eXIAA: eXplainable Injections for Adversarial Attack
Abstract: Post-hoc explainability methods are a subset of Machine Learning (ML) that aim to provide a reason for why a model behaves in a certain way. In this paper, we show a new black-box model-agnostic adversarial attack for post-hoc explainable Artificial Intelligence (XAI), particularly in the image domain. The goal of the attack is to modify the original explanations while being undetected by the human eye and maintain the same predicted class. In contrast to previous methods, we do not require any access to the model or its weights, but only to the model's computed predictions and explanations. Additionally, the attack is accomplished in a single step while significantly changing the provided explanations, as demonstrated by empirical evaluation. The low requirements of our method expose a critical vulnerability in current explainability methods, raising concerns about their reliability in safety-critical applications. We systematically generate attacks based on the explanations generated by post-hoc explainability methods (saliency maps, integrated gradients, and DeepLIFT SHAP) for pretrained ResNet-18 and ViT-B16 on ImageNet. The results show that our attacks could lead to dramatically different explanations without changing the predictive probabilities. We validate the effectiveness of our attack, compute the induced change based on the explanation with mean absolute difference, and verify the closeness of the original image and the corrupted one with the Structural Similarity Index Measure (SSIM).
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper introduces a new way to “attack” the explanations that AI models give for their decisions, especially for images. It doesn’t try to change the model’s answer (like “this is a dog”), but instead quietly changes the explanation (the parts of the picture the model says are most important) while keeping the image looking the same to human eyes. The method works even if you don’t know anything about the model’s inner workings, which shows a serious weakness in popular explainability tools.
What questions did the researchers ask?
The authors focused on three simple questions:
- Can we slightly change an image so it looks the same and the AI still predicts the same class, but the explanation changes a lot?
- Can we do this without seeing or editing the model’s code or its weights (a “black-box” situation)?
