Beyond Exascale: Dataflow Domain Translation on a Cerebras Cluster
Abstract: Simulation of physical systems is essential in many scientific and engineering domains. Commonly used domain decomposition methods are unable to deliver high simulation rate or high utilization in network computing environments. In particular, Exascale systems deliver only a small fraction their peak performance for these workloads. This paper introduces the novel \algorithmpropernoun{} algorithm, designed to overcome these limitations. We apply this method and show simulations running in excess of 1.6 million time steps per second and simulations achieving 84 PFLOP/s. Our implementation can achieve 90\% of peak performance in both single-node and clustered environments. We illustrate the method by applying the shallow-water equations to model a tsunami following an asteroid impact at 460m-resolution on a planetary scale running on a cluster of 64 Cerebras CS-3 systems.


Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
A simple explanation of “Beyond Exascale: Dataflow Domain Translation on a Cerebras Cluster”
Overview: What is this paper about?
This paper is about making big physics simulations run much faster on large computer clusters. The authors introduce a new way to organize the work, called Domain Translation, so that computers don’t have to wait around for messages from each other. They show it working on a special kind of hardware (Cerebras wafer-scale systems) and use it to simulate things like heat flow and giant ocean waves (tsunamis) on a global scale.
Key questions the paper asks
- Can we run physics simulations across many machines without being slowed down by network delays (the time it takes messages to travel between machines)?
- Is there a better method than the usual “cut the problem into chunks and exchange border data every step” approach?
- Will this new method scale up smoothly to lots of chips and still be efficient?
- Can it handle a realistic, hard problem like global tsunami modeling at high resolution?
How it works (methods) in everyday language
To understand the method, it helps to know three ideas:
- What a “stencil” is Many simulations (like heat spreading or water waves) use a grid. At each time step, every grid cell updates its value using only its nearby neighbors. This local “look at your neighbors” rule is called a stencil.
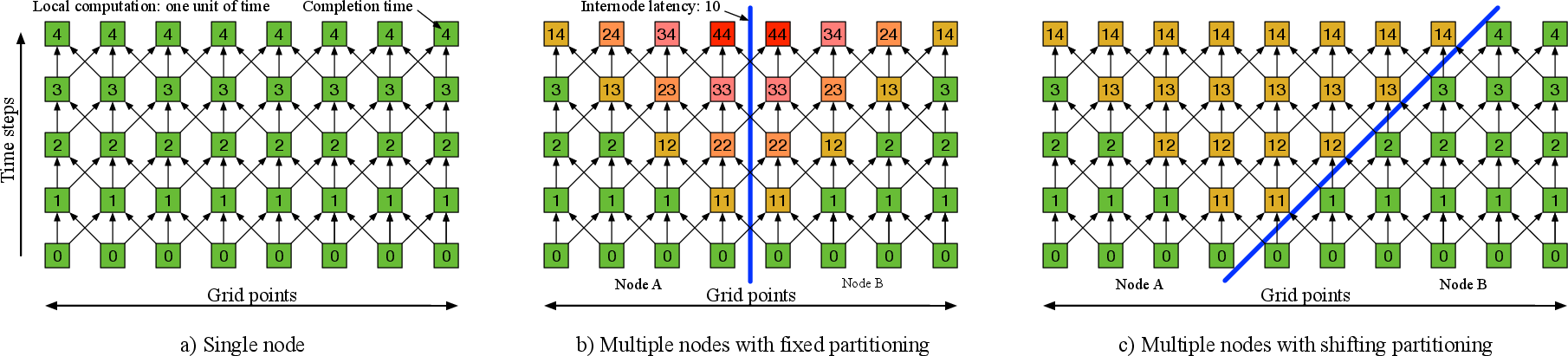
- Why big clusters slow down Normally, a huge grid is split into chunks and given to different machines. After each time step, machines must exchange border values with neighbors. This back-and-forth across the network can be slow (network “latency”), and it happens at every step, so the whole simulation gets stuck waiting.
