Carousel: A High-Resolution Dataset for Multi-Target Automatic Image Cropping
Abstract: Automatic image cropping is a method for maximizing the human-perceived quality of cropped regions in photographs. Although several works have proposed techniques for producing singular crops, little work has addressed the problem of producing multiple, distinct crops with aesthetic appeal. In this paper, we motivate the problem with a discussion on modern social media applications, introduce a dataset of 277 relevant images and human labels, and evaluate the efficacy of several single-crop models with an image partitioning algorithm as a pre-processing step. The dataset is available at https://github.com/RafeLoya/carousel.


























Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What this paper is about
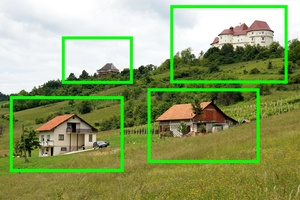
This paper introduces Carousel, a new set of 277 high‑resolution photos designed to help computers crop images in a way people find beautiful—not just once, but multiple times per photo. The idea is to make separate, good‑looking close‑ups of different interesting parts in the same picture (like several faces in a group photo or different landmarks in a wide landscape), so social media viewers can swipe through them like zooming into the original high‑quality image.
The big questions the paper asks
- How can we automatically make several separate, nice‑looking crops from one photo, each focusing on a different interesting area?
- Do existing “single‑crop” methods work if we prepare the image in a smart way?
- What kind of data (photos and labels) do researchers need to build and test multi‑crop methods?
How the researchers approached it
The authors did three main things:
- Built a high‑resolution dataset:
- They collected 277 large images (average size about 10.58 megapixels) from open sources like Wikimedia Commons and Flickr.
- Human experts marked the best crops for each image, focusing on more than one “salient region” (the parts of a photo that naturally grab your attention).
- They used fixed aspect ratios: 2:3 for landscape and 3:2 for portrait. An “aspect ratio” is the shape of the rectangle (width:height), like how phone screens or photo prints have standard shapes.
- Each crop is a “bounding box,” which is just a rectangle drawn around the interesting area.
- Prepared images so single‑crop models could try multiple crops:
- Existing models are built to find one best crop, so if you ask them for more, their suggestions often overlap and focus on the same subject.
- To fix this, the authors “partitioned” each image into separate zones before cropping. Think of slicing a pizza into regions so each slice contains a different topping you care about.
- They used a “saliency” tool called U²‑Net to highlight important regions (like faces, animals, or buildings). Using those highlights, the partitioning algorithm separated the photo into non‑overlapping sub‑images so each one could be cropped independently.
- Measured performance with an easy‑to‑understand score:
- They used Intersection over Union (IoU), a common measure of how much two rectangles overlap. Imagine two transparent rectangles: the IoU is the area where they overlap divided by the area covered by either one of them.
- Because each photo can have multiple ground truths and multiple predictions, they defined “Top‑k IoU” (kIoU). This matches each predicted crop to the best ground‑truth crop without reusing the same rectangle twice, then averages the scores. They reported kIoU at different strictness levels (like passing grades at 50% overlap up to 95%).
They tested several well‑known cropping models:
- VPN (View Proposal Network) and VEN (View Evaluation Network)
- A2‑RL (Aesthetics‑Aware Reinforcement Learning)
- GAICv2 (a fast grid‑based crop selector)
What they found and why it matters
- Partitioning helps a lot: When they first split images into separate regions, single‑crop models did a much better job making multiple distinct crops.
- GAICv2 performed best among the tested models after partitioning.
- Without partitioning, VPN’s multi‑view suggestions overlapped too much and missed secondary subjects.
- Not perfect yet: For 45 out of 277 images, the partitioning failed (for example, when ideal crops had mixed directions or when subjects were very uneven in size), so those were excluded from the main evaluation. These tricky cases show that simply partitioning isn’t always enough.
Why this is important:
- Social media sites often shrink photos to save space (e.g., Instagram caps width at 1080 pixels). High‑resolution photos lose detail when downscaled.
- Multi‑target cropping lets creators post a swipeable set of zoomed‑in, well‑composed images, bringing back the rich detail that gets lost at upload.
