Assessing the Capabilities of LLMs in Humor:A Multi-dimensional Analysis of Oogiri Generation and Evaluation
Abstract: Computational humor is a frontier for creating advanced and engaging NLP applications, such as sophisticated dialogue systems. While previous studies have benchmarked the humor capabilities of LLMs, they have often relied on single-dimensional evaluations, such as judging whether something is simply ``funny.'' This paper argues that a multifaceted understanding of humor is necessary and addresses this gap by systematically evaluating LLMs through the lens of Oogiri, a form of Japanese improvisational comedy games. To achieve this, we expanded upon existing Oogiri datasets with data from new sources and then augmented the collection with Oogiri responses generated by LLMs. We then manually annotated this expanded collection with 5-point absolute ratings across six dimensions: Novelty, Clarity, Relevance, Intelligence, Empathy, and Overall Funniness. Using this dataset, we assessed the capabilities of state-of-the-art LLMs on two core tasks: their ability to generate creative Oogiri responses and their ability to evaluate the funniness of responses using a six-dimensional evaluation. Our results show that while LLMs can generate responses at a level between low- and mid-tier human performance, they exhibit a notable lack of Empathy. This deficit in Empathy helps explain their failure to replicate human humor assessment. Correlation analyses of human and model evaluation data further reveal a fundamental divergence in evaluation criteria: LLMs prioritize Novelty, whereas humans prioritize Empathy. We release our annotated corpus to the community to pave the way for the development of more emotionally intelligent and sophisticated conversational agents.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper studies how well LLMs—the AI systems behind many chatbots—can understand and make jokes. Instead of just asking “Is this funny?”, the authors look at humor from several angles. They use a Japanese comedy game called Oogiri, where people are given a prompt and must reply with a witty, surprising line.
What is Oogiri?
In Oogiri, players see a topic like “A taxi driver who just awakened—what does he say?” and try to write a clever punchline like “I can make this traffic jam disappear. Want me to?” It’s fast, creative, and depends a lot on shared human experiences.
Goals and Questions
The paper tries to answer two simple questions:
- Can AI write funny Oogiri-style answers that people actually find funny?
- Can AI judge (score) jokes the way people do, using similar tastes and reasons?
How They Did It
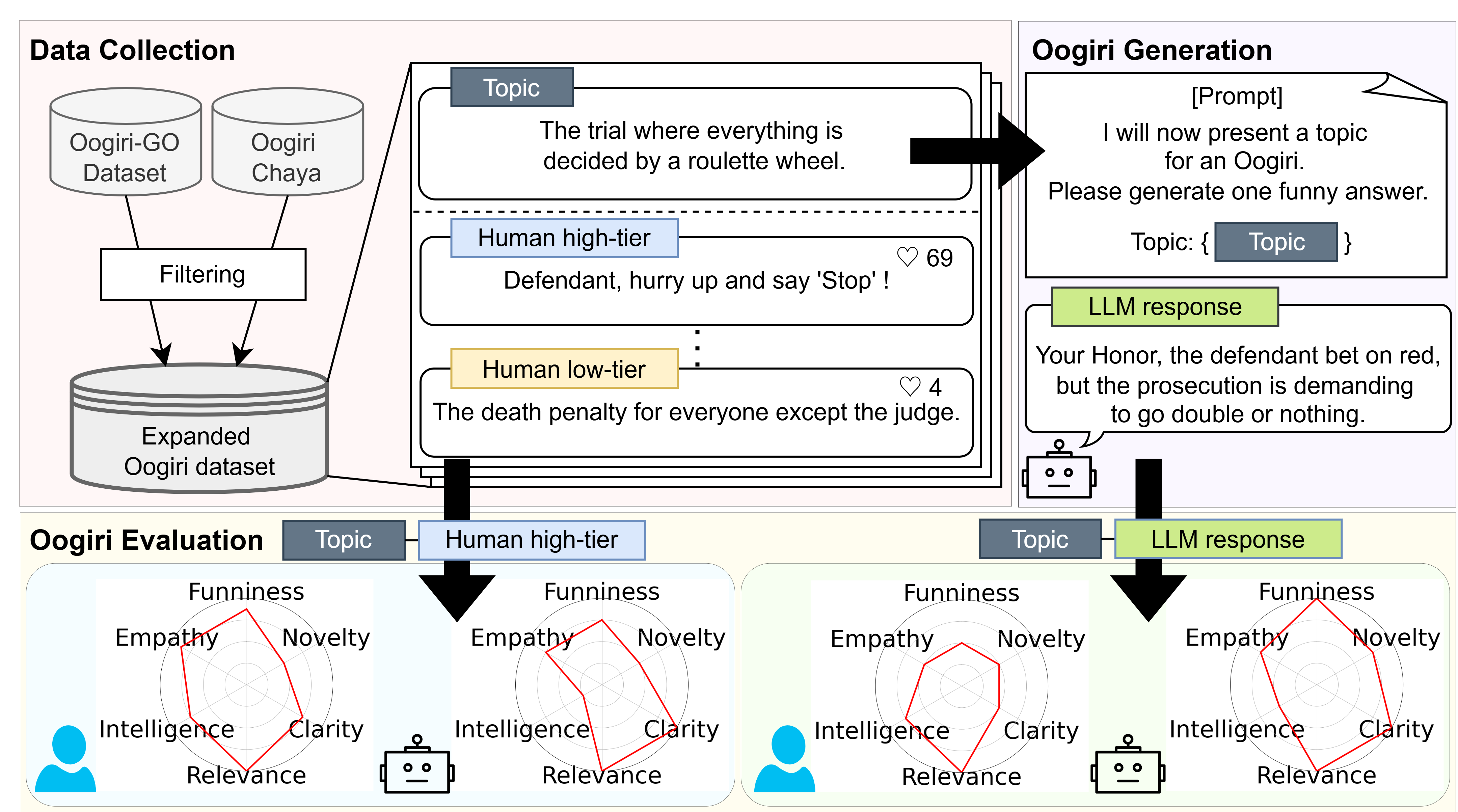
To keep things fair and thorough, the authors built a large set of Oogiri prompts and answers:
- They collected real human-written Oogiri answers from two websites (Bokete and Oogiri-Chaya).
