- The paper shows that integrating Chain-of-Thought significantly boosts LLMs' state tracking accuracy across sequential tasks.
- It employs three tailored benchmarks—LinearWorld, HandSwap, and Lights—to isolate and measure state update capabilities.
- Experimental results indicate that newer LLMs like GPT-4 maintain higher performance even with increased task complexity.
Exploring State Tracking Capabilities of LLMs
Introduction
The ability of LLMs to perform state tracking—maintaining and updating an internal representation of a system's state—has significant implications for tasks requiring sequential reasoning and dynamic context management. This paper evaluates the state tracking proficiency of state-of-the-art LLMs through a newly designed benchmark featuring three distinct tasks: LinearWorld, HandSwap, and Lights. The paper contrasts the performance of different models, including prominent versions like GPT-4 and Llama3, with particular emphasis on the effects of the Chain of Thought (CoT) prompting technique.
Methodology
The authors devised three probing tasks to isolate and evaluate the state tracking capabilities of LLMs. These tasks are designed to be both simple for human solvers and varied in presentation to minimize performance variance due to superficial differences. The tasks include:
- LinearWorld: Involves tracking the positions of entities on a linear scale.
- HandSwap: Challenges models to determine item ownership among individuals after a series of swaps.
- Lights: Requires models to determine the status of lights in various rooms based on sequences of switch activations.
The tasks are intentionally straightforward, allowing focus on the core capability of following and updating state. The models assessed include cutting-edge LLMs such as GPT-4 and Llama3 70B, alongside those from the previous generation, like GPT-3.5 and Mixtral.
Experimental Results
The experiments reveal notable findings:
- Depth Impact: Model performance generally diminishes as task depth increases. Newer models, especially when using CoT, maintain higher accuracy over longer sequences of updates compared to older models.
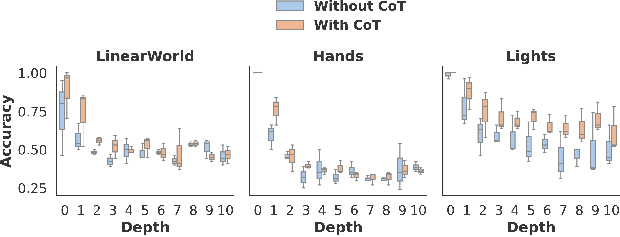
Figure 1: Average accuracy at different depths across tasks (left: LinearWorld, middle: Hands, and right: Lights) for all systems except for the two top performers which use Chain of Thought (CoT), i.e., Llama3 70B and GPT-4.
- Chain of Thought: CoT prompting significantly enhances performance, as it encourages models to use the input context as a form of memory. Systems like GPT-4, when instructed with CoT, leverage this mechanism effectively, resulting in higher accuracy on state tracking tasks.
- State Versus Stateless Baselines: Results show LLMs outperform a naive stateless baseline, suggesting they can integrate update information to some degree, although difficulties remain especially at deeper levels of state changes.
Analysis
Several complementary studies underscore these findings:
- Update Type Effect: The models perform better on tasks with "integer" update types than "swap" updates. Integer-based tasks seem to facilitate models' logical follow-through by appealing to their ability to perform simple arithmetic operations.

Figure 2: Accuracy at different depths comparing the "swap" update type with the "integer" update type in the LinearWorld task (the state-dependent query variants) for all CoT integrated systems.
- Mathematical Operations: LLMs like GPT-4 demonstrate proficiency in handling arithmetic by generating accurate mathematical expressions, a key component in tasks requiring numerical reasoning.
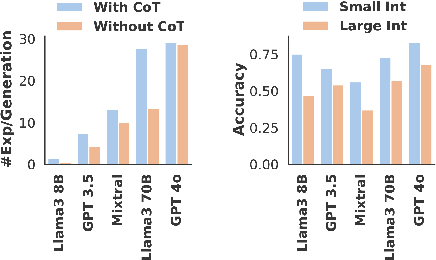
Figure 3: Average number of mathematical expressions per model response for all the models (left), and accuracy of generated expression evaluations across models integrated with CoT (right).
Implications and Future Work
This paper highlights the steady progression of new-generation LLMs in tracking states through sophisticated CoT strategies. The research suggests that enhancing LLMs' reasoning abilities can be instrumental in practical applications involving dialogue management and multi-step reasoning tasks. Future work could explore augmenting LLMs with external memory systems to further enhance state tracking capabilities and address the performance drop seen at greater depths.
Conclusion
This investigation elucidates the evolving capacity of LLMs to maintain and update states throughout complex interactions, showcasing particular strengths and weaknesses of various models. The fine-tuned integration of CoT demonstrates that simple adjustments in prompting techniques can significantly impact LLM efficacy in state tracking tasks. This work lays a foundation for further advancements in the integration of memory functions within LLM frameworks.