- The paper introduces a unified framework that uses VLM-based semantic arbitration to fuse human and autonomous driving plans.
- It details three core modules—abstraction, uncertainty estimation, and multi-modal reasoning—to maintain driving intent and robust control.
- Empirical results show significant improvements in collision reduction, route completion, and overall driving performance in challenging scenarios.
SAFe-Copilot: Unified Shared Autonomy Framework
Introduction
SAFe-Copilot introduces a unified shared autonomy framework for interactive driving that leverages recent advances in vision–LLMs (VLMs) to synthesize and arbitrate between plans originating from both human drivers and autonomous planners. The framework targets one of the persistent challenges in autonomous vehicles: their brittleness in the face of ambiguous, out-of-distribution (OOD) scenarios and limitations in contextual reasoning, where humans are adept. Unlike typical low-level arbitration approaches that combine geometric trajectories—often discarding driving intent—SAFe-Copilot operates at a high-level semantic abstraction, maintaining intent and enabling context-sensitive, common-sense reasoning.
This essay provides an expert analysis of the technical mechanisms, empirical results, and implications of the SAFe-Copilot approach.
Technical Architecture
SAFe-Copilot unites three core modules: abstraction, uncertainty estimation, and reasoning via VLMs. The system is designed to operate in both proactive fusion and prompted (supervisory) control modes, supporting varied modalities of human–AI teaming. The core data pathways and process flow are illustrated in the system overview.
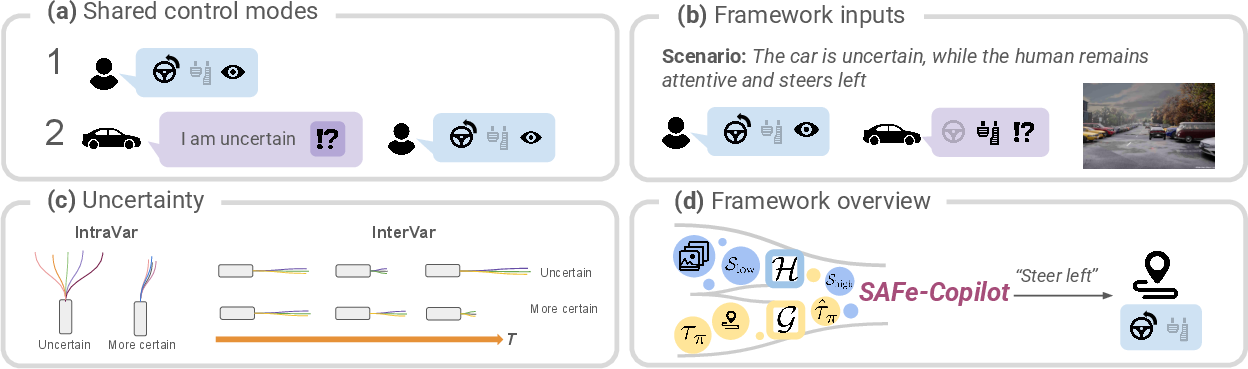
Figure 1: The framework supports both proactive and supervisory teaming modes, integrates multimodal and contextual cues, and performs symbolic arbitration between plans.
Abstraction Module
Continuous, low-level signals (throttle, brake, steering, kinematics) from both human and autonomy stacks are mapped to high-level semantic descriptors. Plans are categorized as stop, turn (left/right), drive forward, or slow down based on the net displacement and length of the candidate path. State descriptors bin control inputs and assign ordinal, textual labels, which, along with environment descriptors, produce language-ready symbolic state representations.
Thresholds for categorization (e.g., θstop,θturn,θfwd) are empirically set to ensure consistency across diverse driving situations.
Uncertainty Module
Planner confidence is estimated via convex combination of intra-frame and inter-frame trajectory variances. This quantifies, respectively, the spread of predicted actions at a time step, and the temporal volatility of the plan across consecutive frames:
ut=α+βα IntraVart+β InterVart
Where ut exceeding a confidence threshold triggers a request for human intervention or shifts arbitration strategy.
