- The paper introduces a dual UNet approach that effectively handles imbalanced precipitation data using full-spectrum GEO imagery.
- The model outperforms existing GEO and PMW-based algorithms, achieving significant improvements in CSI and retrieval accuracy for light precipitation events.
- Pretraining on IMERG and rigorous augmentation strategies enhance real-time global scalability, offering practical applications in hydrology and disaster management.
Oya: Deep Learning Approaches for Global Precipitation Estimation
Introduction and Motivation
Oya presents a machine learning methodology for real-time global precipitation estimation using the full spectrum of visible and infrared (VIS-IR) data from geostationary (GEO) satellites. Unlike conventional algorithms that restrict themselves to single-channel IR data or regional calibration, Oya integrates multi-band observations from a GEO constellation and leverages deep learning (specifically dual UNet architectures) to handle highly imbalanced rain/no-rain events. The approach is tailored to data sparsity challenges in the Global South, where ground-based sensors and radar networks are rare, undermining traditional precipitation monitoring and forecasting frameworks. Oya’s primary contributions lie in its universal spectral input, effective ground truth alignment using GPM CORRA v07, and a robust pretraining pipeline employing IMERG Final retrievals.
Data Handling and Training Pipelines
Oya’s supervised training routine involves collocating GEO satellite multispectral frames with GPM CORRA precipitation estimates. Input-output pairs are mapped to a global grid (nominal $5$ km resolution at the equator) and partitioned into 128×128 spatial patches ($640$ km2 area). Only patches overlapping valid GPM CORRA swaths are retained as training samples.

Figure 1: Pipeline for creating training examples by patching and aligning GEO imagery with GPM CORRA precipitation swaths.
Due to the sparseness of GPM CORRA temporal sampling, pretraining on IMERG Final (with its complete global coverage and extensive temporal range) is critical. Validation is strictly performed on withheld 2022 data to guarantee generalization.
Architectural and Learning Innovations
Class Imbalance Strategy
Precipitation ground truth (GPM CORRA) shows severe class imbalance: non-precipitation is 18× more common than precipitation, and within precipitation, light events vastly outnumber heavy/extreme events.
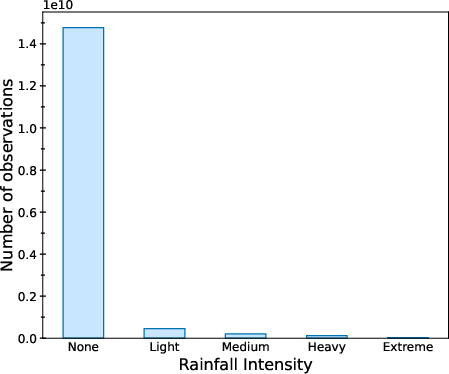
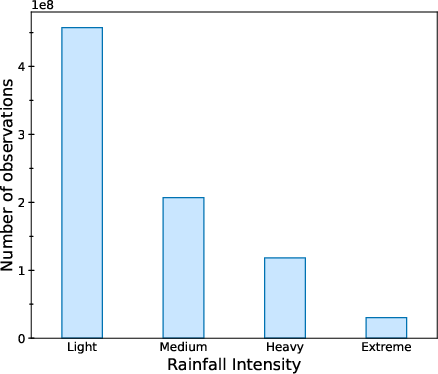
Figure 2: (a) Distribution of GPM CORRA v07 observations demonstrates the extreme imbalance between no-precipitation and precipitation samples. (b) Breakdown of precipitation events further highlights the predominance of light precipitation.
Rather than using costly oversampling or brute-force loss reweighting, Oya decomposes the task into:
- Event detection: A UNet classifier discriminates precipitation vs. no-precipitation.
- Quantitative Estimation (QPE): A UNet regressor predicts rainfall rates only for precipitation-positive pixels.
To mitigate skew and enhance regression stability, targets are log-transformed; training loss for QPE is further reweighted according to inverse label density estimated using Label Distribution Smoothing (LDS).