- How strong is this kind of attack across different models and explanation methods?
How did they do it?
Think of an AI image classifier like a student who gives you an answer and then highlights parts of the picture to explain that answer. The researchers figured out how to sneak tiny details from another image into the original, so the student still says “dog,” but highlights different parts of the picture to explain why.
Here’s the approach in everyday terms:
Key ideas and terms
- Black-box: You can only see the model’s outputs (its predictions and explanations), not its inner workings.
- Model-agnostic: The attack works on different models, not just one special type.
- Post-hoc explainability: Tools that create explanations after a model makes a prediction, rather than building the explanation into the model itself.
The explainability tools they target
These tools produce “feature attributions,” often shown as heatmaps over the image to indicate which pixels mattered most to the prediction:
- Saliency Maps: Measure how much changing each pixel would change the model’s output.
- Integrated Gradients: Compare the image to a simple “baseline” (like a blank picture) and add up how important each pixel is along the path from baseline to the actual image.
- DeepLIFT SHAP: Estimates how much each pixel “contributes” to the prediction by comparing it to reference images.
The three-phase attack pipeline
- Phase 1: Pick a “runner-up” class. They first run the original image through the classifier and find the second most likely class (for a dog image, maybe cat is second). Then they choose a very confident example image from that runner-up class (a clear cat picture).
- Phase 2: Extract top features. Using the same explainability method, they find the most important pixels in the runner-up image (the pixels most responsible for “cat”).
- Phase 3: Inject features gently. They blend a small amount of those important runner-up pixels into the original image, but only at selected spots and with a tiny weight. This keeps the image looking the same to humans and preserves the original prediction, yet it shifts the explanation a lot. They also “clip” pixel values to ensure the final image stays in a normal range.
To check success:
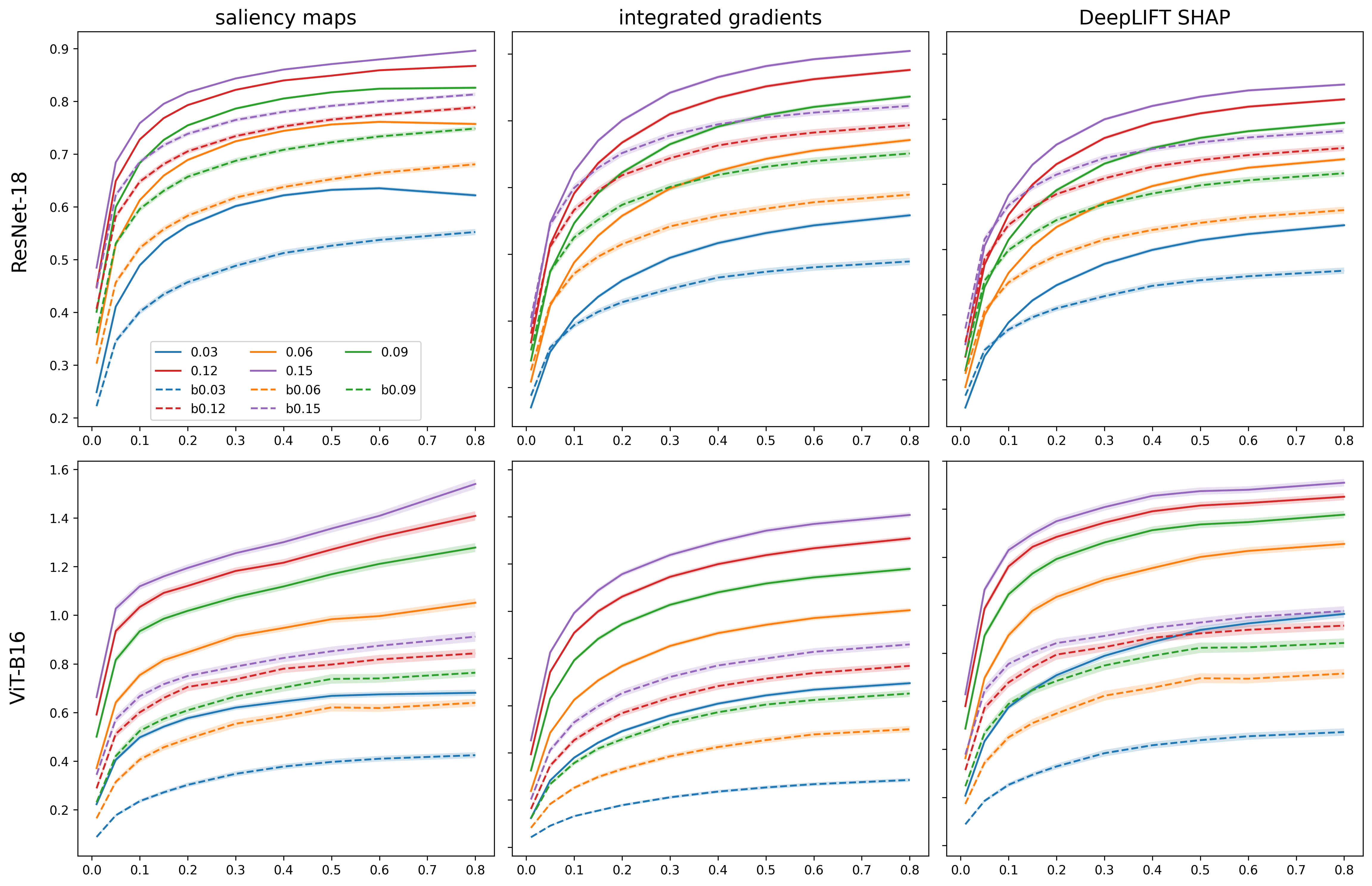
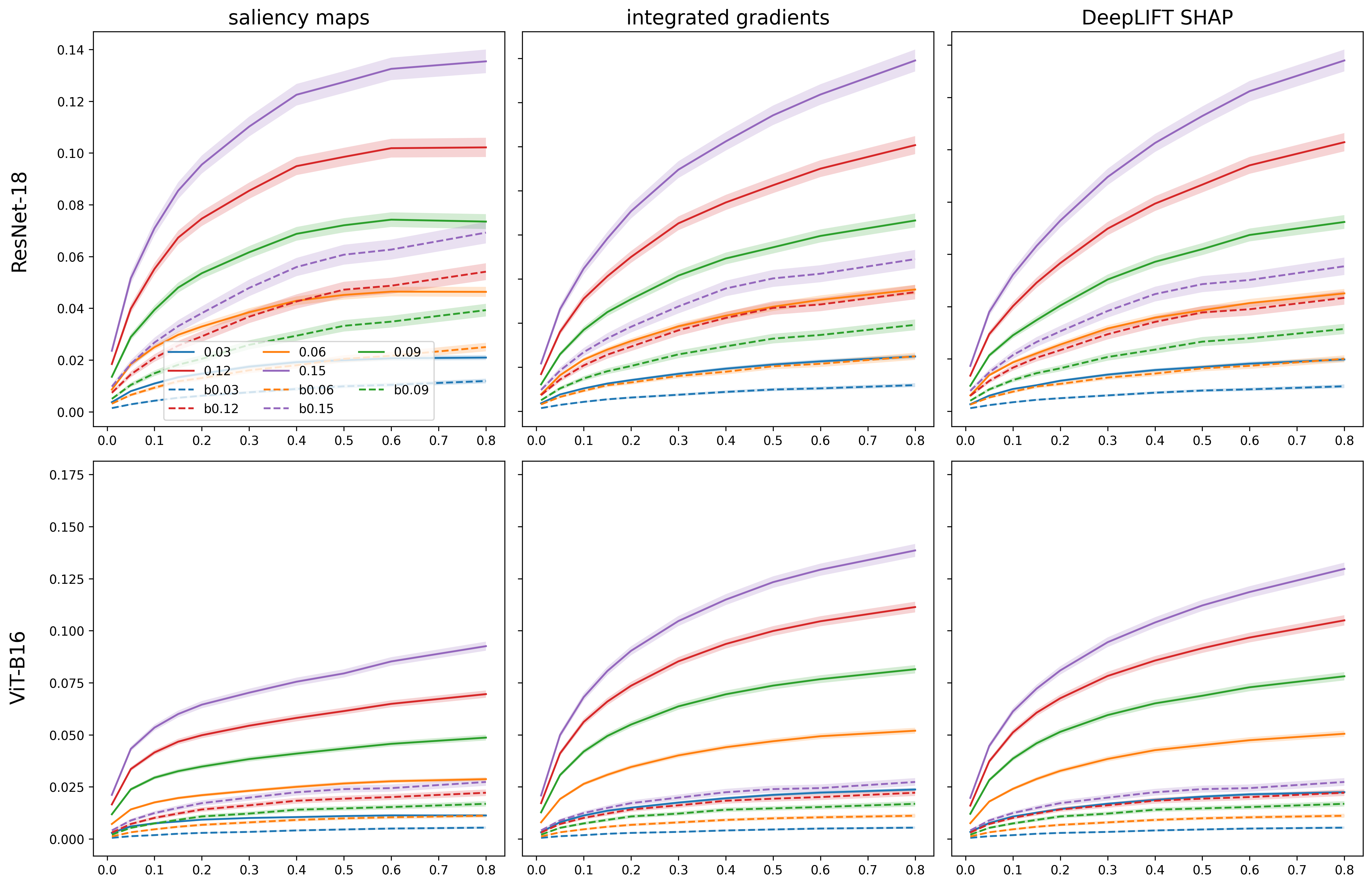
- They measure how much the explanation changes using the mean absolute difference (sum of absolute changes across all pixels).