The takeaway and future impact
Carousel gives researchers a high‑quality, human‑labeled dataset to build better multi‑crop tools. The study shows that smart pre‑processing (partitioning) can make existing single‑crop models useful for multi‑target cropping, but it’s not a complete solution.
What’s next:
- Create new models that directly produce several non‑overlapping, beautiful crops from the full image—without needing a partitioning step.
- Automatically figure out how many crops () a photo should have.
- Expand the dataset with more types of scenes and more aspect ratios.
If these improvements happen, people sharing photos could easily offer viewers swipeable, detailed views of different parts of a high‑resolution image—keeping the beauty and clarity that often gets lost online.
Dataset link: https://github.com/RafeLoya/carousel
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise list of concrete gaps and unresolved questions that the paper leaves open, intended to guide future research.
- End-to-end multi-target cropping: No model is proposed that directly outputs multiple distinct crops from a full-resolution image; current evaluation relies on a saliency-based partitioning pre-processing step.
- Automatic determination of k: The number of target crops () is provided as metadata, but no method is proposed or evaluated to infer automatically from the image content.
- Partitioning assumptions and failure modes: The partitioning algorithm assumes a single global partition orientation and uses heuristic thresholds; it fails when ground-truth crops overlap substantially in both axes or when subject sizes are highly disparate. Robust strategies for mixed orientations, uneven subject sizes, and occlusions are not explored.
- Saliency backbone suitability: The approach relies on U²-Net saliency maps trained for generic saliency, not aesthetics or multi-subject composition. The comparative impact of using instance segmentation, object detectors, or aesthetics-aware saliency models on partition quality is untested.
- Hyperparameter transparency and reproducibility: The dynamic saliency thresholding and smallest-valid-box selection used during partitioning are not fully specified (e.g., threshold schedule, validity constraints), hindering reproducibility and ablation.
- Handling partition failures: 45/277 images were omitted from quantitative evaluation due to partition failures. Methods to recover or adaptively redesign partitions to handle these cases (e.g., iterative refinement, constraint optimization, or graph cuts) are not presented.
- Dataset scale: The dataset size (277 images) is too small to train modern deep models; guidance on recommended train/val/test splits or augmentation strategies for benchmarking and training is absent.
- Selection bias and coverage: Sourcing criteria (open licenses, “high aesthetic quality”, at least two salient regions) may bias content and neglect everyday social media scenes (e.g., low-light, cluttered, selfies). Category distributions and scene diversity statistics are not provided.
- Licensing constraints: Images are non-commercially licensed; implications for adoption by industry, dataset redistribution, and model release policies are not discussed.
- Annotation protocol details: The number of annotators per image, their expertise levels, annotation guidelines, and inter-annotator agreement are not reported, leaving the subjectivity and consistency of “ideal compositions” unquantified.
- Limited aspect ratios: Ground truths are restricted to 2:3 (landscape) and 3:2 (portrait). Common social platform formats (e.g., 1:1, 4:5, 16:9, 9:16) are missing, limiting ecological validity and downstream utility.
- Bounding boxes vs. composition masks: Labels are bounding boxes; no segmentation masks or compositional cues (e.g., leading lines, horizon alignment, subject pose) are captured. The gap between box overlap (IoU) and actual aesthetic quality is unaddressed.
- Aesthetic evaluation metrics: Evaluation uses IoU ([email protected] and [email protected]:0.95), which measures spatial overlap but not composition quality, crop diversity, subject emphasis, or human preference. Human studies or learned aesthetic scorers for multi-crop assessment are absent.
- Diversity and non-overlap constraints: There is no metric to quantify the diversity or non-redundancy of multi-target crops (e.g., coverage of distinct subjects, minimal overlap, complementary viewpoints).
- Baseline breadth and tuning: Only single-target cropping models (VPN, VEN, A2-RL, GAICv2) are evaluated; no multi-view diversity methods, detection+composition hybrids, or recent ranking architectures are benchmarked. Model fine-tuning on Carousel and sensitivity analyses are missing.
- Runtime and scalability: Computational cost, memory usage, and inference time for partitioning and cropping on high-resolution inputs are not measured, leaving practical feasibility on user devices unexplored.
- Robustness to downscaling: The paper motivates high-resolution sources vs. social platform downscaling but does not test how models perform under platform constraints (e.g., 1080 px width), nor whether multi-crops remain compelling after platform compression.
