- The paper demonstrates that causal interventions yield divergent representations in neural networks, potentially compromising mechanistic interpretability.
- It distinguishes between harmless divergences in the null-space and pernicious divergences that lead to misleading network behaviors.
- The study introduces a Counterfactual Latent (CL) loss to reduce divergence and enhance out-of-distribution generalization in synthetic tasks.
Addressing Divergent Representations from Causal Interventions on Neural Networks
Introduction
Causal interventions in neural networks (NNs) are crucial for understanding and interpreting the representations these networks learn. The study "Addressing divergent representations from causal interventions on neural networks" investigates the reliability of such interventions. It reveals that interventions often induce representational divergences, potentially impacting the faithfulness of mechanistic explanations. The paper provides both theoretical and empirical insights into these divergences and proposes modifications to mitigate their pernicious effects. This essay discusses the key elements of the research, including empirical observations, theoretical analyses, and the application of a modified loss function to reduce divergence.
Empirical Observations of Representational Divergence
The study systematically demonstrates that causal interventions in NNs frequently result in divergent representations. This phenomenon occurs across various methods, including activation patching and Distributed Alignment Search (DAS). Empirical data show that representations post-intervention often shift away from their natural distribution, raising concerns about the fidelity of causal interpretations derived under these conditions.
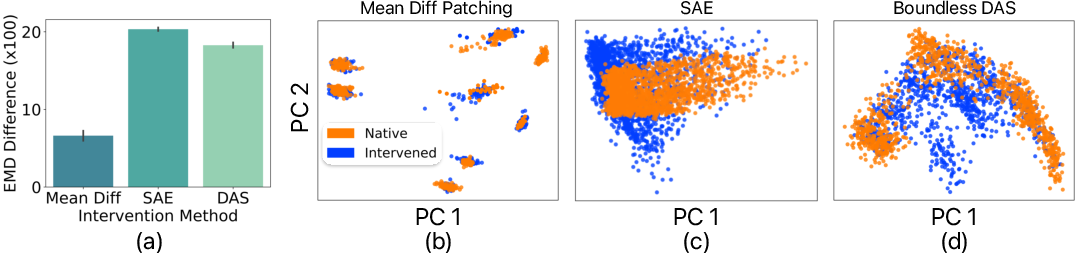
Figure 1: Representational divergence is a common issue across various forms of patching.
Theoretical Analysis: Harmless vs. Pernicious Divergence
Theoretical exploration in the paper distinguishes between harmless and pernicious divergences. Harmless divergences can occur in the null-space of network weights where they do not affect model behavior and can sometimes be desirable for inference. In contrast, pernicious divergences activate hidden pathways, leading to misleadingly confirmatory or dormant changes in behavior, thus compromising the mechanistic validity of interpretations.