Reasoning (Arbitration) Module
This is the main locus of innovation. The module utilizes a VLM (here, ChatGPT o3-2025-04-16) prompted with image triplets and textual abstractions of both vehicle states and plans. The VLM performs multi-modal contextual reasoning to:
- Infer driver intent from combined actions and environment cues
- Analyze the consequences of both human and autonomy-generated plans in context
- Select or fuse plans, choosing pure human, pure autonomy, or an integrated high-level action that aligns with safety, intent, and context

Figure 2: Arbitration combines scene, human intent, uncertainty, and plan proposals to select the safest trajectory.
The VLM is exploited not only for visual semantic analysis but also for symbolic plan integration, enabling common-sense decision-making unattainable with purely hard-coded or low-level fusion approaches.
Empirical Evaluation
Experiments were conducted in the CARLA simulator using Bench2DriveZoo and VAD autonomous stacks, and were complemented by a human-subject survey for qualitative alignment with real-world driving preferences.
Qualitative and Scenario-based Demonstrations
SAFe-Copilot's reasoning module demonstrates inference of multi-modal driver intent, adaptation to rule-flexible human behaviors, and robust arbitration even in OOD and sensor-failure situations.

Figure 3: The system infers driver intent and fuses plans—in this scenario, by safely merging the intent to avoid an obstacle with surrounding traffic constraints.

Figure 4: Examples include yielding to emergency vehicles, overtaking construction zones, and handling sensor (glare) failure cases.
Qualitative studies reveal the VLM correctly contextualizes human interventions, handles societal norms (e.g., temporarily crossing solid lines for obstacle avoidance), and recognizes sensor limitations, deferring control accordingly.
Mock Human Arbitration
The arbitration policy was benchmarked against naive and decision-tree baselines using a "mock human" agent whose correctness was probabilistically varied. Notably, SAFe-Copilot achieved perfect recall—selecting the correct human plan when available—while maintaining substantially higher accuracy and precision than the naive baseline, and greater flexibility than decision-tree methods. The framework robustly rejected incorrect human behaviors, acting as a safety guardian rather than a passive controller.
Human Survey
A survey of 38 real drivers evaluated 40 driving scenarios. Key results:
Quantitative Benchmarks
Bench2Drive evaluation across 180 scenarios demonstrated:
- Collision rate reduced by 15.66%
- Route completion up by 13.22%
- Composite driving score increase of 27.96% over pure VAD autonomy
Improvements were most pronounced in OOD scenarios and rare edge cases (e.g., construction sites, stationary obstacles), where human input and semantic arbitration are critical.
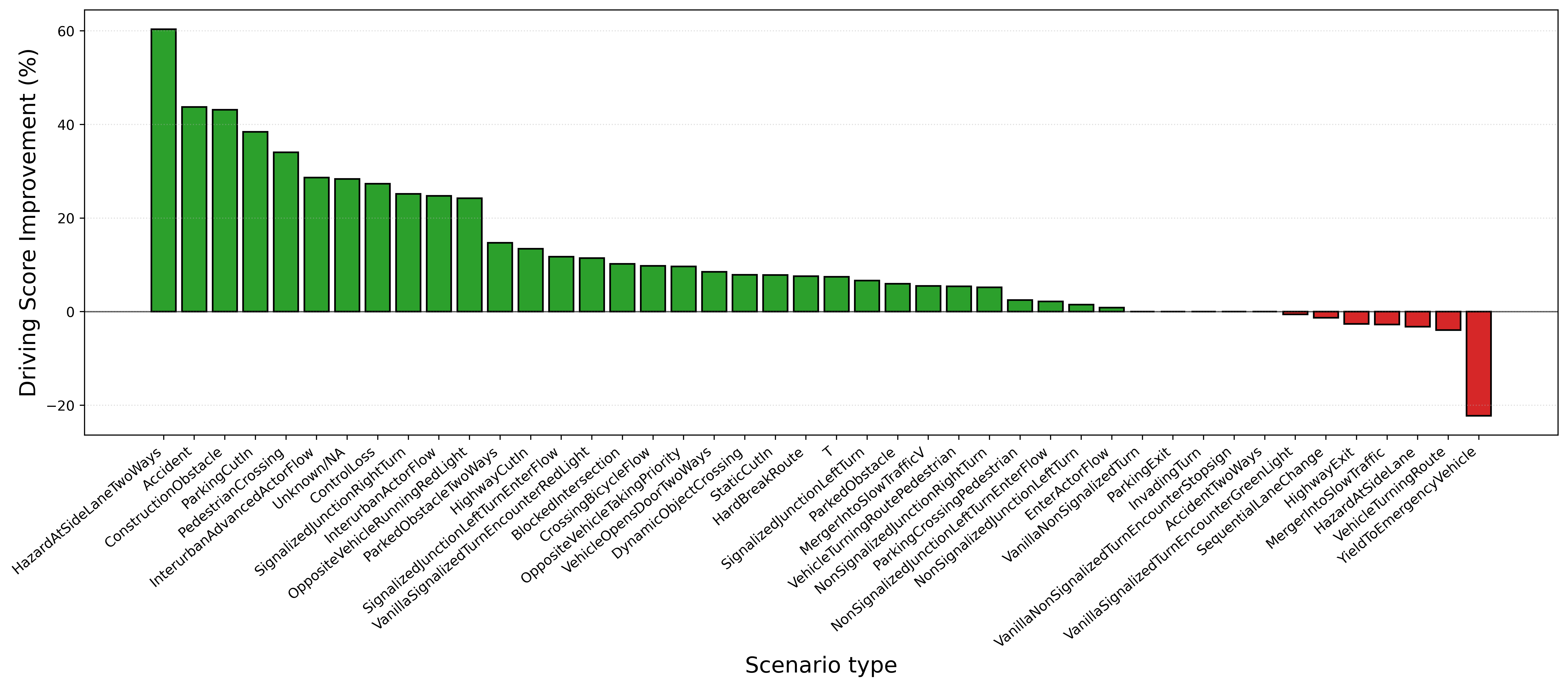