- Sequence design for user experience: How to order crops in a “carousel” for optimal user experience (e.g., importance-first, spatial sweep, storytelling) is unexamined; no behavioral/user studies assess engagement or preference.
- Ambiguity in “distinct subjects”: The operational definition and decision criteria for “distinct salient regions” are not formalized, making k and ground-truth choices potentially inconsistent across images.
- Generalization beyond images: Extension to video (multi-target cropping across time), burst photos, or panoramas with extreme aspect ratios is not explored; temporal coherence and crop tracking remain open.
- Cross-cultural and task-specific aesthetics: Variation in aesthetic preferences across cultures, contexts, and platforms is unaddressed; no stratified analyses or domain adaptation strategies are discussed.
- Benchmark protocol: A standardized evaluation protocol (splits, metrics beyond IoU, baselines, code) for multi-target cropping on Carousel is not fully specified, which may hinder fair and reproducible comparisons.
- Failure-case characterization: While some failure modes are shown qualitatively, a quantitative taxonomy linking image attributes (e.g., subject count, size variance, overlap) to partitioning/model errors is missing, limiting targeted method development.
- Integration of compositional priors: How photographic rules (rule of thirds, leading lines, balance) can be encoded in multi-crop generation and scoring—especially to avoid purely saliency-driven crops—is not investigated.
- Learning to partition: No learned partitioner is explored; opportunities to train a partitioning network end-to-end with multi-crop objectives or to jointly optimize partitions and crop boxes are open.
- Multi-output calibration: Methods to ensure each crop is individually aesthetically strong while jointly covering distinct content (e.g., multi-objective optimization, Pareto fronts) are not considered.
- Data augmentation and synthetic generation: Techniques to expand the dataset via synthetic multi-subject scenes, compositional augmentations, or generative approaches are not discussed.
Practical Applications
Overview
The paper introduces Carousel, a high-resolution dataset (277 images, average 10.58 MP) with human-labeled, multiple distinct aesthetic crops, designed to advance multi-target automatic image cropping. It also proposes an evaluation pipeline that adapts single-target cropping models to multi-target use via a saliency-based partitioning pre-processing step, and defines Top-k IoU (kIoU) metrics for fair multi-crop evaluation. Below are practical applications derived from these findings, methods, and innovations.
Immediate Applications
- Multi-crop carousel generation for social platforms (software, media/entertainment)
- Automatically produce swipeable, non-overlapping crops from a single high-res upload to emulate “zoom-in” viewing without increasing platform bandwidth; integrate server-side or client-side as a pre-publish feature.
- Tools/workflow: U²-Net saliency → Hamara et al. multi-region partitioning → GAICv2 (or VEN/A2-RL) per partition → assemble ordered carousel.
- Dependencies/assumptions: Requires high-resolution source images; accurate saliency partitioning; k (number of crops) known or user-specified; platform support for multi-image posts/carousels; aesthetic criteria compatible with target audience.
- Photo gallery “Auto Highlights: Multi-View” (consumer apps, daily life)
- On-device or app-based feature that suggests multiple distinct crops for a single photo: per-person crops in group photos, details in landscapes/panoramas, pets/objects in candid shots.
- Tools/workflow: Local inference pipeline using pre-trained GAICv2 + partitioning; optional user override for k and aspect ratio (2:3 landscape, 3:2 portrait).
- Dependencies/assumptions: Sufficient mobile compute or batching; user opt-in to automated aesthetic choices; limited aspect ratios per dataset labeling.
- Editorial and CMS asset generation (newsrooms, digital publishing, marketing)
- Automate multi-subject thumbnail and social-card generation from one image (e.g., separate crops for speaker, audience, scene detail); reduce manual design time.
- Tools/workflow: CMS plugin/API that ingests images, runs partitioning + cropping, exports crops mapped to channel-specific templates.
- Dependencies/assumptions: Editorial guidelines for what constitutes “salient”; non-overlap constraints compatible with design; QA checkpoints to catch failure cases.
- E-commerce and marketplace listing enhancement (retail/e-commerce)
- Generate distinct crops highlighting product features/accessories from a single catalog image; build richer galleries without reshoots.
- Tools/workflow: Batch pipeline in DAM (Digital Asset Management) systems; saliency partitioning to ensure each feature gets a dedicated crop.
