- The paper introduces a band-split neural codec that processes audio by dividing it into discrete frequency bands for specialized and efficient encoding.
- It employs dedicated encoder-quantizer-decoder pipelines with advanced SimVQ, yielding superior performance on music and complex audio at reduced bitrates.
- Empirical results reveal faster convergence, enhanced codebook utilization, and improved downstream benchmarks compared to traditional RVQ codecs.
BSCodec: A Band-Split Neural Codec for Universal Audio Reconstruction
Motivation and Empirical Observations
BSCodec addresses a central deficit in current neural audio codecs: state-of-the-art models, while capable of producing high-fidelity compressed reconstructions for speech, steadily degrade when compressing non-speech content such as music or general sound. This performance gulf is rooted in the wide spectral diversity across audio domains—speech is highly concentrated in narrow, low-frequency bands related to pitch harmonics, while music and environmental sounds distribute energy more broadly across the frequency spectrum. Consequently, uniform capacity allocation and entangled representations in full-band or conventional residual vector quantization (RVQ) codecs are both suboptimal for universal audio.
This is supported by quantitative spectral comparisons:
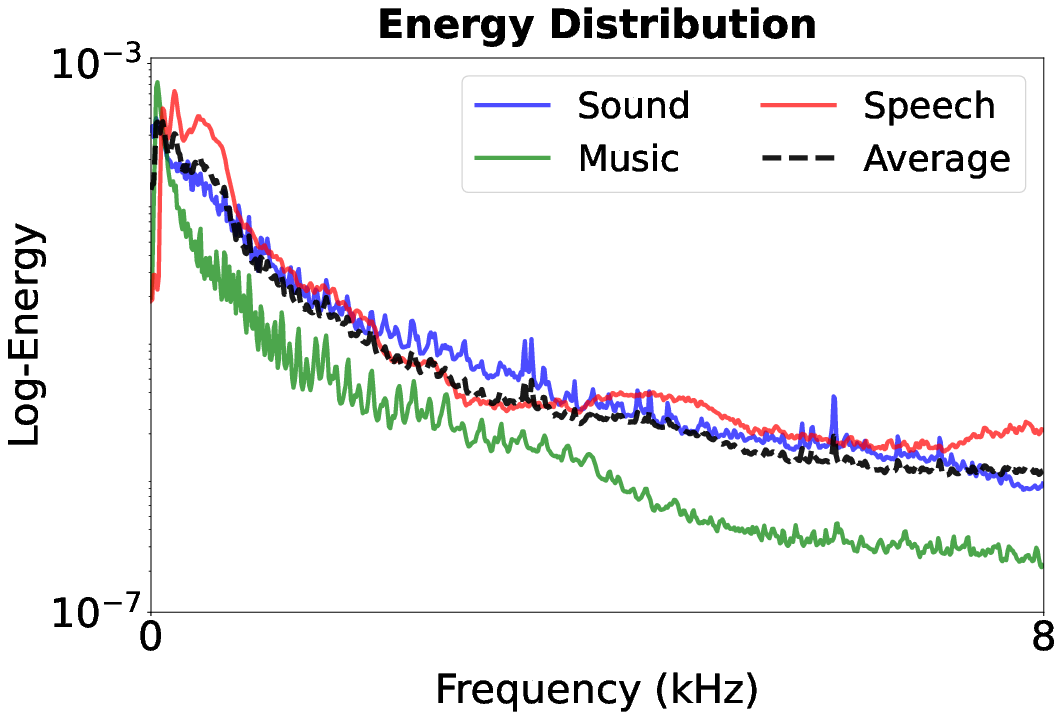
Figure 1: Energy distributions in the frequency domain demonstrate structural differences between speech, sound, and music, underscoring the motivation for frequency-aware processing.
Such distributions demand an approach that reflects audio’s frequency-domain heterogeneity to enable robust universal reconstruction.