- They measure how similar the corrupted image is to the original using SSIM (Structural Similarity Index), where 1 means identical-looking.
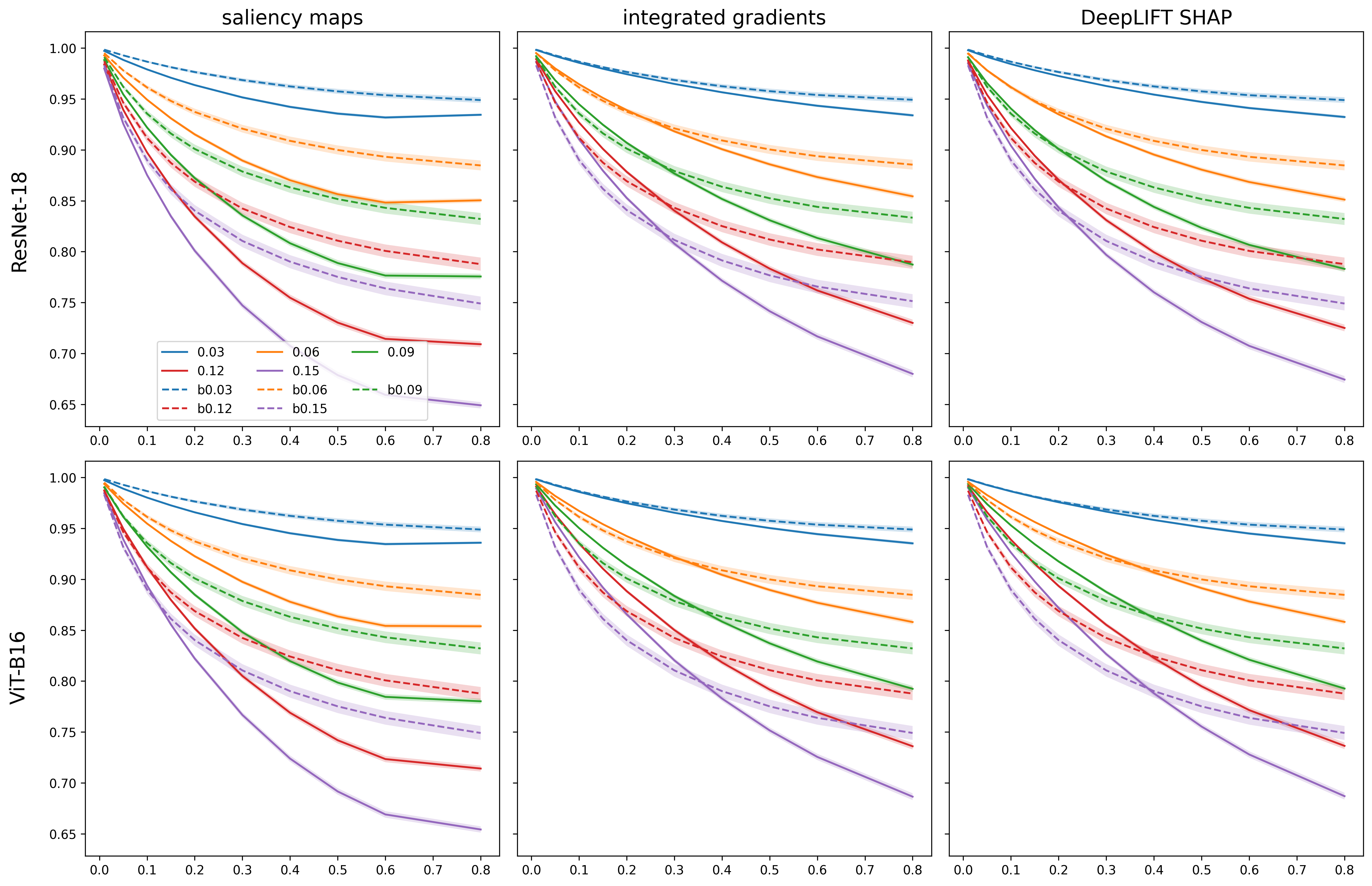
- They compare prediction probabilities before and after to ensure the class confidence barely changes.