- Bokete shows other people’s votes while you vote, which can create bandwagon effects (popular answers get even more popular).
- Oogiri-Chaya hides other answers and vote counts during voting, which reduces bias and makes the votes more about actual funniness.
- They also asked three top AI models (GPT-4.1, Gemini 2.5 Pro, Claude Sonnet 4) to write answers to the same prompts.
For each prompt, they built a small “lineup” of answers to compare:
- Very popular human answer, average human answer, low-rated human answer
- An “unrelated” answer (a top joke from a different, mismatched prompt)
- A serious (not meant to be funny) AI answer
- Funny attempts from the three AIs
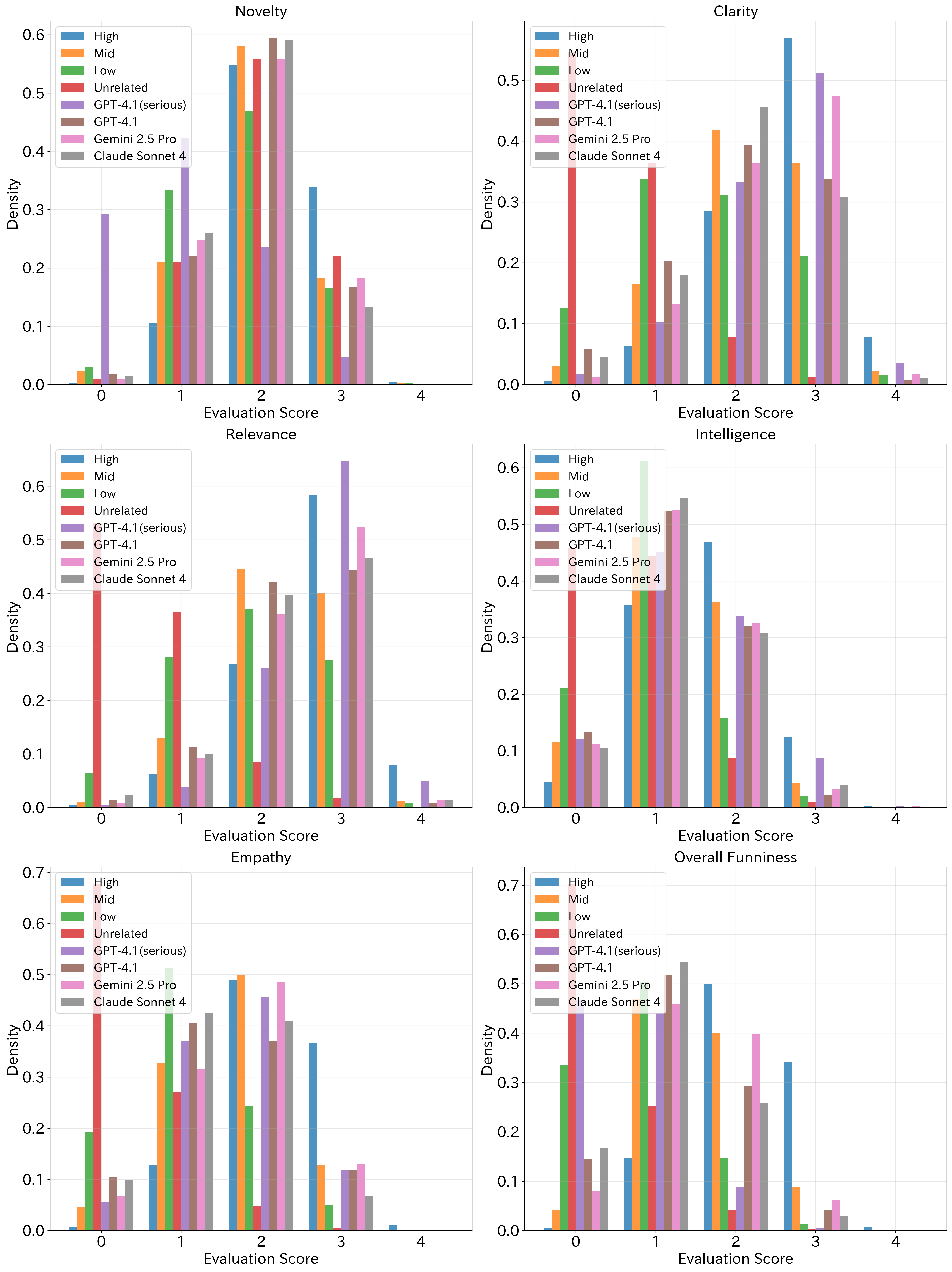
Then, human judges rated each answer using six simple 0–4 scores (0 = not at all, 4 = excellent). The six dimensions were:
- Novelty: Is it original and surprising?
- Clarity: Is it easy to understand?