Architectural Approach: Band-Split Codec Structure
BSCodec introduces an explicit frequency band-splitting stage within the codec pipeline. Rather than a monolithic encoder-quantizer-decoder, BSCodec decomposes input audio into B disjoint frequency bands, processes each band with a dedicated stack of encoder, quantizer, and decoder (all operating in parallel), and sums the outputs for final reconstruction:
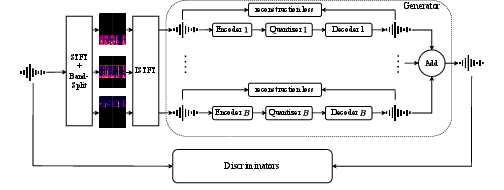
Figure 2: BSCodec processes audio by splitting it into frequency bands, each handled by separate encoder-quantizer-decoder modules, followed by reconstruction and adversarially-trained multi-band discriminators.
Band Splitting Mechanism
- Input waveform x[n] is transformed via STFT to obtain X(m,k).
- Frequency bands B with boundaries {f0,…,fB} are defined.
- For each band b, a binary mask Mb(k) isolates its frequency bins. Inverse STFT reconstructs temporally-localized waveforms xb[n] for each band.
This modular methodology:
- Enables band-specialized representation learning.
- Provides a natural avenue for differential quantization allocation per spectral region.
- Keeps parallel and efficient model implementations.
Encoder-Quantizer-Decoder and Vector Quantization
Each band’s pipeline begins with a SEANet-style encoder (per-band parameterization, no sharing), producing 512-D latent vectors at 75 Hz. Quantization uses an independent single-layer SimVQ codebook per band—experimentally set at K=131,072—to avoid the capacity bottleneck and utilization collapse prevalent in large codebooks.
SimVQ extends standard VQ with a learnable linear transformation W on codebook vectors, mitigating representational collapse during optimization, which is statistically verified by utilization analysis.
Adversarial and Reconstruction Losses
- Multi-scale mel-spectrogram L1 loss drives frequency-accurate reconstructions.
- Audio waveform adversarially regularized with multi-period and multi-band discriminators.
- Gradient flow through quantization is maintained with a straight-through estimator.
Empirical Results: Multi-Domain and Downstream Effectiveness
Music and Universal Audio Reconstruction
Band-splitting allows finer preservation of harmonic and timbral content necessary for music and complex sound. When evaluated against multi-layer RVQ codecs (e.g., DAC), BSCodec’s 5-band and 3-band settings yield improved or competitive performance at substantially lower bitrates:
- On music and sound, 5-band VQ at 3.75 kbps outperforms DAC at 4.5/6 kbps on VISQOL and spectral metrics.
- The 3-band SimVQ (3.83 kbps) matches or surpasses DAC, while a 2-band variant (2.55 kbps) demonstrates graceful performance reduction, trading off some music fidelity for bandwidth.
- For speech, overly fine band partitioning (5 bands) is suboptimal—coarser decomposition (e.g., 3 bands with high-capacity codebooks for the low-frequency band) is essential.
Per-layer and joint entropy analysis reveals:
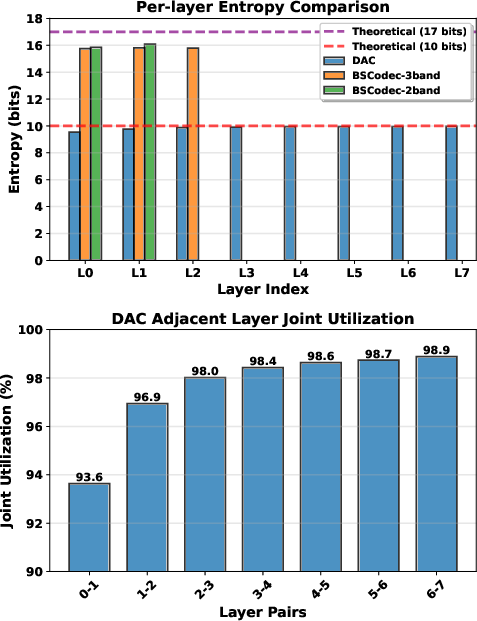
Figure 3: Per-layer and adjacent-layer codebook entropy comparison illustrates reduced redundancy and improved utilization of BSCodec’s band-specific codebooks compared to RVQ hierarchies employed by DAC.
- Joint codebook utilization in BSCodec is comparable to or exceeds RVQ’s pairwise utilization, without the redundancy observed in deeper residual stacks.
- The marginal utility of the final RVQ layers in DAC is negligible, suggesting wasteful over-parameterization.