What did they find?
Across many tests (using ImageNet, two common models—ResNet-18 and ViT-B16—and three explanation methods), the attack:
- Strongly changed explanations: The highlighted “important” parts of the image changed a lot, even though the prediction stayed nearly the same.
- Kept images visually similar: SSIM scores stayed high, meaning humans wouldn’t notice the changes.
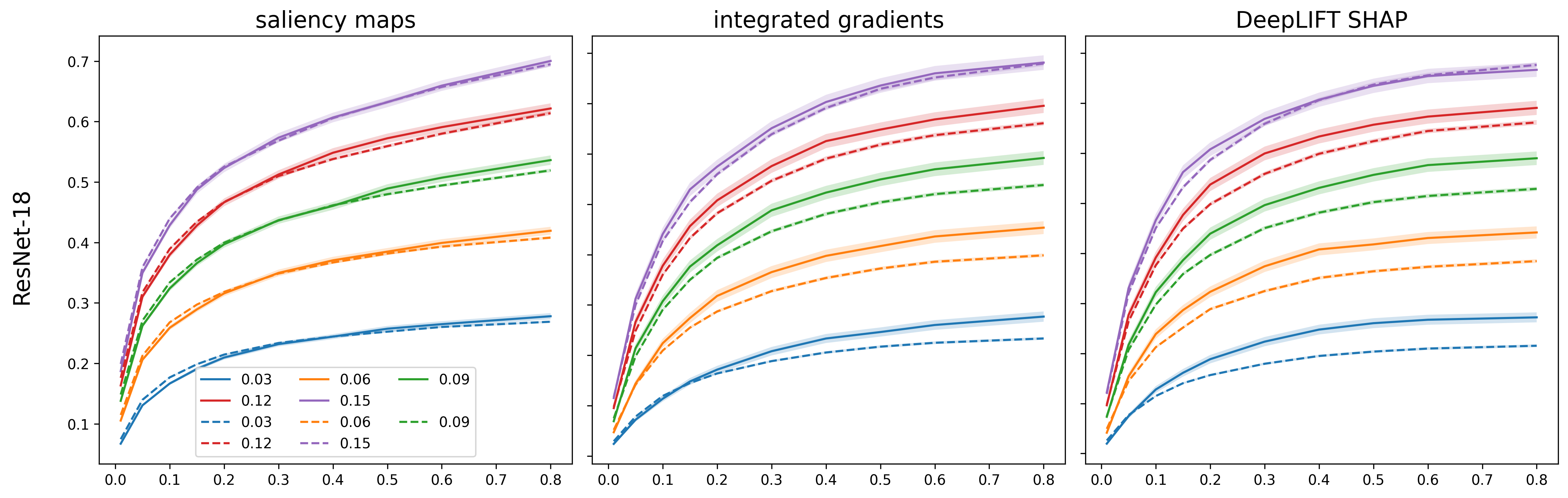
- Barely changed predictions: For most settings, the main class confidence dropped only slightly (often under about 5%, and only larger when the blending was made stronger).
- Worked better than random noise: Compared to a simple baseline (adding Gaussian noise), their targeted “feature injection” caused much larger shifts in explanations with similar or small visual change.
- A clever choice of runner-up class matters: Injecting features from the class that the model is most confused with (the runner-up) makes the attack notably stronger than injecting features from random other classes.
- Model differences: ViT-B16 (a transformer) often kept its predictions stable but was more vulnerable in terms of explanation changes compared to ResNet-18. In short, being robust to input noise didn’t automatically make its explanations robust.
They varied two knobs:
- alpha (how strongly to blend runner-up features into the original), and
- top-k (how many of the most important runner-up pixels to inject). Increasing these generally made the explanation changes bigger, but with diminishing returns at higher values.
Why does this matter?
If explanations can be manipulated while predictions stay the same, users—like doctors, drivers, or financial analysts—could be misled about why a model made a decision. That’s dangerous in safety-critical areas, where the “why” matters as much as the “what.”
This work highlights an important gap: many popular explanation methods can be tricked in a realistic, black-box setting. The takeaway is that we need:
- Stronger, more robust explainability tools that resist such attacks.
- Better tests and standards for evaluating explanations, not just predictions.
- Careful use of explanations in high-stakes decisions until their reliability improves.
In short, the paper is a warning: don’t blindly trust AI explanations just because they look convincing. We must build and test explanations with the same rigor we use for predictions.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a consolidated list of what remains missing, uncertain, or unexplored in the paper. Each point is formulated to be concrete and actionable for future research.
- Threat model clarity: The attack assumes access to both model predictions and high-resolution, per-pixel explanations for arbitrary inputs. Many real-world systems do not expose explanations externally or only return low-resolution overlays. What is the minimum explanation granularity and API access needed for the attack to remain effective?
