- The paper introduces RoMA which aligns routing weights with task embeddings via manifold regularization.
- RoMA fine-tunes MoE routers, yielding 7-15% accuracy improvements across benchmarks like MMLU, HellaSwag, and PIQA.
- The method enhances model generalization, matching or surpassing larger dense models while maintaining efficient inference costs.
Routing Manifold Alignment for Mixture-of-Experts LLMs
Introduction
The paper "Routing Manifold Alignment Improves Generalization of Mixture-of-Experts LLMs" explores the limitations of current routing strategies in Sparse Mixture-of-Experts (MoE) models, particularly in the context of LLMs. Sparse MoEs have become a key architecture for scaling up LLMs efficiently, relying on routers to assign input tokens to experts—a deterministic feature across different tasks. Despite their effectiveness in managing computational loads, these routers exhibit suboptimal performance, often leading to a notable accuracy gap compared to optimal routing configurations.
Task-Expert Routing Manifold Misalignment
Pretraining evaluations reveal misalignment between the task embedding manifold and the routing weights manifold in MoE models. This is evidenced by disparate clusters within the task embedding space that are not reflected in the routing patterns, as shown in Figure 1. Such misalignment hampers consistent expert selection and efficient knowledge transfer across tasks, constituting a core bottleneck in the generalization of MoE models.
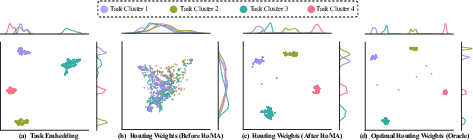
Figure 1: UMAP visualization of task embedding and routing weights manifolds for samples in ARC-C; RoMA aligns routing weights with the manifold's cluster structure.
Routing Manifold Regularization (RoMA)
RoMA introduces a manifold regularization term into the post-training objective for MoE LLMs' routers. It optimizes the router parameters by aligning routing weights with task embeddings—this ensures that input samples targeting similar tasks exhibit homogeneous expert choices. The manifold regularization dynamically adjusts routing paths by aligning less effective samples with those exhibiting optimal routing weights based on semantic similarity. Adoption of regularization techniques from manifold learning allows for improved consistency in task understanding and expert allocation throughout multiple layers.
This method paves the way for enhanced generalization by harmonizing internal representations and routing functionality. Training involves lightweight fine-tuning where routers learn from successful routing configurations of semantically similar samples, thereby preserving manifold structures.
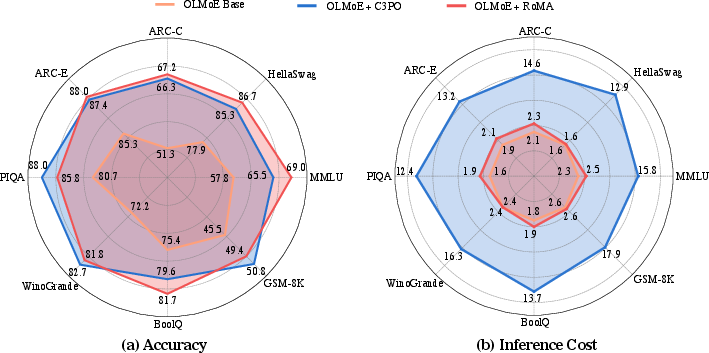
Figure 2: Radar figure showing accuracy and inference cost analysis; RoMA maintains efficiency while achieving higher accuracy.
Experiments
RoMA's efficacy was tested on three prominent MoE LLMs across benchmarks including MMLU, HellaSwag, and PIQA. Results demonstrate substantial improvements (7-15% accuracy increase) alongside competitive inference costs compared to state-of-the-art methods like C3PO. Remarkably, RoMA achieves superior model generalization when compared to dense models with significantly larger active parameters.
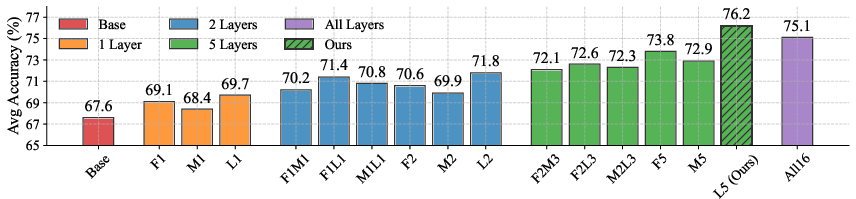
Figure 3: Comparison of different training set sizes for RoMA; significant gains are achieved even with partial datasets.
Conclusion
RoMA provides a robust enhancement to routing strategies within MoE LLMs, addressing the misalignment issue that inhibits task-specific expert allocation. Not only does RoMA improve accuracy and efficiency by leveraging manifold structures around routing weights, but it also extends the operational capabilities of small-scale MoEs to match or surpass larger dense models.
This work refines the MoE architecture's router utilization process, highlighting geometric alignment between routing weights and task embeddings. Future studies may explore more detailed dynamics of manifold representations and their broader implications in knowledge transfer and specialization of expert pathways in MoE models.