- Relevance: Does it actually fit the prompt?
- Intelligence: Does it show clever thinking?
- Empathy: Is it relatable—does it feel like it understands people and the situation?
- Overall Funniness: How funny is it in the end?
They also asked the AIs to act as judges and score the same answers in the same six categories. Finally, they compared how much the AI scores “move together” with human scores (think: if humans rate something higher, does the AI also rate it higher?). That “moving together” is called correlation.
Main Findings
1) How funny are AI-written jokes?
- AI jokes were, on average, between low-tier and mid-tier human jokes.
- Among the AIs, Gemini 2.5 Pro did the best overall.
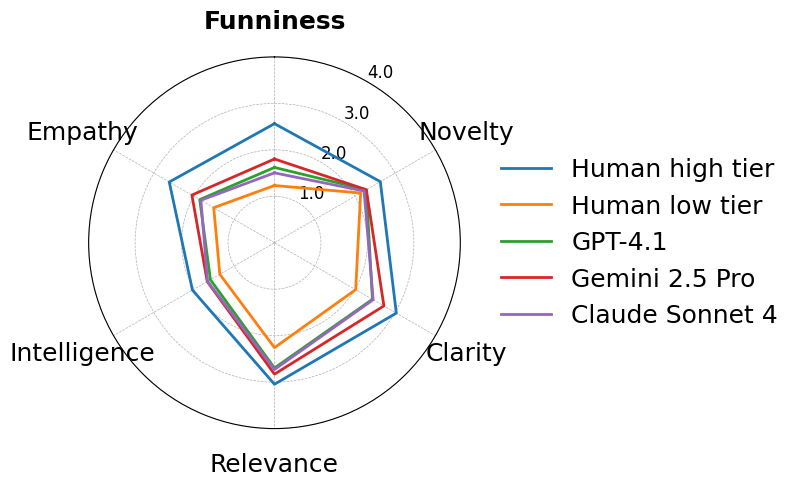
- Biggest weakness: Empathy. AIs could be novel and on-topic, but often lacked that human “I get you” feeling that makes a joke land.
Why this matters: Good jokes often work like this—first they surprise you (Novelty), then they “click” with your real-life feelings or shared experiences (Empathy). The AIs did the surprise part better than the “click” part, so the humor didn’t feel complete.
2) How good are AIs at judging humor like humans do?
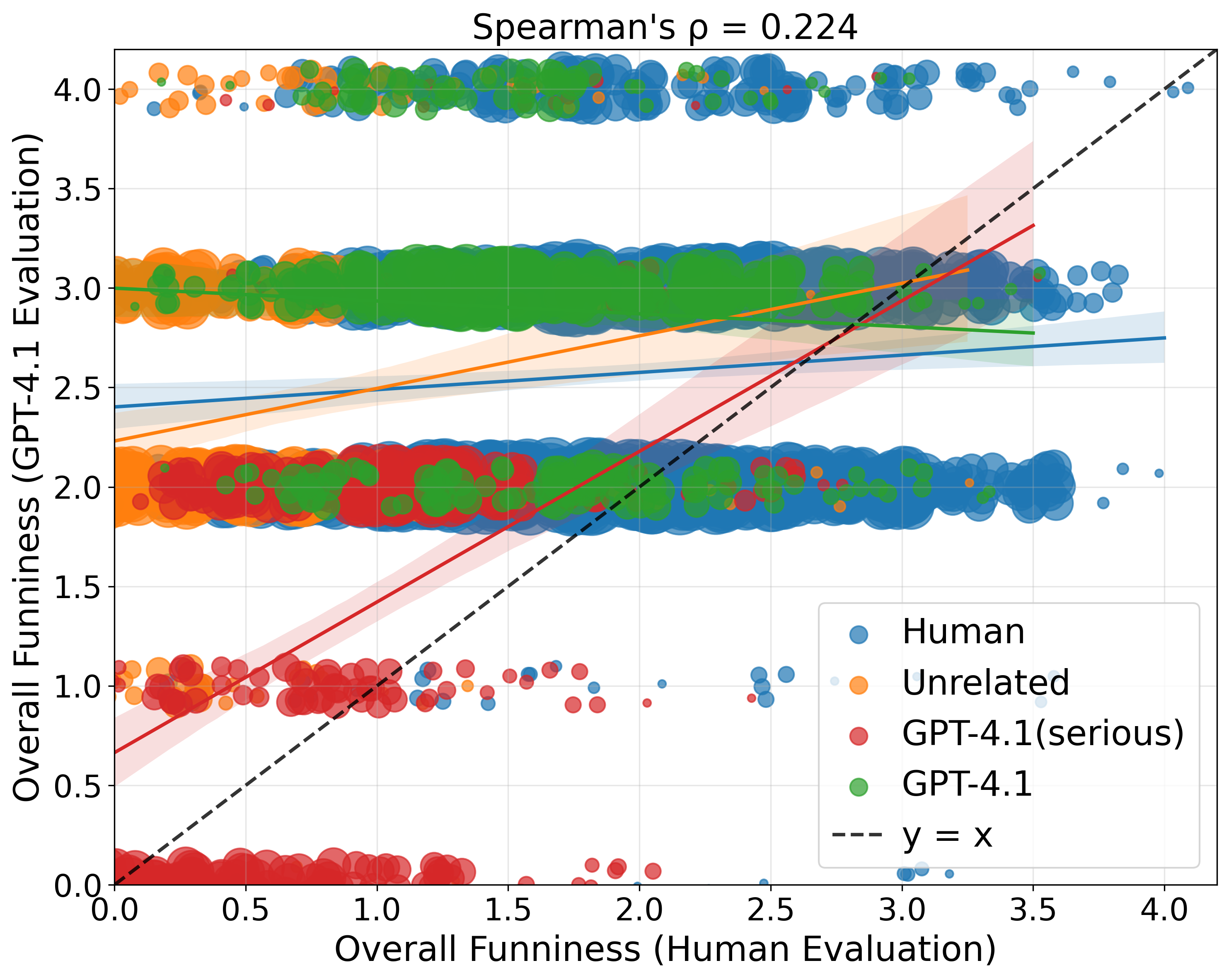
- Overall, AIs did not agree strongly with human judges about what’s funniest.