- Practicality of attack image selection: The method selects the “highest-confidence” image from the model’s running-up class, implying access to a labeled corpus and sufficient query budget to score many candidates. How can the attack be adapted when labels are unavailable or query budgets are limited (e.g., via generative sampling, prototype synthesis, or few queries)?
- Generality across XAI methods: Only saliency maps, integrated gradients, and DeepLIFT SHAP are tested. Do perturbation-based (e.g., occlusion, RISE), CAM-based (Grad-CAM, Score-CAM), LRP, and SHAP Kernel/Tree explainers exhibit similar vulnerability? Comprehensive benchmarking across a broader set of XAI methods is missing.
- Dependency on explanation type/shape: The pipeline assumes explanations are (per-pixel, per-channel). Many widely used methods return heatmaps or region-level attributions. How does the attack perform when explanations are single-channel maps, aggregated over channels, or region-level?
- Baseline choice in IG and DeepLIFT SHAP: The attack’s effectiveness likely depends on explainer baselines/references (e.g., zero, blur, dataset mean). Systematically studying how baseline choice affects vulnerability is missing.
- Targeted manipulation vs untargeted change: The paper maximizes absolute difference in explanations but does not demonstrate targeted manipulation (e.g., moving attribution to specific regions or objects). Can the attack be made targeted, and under what constraints?
- Multi-objective optimization: Parameter tuning for alpha and top-k is grid-based. An explicit multi-objective procedure to satisfy detectability (e.g., SSIM ≥ threshold), constant predicted class, and maximal explanation change is not provided. Can an automated, query-efficient selection strategy be developed?
- Maintaining label invariance: Results report mean confidence drops but do not quantify the success rate of preserving the predicted class label. What fraction of attacks preserve the original top-1 class, and under what parameter regimes?
- Detectability beyond SSIM: SSIM alone may not capture perceptual detectability or forensic cues. How do LPIPS, PSNR, color histogram shifts, or human perceptual studies change the picture? Are small alpha/top-k settings truly imperceptible to humans?
- Robustness to common image pre-processing: The persistence of the attack under resizing, JPEG compression, quantization, denoising, cropping, and augmentations is not tested. Do common pre-processing steps neutralize or attenuate the explanation manipulation?
- Cross-architecture and scale generality: Only ResNet-18 and ViT-B16 are evaluated. How does vulnerability change for larger or more robust models (e.g., ResNet-50/152, EfficientNet, Swin, ConvNext, adversarially trained models, models with spectral normalization)?
- Query efficiency and computational cost: Integrated Gradients and DeepLIFT SHAP incur non-trivial compute per explanation. The overall query/computation budget per successful attack is not quantified. What are the minimal query/computation regimes for practical deployment?
- Negative vs positive attributions: The attack uses top positive features from the running-up class. Are negative attributions equally or more effective for manipulation? A systematic comparison is missing.
- Cross-method consistency checks as defenses: If an attacker exploits one explainer, do multi-explainer consistency checks (e.g., agreement across saliency, CAM, perturbation-based methods) reliably detect manipulation? No defense-side evaluation is provided.
- Simple stochastic defenses: Do randomized smoothing of explanations, ensemble explanation averaging, or input randomization (e.g., slight crops/jitters) reduce attack efficacy? No defense baselines are evaluated.
- Faithfulness and utility impact: The paper measures explanation difference but not task-relevant impact (e.g., deletion/insertion metrics, AOPC, ROAR). Do manipulated explanations materially degrade faithfulness measures, or merely change visualization patterns?
- Human-in-the-loop risk assessment: No user studies or domain-expert evaluations assess whether altered explanations would actually mislead practitioners (e.g., clinicians). What explanation changes are consequential to human decision-making?
- Extension to other modalities: Claims about applicability to time series, text, and tabular are not substantiated. How would feature injection work for discrete tokens (NLP), irregular sampling (time series), or mixed-type features (tabular) without obvious pixel blending?
- Multi-label and structured tasks: Segmentation, detection, and multi-label classification are not explored beyond a brief note. How should attack selection and feature injection be adapted when multiple classes are present or when outputs are spatially structured?
- Real-world data availability constraints: The method presumes a repository of candidate images for the running-up class. In practice, attackers may not have access to class-specific exemplars. Can class-agnostic or synthetic exemplars (e.g., diffusion-based prototypes) achieve similar manipulation?
- Stability across explanation versions and implementations: Different libraries and configurations (e.g., Captum vs tf-explain) can yield different gradients/attributions. Is the attack robust across implementations and numerical subtleties?
- Statistical significance: Reported improvements are shown as means and standard deviations, but formal significance testing, effect sizes, and confidence intervals are not provided. Are observed differences robust across larger and more diverse samples?
- Formal analysis: No theoretical characterization of why blending top-k attributions from a running-up class manipulates explanations while minimally affecting predictions is given. Can conditions or bounds be established that guarantee explanation sensitivity under such injections?
- Ethical and deployment considerations: The paper asserts no ethical violations but does not analyze realistic attack surfaces (e.g., PACS systems, clinical AI APIs) where explanations may or may not be exposed. What are concrete pathways for or barriers to real-world exploitation?