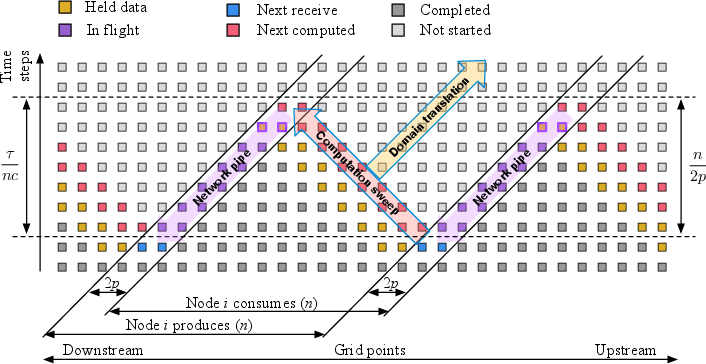
- The new idea: Domain Translation Instead of keeping the chunk borders fixed, the authors let the border “slide” across the grid by a small amount every time step—like a moving fence. Data then flows mostly in one direction, like cars on a one-way street, instead of constantly bouncing back and forth. Each piece of data only pays the “network delay” once as it passes through, instead of paying that cost at every step. Analogy: Imagine a relay race on a moving walkway. If runners pass the baton forward on the walkway (one direction), the baton moves quickly overall and doesn’t keep stopping. Traditional methods are more like passing the baton back and forth across a busy street—lots of waiting at every exchange.
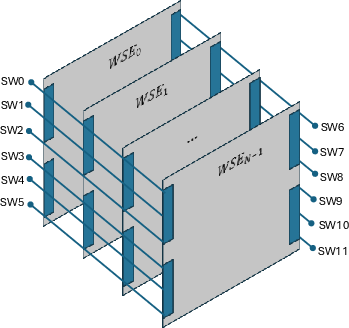
On top of this, the code runs on Cerebras wafer-scale engines (WSEs). These are giant chips with hundreds of thousands of tiny processors, each with its own small memory, all connected in a tight grid inside the chip. This “spatial” design lets nearby processors talk very fast, and the simulation naturally matches this layout because it also works with neighbors. The cluster links many such wafers together.
What they implemented and tested:
- Heat equation with 5-point and 9-point stencils (simple, classic physics test).
- Shallow Water Equations (SWE) for ocean waves, using a stable and accurate method (a two-stage Runge-Kutta time scheme with a Lax–Wendroff spatial step).
- They ran across up to 64 Cerebras CS-3 systems, measured time steps per second, math operations per second (FLOPs), and how well performance “scales” as you add more machines.
Main findings and why they matter
Here are the highlights from their results:
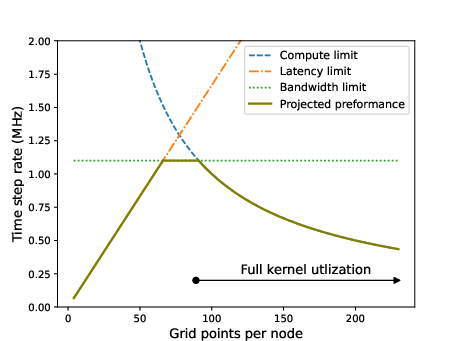
- They hide network delay completely once each machine has a modestly large chunk of the grid. That means performance is no longer limited by latency—it’s limited only by how fast the chips compute or how much network bandwidth you give them.
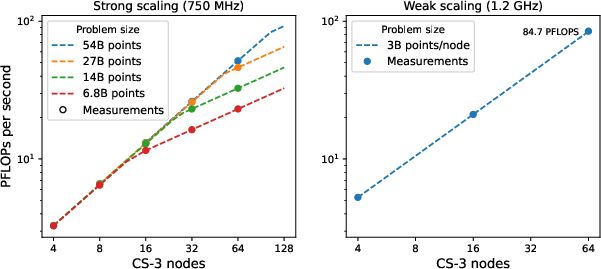
- Near-perfect scaling: As they add more machines, the speed increases almost exactly as expected (very rare and very good for big simulations).
- Very high speed: They achieved more than 1.6 million time steps per second in some runs, and up to 84.7 PFLOP/s (that’s 84.7 quadrillion math operations per second) on 64 systems, which is about 66% of the hardware’s peak in that setup.
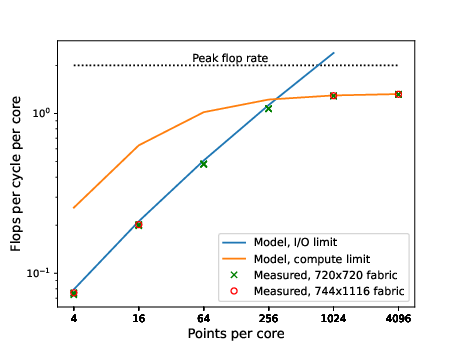
- High efficiency: In different tests, their method approaches about 90% of peak performance on both single machines and across the cluster, which is exceptional for this kind of problem (stencils are often memory- and communication-limited).