- Of the three, Claude Sonnet 4 matched humans slightly better than the others—but still not great.
- A strange pattern: AIs tended to overrate answers that humans thought weren’t funny, including:
- Unrelated answers (AIs scored them surprisingly high)
- AI-made jokes (AIs scored these as highly as top human jokes, but humans didn’t)
This suggests two biases:
- Positivity bias: AIs are too generous and avoid giving low scores.
- Self-preference bias: AIs rate AI-generated answers too kindly.
3) What do humans vs. AIs value in humor?
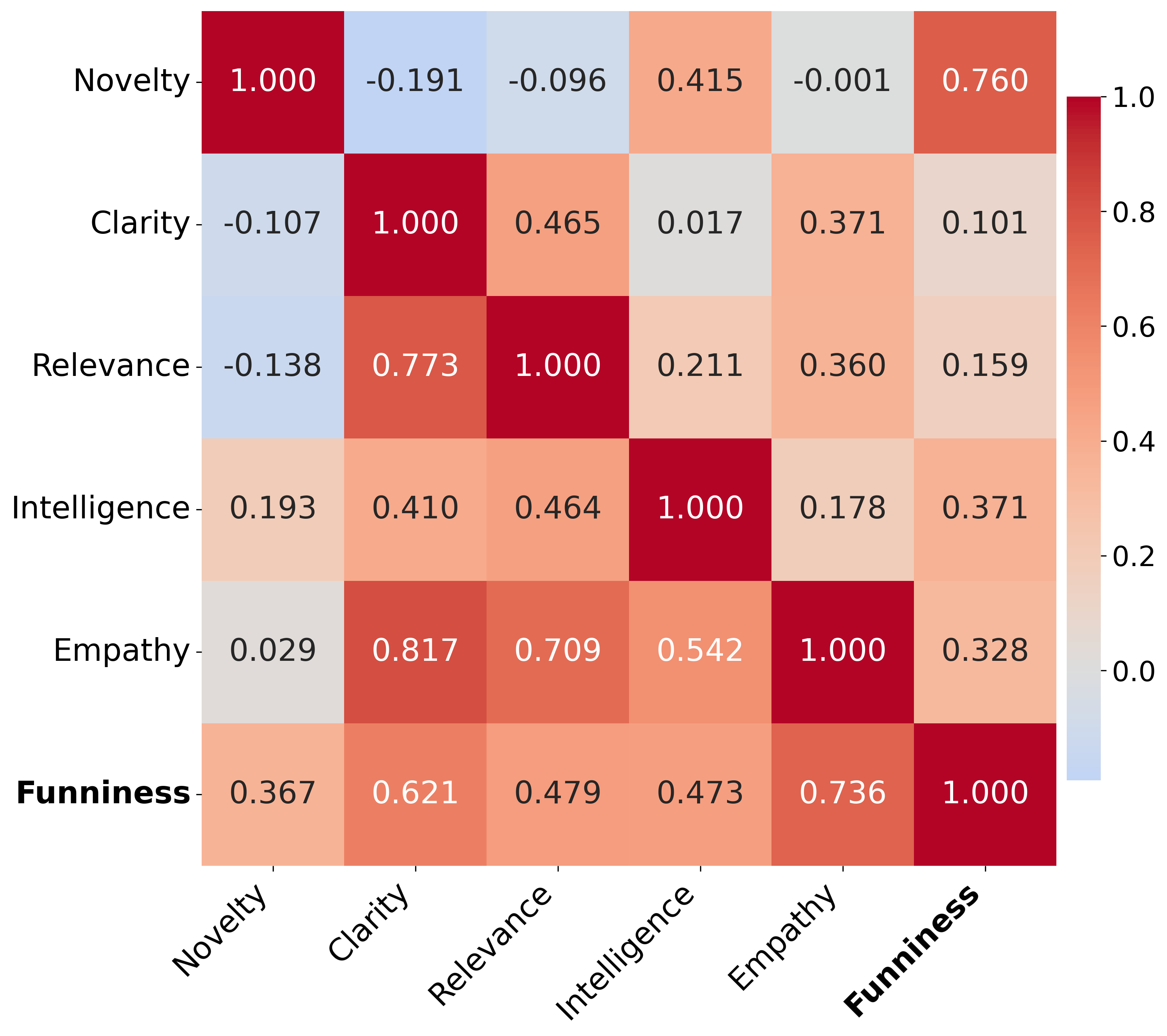
- Humans’ Overall Funniness was most connected to Empathy (relatability).
- AIs’ Overall Funniness was most connected to Novelty (surprise).
- This means AIs have a different “sense of humor” from humans: they prefer “unexpected,” while people prefer “I get it and it gets me.”