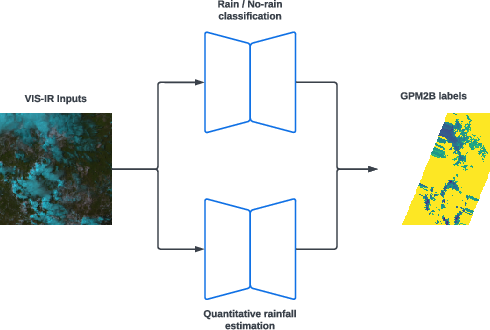
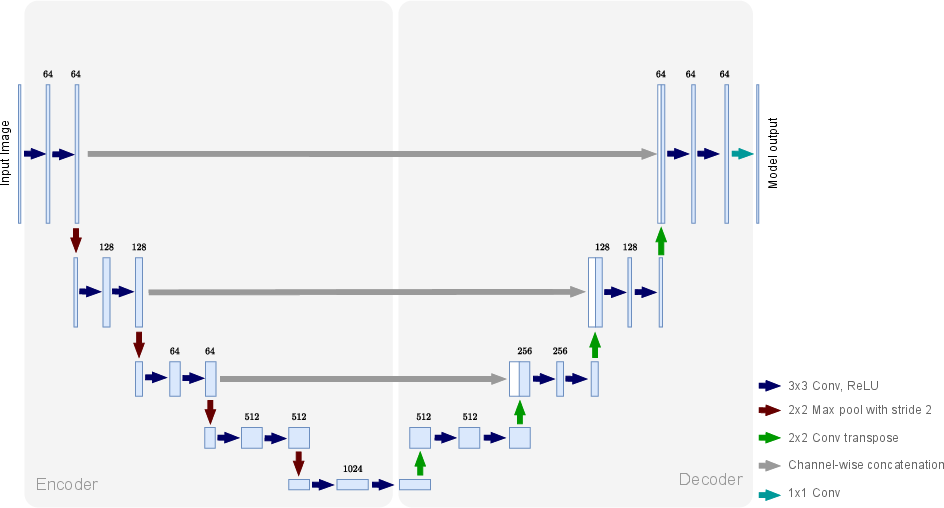
Figure 3: (a) Oya architecture combining a UNet-based event detector and rain rate regressor; (b) standard UNet block with encoder-decoder and skip connections.
Augmentation and Transfer Learning
Physical plausibility in satellite data augmentation is maintained via spatial ops: random flips and 90∘ rotations applied to both input and target. Transfer learning is used by pretraining both UNets on IMERG Final data and fine-tuning with GPM CORRA—leveraging noisy but abundant labels, consistent with empirical findings in robust deep learning.
Empirical Validation and Results
Retrieval metrics such as Critical Success Index (CSI), Probability of Detection (POD), Frequency Bias (Bias), and False Alarm Ratio (FAR) are employed. For the African subregion:
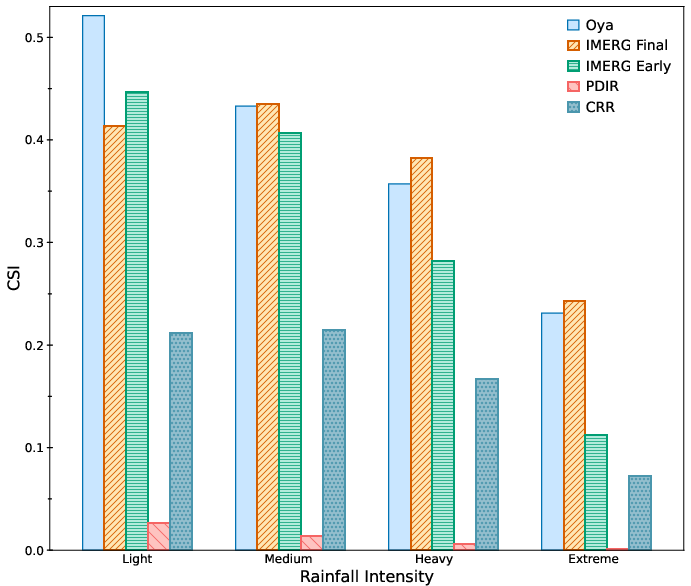
Figure 4: CSI and related metrics (POD, FAR, Bias) for various retrieval products over Africa. Oya demonstrates markedly superior performance against both GEO-centric and PMW-based baselines.