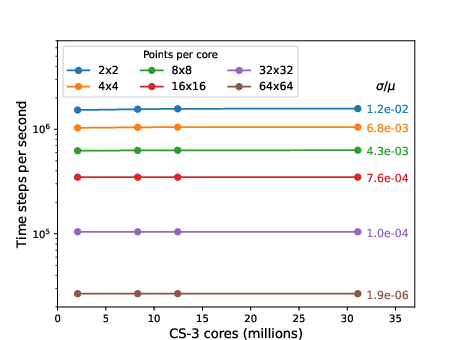
- Good even at small per-processor workloads: It stays efficient down to about 256 grid points per tiny processor, meaning you don’t need huge chunks to get good speed.
- Strong energy efficiency: About 57 GFLOPs per watt for large runs.
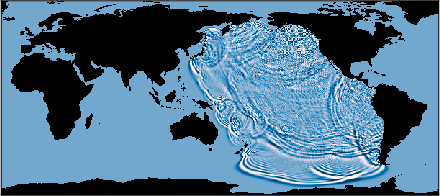
- Real-world demo: They simulated tsunami wave propagation across the whole planet at about 460-meter resolution using the Shallow Water Equations on a 64-node cluster—showing the method can handle serious, practical problems.
- Trustworthy model: Their simple performance model (based on compute and bandwidth, ignoring latency) matches the measurements very closely, confirming that latency is truly hidden.
Why this matters:
- Traditional methods either run fast but waste a lot of work (by recomputing data in “ghost” regions) or they run efficiently but are slowed by latency at every step. Domain Translation avoids both traps—no repeated waits, no heavy waste.
- This unlocks fast, scalable simulations for many physics problems on large clusters, not just on a single chip.
What could this change in the future?
- Faster, more accurate science: Weather prediction, climate models, ocean modeling, earthquake or tsunami early-warning studies, and many other physics-based simulations could run faster and at higher resolution.
- Better use of big computers: Supercomputers and specialized chips can be used more efficiently, saving time and energy.
- Scaling beyond today: Because the method removes the latency roadblock, it should keep working well as clusters get larger and networks get faster.
In short, the paper introduces a clever way to “keep the data flowing in one direction,” so the simulation doesn’t keep stopping to wait for messages. Combined with hardware that matches the problem’s local-neighbor pattern, it delivers unusually high speed, excellent scaling, and strong efficiency—even for big, real-world simulations like global tsunamis.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, concrete list of what remains missing, uncertain, or unexplored in the paper, framed to guide follow-on research.
- Formal analysis is incomplete: no proof of correctness, stability, or convergence of Domain Translation (DT) for general PDE classes, higher-order stencils, and multi-stage integrators beyond the qualitative argument and a 1D sketch.
- The critical threshold for latency hiding () is stated but not validated across varying network latencies, bandwidths, or topologies; sensitivity studies and empirical verification are absent.
- The algorithm’s dependence on a ring/torus logical topology is assumed but not generalized; how to construct efficient overlays on non-torus fabrics (fat-trees, Clos) and quantify overheads is not addressed.
- Cluster-level constraints introduced by checkerboard mirroring (requiring node counts be multiples of four) are not resolved or generalized to arbitrary cluster sizes and layouts.
- Start-up and shut-down (pipeline fill/flush) costs are not quantified; impact on short-run or checkpoint-heavy workloads is unknown.
- Fault tolerance is not discussed: how DT handles packet loss, jitter, link/node failures, or mid-run topology changes (re-routing, recovery, or rebalancing) is unspecified.
- Load imbalance and heterogeneity are not addressed; there is no mechanism described for performance variability (e.g., power throttling) or uneven workloads across nodes without breaking the unidirectional pipeline.
- Applicability to 3D domains is asserted but not demonstrated; the effects on memory capacity per core, bandwidth, and translation strategy in 3D (edges, faces, corners) remain unexplored.
- Extension beyond structured grids is unaddressed; how DT applies to unstructured meshes, AMR, or irregular dependencies (e.g., finite element/volume on general meshes) is open.
- The approach targets explicit/local stencils; support for implicit methods, elliptic solves, or PDEs requiring global reductions (e.g., Poisson, pressure projection) is not considered.
- Numerical stability/accuracy impacts of continuous state migration are not analyzed; interactions with CFL limits, error propagation, and order-of-operations effects under DT (especially for nonlinear systems) are not studied.
- Boundary conditions beyond periodic/torus-like wrapping are not treated in detail; how DT handles physical boundaries, complex geometries, obstacles, or mixed Dirichlet/Neumann conditions is unclear.