Why It’s Important
- For comedy and conversation, empathy is huge. It’s what makes a joke feel real and relatable, not just random or weird.
- If we want chatbots to be fun and natural, they need more than clever wordplay—they need to sense what people feel and care about.
- Using AIs as “judges” of humor is risky right now. Because they favor Novelty and are overly positive, they may give the wrong feedback and steer creators in the wrong direction.
What This Could Change
- Training: To make AI humor better, we should help models improve Empathy—understanding human situations, emotions, and social context.
- Evaluation: Developers should be careful using “AI-as-a-judge” for humor. Human judgment still matters, especially for subjective things like jokes.
- Research tools: The authors are releasing their annotated dataset (with six-dimension scores) so others can build more emotionally aware, better-aligned AI systems.
In Short
- AIs can write somewhat funny jokes, but not as well as good humans—mostly because they lack empathy.
- AIs don’t judge humor the way people do; they prize newness over relatability.
- To get truly funny, human-like AI, we need to teach models to connect with people, not just surprise them.
Knowledge Gaps
Knowledge Gaps, Limitations, and Open Questions
Below is a single, focused list of what remains missing, uncertain, or unexplored in the study, phrased to enable concrete follow-up work.
- External validity beyond Japanese Oogiri: unclear whether findings (e.g., empathy vs. novelty prioritization) generalize to other languages, cultures, or humor genres (stand-up, sarcasm, irony, satire, dark/taboo humor).
- Multimodality gap: image-based Oogiri topics are included, but it is unclear whether annotators and models actually saw images or only text; no vision-LLMs (VLMs) were evaluated despite multimodal items.
- Validation of the six-dimensional rubric: no evidence of construct validity (e.g., factor analysis, measurement invariance) for Novelty/Clarity/Relevance/Intelligence/Empathy/Funniness; unclear if “Empathy” is distinct from familiarity, concreteness, or cultural sharedness.
- Inter-annotator reliability is unreported: no kappa/ICC or rater calibration analyses per dimension; robustness of the human labels (and between-subset comparability) is unknown.
- Annotator demographics and their effects: humor is audience-dependent, but age, gender, region, and cultural background of annotators were not collected/analyzed; sensitivity of results to rater composition is unknown.
- Absolute vs. comparative judgments: only 5-point absolute ratings used; no pairwise, best–worst, or Thurstone-style comparative schemes to reduce scale-use bias and improve discrimination.
- Scale calibration: LLM judges show near-ceiling means (e.g., Clarity ~4) suggesting poor calibration; no use of anchor items, z-score normalization, or rubric-specific few-shot calibration to align LLM scales with human use.
- Statistical rigor of model differences: differences across models/dimensions reported without confidence intervals, hypothesis tests, or mixed-effects modeling to control for topic/rater variance.
- Causal interpretation of “Empathy”: the claim that empathy underpins funniness is correlational; no interventions (e.g., empathy-boosting prompts, persona priming, retrieval of lived-experience vignettes) to test causal effects.
- Mechanisms to improve empathy: no exploration of concrete training/evaluation strategies (persona conditioning, audience modeling, memory of shared experiences, socio-cultural grounding, socio-emotional reasoning modules).
- LLM-as-judge biases diagnosed but not mitigated: positivity and self-preference biases identified, but no tested remedies (e.g., strict negative feedback instruction, confidence calibration, judge-ensembles, debias prompts, adversarial anchors).
- Source identity masking: LLMs may recognize their own stylistic fingerprints; no anonymization/paraphrase or controlled masking to test whether self-preference persists when source cues are removed.
- “Unrelated” control construction: procedure to ensure true topical irrelevance is underspecified; some “unrelated” punchlines may be broadly funny or weakly related, confounding Relevance and Overall Funniness judgments.
- Platform-specific effects: Bokete vs. Oogiri-Chaya have different voting biases, but results are not stratified by source; no analysis of whether model–human alignment varies across platforms or topic types.
- Topic sampling bias: 200 topics selected by “popularity of top-voted answers,” potentially over-representing mainstream/safer humor; no stratified sampling by theme, difficulty, or humor mechanism (pun vs. situational vs. absurdist).
- Content filtering effects: removal of edgy/controversial content likely narrows humor types; no analysis of how safety filtering shifts dimension weights (e.g., reduces novelty/edginess, alters empathy ratings).
- Image transcription fidelity: text-in-image transcription via GPT-4.1 is not validated; potential OCR/interpretation errors could distort topic meaning and evaluations.
- Relevance vs. absolute funniness conflation: “Overall Funniness” integrates all dimensions by instruction, potentially penalizing otherwise funny but off-topic answers; no separate metric for topic-conditional funniness vs. absolute funniness.
- Limited decoding/prompting ablations: generations used default settings and a single base prompt; no study of temperature, top-p, sampling strategies, few-shot exemplars, or humor-specific prompting (e.g., comedic archetypes, audience constraints).
- No exploration of chain-of-humor methods: methods like staged incongruity–resolution planning, narrative scaffolding, or retrieval-augmented cultural references are not tested.
- Single-turn humor only: Oogiri one-liners omit conversational context; no study of multi-turn, audience-adaptive humor where empathy and timing might be learned or elicited interactively.
- No contamination check: models may have seen Bokete/Oogiri content in pretraining; no de-duplication or memorization audits (e.g., n-gram overlap, nearest-neighbor checks).
- Rater assignment design: each annotator rated only one response type per topic; potential between-group calibration differences are uncorrected; no cross-over design or post-hoc normalization to remove rater-type confounds.