- Dependencies/assumptions: Saliency correlates with product-relevant detail (may need domain-tuned saliency models); aspect ratio requirements per platform.
- Real estate and travel platforms (real estate, travel)
- From panoramas or room shots, produce crops focusing on distinct amenities (fixtures, views, layout zones); improve listing clarity.
- Tools/workflow: Partitioning + GAICv2; export to slideshow/carousel formats.
- Dependencies/assumptions: Saliency maps must surface structural features; human QA for edge cases (occlusions, reflections).
- Academic benchmarking and method development (academia/computer vision)
- Use Carousel to benchmark multi-target cropping, adopt kIoU metrics, and stress-test adaptations of single-view models.
- Tools/workflow: Public dataset and code; comparative evaluation across IoU thresholds ([email protected] and [email protected]:0.95).
- Dependencies/assumptions: Community acceptance of kIoU matching protocol; recognition of dataset’s resolution advantage and multi-subject focus.
- Creative tooling and plugins (software/content creation)
- Lightroom/Photoshop/GIMP plugins to auto-suggest distinct crops for print layouts, web banners, and social variants.
- Tools/workflow: Plugin wraps saliency partitioning + crop ranking; UI to approve/reorder crops.
- Dependencies/assumptions: Licensing compatibility; plugin performance on large images.
- Profile photo extraction from group shots (consumer apps, daily life)
- Auto-crop per-person portraits from group photos for contact images or social profiles, ensuring non-overlap and aesthetics.
- Tools/workflow: Face-aware saliency → partitioning → crop finalization with portrait aspect ratios.
- Dependencies/assumptions: Reliable person/face detection; consent and privacy settings; portrait ratios beyond 3:2 as needed.
- Standards and evaluation adoption (academia/industry)
- Adopt the Top-k IoU (kIoU) protocol for multi-crop evaluation and reporting; improve comparability across models.
- Tools/workflow: Integrate kIoU matching and threshold sweeps in CI pipelines for vision models.
- Dependencies/assumptions: Agreement on matching procedure and thresholds; datasets with multiple GT crops.
Long-Term Applications
- End-to-end multi-target crop models (software/AI)
- Train models that directly output multiple distinct, aesthetically optimized crops and automatically predict k, removing reliance on pre-partitioning.
- Tools/workflow: Model architectures with multi-head outputs, diversity/coverage constraints, and disjointness penalties; extended Carousel with more categories and aspect ratios.
- Dependencies/assumptions: Larger, diversified datasets; improved training objectives for aesthetic diversity; efficient inference at high resolution.
- Adaptive “zoomable” feeds with bandwidth-aware delivery (media/streaming)
- Platforms deliver selected crops instead of full-image downscales; personalize which crops to show based on user interactions (hover/scroll/engagement signals).
- Tools/workflow: Telemetry-driven crop selection; integration with CDN edge logic; ties to adaptive streaming stacks.
- Dependencies/assumptions: Policy changes to content pipelines; data privacy for user interaction signals; robust crop selection under real-time constraints.
- Multi-target video cropping for highlights and education (broadcast, sports, e-learning)
- Extend to video: generate parallel crops focusing on different players, instruments, board regions, or key details; enable multi-view learning materials (e.g., lab demos, lectures).
- Tools/workflow: Temporal saliency + multi-view tracking; kIoU-like metrics for video; synchronized multi-pane players.
- Dependencies/assumptions: Stable saliency across frames; computational budgets; UI for multi-view playback.
- Domain-specific multi-ROI aesthetics (cultural heritage, museums, archives)
- High-res artwork or artifact imagery with automatic crops on motifs, inscriptions, restorations to support exploration and accessibility.
- Tools/workflow: Curator-in-the-loop crop validation; metadata tagging; interactive viewers.
- Dependencies/assumptions: Domain-tuned saliency (not only generic); careful handling of cultural sensitivity.
- Automated layout engines for print/photo books (printing, design)
- Systems assemble multi-crop layouts across pages, maintaining aesthetic principles (rule of thirds, balance) and narrative continuity.
- Tools/workflow: Layout optimization with crop sets; template libraries; constraint solvers for visual balance across spreads.
- Dependencies/assumptions: Broader aspect ratio support; user style profiles; high-res source access.
- Personalization and taste modeling (software/AI)
- Learn user aesthetic preferences to tailor crop selection (e.g., symmetry vs. leading lines bias) and count k per image dynamically.
