- The paper proposes Scale SAE that deploys multiple expert activation to reduce feature redundancy and enhance specialization.
- It introduces a feature scaling mechanism inspired by high-pass filtering to amplify essential high-frequency components.
- Experiments on GPT-2 activations demonstrate improved reconstruction error and feature diversity over traditional sparse autoencoders.
Beyond Redundancy: Diverse and Specialized Multi-Expert Sparse Autoencoder
Introduction
The paper "Beyond Redundancy: Diverse and Specialized Multi-Expert Sparse Autoencoder" introduces a strategy to improve the interpretability and computational efficiency of Sparse Autoencoders (SAEs) in analyzing LLMs. SAEs have faced limitations due to non-specialized learning within Mixture of Experts (MoE) architectures, resulting in feature redundancy. This paper proposes a novel architecture called Scale Sparse Autoencoder (Scale SAE) that integrates Multiple Expert Activation and Feature Scaling to enhance specialization and diversity.
Methodology
Scale Sparse Autoencoder Architecture
Scale SAE consists of two synergistic mechanisms designed to address specialization and feature redundancy challenges inherent in MoE. The Multiple Expert Activation engages subsets of experts dynamically, helping to decompose polysemantic neuron activations into distinct semantic components across experts. Conversely, Feature Scaling adaptively enhances the high-frequency components of encoder features, encouraging diversity and reducing redundancy.
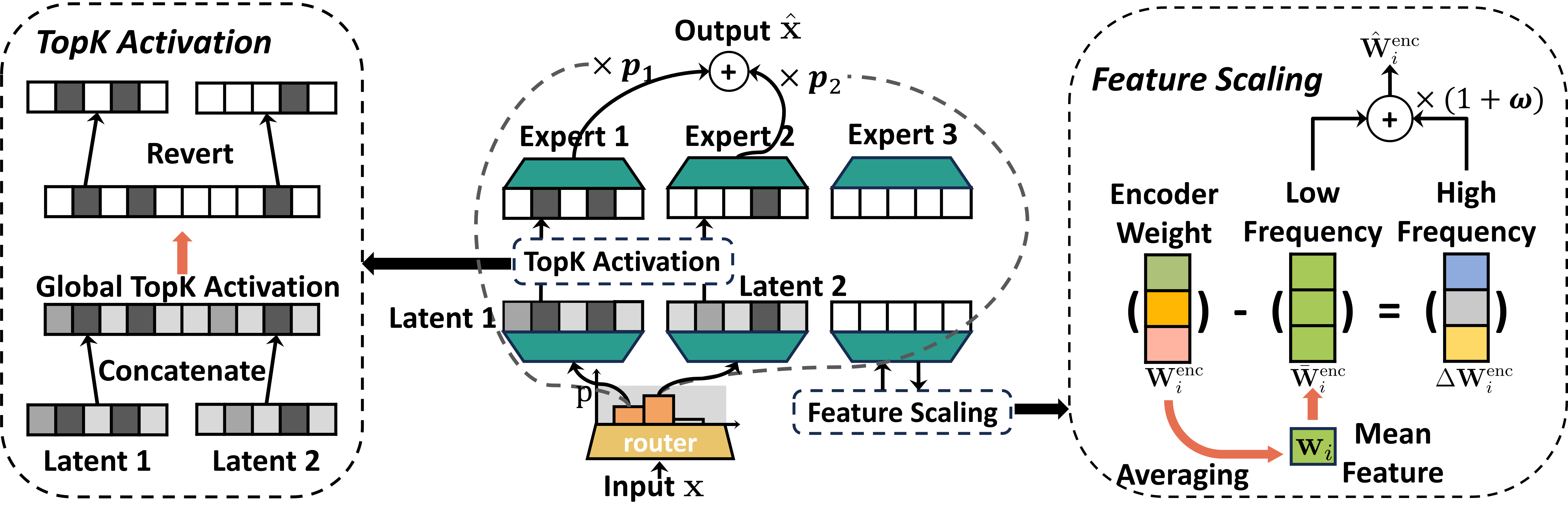
Figure 1: Scale Sparse Autoencoder Architecture. An illustration of the three core mechanisms in the Scale SAE architecture. (a) Multiple Expert Activation. A router selects a subset of experts (e.g., 2 out of 3 shown) to process each input. (b) Global Top-K Activation. The activations from the selected experts are aggregated, and a global Top-K operation (K=3 shown) is applied to enforce sparsity. (c) Feature Scaling. The encoder weights of each expert are decomposed and scaled to dynamically amplify high-frequency components.
