- The paper reveals that adversarial man-in-the-middle attacks degrade LLM factual recall by injecting misleading instructions and noise into input queries.
- The paper employs a Random Forest-based defense mechanism using uncertainty metrics, such as entropy and perplexity, to distinguish manipulated query responses.
- The paper's experiments across varying LLM sizes and datasets highlight that larger models like GPT-4 are more prone to these attacks, emphasizing the need for robust safeguards.
Injecting Falsehoods: Adversarial Man-in-the-Middle Attacks Undermining Factual Recall in LLMs
Introduction
The paper "Injecting Falsehoods: Adversarial Man-in-the-Middle Attacks Undermining Factual Recall in LLMs" (2511.05919) investigates the vulnerability of LLMs to adversarial attacks in information retrieval applications. Given the regulatory emphasis on AI system robustness, the analysis of LLMs as intermediaries in information delivery becomes critical, particularly in light of possible adversarial manipulations by man-in-the-middle (MitM) attacks. This study introduces a theory-grounded MitM framework, highlighting LLM susceptibility to instruction-based adversarial attacks, and suggests a simple Random Forest-based defense mechanism leveraging uncertainty metrics.
Methodology
Three prominent attacks, α, β, and γ, form the basis of the proposed .TheseattacksmanipulateuserqueriesbeforeprocessingbyLLMs,targetingfactualmitigationinclosed−booksettings.MitMattacksaremanifestedbyperturbingfactualcontextswitheitherzero−shotinstructionadditionsornoise,absentdirectinterferencewithLLMinnerworkings.</p><p><strong>Attack\alpha:</strong></p><p>Aninstruction−basedattackappendsmisleadingdirectivestouserqueries,significantlydecreasingaccuracybyleadingLLMstoprovideincorrectanswers.</p><p><strong>Attack\beta andγ:
These fact-aware attacks involve the insertion of semantically or syntactically incorrect or irrelevant factual contexts, relying on manipulating historical factual memory. Additionally, they exploit internal fact storage and generation discrepancies (Figures 5 and 6).
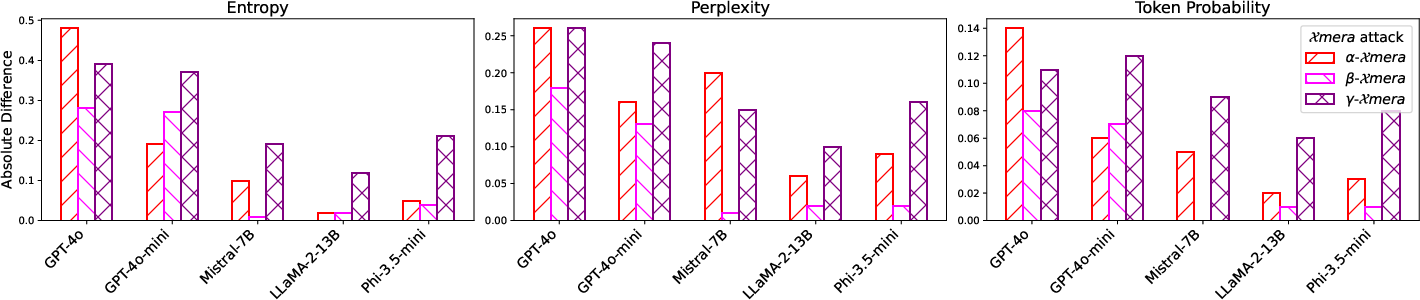
Figure 1: Differences in uncertainty between correct and incorrect answers against attacks.</p></p><h3class=′paper−heading′id=′experimental−evaluation′>ExperimentalEvaluation</h3><p>ComprehensiveevaluationacrossvariousLLMparadigmsanddatasets,includingTriviaQA,HotpotQA,andNaturalQuestions,demonstratesaccuracydegradation.LargerLLMslike<ahref="https://www.emergentmind.com/topics/llm−judge−gpt−4o"title=""rel="nofollow"data−turbo="false"class="assistant−link"x−datax−tooltip.raw="">GPT−4o</a>aresubstantiallyimpactedby\alphaduetoapredispositionforinstructionadherence.Incontrast,smallermodelsexhibitvariabilityinattackresilience,underscoringsizeandmethodologicalinfluenceonattacksusceptibility(Figure2).<imgsrc="https://emergentmind−storage−cdn−c7atfsgud9cecchk.z01.azurefd.net/paper−images/2511−05919/aucrocallmodels.png"alt="Figure2"title=""class="markdown−image"loading="lazy"><pclass="figure−caption">Figure2:AUC−ROCperformanceforallclassifiersontheuncertaintylevelsofresponsesfromdifferentLLMs.</p></p><h3class=′paper−heading′id=′discussion′>Discussion</h3><p>Nuanceddifferencesinuncertaintymetrics,notablyentropyandperplexity,underscorediscerniblediscrepanciesbetweencorrectandincorrectresponsegeneration.Bytrainingclassifiersontheseuncertaintyprofiles,enduserscanbealertedofpossiblequeryinterceptionandalteration.Yet,substantialgranularitiespersistindetectionaccuracyacrossmodels,withparticulardifficultyincollectivelydetecting\alpha,\beta,and without differentiated vulnerability metrics.
Conclusion
This study outlines the latent vulnerabilities of LLMs to MitM adversarial attacks, emphasizing the necessity for augmented cybersecurity measures within AI information retrieval applications. Future research should explore sophisticated adversarial methods and defense mechanisms beyond basic uncertainty alerts, ensuring broader applicability and scalability in real-world settings. Ensuring the integrity of AI systems against adversarial threats remains vital for maintaining user trust and system accountability in high-risk domains.