- Tools/workflow: Preference learning from edit history; lightweight on-device models; feedback loops.
- Dependencies/assumptions: Sufficient user data; privacy-preserving personalization; explainability of aesthetic choices.
- Policy and platform guidelines for aesthetic cropping (policy/industry)
- Develop guidelines to reduce bias (e.g., overemphasis on certain subjects like faces), ensure transparency, and respect privacy in automated cropping.
- Tools/workflow: Auditing tools; bias detection dashboards; opt-out mechanisms.
- Dependencies/assumptions: Cross-stakeholder consensus; regulatory compliance; user control UX.
- Edge/offline multi-crop pipelines (systems/edge computing)
- On-device cropping reduces cloud costs and latency; suitable for low-connectivity scenarios and privacy-sensitive workflows.
- Tools/workflow: Model compression and quantization; energy-aware saliency estimation; batched processing for albums.
- Dependencies/assumptions: Efficient models at high resolution; hardware acceleration; battery and thermal constraints.
- Expanded dataset ecosystem and benchmarks (academia/industry)
- Larger, more diverse, multi-aspect-ratio datasets with difficult scenes (overlapping saliency, extreme aspect ratios) to spur robust multi-target methods.
- Tools/workflow: Community contributions; standardized annotation tools with fixed aspect ratio modes; shared leaderboards using kIoU and diversity metrics.
- Dependencies/assumptions: Sustainable licensing (open/non-commercial); annotator training for aesthetic consistency; funding and maintenance.
- Cross-domain variants (cautious extension; healthcare, industrial inspection)
- With domain-specific saliency models and non-aesthetic criteria, multi-ROI cropping could support rapid overview of multiple findings/defects from a single high-res image.
- Tools/workflow: Saliency tuned to clinical or inspection signals; strict QA pipelines; human-in-the-loop review.
- Dependencies/assumptions: Domain validation; regulatory standards; avoidance of aesthetic heuristics for safety-critical contexts.
Glossary
- A2-RL: Aesthetics Aware Reinforcement Learning; a reinforcement learning framework that sequentially adjusts a crop to maximize aesthetic quality. "The Aesthetics Aware Reinforcement Learning (A2-RL) framework \cite{a2rl} put forth by Li et al. takes a sequential decision-making approach, where the cropping agent progressively transforms the cropping window through a series of actions until it takes a termination action."
- Aesthetic image cropping: Automatic cropping aimed at human-perceived aesthetic quality rather than task-specific accuracy. "Automatic (or ``aesthetic'') image cropping, on the other hand, is aimed toward human vision \cite{ava, aadb}."
- Anchoring mechanism: A proposal strategy that selects initial crop anchors before refining them via regression. "The model of Jia et al. \cite{jia_rethinking_2022} also uses an anchoring mechanism to suggest a variety of starting crop regions, then regresses those suggestions to produce aesthetically high-quality crops."
- Aspect ratio: The proportional relationship between image width and height. "For this work, we limited our annotations to the 2:3 and 3:2 aspect ratios for landscape and portrait orientations, respectively."
- Bounding box: A rectangular region specified by coordinates that encloses a subject or crop area. "After this reviewing process, the images were annotated with ground truth bounding box labels."
- Candidate windows: The set of possible crop regions considered by a model before selection. "It outperforms prior weakly-supervised methods with fewer candidate windows, while having faster inference times."
- Confidence rankings: The ordered list of model proposals by their predicted confidence. "Wei et al. introduced the View Proposal Network (VPN) \cite{wei_good_2018}, which can produce multiple view suggestions with confidence rankings."
- Confidence scores: Numerical values indicating the model’s certainty about a predicted crop. "Whereas many models will evaluate IoU only for the crop with the highest confidence, the A2-RL model does not provide confidence scores."
- Content preservation: Ensuring important image content remains within the crop. "This is done through a grid anchor-based approach which considers key aspects such as aspect ratio and content preservation."
- GAICv2: A grid-anchor-based aesthetic cropping model that reduces candidate crops while improving speed and accuracy. "Compared to VPN, the GAICv2 model \cite{zeng_grid_2020} reduces the number of candidate crops tenfold."