- Reproducibility and artifact availability: Code/data will be released “if accepted,” creating an immediate barrier. Full reproducibility requires open artifacts, precise hyperparameter schedules, and details on explanation configurations (e.g., baselines, step counts).
Practical Applications
Immediate Applications
Below are practical use cases that can be deployed now, leveraging the paper’s black-box, model-agnostic attack on post-hoc explanations and its empirical findings about explanation fragility.
Industry
- XAI red-teaming and robustness audits
- Sectors: healthcare, finance, autonomous driving, industrial automation, software.
- What: Offer “explanation security” assessments to stress-test saliency maps, Integrated Gradients, and DeepLIFT SHAP for deployed models without access to their internals.
- Tools/products/workflows:
- An “XAI Red Team Toolkit” built on Captum and the paper’s eXIAA procedure to generate explanation-targeted adversarial tests with tunable alpha and top-k.
- Reports that quantify Explanation Change Ratio (e.g., mean absolute difference), prediction drift, and SSIM similarity.
- Assumptions/dependencies: Requires access to model outputs and the explanations; the system must expose or allow generation of post-hoc attributions. Query access is necessary to identify the running-up class.
- MLOps guardrails for explanation stability
- Sectors: software/AI platforms, healthcare/AV model ops.
- What: Integrate explanation-stability checks in CI/CD pipelines to block deployments when explanations change dramatically under small, imperceptible perturbations.
- Tools/products/workflows:
- “Explanation Drift Monitor” that computes explanation differences across eXIAA injections; thresholds auto-gate deployment.
- Cross-method consensus checks (saliency vs IG vs DeepLIFT SHAP) to detect instability.
- Assumptions/dependencies: Requires standardized explanation APIs and baseline similarity metrics (SSIM or domain-specific equivalents).
- Vendor due diligence and procurement testing
- Sectors: healthcare providers, insurers, banks, AV OEMs.
- What: Add explanation robustness tests to vendor evaluation and model procurement processes.
- Tools/products/workflows:
- Checklists requiring evidence of explanation robustness under eXIAA-like attacks.
- Benchmark reports comparing ResNet vs ViT vulnerabilities and explainability tool performance.
- Assumptions/dependencies: Access to vendor trial endpoints for predictions and explanations; contractual permission to probe models.
- Initial defense via explanation-aware data augmentation
- Sectors: computer vision (medical imaging, quality inspection), AV perception.
- What: Retrain or fine-tune models with eXIAA-injected samples to reduce explanation volatility while monitoring prediction fidelity.
- Tools/products/workflows:
- Training pipelines that incorporate explanation consistency loss and eXIAA-based augmentation.
- Validation dashboards tracking explanation change vs prediction change.
- Assumptions/dependencies: Access to training data and the ability to retrain; effectiveness varies by architecture (paper shows ViT explanations more vulnerable even if predictions are robust).
Academia
- Benchmarking explainability robustness across methods and architectures
- What: Systematically evaluate saliency maps, IG, and DeepLIFT SHAP for ResNet and ViT, reproducing the paper’s setup and expanding datasets and metrics.
- Tools/products/workflows:
- Public datasets of adversarial explanation pairs (original vs eXIAA-corrupted).
- Shared code for single-step black-box explanation attacks; standardized metrics (SSIM, explanation MAD).
- Assumptions/dependencies: Availability of pre-trained models and Captum implementations; ethics approvals where needed (e.g., medical datasets).
- Curriculum and training modules on XAI fragility
- What: Course labs demonstrating that explanations can be manipulated without changing predictions.
- Tools/products/workflows:
- Jupyter notebooks showcasing eXIAA attacks and mitigation heuristics.
- Assumptions/dependencies: Educational access to ML frameworks and models; institutional approval.
Policy and Governance
- Risk guidance and disclaimers for post-hoc explanations
- Sectors: regulators, standards bodies, compliance teams.
- What: Draft policy notes that caution against relying solely on post-hoc feature attributions in high-stakes decisions unless robustness testing is performed.
- Tools/products/workflows:
- Compliance templates: require “explanation robustness evidence” (e.g., pass/fail thresholds for eXIAA tests).
- Assumptions/dependencies: Regulatory capacity to incorporate guidance; stakeholder engagement (clinical, legal, technical).
- Incident response playbooks for explanation tampering
- Sectors: security, trust and safety.
- What: Procedures to investigate suspected explanation manipulation in deployed AI systems.
- Tools/products/workflows:
- Runbook for triaging anomalies: replicate outputs under eXIAA, compare against baselines, isolate inputs causing large attribution changes.
- Assumptions/dependencies: Monitoring access to inputs, outputs, and explanation logs; governance to act on findings.
Daily Life
- Practitioner awareness and verification habits
- Sectors: clinicians, radiologists, risk analysts, AV safety operators.
- What: Encourage verification of AI explanations via multiple methods and quick stress-tests (small perturbations) before acting on them.
- Tools/products/workflows:
- Lightweight apps that generate multiple attributions and flag large discrepancies or sensitivity to minor changes.