Convergence and Learning Dynamics
Training evolution is consistently superior:
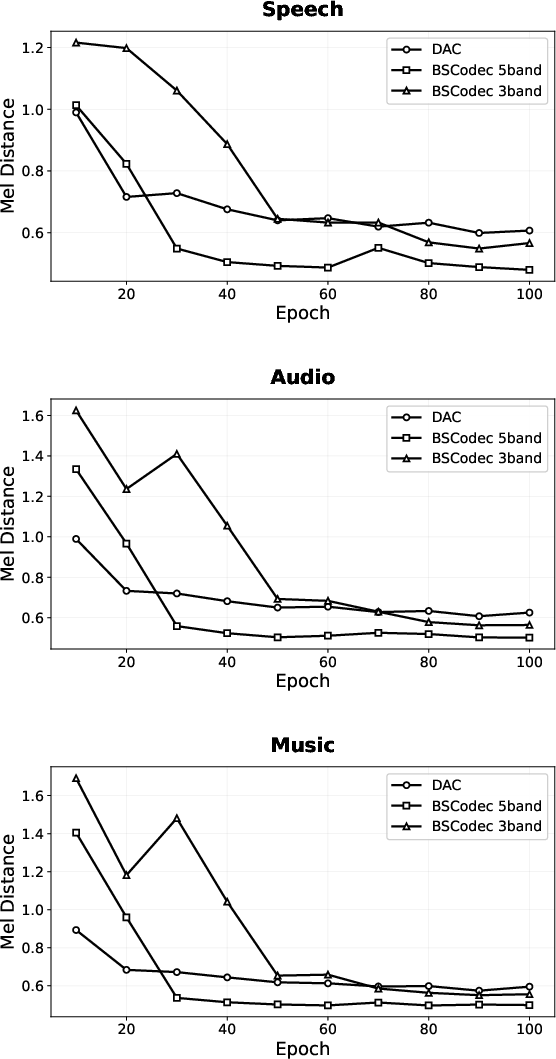
Figure 4: MEL distance curves during training show that BSCodec configurations achieve both faster convergence and lower final reconstruction errors relative to DAC.
- Band-split configurations (especially 3-band and 5-band) exhibit rapid convergence in early epochs, reaching stable, improved MEL distances within 40–60 epochs.
- DAC converges more slowly and with higher final reconstruction error.
Downstream Task Benchmarking
In speech and audio understanding benchmarks (Codec-SUPERB, ARCH):
- BSCodec’s representations (notably the 3-band variant) yield substantially higher scores for speaker verification (ASV), audio event classification, and emotion/speech recognition relative to DAC and EnCodec.
- Semantic richness and downstream task utility are notably improved with band-specific encoders, especially for speech and audio subtasks.
Limitations and Trade-offs
- The architecture’s benefits for large-scale generative modeling (e.g., LLM-driven TTS, universal synthesis) remain unexplored.
- Excessive band splitting degrades speech performance—hybrid partitioning/granularity selection is crucial.
- Computational cost scales with the number of bands, and careful resource balancing is critical for low-latency applications.
Theoretical and Practical Implications
BSCodec demonstrates that encoder design aligned with the natural frequency structure of universal audio sources significantly enhances both reconstruction and representational fidelity versus conventional entangled approaches. Decoupling spectrally disparate information both increases compression efficiency and improves utility for downstream semantic tasks.
Broader Impacts
- Compression: Half-bitrate codecs with equal or better fidelity for multi-domain audio will reduce communication/storage costs.
- Representation Learning: Band-split quantization offers improved latent spaces for cross-domain downstream models (e.g., paralinguistic analysis, cross-modal retrieval).
- Scalability: Modular encoders simplify future scaling to higher or variable sample rates and extensibility to new audio domains.
Future Directions
- Adaptive band partitioning via learnable, data-driven splits.
- Combining band-splitting with domain-conditioned or MoE decoders for further gains.
- Integration of linguistic/semantic priors into the band-split pipeline.
Conclusion
The BSCodec framework provides strong evidence that respect for physical signal structure via frequency band splitting is critical for high-performance, general-purpose neural audio codecs. Through both architecture and quantization advances, BSCodec delivers state-of-the-art universal audio reconstruction at significantly reduced bitrates, with strong performance verified across a range of downstream tasks. The methodology and empirical findings of this work are likely to influence both neural codec design and broader representation learning for universal audio.