Oya outperforms both regional and global GEO baselines (CRR, PDIR-Now) on all thresholds. For instance, on light precipitation, Oya's CSI exceeds CRR by >30 points. Notably, Oya also surpasses IMERG Early and is competitive with IMERG Final—despite the latter’s access to comprehensive PMW inputs and delayed post hoc calibration.
Extending to full Meteosat 0∘ coverage experiences a uniform performance drop mainly attributable to limb darkening and parallax in high-latitude observations; mitigation strategies for these nonlinear artifacts remain an open challenge.
Global Analysis
Oya models trained on additional GEO sources (Himawari, GOES) sustain their advantage over IR-only products (PDIR-Now), display robust CSI across all intensity bins, and outperform IMERG Early. A global performance map shows highest accuracy in tropical regions, with decay toward higher latitudes and poor performance in arid/high-altitude geographies.
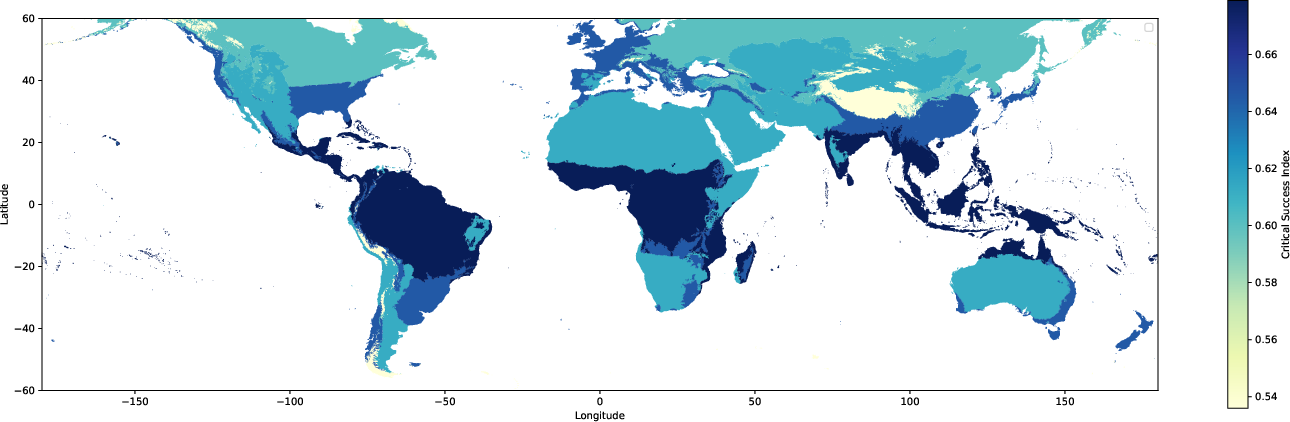
Figure 5: CSI map for Oya precipitation estimates globally, highlighting strongest retrieval skill in tropical zones and declining skill with latitude and altitude.
Case Studies
For extreme events (e.g., August 2022 South Sudan storm), Oya reproduces precipitation structures observed by GPM CORRA more reliably than competitors, notably outperforming both GEO-only and PMW+IR fusion baselines on detection and intensity metrics.