Figure 6: Scenario-wise improvements—shared autonomy substantially boosts driving scores, especially in challenging scenarios.

Figure 7: Bench2Drive qualitative examples illustrate shared autonomy resolving base policy indecision or unsafe maneuvers in OOD conditions.
Discussion and Implications
Semantic-level arbitration using VLM-based reasoning introduces a paradigm shift: Arbitration at the abstraction of driving intent, rather than low-level trajectory or control fusion, preserves the semantics of human input and aligns more closely with context-rich real-world driving. This approach is more robust to imperfect or context-flexible human interventions than rule-based or purely geometric fusion, and can flexibly relax or reinforce traffic rule adherence as dictated by scene context and safety considerations.
The framework’s modularity means it is readily extensible to incorporate richer state abstractions (e.g., attention, gaze, intention prediction) and additional sources of human or environmental input. Further, decoupling arbitration from specific planners ensures compatibility with a wide range of modern stack architectures, including foundation models and closed-loop neural policies.
On the practical front, the system demonstrated significant performance enhancements in simulated multi-agent driving tasks, especially in rare-event and OOD scenarios—a noted weakness for end-to-end autonomous policies. The survey results further suggest emerging social acceptability and trust in language-driven shared autonomy.
Limitations are primarily in the scale and domain of evaluation: Most experiments are simulator-based, and extended human-in-the-loop on-road testing remains an open problem. There is also scope for more sophisticated self-verification and plan introspection by the system itself.
Future Directions
Key avenues for advancement include:
- Integration of richer physiological and cognitive driver models into state abstraction
- Real-time deployment and closed-loop testing in physical or hybrid autonomy platforms
- Continual learning for improving symbolic abstraction and VLM prompts based on longitudinal user feedback
- Extension to multi-agent and interactive episodic scenarios (e.g., dense urban settings, mixed human/autonomy fleets)
Conclusion
SAFe-Copilot demonstrates that arbitration and fusion at the level of high-level semantic intent, mediated by VLM-based symbolic reasoning, can robustly combine the adaptability of human drivers with the reliability of autonomy. The framework’s superior empirical performance and high alignment with human preferences identify semantic arbitration as a promising design principle in shared autonomy. Broader application of this symbolic, language-driven arbitration paradigm could accelerate acceptance, adaptability, and safety in human–AI teaming for complex, non-deterministic domains such as autonomous driving.