- Agreement metrics limited to Spearman’s ρ: no Kendall’s τ, intraclass correlation, calibration error, or reliability decomposition (topic vs. rater vs. model) reported; model–human gaps may be mischaracterized.
- Per-dimension causal structure: only bivariate correlations reported; no partial correlations or regression analyses to isolate the unique contribution of Empathy vs. Novelty while controlling for Clarity/Relevance.
- Serious baseline limited to GPT-4.1: “serious” non-humorous responses come from one model only; unclear if alignment on “not funny” generalizes across other generators or human-written serious baselines.
- No variance across runs: model stochasticity (seed/temperature) and judge reproducibility are unreported; stability of findings across runs is unknown.
- Missing VLM-as-judge: for image topics, VLM judges could be more relevance-aware; their absence leaves open whether multimodal evaluators reduce the “Unrelated” over-scoring problem.
- Reproducibility of prompts and code: prompts are in the appendix, but data processing, filtering, and rater tooling code availability and licensing of scraped content are not fully detailed; legal/copyright status of released items (esp. images) is unclear.
- Ethics and audience harm: empathy scoring may penalize certain humor traditions (e.g., dark humor) without explicit ethical framework; absence of analysis on potential harms, cultural sensitivity, or subgroup fairness in humor evaluation.
Practical Applications
Overview
The paper introduces a multi-dimensional framework and corpus for evaluating and generating humor in Japanese Oogiri, identifies a consistent empathy deficit in current LLMs, and shows that LLMs-as-judges diverge from human criteria (LLMs prioritize novelty; humans prioritize empathy). Below are practical, real-world applications that derive from the paper’s findings, methods, and dataset, organized into immediate and long-term opportunities.
Immediate Applications
- Software & Conversational AI: empathy‑gated humor modes in chatbots
- Application: Add an optional “humor mode” that first elicits user context (preferences, mood, sensitivities) and applies the paper’s rubric to gate joke delivery (e.g., only deliver humor if Empathy and Relevance thresholds are met).
- Tools/workflows: Prompt templates that explicitly optimize for Empathy and Relevance; pre‑checks using LLM scoring for Clarity and Relevance; human-in-the-loop for Empathy/funniness until models improve.
- Sectors: software, customer support, education.
- Dependencies/assumptions: Cultural specificity of Oogiri; Empathy rubric transferability across languages; policy requirements for safe humor in sensitive contexts.
- Marketing & Advertising: two‑stage content review for humorous copy
- Application: Pre‑screen draft copy with LLM scoring on Clarity/Relevance/Novelty, then route to human reviewers to judge Empathy and Overall Funniness using the six‑dimension rubric; use A/B tests to validate impact on engagement.
- Tools/workflows: “Rubric-based content review pipeline” integrated into CMS; dashboards displaying six-dimension scores; human QA queue for empathy/funniness.
- Sectors: marketing, media, brand safety.
- Dependencies/assumptions: Human reviewer availability; brand guidelines; ethical constraints (avoid discriminatory or harmful humor); generalization beyond Japanese.
- Content Safety & Risk Management: empathy-based safety gates
- Application: Use Empathy and Relevance thresholds to block or downrank content with low relatability (high risk of offense/misinterpretation), especially for sarcasm or edgy humor.
- Tools/workflows: “Empathy gatekeeper” module; policy rules that penalize low Empathy despite high Novelty; triggers for manual review.
- Sectors: social platforms, community moderation.
- Dependencies/assumptions: Clear definitions of “harmful” in local contexts; potential over-blocking of legitimate satire; need for appeal/review mechanisms.
- Product UX Guidelines: avoid automatic humor in service contexts
- Application: Default to serious responses in customer support and healthcare; allow humor only when user explicitly opts in, given LLMs’ misalignment with human humor evaluation and better agreement on “non-humor.”
- Tools/workflows: “No-jokes mode” switch; explicit consent prompts for humor.
- Sectors: customer support, healthcare, finance.
- Dependencies/assumptions: Regulatory compliance (e.g., healthcare); organizational policies; user preference management.
- Creative Ideation for Japanese Markets: Oogiri-style brainstorming assistant
- Application: Use LLMs for idea generation (low‑ to mid‑tier humor) and rely on human creatives to refine for Empathy and timing; helpful for captioning, social posts, and variety generation.
- Tools/workflows: “Humor Draft Assistant” that generates multiple Oogiri-style punchlines and flags novelty versus empathy risks.
- Sectors: entertainment, media, social content teams.
- Dependencies/assumptions: Japanese audience targeting; human editorial oversight; legal clearance for platform-derived topics.
- Academic and R&D: reproducible benchmarking and rubric adoption
- Application: Adopt the six‑dimension rubric (Novelty, Clarity, Relevance, Intelligence, Empathy, Funniness) for evaluating creative text in lab settings, courses, and student projects; use the released corpus for replication and baseline comparisons.
- Tools/workflows: Course modules on computational humor; benchmark suites; annotation guidelines from the paper.
- Sectors: academia, research labs.
- Dependencies/assumptions: Access to released corpus and licenses; annotator training; language scope beyond Japanese.
- LLM‑as‑Judge Guardrails: narrow use to clarity/relevance checks
- Application: Use LLM judges for objective-ish dimensions (Clarity, Relevance) and avoid relying on them for Empathy or Overall Funniness; apply debiasing rules to mitigate positivity/self‑preference biases.