- For multi-stage methods (e.g., SWE with RK2 + Lax–Wendroff), the general rule for choosing translation distance per sub-step and synchronization across half-steps is not formalized.
- Additional bandwidth due to moving “full state” with each grid point is not quantified; there is no comparison of bytes moved per time step against static decomposition for different numbers of fields (e.g., 7 in SWE).
- I/O bottlenecks acknowledged by the authors (redundant vertical transmissions and equal channel provisioning) are not fixed; quantitative impact and expected gains from proposed optimizations (e.g., transmit filtering, channel pooling) are not provided.
- Link utilization and congestion are not measured; absence of per-link throughput/latency/jitter data leaves uncertainty about bottlenecks at larger scales or under mixed-direction traffic.
- Scalability beyond 64 nodes is claimed as future work; no evidence or model-based projection with confidence bounds is given for 100s–1000s of nodes or for different interconnects.
- The comparison baseline is missing; there is no head-to-head with overlapping (ghost) domain decomposition or communication-avoiding schemes on the same hardware/cluster to quantify speedup and efficiency gains.
- Relation to prior art (e.g., swept time–space decomposition, time skewing, communication-avoiding temporal blocking) is not addressed; similarities/differences and why DT offers advantages are not discussed.
- Reproducibility is limited: code and configuration artifacts (routing recipes, virtual channel allocation, compiler versions) are not made available; key implementation details (e.g., message formats, flow control) are omitted.
- Numerical validation for the SWE tsunami scenario is absent; no benchmark comparisons, conservation diagnostics (mass/energy), or verification against analytical/standard test cases are reported.
- Physical modeling details for SWE are incomplete (e.g., wetting/drying scheme, shoreline treatment, friction, dissipation, handling of shocks/bores), and their impact on stability/accuracy under DT is unknown.
- Projection choice (Mercator) at planetary scale introduces severe polar distortions; treatments near poles, time-step restrictions across latitudes, and numerical stability in high-lat regions are not evaluated.
- Precision is not discussed: results and peak rates are reported for single precision; the effect of double precision (common in geophysics) on performance, bandwidth, and stability is not quantified.
- Energy-efficiency methodology is under-specified; power figures rely on rated or throttled scenarios without external metrology, and comparisons to Green500 (dense linear algebra) are not normalized for workload type.
- On-wafer routing choices (daisy chains, turns, 8 virtual channels) could create hotspots; there is no contention analysis, buffering assessment, or deadlock/livelock proof for the chosen routing.
- Checkpointing and I/O are not integrated; how to capture a consistent global “time slice” under a continuously translating domain (and the associated performance overhead) is unaddressed.
- Portability to other spatial/dataflow hardware (Dojo, Groq, SambaNova) or to GPUs/CPUs is not demonstrated; DT’s dependence on WSE-specific features (e.g., multicast virtual channels, wavelet routers) raises unanswered portability questions.
- The claim of “no host-device interaction” omits job control, debugging, and monitoring considerations; mechanisms for safe orchestration, failure recovery, and observability at scale are not provided.
- Parameter selection guidance is thin; there is no principled method to choose translation distance, packetization, or core/node tilings for a given PDE, stencil radius p, and network characteristics.
- Short-run performance is not characterized; when pipeline fill cost is non-negligible (small iteration counts), DT’s time-to-solution relative to standard methods is unknown.
- Some reported latencies and equations appear inconsistent or partially mangled (e.g., latency averaging calculation, SWE equation notation), which hinders independent validation.
Practical Applications
Immediate Applications
The paper’s Domain Translation algorithm and its implementation on a 64-node Cerebras CS-3 cluster enable deployable improvements for stencil-based, explicit time-stepping PDE workloads where spatial locality dominates and inter-node latency typically throttles throughput. The following use cases can be acted on now by organizations with access to similar hardware or by vendors packaging the framework.
- Scientific HPC (Academia, National Labs, Industry R&D) — Latency-immune stencil solvers on Cerebras clusters
- What: Port explicit, structured-grid PDE kernels (e.g., heat/diffusion, linear/nonlinear advection, wave equations, shallow-water, FDTD electromagnetics) to the provided Tungsten-based stencil framework with Domain Translation to achieve high utilization and near-perfect weak scaling.
- Sectors: Software, Energy, Materials, Aerospace, Semiconductor, Defense.
- Tools/Workflows: Use the provided ~1K LOC stencil framework; adapt 5-/9-point and SWE examples; integrate with cluster job schedulers; deploy performance model calculator to size n, p, and IO.