- Greedy bipartite matching: A heuristic pairing process that iteratively selects the highest-scoring unmatched prediction-ground truth pair. "Finally, we perform greedy bipartite matching, prioritizing the pair with the highest IoU score; once a pair is matched, both bounding boxes are removed from further consideration."
- Ground truth: The human-annotated reference labels used for evaluation. "Each image is distributed with a corresponding JSON file containing the ground truth labels and JSON file containing the image metadata (such as the source URL and copyright information)."
- Intersection Over Union (IoU): A metric measuring overlap between predicted and ground-truth bounding boxes, defined as intersection area divided by union area. "A common metric in the cropping literature is the Intersection Over Union (IoU), which is given by the spatial area where two bounding boxes overlap (intersection), divided by the total area of the image they cover (union)."
- kIoU (Top-k IoU): The average IoU after matching up to k predicted crops with k ground-truth crops per image. "Therefore, we define the metric Top- IoU (or ``kIoU'') and our evaluation methodology as follows."
- Multi-region saliency partitioning: An algorithm that segments an image into non-overlapping regions based on saliency for fair multi-crop evaluation. "To partition input images into distinct subregions, we leverage the multi-region saliency partitioning algorithm introduced by Hamara et al. \cite{2025croppingalgorithm}."
- Multi-target automatic image cropping: The task of producing multiple distinct, aesthetically pleasing crops from a single image, each focusing on a salient region. "Inspired by this interactive zoom, we propose multi-target automatic image cropping."
- Multiscale labels: Crop annotations provided at multiple scales or aspect ratios to capture variability. "Several datasets have been released for single-view image cropping. Recent works have emphasized multiscale labels for each crop region, typically by providing several aspect ratios (e.g., 2:3, 5:7, etc.) or providing similar crops from a number of human annotators."
- Partition orientation: The choice of vertical or horizontal partitioning of an image based on spatial variance of subject locations. "Our implementation enhances \cite{2025croppingalgorithm} by determining the partition orientation from the variance in the x and y positions of the bounding boxes."
- Saliency maps: Pixel-level maps highlighting visually important regions used to guide partitioning and crops. "We utilized U\textsuperscript{2}-Net \cite{u2net} to generate saliency maps, which are then used for partitioning."
- Saliency threshold: A cutoff on saliency values used to select valid regions for cropping. "In each iteration (determined by k, the number of target crops), we select the smallest valid bounding box that meets a dynamically updated saliency threshold."
- Sequential decision-making approach: A reinforcement learning strategy where an agent makes a series of actions to optimize an objective. "The Aesthetics Aware Reinforcement Learning (A2-RL) framework \cite{a2rl} put forth by Li et al. takes a sequential decision-making approach, where the cropping agent progressively transforms the cropping window through a series of actions until it takes a termination action."
- Semi-automatic image cropping: A cropping method that requires user input to select the subject before automatic refinement. "In this way, it may be considered a form of semi-automatic image cropping."
- Teacher model: A higher-performing model used to guide or supervise the training of another model (student). "Also utilized by Wei et al., the View Evaluation Network (VEN) \cite{wei_good_2018} served as a teacher model for VPN due to its superior accuracy across multiple benchmarks."
- Termination action: The action that stops the reinforcement learning agent’s cropping process. "until it takes a termination action."
- U2-Net: A deep neural network architecture for saliency detection used to generate saliency maps. "We utilized U\textsuperscript{2}-Net \cite{u2net} to generate saliency maps, which are then used for partitioning."
- Variance: A statistical measure of spread used here to decide how to orient partitions. "determining the partition orientation from the variance in the x and y positions of the bounding boxes."
- VEN (View Evaluation Network): An aesthetic evaluation model used as a teacher due to its strong accuracy. "The Aesthetics Aware Reinforcement Learning (A2-RL) framework \cite{a2rl} put forth by Li et al. takes a sequential decision-making approach, where the cropping agent progressively transforms the cropping window through a series of actions until it takes a termination action." [Use also:] "the View Evaluation Network (VEN) \cite{wei_good_2018} served as a teacher model for VPN due to its superior accuracy across multiple benchmarks."
- VPN (View Proposal Network): A model that proposes multiple candidate crops with confidence rankings. "Wei et al. introduced the View Proposal Network (VPN) \cite{wei_good_2018}, which can produce multiple view suggestions with confidence rankings."
Collections
Sign up for free to add this paper to one or more collections.