- Tools/workflows: “Judge role separation” (LLM → Clarity/Relevance; humans → Empathy/Funniness); bias-aware calibration (e.g., downweight scores on unrelated items).
- Sectors: evaluation platforms, software QA.
- Dependencies/assumptions: Awareness of LLM biases (positivity, self-preference); periodic audits; model updates may alter behavior.
- Product Analytics & User Research: six‑dimension instrumentation
- Application: Tag generated content with the six scores and correlate with real engagement metrics (clicks, shares, dwell time) to identify which dimensions drive outcomes in your audience.
- Tools/workflows: Analytics pipeline capturing dimension scores + engagement; cohort analyses distinguishing empathy-sensitive segments.
- Sectors: software analytics, marketing analytics.
- Dependencies/assumptions: Data privacy/consent; robust measurement; statistical power.
Long-Term Applications
- Empathy‑aware training objectives and reward modeling
- Application: Train LLMs with multi‑objective reward models that explicitly optimize Empathy (and human-aligned resolution of incongruity), not just Novelty; include human preference data emphasizing empathetic resonance.
- Tools/workflows: RLHF/RLAIF with empathy weighting; multi‑dimensional reward models; curated empathy datasets.
- Sectors: foundational model development, software.
- Dependencies/assumptions: Large-scale, high-quality empathy-labeled data; safety and ethics review; compute resources.
- Human‑aligned humor evaluators (debiasing LLM‑as‑Judge)
- Application: Build specialized evaluators calibrated to human judgments (correcting positivity and self‑preference biases), enabling more reliable automated triage before limited human review.
- Tools/workflows: Pairwise ranking models trained on human ratings; post-hoc score correction; confidence estimation and abstention when scores are uncertain.
- Sectors: evaluation platforms, content moderation, marketing.
- Dependencies/assumptions: Ongoing human ratings; cross-cultural generalization; model interpretability requirements.
- Multimodal, culturally aware humor understanding for memes and cartoons
- Application: Extend the rubric and training to VLMs for image‑text humor (Oogiri’s image-based tasks; memes), embedding cultural/contextual knowledge for better empathetic resolution.
- Tools/workflows: Vision-LLMs tuned for humor; knowledge retrieval modules; culturally aware fine-tuning.
- Sectors: social media, entertainment, education.
- Dependencies/assumptions: Rights to multimodal training data; culture-specific annotations; safety against offensive imagery.
- Social robotics and digital companions with empathetic humor
- Application: Robots and agents that use humor to build rapport, reduce anxiety, or improve engagement (elder care, therapy, education), with strong empathy safeguards.
- Tools/workflows: Context sensing + humor gating; incremental deployment in controlled settings; clinician/educator oversight.
- Sectors: healthcare, education, robotics.
- Dependencies/assumptions: Clinical validation; safety certifications; risk management for misinterpretation or offense.
- Industry standards and governance for AI humor
- Application: Define multi-dimensional evaluation protocols (including empathy weighting and debiasing) for certifying humor-capable AI; require transparency about LLM-as-judge limitations in high-stakes uses.
- Tools/workflows: Standardized test suites; audit frameworks; disclosure policies.
- Sectors: policy, standards bodies, enterprise governance.
- Dependencies/assumptions: Multi-stakeholder consensus; alignment with local regulations; periodic updating as models evolve.
- Cross-cultural humor localization engines
- Application: Systems that adapt humorous content across regions and languages, preserving empathetic resonance while modulating references and tone.
- Tools/workflows: Culture-specific humor maps; semantic alignment layers; human editorial review.
- Sectors: global marketing, media distribution, education.
- Dependencies/assumptions: Culture-aware knowledge bases; access to local annotators; ethical vetting.
- Personalized humor modeling
- Application: Learn individual users’ humor profiles (topics, empathy triggers, sensitivities) to tailor content for higher funniness without offense.
- Tools/workflows: Preference learning; on-device or privacy-preserving personalization; consent and opt-out controls.
- Sectors: consumer apps, entertainment, education.
- Dependencies/assumptions: Data privacy and consent; robustness against echo chambers; safeguards for sensitive groups.
- Entertainment production tools and formats
- Application: Writers’ rooms augmented by humor assistants that suggest variants ranked by empathy and human-likeness; interactive Oogiri-style apps where AI competes and users judge.
- Tools/workflows: Authoring tools integrated with the rubric; real-time audience feedback loops.
- Sectors: TV/film, streaming, gaming.
- Dependencies/assumptions: IP/licensing; union and labor considerations; audience safety filters.
- Academic advancements in computational humor
- Application: Use the corpus and rubric to study the mechanics of humor (incongruity vs. resolution), empathy modeling, and cross‑disciplinary ties to psychology; develop better theory-informed architectures.
- Tools/workflows: Interdisciplinary research programs; datasets expanded beyond Japanese; public leaderboards.
- Sectors: academia, research consortia.
- Dependencies/assumptions: Funding, ethical approvals, multilingual expansion.
Notes on general assumptions and dependencies across applications:
- The corpus is Japanese and Oogiri‑specific; transfer to other languages and humor styles will require cultural adaptation and new annotations.
- LLM behavior changes with model updates; periodic re‑validation is necessary.
- Empathy is a complex, culturally contingent construct; operational definitions must be stress-tested to avoid over‑ or under‑filtering.
- Human-in-the-loop remains essential where Empathy and Overall Funniness are critical, given current evaluator misalignment and biases.
- Legal and ethical considerations (dataset licensing, content safety, privacy) must be addressed before deployment.