- Assumptions/dependencies: Availability of explanation outputs; time and workflow allowance to perform checks.
- Content authenticity checks for explanation overlays
- Sectors: media, education.
- What: Teach end-users not to over-trust saliency-style overlays in educational demos or media; validate with alternative methods or known baselines.
- Tools/products/workflows:
- Simple “explanation sanity” widgets for classroom and demo use.
- Assumptions/dependencies: Access to the underlying model or a comparable proxy to generate multiple explanations.
Long-Term Applications
These applications require further research, scaling, method refinement, or regulatory adoption.
Industry
- Cross-domain explanation attack frameworks
- Sectors: healthcare (ECG, EEG), finance (time-series), NLP (text), tabular analytics, audio.
- What: Adapt eXIAA to non-image domains with domain-specific similarity metrics (e.g., DTW for time-series, BLEU/semantic similarity for text).
- Tools/products/workflows:
- Domain-specific “Explanation Red Team” libraries supporting signals, text, and tabular with perceptual or semantic similarity constraints.
- Assumptions/dependencies: New similarity metrics and attribution methods per domain; careful human-in-the-loop validation.
- Explanation tampering detection and “explainability firewall”
- Sectors: platform security, enterprise AI.
- What: Real-time systems that intercept explanation requests, run perturbation tests, rate-limit suspicious activity, and quarantine anomalous explanation behavior.
- Tools/products/workflows:
- “Explainability Firewall” service: generates micro-perturbations, measures consistency across methods, applies anomaly detection to attribution maps.
- Assumptions/dependencies: Compute overhead; integration into production inference; access to explanation APIs.
- Robust XAI model families and training regimens
- Sectors: healthcare diagnostics, AV perception, industrial inspection.
- What: Architectures and training objectives that constrain explanation variability (e.g., consistency losses, sparse self-explainable models like ProtoS-ViT).
- Tools/products/workflows:
- End-to-end training with “explanation adversarial training” using eXIAA injections; multi-objective optimization (accuracy + explanation stability).
- Assumptions/dependencies: Novel losses and evaluation protocols; empirical validation that stability doesn’t degrade accuracy or fairness.
- Forensic tooling for explanation integrity
- Sectors: compliance, digital forensics.
- What: Attribution watermarking or cryptographic signing to attest explanation provenance and detect tampering.
- Tools/products/workflows:
- Explanation provenance logs; integrity checks via signatures anchored in input hashes and model versions.
- Assumptions/dependencies: Standardized logging and signing; chain-of-custody requirements; regulation-driven demand.
Academia
- Formal benchmarks and certification schemes for XAI robustness
- What: Community-wide standards (datasets, protocols, metrics) for certifying that explanation methods pass adversarial robustness thresholds.
- Tools/products/workflows:
- Public leaderboards measuring explanation stability under eXIAA and other attacks; certification criteria for “robust XAI.”
- Assumptions/dependencies: Broad community coordination; sponsorship by standards bodies.
- Theoretical guarantees and invariance-based attribution
- What: Design attribution methods with provable robustness or invariance to small perturbations.
- Tools/products/workflows:
- New methods that tie explanations to causal features or certified gradients; formal analyses of post-hoc fragility.
- Assumptions/dependencies: Advancements in theory and causal ML; tractable certification routines.
- Multi-label and multi-task adaptation of eXIAA
- What: Extend attack and defense strategies to models producing multiple class attributions or multi-task outputs.
- Tools/products/workflows:
- Joint selection of “running-up” classes and class-specific feature injection across multiple heads; multi-head stability metrics.
- Assumptions/dependencies: New selection strategies and metrics; complexity/scalability management.
Policy and Governance
- Regulatory requirements for explanation robustness testing
- Sectors: healthcare (medical devices), finance (credit decisions), automotive (AV safety).
- What: Mandate pre-deployment testing and ongoing monitoring of XAI robustness; define acceptable thresholds and reporting obligations.
- Tools/products/workflows:
- Standardized audit reports including SSIM-based visibility checks and explanation-change metrics; attestation frameworks.
- Assumptions/dependencies: Regulatory capacity; harmonization across jurisdictions; alignment with existing safety/quality standards.
- Liability frameworks and insurance for explanation risk
- Sectors: insurers, legal.
- What: Quantify and price the risk of explanation manipulation or instability in AI deployments.
- Tools/products/workflows:
- Risk scoring models incorporating explanation robustness metrics; premium adjustments and coverage terms linked to certified defenses.
- Assumptions/dependencies: Mature metrics; historical incident data; legal clarity on responsibility.
Daily Life
- Consumer tools for explanation validation
- Sectors: prosumer AI apps, educational platforms.
- What: End-user utilities that compare multiple explanations and flag sensitivity to perturbations before the user trusts a visualization.
- Tools/products/workflows:
- “Trust Check” plugins that run quick eXIAA-style perturbations and display explanation stability scores.
- Assumptions/dependencies: Exposed explanation interfaces in consumer apps; simplified UX for non-experts.
Notes on Assumptions and Dependencies (cross-cutting)
- Attack surface: The eXIAA method requires access to model predictions and post-hoc explanations. If a system does not expose explanations, the attack vector is reduced, but internal users may still be misled if the system generates explanations for them.