Multiple Expert Activation
Switch SAE's limitation, rooted in activating a single expert, leads to high feature redundancy. The Scale SAE modifies the routing mechanism to activate multiple experts, thereby encouraging structured specialization and distinct domain sensitivity.
Feature Scaling
An activation collapse challenge is mitigated through Feature Scaling, inspired by high-pass filtering in signal processing. This mechanism amplifies high-frequency components, aimed at preserving fine-grained information and reducing redundancy.
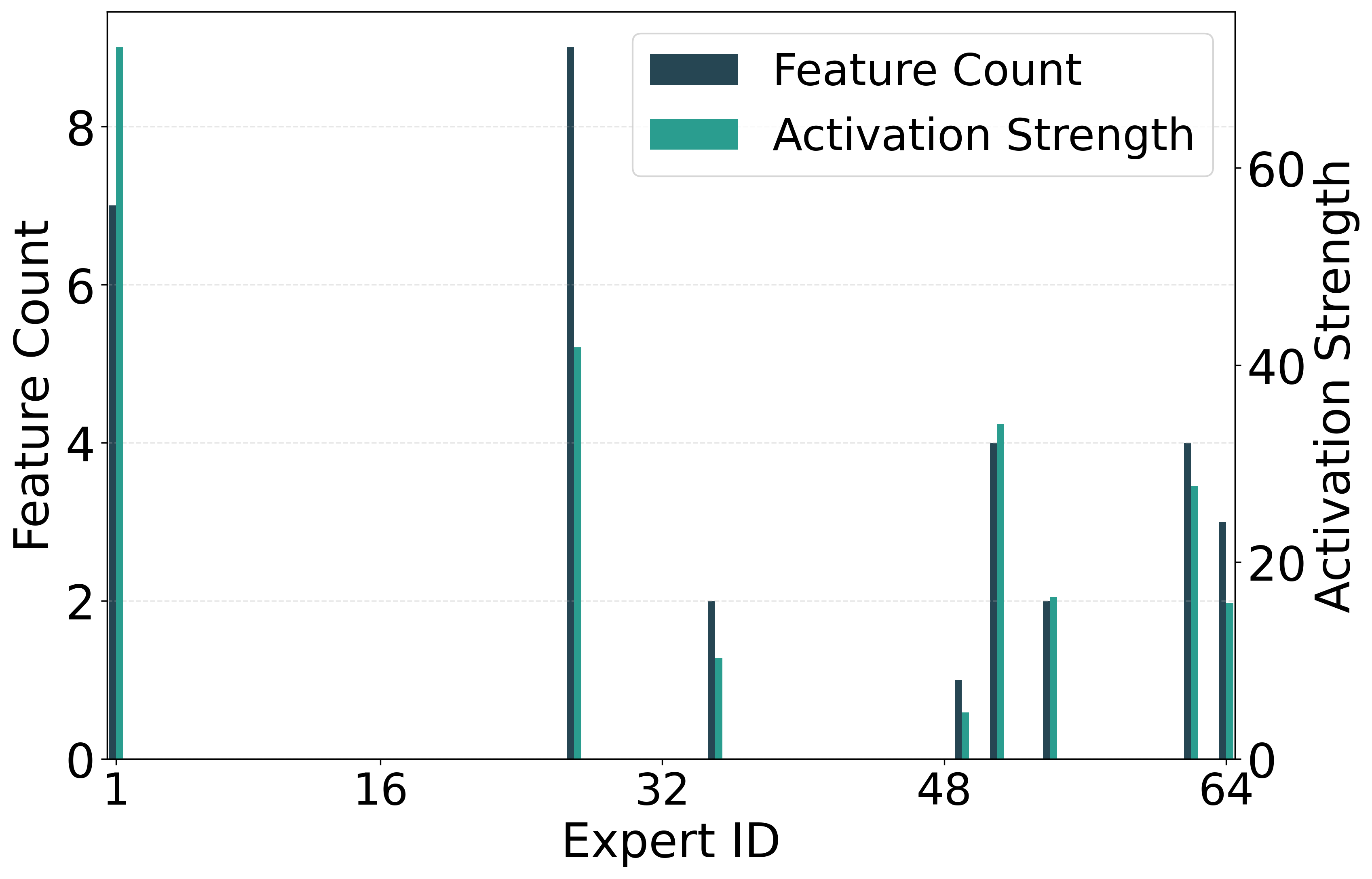
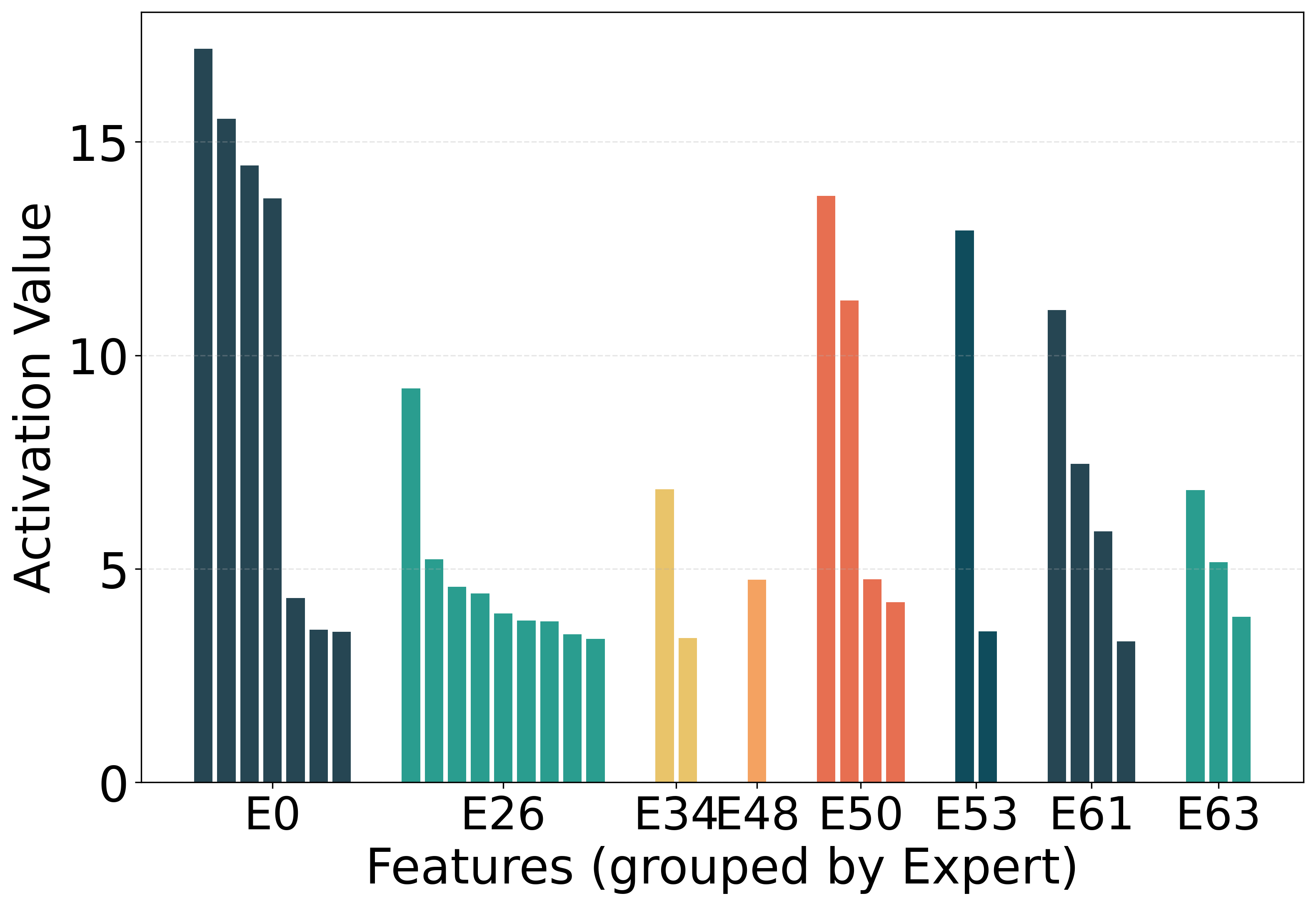
Figure 2: The intensity of different experts being activated.
Experiment
The architecture was rigorously tested on the intermediate layer activations of GPT-2, revealing that Scale SAE consistently outperformed traditional SAEs like Switch SAE, in terms of reconstruction error reduction and feature similarity scores.