- Assumptions/Dependencies: Access to Cerebras CS-3 nodes or similar spatial architectures; workloads fit explicit, local stencils; subdomain size satisfies n2 > 2 p λ / c; bandwidth is provisioned to avoid IO-bound regime; tolerance for porting code to Tungsten DSL.
- Weather and ocean modeling components (Operational forecasting, Research)
- What: Accelerate dynamical core kernels (e.g., shallow-water prototypes, barotropic/baroclinic splits, transport steps) for ensemble throughput, sensitivity studies, and parameter sweeps.
- Sectors: Healthcare-adjacent public safety (heatwaves), Energy (wind/solar forecasting), Public sector weather agencies.
- Tools/Workflows: Standalone SWE kernels for tsunami and gravity-wave propagation; pre-/post-processing to ingest bathymetry and output hazard maps; ensemble orchestration on Cerebras clusters.
- Assumptions/Dependencies: Validation against production models (FV3, MPAS, ICON, NEMO/ROMS); coupling to non-stencil physics, assimilation, and I/O stacks; governance for operational adoption.
- Rapid tsunami hazard simulation (Disaster risk analytics and planning)
- What: Use the SWE implementation to run fast planetary-scale tsunami scenarios (e.g., asteroid- or quake-driven) and produce inundation and arrival-time products for planning and drills.
- Sectors: Public policy, Insurance/Reinsurance, Infrastructure owners.
- Tools/Workflows: Data ingestion (GEBCO bathymetry), scenario libraries, automated map generation, web service for hazard layers.
- Assumptions/Dependencies: Event characterization pipeline (source models), local inundation models for nearshore detail, uncertainty quantification, integration with alerting protocols.
- Energy and subsurface imaging (Oil & gas, CCS, Geothermal)
- What: Speed up wave-equation solvers for seismic modeling and reverse-time migration using Domain Translation to mitigate latency across nodes.
- Sectors: Energy.
- Tools/Workflows: Port acoustic/elastic wave stencils; integrate with existing imaging pipelines; performance planner to balance points-per-core and link provisioning.
- Assumptions/Dependencies: Structured-grid discretizations; memory footprint per core; pre/post processing kept off critical path or pipelined; cluster interconnect configured as per mirror/checkerboard scheme.
- Electromagnetics (Antenna/RCS/FDTD)
- What: Boost FDTD and related stencil computations for design sweeps and optimization loops.
- Sectors: Aerospace/Defense, Telecom.
- Tools/Workflows: Stencil translation of Maxwell solvers; batch parameter studies; tie-in with optimization/adjoint workflows.
- Assumptions/Dependencies: Explicit, local updates; handling of material interfaces and absorbing boundary conditions in a translating partition.
- Green HPC benchmarking and cost/performance optimization
- What: Apply the demonstrated 57 GFLOPs/W sparse-compute efficiency to lower energy and cost per simulation for stencil-heavy workloads.
- Sectors: HPC operations, Sustainability.
- Tools/Workflows: Power-optimized kernels (e.g., 9-point HE at 1.2 GHz with cache-aware code); cluster-level power monitoring; schedule runs in optimal thermal bands.
- Assumptions/Dependencies: Availability of clock-boost and thermal management; workloads dominated by compute-bound stencil steps.
- Education and training (Courses, tutorials, workshops)
- What: Use the compact Tungsten implementations and the paper’s performance model to teach latency-hiding, dataflow computing, and stencil optimization on spatial architectures.
- Sectors: Academia, Professional training.
- Tools/Workflows: Hands-on labs with heat equation and SWE kernels; “n–p–λ–c” calculator for performance planning; visualization of domain translation in space-time.
- Assumptions/Dependencies: Access to simulators or time on Cerebras hardware; instructors familiar with dataflow concepts.
- HPC service providers — “Stencil-as-a-Service”
- What: Offer packaged Domain Translation-enabled solvers (heat/SWE templates) on WSE clusters via APIs for clients needing fast explicit PDE runs.
- Sectors: Software, Cloud HPC, Consulting.
- Tools/Workflows: Multi-tenant cluster orchestration; SDKs for job submission; templated kernels; billing tied to simulated-timestep throughput.
- Assumptions/Dependencies: Capacity planning for IO links; standardized data formats; SLAs around throughput and queueing.
Long-Term Applications
Beyond the immediate stencil workloads on spatial architectures, the method points to broader transformations in simulation throughput, decision support, and hardware/software co-design. These require further research, scaling, integration, and validation.