- Running-up class availability: Identifying and sourcing a high-confidence “attack image” from the second-most probable class depends on being able to query the model and having a suitable dataset of candidate images.
- Domain-specific similarity: SSIM is appropriate for images; other domains need perceptual/semantic similarity metrics (e.g., DTW for time series, embedding-based similarity for text).
- Architecture sensitivity: The paper finds ViT-B16 explanations more vulnerable than ResNet-18 for comparable prediction stability. Sector adoption plans should account for architecture-specific risks.
- Ethical use: These capabilities should be deployed for auditing, education, and defense. Organizational policies must prevent misuse for deceptive purposes.
Glossary
- Adversarial attack: A targeted manipulation of inputs intended to disrupt a model or its outputs (here, its explanations) without necessarily changing predictions. "a new black-box model-agnostic adversarial attack"
- Adversarial perturbations: Small, carefully crafted input changes that significantly alter a model’s explanations or decisions. "adversarial perturbations to neural network interpretation"
- Ante-hoc methods (interpretable models): Approaches where the model is inherently interpretable and produces explanations alongside predictions. "ante-hoc methods (interpretable models)"
- Backpropagation: The gradient-based procedure used to compute derivatives through a network for optimization or attacks. "requires the ability to perform backpropagation"
- Baseline input: A reference input used by certain attribution methods (e.g., Integrated Gradients) to compute contributions relative to a starting point. "by integrating the gradients with the use of a baseline input "
- Black-box: A setting where the attacker has no access to the model’s internals (architecture, weights) and only uses inputs/outputs. "a new black-box model-agnostic adversarial attack"
- Captum: A PyTorch library providing implementations of model interpretability and attribution methods. "All three methods are used from the Captum Python library"
- CIFAR-10: A benchmark dataset of small images commonly used in computer vision experiments. "on CIFAR-10"
- DeepLIFT: A feature attribution method that propagates contribution scores relative to a reference input through the network. "by extending DeepLIFT to approximate the Shapley value"
- DeepLIFT SHAP: An attribution approach that extends DeepLIFT to approximate Shapley values by averaging attributions over multiple baselines. "DeepLIFT SHAP"
- Feature attribution methods: Post-hoc techniques that assign importance scores to input features based on their influence on a model’s output. "feature attribution methods seek to pinpoint the portions of the input data that significantly affect the prediction"
- First-order Taylor expansion: A linear approximation of a function near an input point; saliency maps interpret gradients as the coefficients of this expansion. "It can be understood as taking a first-order Taylor expansion of the network at the input"
- Gaussian noise: Random perturbations drawn from a normal distribution, often used as a baseline for input corruption. "adding Gaussian noise to the original image"
- ImageNet: A large-scale image dataset widely used for training and evaluating image classification models. "on ImageNet"
- Integrated gradients: An attribution method that integrates gradients along a path from a baseline to the input to compute feature importance. "Integrated gradients"
- Mean absolute difference: A metric that measures the average magnitude of differences, used here to quantify changes in explanations. "compute the induced change based on the explanation with mean absolute difference"
- Model-agnostic: Methods or attacks that do not depend on a specific model architecture or access to its parameters. "model-agnostic adversarial attack"
- Multi-label classification tasks: Problems where each input can belong to multiple classes simultaneously. "adapting the method to multi-label classification tasks"
- One-hot encoding: A vector representation of class labels where only the index of the true class is set to one and others to zero. "one-hot encoding of the classification label"
- One-step attack: An adversarial procedure that computes the perturbation in a single step rather than iteratively. "This provides a one-step attack that proves very effective"
- Poisson blending: An image compositing technique that solves a Poisson equation to blend content seamlessly and reduce artifacts. "Poisson blending"
- Post-hoc explainability methods: Techniques applied after model training to interpret predictions without changing the model. "post-hoc explainability methods (saliency maps, integrated gradients, and DeepLIFT SHAP)"
- ResNet-18: A deep residual neural network architecture with 18 layers, commonly used for image classification. "ResNet-18 model"
- Running-up class: The class with the second-highest predicted probability for a given input, used here to select an attack image. "running-up class"
- Saliency maps: Gradient-based visualizations that highlight input regions most influential to a model’s output. "Saliency maps"
- Saturation problem: A phenomenon where gradients become uninformative due to activation saturation, affecting attribution quality. "saturation problem"
- Shapley value: A game-theoretic measure of feature contribution, representing fair attribution across all coalitions. "Shapley value"
- Structural Similarity Index Measure (SSIM): A perceptual metric comparing images on luminance, contrast, and structure to quantify similarity. "Structural Similarity Index Measure (SSIM)"
- Transformer-based architecture: Neural network models utilizing self-attention mechanisms, such as Vision Transformers. "transformer-based architecture"
- ViT-B16: A Vision Transformer model variant using 16×16 image patches for classification. "ViT-B16"
- Weighted sum: A blending operation that combines original and attack pixels using a weighting parameter to control visibility. "We use a weighted sum with parameter "
Collections
Sign up for free to add this paper to one or more collections.