Glossary
- Absolute evaluation: Assigning direct, non-comparative scores to items across predefined criteria. "We conducted absolute evaluations for the eight response types across six dimensions: Novelty, Clarity, Relevance, Intelligence, Empathy, and Overall Funniness."
- Adversarial attack: An input manipulation designed to reduce model performance or reveal weaknesses. "An adversarial attack shows that models trained on pun datasets are less robust."
- Annotated corpus: A dataset enriched with labels or metadata to support analysis and model training. "We release our annotated corpus to the community to pave the way for the development of more emotionally intelligent and sophisticated conversational agents."
- Bandwagon effect: A social bias where popularity drives further popularity, independent of intrinsic quality. "It can also cause a ``conformity bias'' (bandwagon effect), in which popular responses tend to attract more votes."
- Conformity bias: The tendency to align judgments with perceived consensus or others’ choices. "It can also cause a ``conformity bias'' (bandwagon effect), in which popular responses tend to attract more votes."
- Crowd annotations: Human-provided labels collected at scale via distributed contributors. "we then evaluated both the LLM-generated and human-generated responses through crowd annotations."
- Crowdsourcing: Obtaining data or annotations from a large pool of online participants. "They used crowdsourcing to annotate Oogiri responses with various humor-related attributes and found that three factors (relevance to the topic, clarity, and novelty) were the most important contributors to a response's funniness."
- Empathy: An evaluation dimension capturing how relatable or resonant a response is to human experience. "We then manually annotated this expanded collection with 5-point absolute ratings across six dimensions: Novelty, Clarity, Relevance, Intelligence, Empathy, and Overall Funniness."
- Epistemic markers: Linguistic cues indicating degrees of certainty, belief, or knowledge. "Are LLM-Judges Robust to Expressions of Uncertainty? Investigating the effect of Epistemic Markers on LLM-based Evaluation"
- First-mover advantage: A bias favoring earlier submissions due to visibility or momentum effects. "This system can potentially give rise to a ``first-mover advantage,'' where earlier responses are favored."
- Information bottleneck principle: A framework for extracting minimal yet sufficient information relevant to a task. "Their method uses the information bottleneck principle to extract relevant knowledge from a Vision-LLM (VLM) and iteratively refine it."
- Incongruity-resolution theories of humor: Theories positing humor arises from detecting and resolving discrepancies between expectations and outcomes. "This finding can be effectively interpreted through the lens of incongruity-resolution theories of humor \cite{Suls1972}."
- Likert scale: An ordered categorical rating scale used for subjective assessments. "Each dimension is rated on a 0--4 Likert scale (0 = not at all, 4 = excellent)."
- LLM-as-a-Judge: A paradigm where LLMs replace humans in evaluating content quality. "a paradigm known as ``LLM-as-a-Judge,'' which uses LLMs themselves as evaluators to substitute for human assessment, has garnered significant attention."
- Multimodal humor: Humor combining multiple modalities (e.g., text and images). "have proposed an LLM-based method to understand and explain the funniness of multimodal humor (e.g., memes and cartoons) composed of images and captions."
- Oogiri: A Japanese improvisational comedy format where participants craft humorous responses to prompts. "Oogiri, a form of Japanese improvisational comedy games."
- Oogiri-Chaya: A curated dataset/platform for Oogiri with evaluation procedures designed to reduce bias. "Oogiri-Chaya is a dataset derived from another online Oogiri competition platform"
- Oogiri-GO: A large-scale Oogiri dataset compiled from online platforms for humor benchmarking. "Our primary resource is the Oogiri-GO dataset \cite{zhong2024letsthinkoutsidebox}, collected from Bokete, an online Oogiri competition platform."
- Out-of-domain data: Data drawn from distributions different from those used in training or development. "The behavior of the models on out-of-domain data is unstable, suggesting that some of the models overfit, while others learn non-specific humor characteristics."
- Positivity bias: A tendency to assign overly favorable evaluations, under-penalizing poor or irrelevant content. "One such bias is a positivity bias."
- Preference tuning: Fine-tuning models using human preference signals to shape outputs and behaviors. "Through processes like instruction and preference tuning, they are optimized to be cooperative and to generate positive responses, inadvertently predisposing them to assign favorable scores and hesitate to provide negative feedback."
- Radar chart: A polar plot for comparing multi-dimensional metrics across entities. "As shown in the radar chart (Figure \ref{fig:Radar_Chart}), the largest performance gap is on this dimension."
- Rubric: A structured set of criteria guiding consistent evaluation. "instruct them to perform an evaluation using the same six-dimensional rubric described previously."
- Self-preference bias: A bias where models disproportionately favor outputs produced by models (including themselves). "Another observable bias is a self-preference bias, where LLMs tend to rate responses generated by other LLMs as comparable to high-tier human answers, whereas humans place them below the mid-tier (Tables \ref{tab:Human_reordered}, \ref{tab:GPT_reordered})."
- Spearman's correlation coefficient: A rank-based statistic measuring monotonic association between variables. "we compute the Spearman's correlation coefficient between the human scores and the LLM scores."
- Vision-LLM (VLM): A model that jointly processes visual and textual inputs. "Their method uses the information bottleneck principle to extract relevant knowledge from a Vision-LLM (VLM) and iteratively refine it."
- Zero-shot scenario: Evaluating or performing a task without task-specific training examples. "We also evaluate the sense of humor of the chatGPT and Flan-UL2 models in a zero-shot scenario."
Collections
Sign up for free to add this paper to one or more collections.