- Global digital twins and real-time Earth system forecasting
- What: Kilometer-scale global weather/ocean models with near-real-time ensemble updates and rapid parameter studies for decision support (e.g., aviation, energy grid).
- Sectors: Public policy, Energy, Transportation, Insurance.
- Tools/Workflows: Domain Translation inside next-gen dynamical cores; streaming data assimilation pipelines; ensemble management; on-demand scenario generation.
- Assumptions/Dependencies: Extensive model refactoring (explicit kernels + fast coupling to non-stencil physics), scalable IO/assimilation, validation and certification; significant Cerebras-scale capacity or future spatial hardware.
- City- and basin-scale hazard early warning at operational cadence
- What: Operational tsunami/flood/ surge forecasts at resolutions supporting evacuation and infrastructure control, delivered within minutes of event detection.
- Sectors: Public safety, Municipal planning, Utilities.
- Tools/Workflows: End-to-end pipeline (sensor ingest → source inversion → fast SWE/CFD stencils → inundation mapping → alerting APIs); uncertainty and ensemble products.
- Assumptions/Dependencies: Regulatory approval, robust QA/QC, integration with legacy alert networks, high-resolution topography/roughness data.
- High-throughput aerospace/automotive design with dynamic CFD
- What: Near-real-time digital wind tunnels enabling interactive design space exploration, adjoint-based optimization, and robust control testing.
- Sectors: Aerospace, Automotive, Industrial design.
- Tools/Workflows: Partitioning and stabilization for compressible Navier–Stokes stencils; coupling with turbulence models; optimization frameworks.
- Assumptions/Dependencies: Portability of more complex stencil operators; ensuring numerical stability with translating domain boundaries; hardware memory capacity for multi-variable fields.
- Next-generation seismic imaging, CO2 storage, geothermal reservoir management
- What: Faster full-waveform inversion and uncertainty quantification; on-demand risk assessment for CCS plume, induced seismicity.
- Sectors: Energy, Climate tech.
- Tools/Workflows: Extended stencil sets (anisotropy, attenuation); multi-physics (poroelasticity); ensemble workflows with Domain Translation-enabled kernels.
- Assumptions/Dependencies: Efficient checkpointing and adjoint recomputation within moving partitions; scalable in-situ reduction/IO.
- Financial engineering PDE engines
- What: Low-latency, high-throughput pricing and risk on PDE grids (e.g., multi-factor Black–Scholes, HJB equations) for intraday risk and stress scenarios.
- Sectors: Finance.
- Tools/Workflows: Explicit finite-difference solvers mapped to Domain Translation; scenario batching; API services for trading/risk platforms.
- Assumptions/Dependencies: Suitability of explicit schemes for stability constraints; mapping higher-dimensional stencils to available memory; model validation.
- Standardization of Domain Translation in mainstream HPC frameworks
- What: Integration into Kokkos/RAJA/GridTools/Legion-like frameworks and MPI runtimes to support translating partitions and pipeline-friendly messaging on heterogeneous clusters (GPU/CPU/spatial).
- Sectors: Software.
- Tools/Workflows: Compiler/runtime support for partition shifting, link scheduling, and automatic mirroring; performance models in autotuners.
- Assumptions/Dependencies: R&D investments; NIC/driver features for ordered pipeline transfers; community adoption.
- Hybrid solvers for nonlocal/implicit physics
- What: Combine Domain Translation for explicit local updates with latency-tolerant preconditioners/multigrid for elliptic components (pressure solves, Poisson equations).
- Sectors: Weather/climate, CFD, Plasma physics.
- Tools/Workflows: Operator splitting; asynchronous Krylov/multigrid with communication-avoiding techniques; mixed-precision strategies.
- Assumptions/Dependencies: Algorithmic research; stable coupling across translating partitions; reprojection/redistribution overheads.
- Hardware co-design and network architectures
- What: Future spatial processors and interconnects optimized for unidirectional, pipeline-sustained dataflows (e.g., on-die support for partition translation, VC-rich NoCs, low-energy off-wafer rings/tori).
- Sectors: Semiconductors, HPC systems.
- Tools/Workflows: Co-design benchmarks (stencil suites), RTL features for message pacing/replication filters, on-wafer mirroring primitives, diagnostic counters aligned to the “n–p–λ–c” model.
- Assumptions/Dependencies: Vendor roadmaps; market adoption; standard APIs.
- Personalized climate and risk analytics for the public
- What: Location-specific, quickly updated hazard layers (flood, heat, surge) for insurance, mortgages, urban planning, and citizen apps.
- Sectors: Daily life, Finance/Insurance, Real estate.