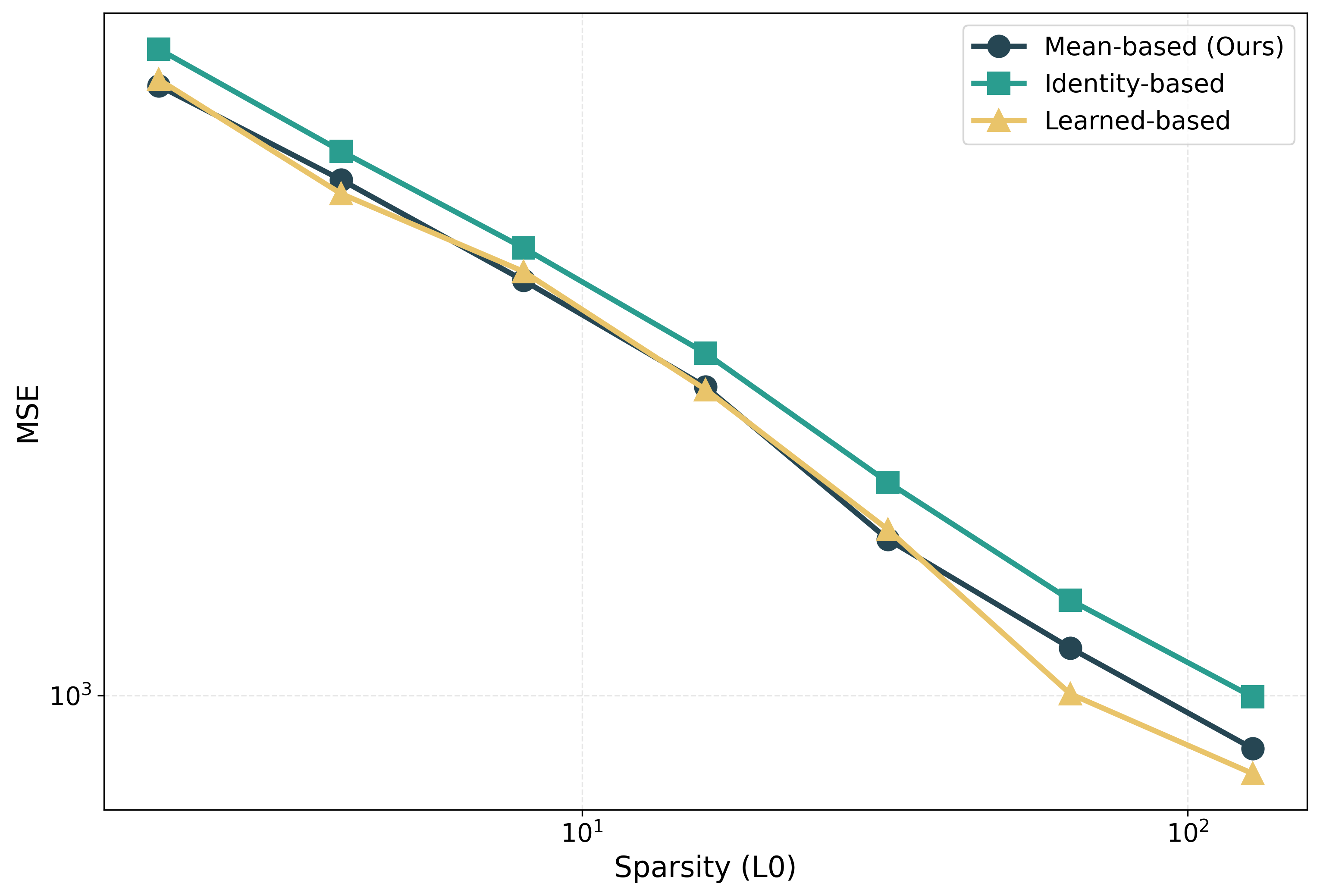
Figure 3: Performance comparison of the three feature decomposition strategies across a range of sparsity levels.
Implications and Future Directions
This research bridges the gap in LLM interpretability and efficiency, presenting a framework that potentially could refine model evaluations in future experiments. While current results are robust, future advancements may incorporate more sophisticated routing or scaling mechanisms to enhance specialization further.
Conclusion
Scale SAE represents a significant advancement in MoE architectures, not through radical changes but through effective utilization of multi-expert activation and feature scaling to resolve feature redundancy issues. The proposed framework promises enhancements in computational efficiency and interpretability, facilitating more insightful analysis of LLMs without compromising efficacy.