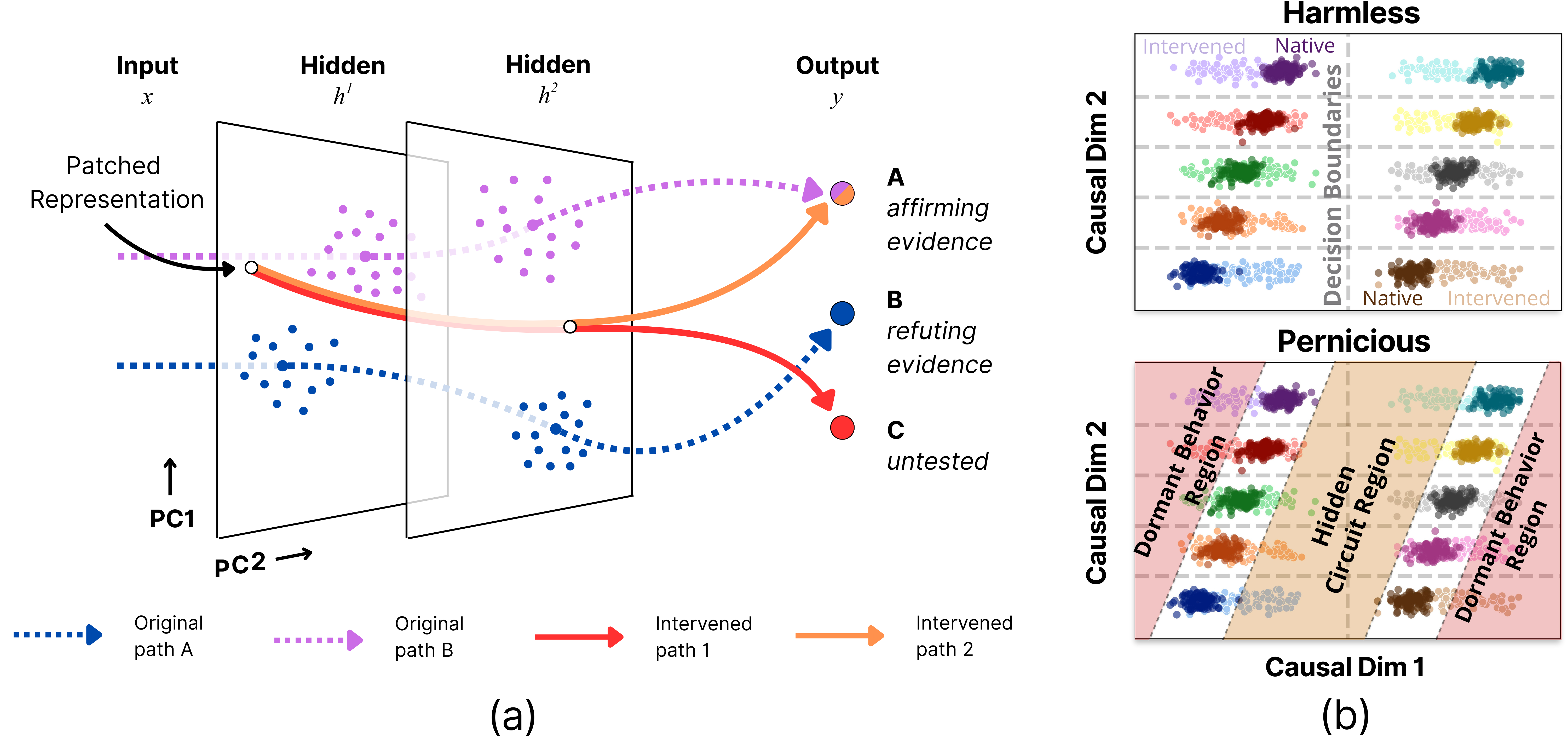
Figure 2: Causal interventions can recruit hidden circuits that produce misleadingly confirmatory or dormant behavior.
Mitigation via the Counterfactual Latent (CL) Loss
To address pernicious divergences, the researchers adapt the Counterfactual Latent (CL) loss to minimize divergence along causally relevant dimensions. This loss function is integrated into the training regime, ensuring that interventions remain closer to the natural distribution of representations. Testing on synthetic data tasks demonstrates that applying this modified loss improves out-of-distribution (OOD) generalization, indicating the benefits of regularizing interventions to align them with natural manifold distributions.
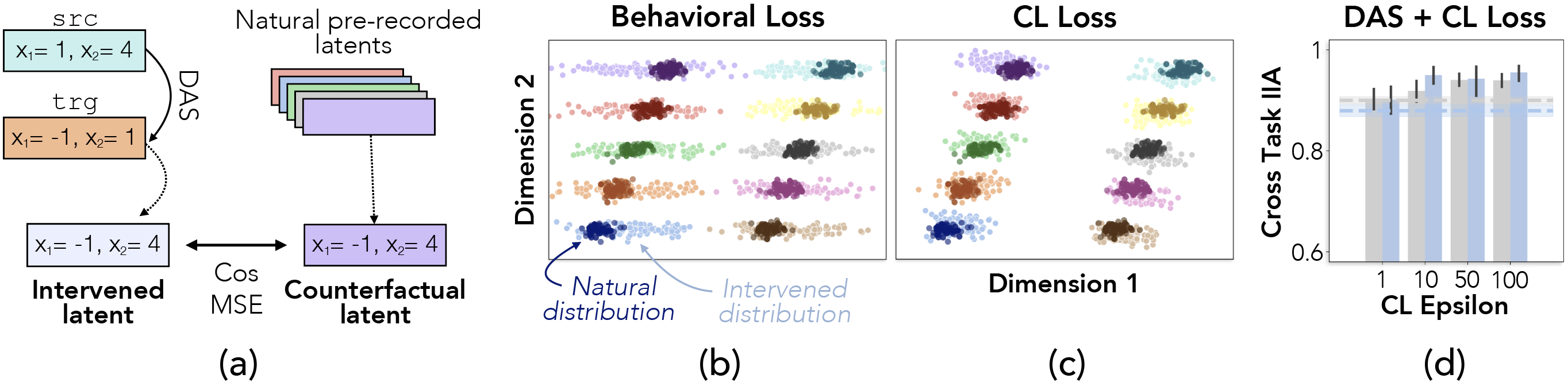
Figure 3: The CL loss reduces representational divergence and improves out-of-distribution generalization.
Practical Implications and Future Directions
The work emphasizes the critical need to assess the consequences of representational divergence in neural networks. The proposed CL loss approach paves the way for more reliable causal interventions, but it is acknowledged that further research is needed to fine-tune intervention methods and ensure their robustness across diverse contexts and network architectures. Future work could focus on enhanced techniques for classifying divergence types and developing intervention strategies that inherently avoid pernicious effects.
Conclusion
This research highlights the widespread issue of representational divergence in causal interventions within neural networks and offers a promising method to mitigate such divergence through modified loss functions. While these insights significantly advance the field of mechanistic interpretability, the ongoing challenge remains to develop comprehensive, scalable solutions to ensure that causal interpretations genuinely reflect the native mechanisms of neural networks. The findings underline a crucial trajectory for future exploration in understanding and controlling neural representations through causal interventions.