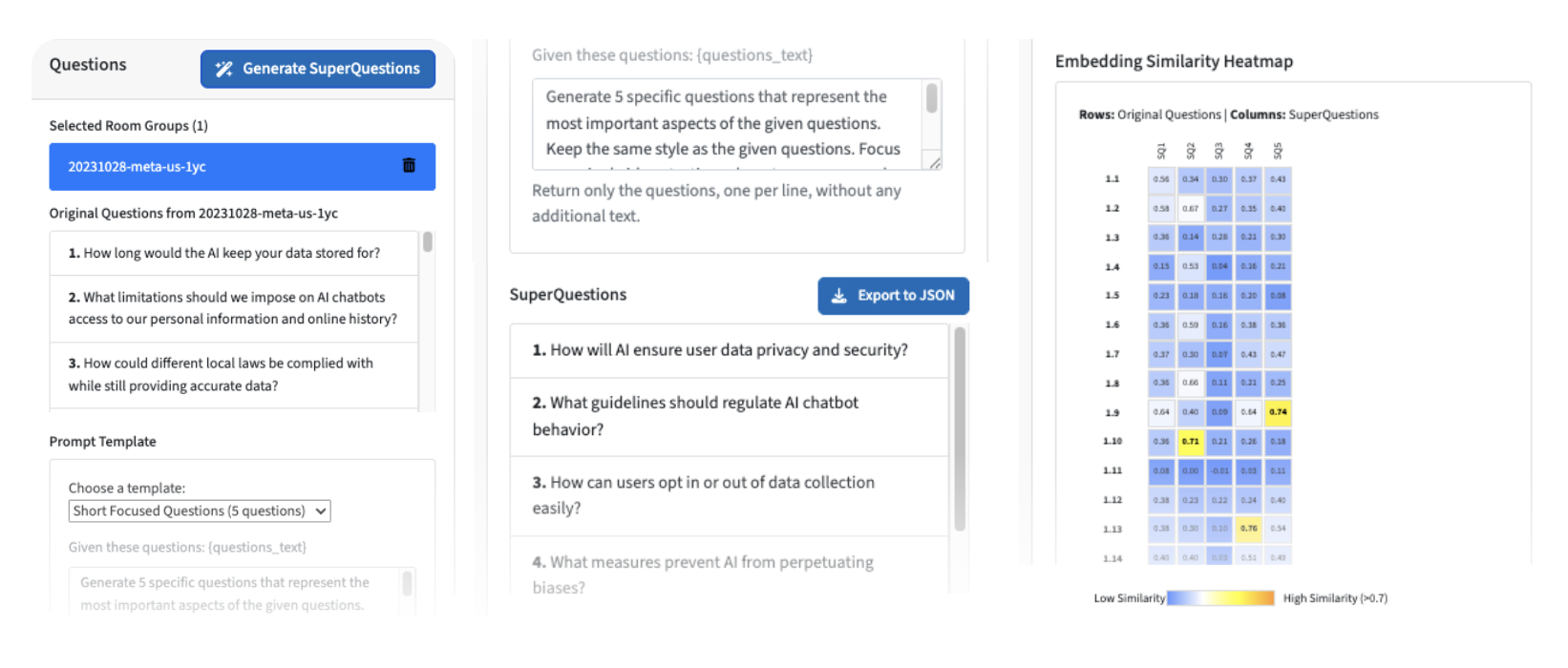
Figure 3: Screenshots of the deliberation platform integrating LLM summarization and representational auditing, enhancing moderator awareness and actionable transparency.
Empirical results indicate:
- Algorithmic methods (IP and LLM-synthesis) consistently yield slates with lower (more favorable) JR values than both randomly sampled and historical, human-curated slates.
- In several panels, human moderator selections do not satisfy JR, suggesting substantial room for procedural improvement.
- Abstractive LLM-generated slates often match or surpass the representativeness of optimal extractive slates, particularly in scenarios with limited original questions; however, performance varies by session, marking the necessity of auditing over blind reliance on automation.
- Systematic cross-validation confirms that similarity-based utilities are sufficiently robust regardless of underlying embedding choice.
Theoretical and Practical Implications
Algorithmic auditing for justified representation in this context directly operationalizes democratic values of inclusiveness and fairness, furnishing moderators and institutions with actionable levers to enhance deliberative legitimacy. The use of semantic similarity informs scalable, interpretable utility estimation, compatible with real-time deployment. Conversely, the limits of moderator curation, as surfaced by audit, challenge assumptions about human process fidelity.
LLM-based question generation shows promise for flexible, scalable abstractive summarization, but empirical variability and the ongoing need for rigorous audit underscore the risk of overgeneralization. The framework further positions itself for extension: hybrid approaches blending selection and synthesis, richer axiomatic audits (PJR, EJR, BJR), and direct participant utility validation are all plausible future directions.
By integrating these algorithms into operational platforms used globally, the research advances immediate practical utility, positioning AI as an augmentative tool rather than a replacement in high-stakes democratic procedures.
Conclusion
This work bridges computational social choice and AI-facilitated online deliberation, providing the first scalable algorithmic audit for justified representation in the general utility setting. Semantic embedding-based utilities and efficient algorithms permit rigorous, actionable evaluation of both extractive and abstractive summarization strategies in question slate selection. Empirical deployment across diverse deliberative contexts reveals that algorithmically-aided processes outperform conventional human moderation on representativeness, but that robust, ongoing audit remains essential in leveraging LLMs. The platform integration ensures these contributions have immediate translational impact, with clear avenues for future refinement in both theory and practice.