- Tools/Workflows: Cloud APIs backed by fast stencil simulations and surrogate models; map UXs; integration with policy tools.
- Assumptions/Dependencies: Data licensing and privacy; explainability and uncertainty communication; regulatory oversight.
- Curriculum and workforce development in dataflow HPC
- What: Programs that prepare engineers/scientists to build latency-immune, dataflow-first solvers and reason about performance with simple analytic models.
- Sectors: Academia, Workforce development.
- Tools/Workflows: DSLs (Tungsten) and emulators; interactive space-time visualization; open benchmark suites.
- Assumptions/Dependencies: Open educational resources; sustained access to suitable hardware or simulators.
Cross-cutting assumptions and dependencies impacting feasibility
- Algorithmic fit: Best for explicit, structured-grid stencil computations with bounded stencil reach p; complex global couplings and irregular meshes need additional research.
- Hardware model: Highest gains demonstrated on spatial architectures (Cerebras WSE) with low on-chip latency and configurable NoC; portability to GPU/CPU clusters requires runtime/compiler support for translating domains and message pipelining.
- Performance regimes: Must choose subdomain size n large enough to satisfy n2 > 2 p λ / c to hide latency; otherwise IO/latency dominates; adequate off-wafer bandwidth provisioning is required.
- Software maturity: Today’s implementation is in Tungsten; broader adoption benefits from SDKs, code generators, and integration into mainstream HPC toolchains.
- Validation and governance: Operational use (weather, hazards, finance) requires rigorous validation, uncertainty quantification, and compliance with regulatory frameworks.
- Data and IO: Ingest/egress pipelines (bathymetry, observations, outputs) must not become bottlenecks; consider in-situ analytics or periodic filtering to reduce redundant transfers (as noted in the paper’s IO observations).
Glossary
- Asymptotic utilization: The fraction of peak performance achieved as problem size grows large; often reported by performance models. Example: "Asymptotic utilization"
- Bandwidth Limit: The maximum rate at which data can be transmitted across a network or link, constraining performance when communication exceeds compute capacity. Example: "Bandwidth Limit"
- Chiplets: Small modular silicon dies integrated into a larger package; avoiding them enables full-wafer designs. Example: "no chiplets or interposer"
- Cluster Computing: Using multiple interconnected compute nodes to run a single workload in parallel. Example: "Cluster Computing"
- Communication avoiding techniques: Algorithms that reduce communication by performing additional local computation to minimize data exchange. Example: "communication avoiding techniques"
- Compute Limit: The performance bound determined purely by available computation throughput rather than communication. Example: "Compute Limit"
- Compute-bound regime: A scenario where the computation rate, not communication, limits performance. Example: "compute-bound regime fully independent of inter-node network latency."
- Coriolis force: An apparent force due to planetary rotation affecting moving fluids, important in geophysical flow models. Example: "Coriolis force"
- Daisy chain: A sequential forwarding pattern where data passes from one node or core to the next in series. Example: "creates a daisy chain between every pair of horizontally adjacent cores."
- Domain decomposition method: A technique that partitions a computational domain across multiple processors or nodes for parallel execution. Example: "use the domain decomposition method"
- Domain Translation: A latency-hiding algorithm that shifts grid-to-processor mapping each step to make inter-node dependencies unidirectional and amortize latency. Example: "We introduce Domain Translation, a parallel algorithm for computing a stencil code efficiently over high-latency network links."
- Dojo: Tesla’s specialized large-scale AI/training system and architecture referenced among spatial/dataflow platforms. Example: "the Dojo by Tesla"
- Eulerian time integration: A time-stepping approach that updates fields using their current values (e.g., forward Euler). Example: "implements Eulerian time integration"
- Exascale systems: Computing systems capable of at least 1018 floating-point operations per second. Example: "Exascale systems deliver only a small fraction their peak performance for these workloads."
- Finite difference: A numerical method that approximates derivatives using differences between adjacent grid points. Example: "finite difference"
- Finite element: A numerical technique that solves PDEs by discretizing the domain into elements and using basis functions. Example: "finite element"
- Finite volume: A method that conserves fluxes by integrating PDEs over control volumes. Example: "finite volume"
- GEBCO_2024 Grid: A high-resolution global bathymetry/topography dataset used for geophysical simulations. Example: "GEBCO_2024 Grid"
- Ghost points: Replicated boundary data from neighboring subdomains used to satisfy stencil dependencies without immediate communication. Example: "replicate a layer of ghost points"
- Green500: A ranking of supercomputers by energy efficiency (FLOPs per watt). Example: "Green500"
- Hyperbolic conservation laws: PDEs that model wave-like transport of conserved quantities (e.g., fluids) with characteristic propagation. Example: "define a system of non-linear hyperbolic conservation laws."