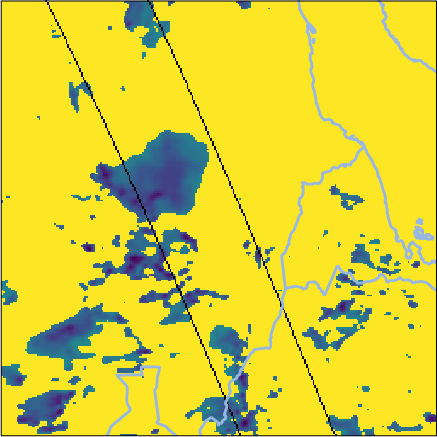
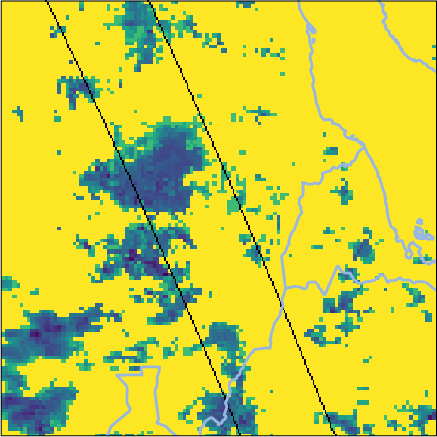
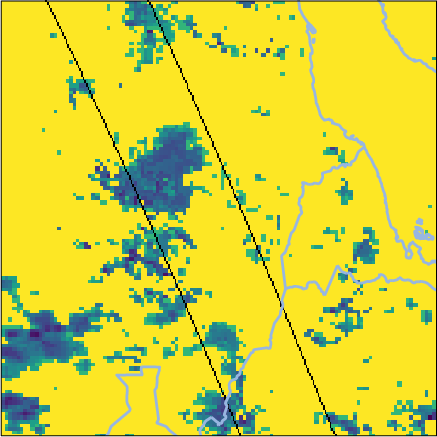
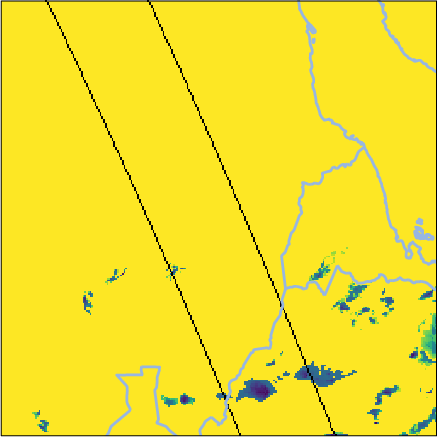
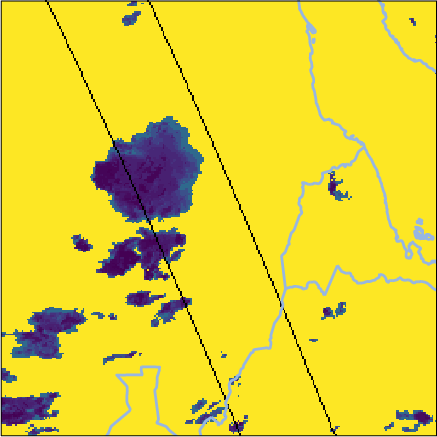
Figure 6: Side-by-side retrievals for a South Sudan precipitation event; Oya’s reconstruction aligns tightly with GPM CORRA and exceeds baseline fidelity.
Ablation Studies
A systematic evaluation isolates the contributions of core design decisions:
- Full spectrum input: Inclusion of all GEO channels improves CSI by >10 points over IR-only models.
- Augmentation: Data augmentation yields +6 CSI for light rain, enhancing generalizability.
- Pretraining: IMERG-based pretraining raises downstream GPM CORRA estimation across all bins.
- Patch size: Context size 64×64 gives optimal balance—larger patches do not yield further gains at $5$ km resolution.
- LDS loss reweighting: Particularly beneficial in boosting recall for heavy/extreme events.
Generation and Release of Global Estimation Dataset
The full inference pipeline outputs a merged global precipitation dataset (2004–present), combining overlapping GEO retrievals and harmonizing across variable satellite records. The dataset is deployed on Google Earth Engine for open access.
Practical and Theoretical Implications
Oya’s approach demonstrates that deep learning architectures, when paired with the full spectral richness of GEO satellites and informed by rigorous pretraining, can equal or surpass current research-grade precipitation products—despite photospheric limitations and patchy ground truth. This has immediate utility for hydrology, disaster management, and climatology, especially in data-scarce regions.
Challenges remain: correcting nonlinear artifacts in higher latitudes, resolving parallax and calibration for severe weather, and extending to even higher spatial and temporal resolutions as new GEO hardware becomes available. The dual-network approach may extend to other climatological retrieval problems where label imbalance and multispectral correlation are problematic.
Conclusion
Oya represents a technically rigorous blending of satellite remote sensing, deep convolutional architectures, and statistical learning strategies to enable real-time, global precipitation estimation with high accuracy and competitive latency. The empirical results—particularly the consistently superior CSI and robust recall—underscore the utility of the full spectral strategy and the importance of transfer learning from noisy but abundant labels. The publicly released dataset provides a foundational resource for downstream meteorological and hydrological research. Further refinement of Oya, particularly with regard to edge-case geographies and extreme weather calibration, could drive future advances in satellite-based environmental monitoring.