- The paper demonstrates a unified framework that jointly optimizes model and layer fusion to enhance performance in various speech tasks.
- It fuses supervised and self-supervised models to yield complementary representations that improve both acoustic detail capture and abstract feature integration.
- Experimental results indicate significant improvements in ASR, emotion recognition, and multilingual applications, highlighting scalability and robustness.
Unifying Model and Layer Fusion for Speech Foundation Models
Introduction
Speech Foundation Models (SFMs) have become widely utilized in recent times, with their substantial applicability in speech processing tasks such as ASR, Speech Segmentation, Visually Grounded Speech, Speaker Verification, and Emotion Recognition. These models are generally pretrained using SSL or SL objectives on extensive data, allowing transfer learning to new tasks efficiently. Improving upon SFM representations has become a key research area, focusing on fusion strategies, enabling enhancement across various tasks.
Fusion Strategies
Two primary fusion mechanisms exist within SFMs: fusion across multiple models and fusion across various layers within a single model. Existing literature highlights the advantages of combining different model architectures under the framework of ensemble learning. Given the diverse data distributions and training objectives, such fusion processes can significantly bolster model performance and robustness.
Layer fusion within speech models is another optimization strategy where lower layers preserve acoustic details, while deeper layers capture more abstract representations. Efficient layer fusion can lead to improved downstream task performance across different speech processing applications.
Proposed Unified Fusion Framework
This work proposes a cohesive framework that simultaneously optimizes model and layer fusion using an innovative interface design. Unlike previous works which treated these processes independently, the proposed method integrates them jointly for superior performance improvements. This is particularly relevant for ASR tasks and non-ASR tasks such as Emotion Recognition and Speaker Verification. Additionally, the fusion of supervised and self-supervised models demonstrates noteworthy advancements, suggesting that models trained under different objectives yield complementary representations.
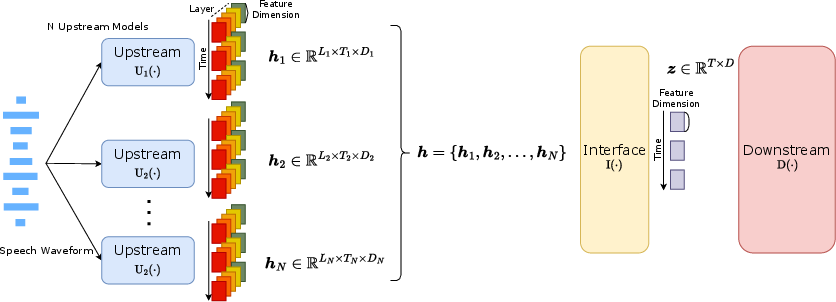
Figure 1: An overview framework of Interface with fusion.
Experimental Evaluation
Experiments conducted on various tasks reveal that the unified fusion approach generally outperforms existing model and layer fusion techniques. Results span across single model optimizations and combinations of multiple models, with the fusion of supervised and self-supervised models showing distinct benefits. Additionally, when scaling these models, particularly using large-size models, the proposed method significantly enhances performance compared to other methods.
The evaluation also includes a detailed analysis of multilingual performance across diverse languages, highlighting the robustness of the unified framework in low-resource language settings. The scalability of large models further reinforces the efficacy of the approach under computational constraints.
Discussion
The empirical results emphasize the importance of selecting appropriate upstream models for effective fusion. These findings suggest that leveraging the diverse representations of supervised and self-supervised models holds significant potential. The ability to scale efficiently to larger models provides compelling evidence for this approach as a viable pathway toward future SFM advancements.
Finally, extending beyond the current framework, future work could explore joint distillation of multiple models, promoting computational efficiency while harnessing the benefits of fusion.
Conclusion
The proposed unified framework for model and layer fusion suggests promising directions for optimizing SFMs across various speech tasks. This work highlights the interplay between supervised and self-supervised training objectives, presenting a path for exploring their synergy. Continued exploration in this area may uncover substantial advancements in the field, paving the way for more robust and versatile speech processing models.