- IO-bound performance: A regime where input/output or communication throughput limits the overall application speed. Example: "IO-bound performance is assessed by measuring link payload per iteration."
- Inviscid fluid flow: Fluid dynamics modeling that neglects viscosity, suitable for large-scale wave propagation. Example: "model inviscid fluid flow"
- Krylov solvers: Iterative linear algebra methods (e.g., CG, GMRES) that operate in Krylov subspaces, often used for large sparse systems. Example: "Krylov solvers"
- Lax-Wendroff spatial discretization: A second-order accurate scheme for hyperbolic PDEs using Taylor expansion and flux terms. Example: "We use a Lax-Wendroff spatial discretization"
- Latency Limit: The performance bound imposed by the time it takes for data to traverse the network. Example: "Latency Limit"
- Latency-hiding algorithm: A technique that schedules computation and communication to mask network delays. Example: "the new latency-hiding algorithm"
- Manhattan stencil radius: The maximum taxicab (L1) distance from a point needed by a stencil operator. Example: "Stencil reach - Manhattan stencil radius"
- Mercator projection: A map projection that preserves angles, used here to flatten the Earth’s grid for computation. Example: "Our simulation uses the Mercator projection"
- Network on Chip (NOC) router: An on-chip routing component enabling packetized communication among processing elements. Example: "Network on Chip (NOC) router."
- Network pipeline: A conceptual sequence of in-flight messages/packages across links whose spacing and throughput affect overall rate. Example: "in the network pipeline."
- No-slip condition: A boundary condition in fluid dynamics where fluid velocity is zero at a solid boundary. Example: "to enforce a no-slip condition"
- Oceanic topography: The elevation of the ocean floor (bathymetry) influencing water depth and flow. Example: "oceanic topography"
- Operational intensity: The ratio of arithmetic work to data movement, central to the roofline performance model. Example: "tend to have low operational intensity"
- Overlapping Domain Decomposition: A method that uses ghost regions to compute multiple steps locally before communication. Example: "Overlapping Domain Decomposition"
- PFLOP/s: Petaflops per second, a unit of computing performance equal to 1015 floating-point operations per second. Example: "84 PFLOP/s"
- Processing Elements (PEs): Lightweight compute units with local memory, arranged in spatial fabrics. Example: "Processing Elements (PEs) arranged in a grid"
- Principle of locality: The physical notion that interactions depend on nearby space-time neighborhoods; mirrored in local computations. Example: "principle of locality"
- Runge-Kutta (RK2): A two-stage time integration method providing second-order accuracy for time-dependent problems. Example: "two-stage Runge-Kutta (RK2) time integration scheme."
- Shallow Water Equations (SWE): A system of PDEs modeling large-scale, depth-averaged fluid motion of oceans or atmospheres. Example: "Shallow Water Equations (SWE)"
- Spatial architectures: Compute systems that co-locate memory and processing across a fabric, emphasizing neighbor-to-neighbor dataflow. Example: "Spatial architectures offer a compelling alternative"
- Stencil computations: Grid-based updates where each point is computed from a fixed neighborhood pattern. Example: "stencil computations"
- Strong scaling: Performance scaling as the problem size is fixed and the number of processors increases. Example: "addressing strong scaling."
- Tensor Streaming Processor: Groq’s spatial/dataflow compute architecture optimized for streaming tensor operations. Example: "the Tensor Streaming Processor by Groq"
- Tungsten dataflow language: A language for expressing dataflow kernels and communication on spatial architectures. Example: "Tungsten dataflow language"
- Virtual channels: Logical subdivisions of physical network links enabling concurrent independent traffic classes. Example: "Each router has 24 virtual channels."
- Von Neumann computer: A conventional architecture with a central memory and processor, often contrasted with spatial designs. Example: "small Von Neumann computer"
- Wafer-scale engine (WSE): A processor built at full wafer scale, integrating a massive array of PEs and routers on a single wafer. Example: "A wafer-scale engine (WSE)"
- Wavelets: Fixed-size message units used by the on-wafer router for low-latency communication. Example: "Routers forward 32-bit messages called wavelets"
- Weak scaling: Performance scaling as the problem size per processor is kept constant while the number of processors increases. Example: "We observed weak scaling efficiencies"
Collections
Sign up for free to add this paper to one or more collections.