Optimizing Mixture of Block Attention
Abstract: Mixture of Block Attention (MoBA) (Lu et al., 2025) is a promising building block for efficiently processing long contexts in LLMs by enabling queries to sparsely attend to a small subset of key-value blocks, drastically reducing computational cost. However, the design principles governing MoBA's performance are poorly understood, and it lacks an efficient GPU implementation, hindering its practical adoption. In this paper, we first develop a statistical model to analyze MoBA's underlying mechanics. Our model reveals that performance critically depends on the router's ability to accurately distinguish relevant from irrelevant blocks based on query-key affinities. We derive a signal-to-noise ratio that formally connects architectural parameters to this retrieval accuracy. Guided by our analysis, we identify two key pathways for improvement: using smaller block sizes and applying a short convolution on keys to cluster relevant signals, which enhances routing accuracy. While theoretically better, small block sizes are inefficient on GPUs. To bridge this gap, we introduce FlashMoBA, a hardware-aware CUDA kernel that enables efficient MoBA execution even with the small block sizes our theory recommends. We validate our insights by training LLMs from scratch, showing that our improved MoBA models match the performance of dense attention baselines. FlashMoBA achieves up to 14.7x speedup over FlashAttention-2 for small blocks, making our theoretically-grounded improvements practical. Code is available at: https://github.com/mit-han-lab/flash-moba.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper is about helping LLMs handle very long inputs much faster and more accurately. The authors study a technique called Mixture of Block Attention (MoBA), which lets the model focus only on the most useful parts of a long text instead of scanning everything. They also build a new, fast GPU program called FlashMoBA so this method runs quickly in practice.
Objectives
The paper asks two main questions:
- How can MoBA reliably find the “right” parts of a long text to pay attention to, without getting confused by all the other parts?
- How can we make MoBA run fast on real hardware (GPUs), especially when using small “blocks” that theory says are best?
Methods and Approach
Think of reading a huge library of books. Standard “attention” makes the model check every page in every book to answer a question—this is slow because time grows roughly with the square of the number of pages. MoBA does something smarter:
- It splits the text into “blocks” (like shelves of books).
- Each question (“query”) first compares itself to a short summary of each block (called a “centroid,” which is just the average of the block’s words). Then it picks the top few blocks that seem most relevant.
- The model then does detailed reading only inside those chosen blocks.
The challenge is making the “router” (the part that picks blocks) pick the right shelves reliably, like a good librarian who knows where to look.
What the authors did:
- A simple statistical model: They modeled how well the router can tell “signal” (relevant blocks) from “noise” (irrelevant blocks). They derived a key formula for the signal-to-noise ratio, or SNR:
- Here, is the “head dimension” (a measure of how rich the attention’s features are), and is the block size (how many tokens per block).
- Bigger or smaller gives a higher SNR, which means the router is more likely to pick the correct blocks.
- Clustering signals: They also show that “key convolution” (a short filter over the text keys, like a quick sweep that groups related tokens) helps pack related tokens into the same block. That makes the block’s centroid more informative and boosts SNR.
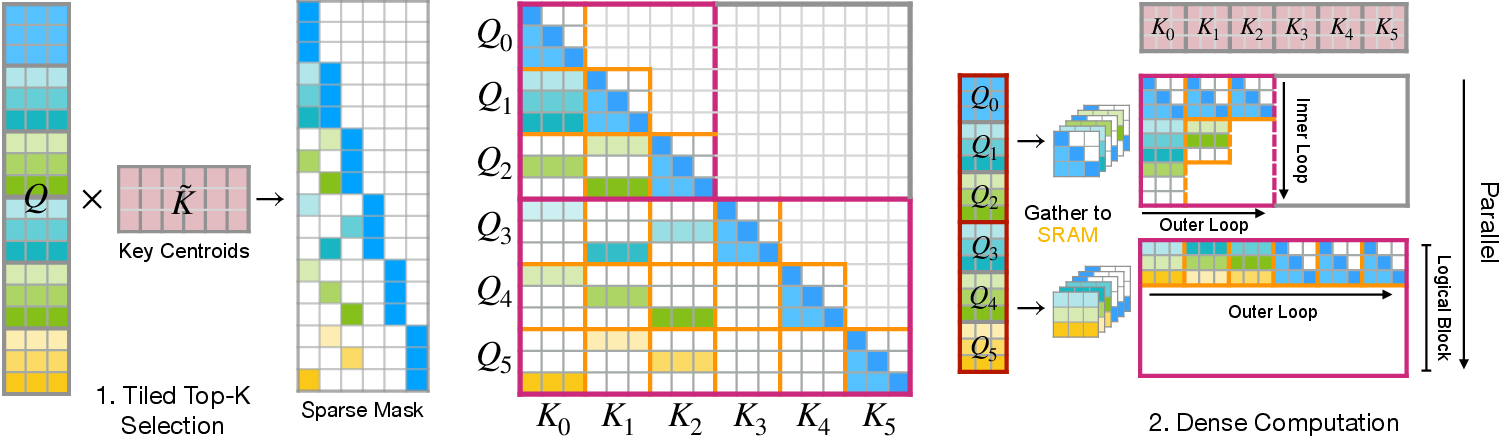
- Fast GPU kernel (FlashMoBA): Small blocks are theoretically better but usually slow on GPUs because they cause messy memory access and overhead. The authors designed FlashMoBA with two main stages tailored to GPUs:
- Tiled Top-k Selection: Efficiently finds the best blocks for each query without building huge score matrices.
- Gather-and-Densify: Collects the chosen queries and blocks into neat chunks in fast on-chip memory and runs dense attention there, then scatters results back. This keeps the GPU busy and avoids slow, random memory reads.
- Experiments: They trained models from scratch and tested them on language tasks, long-context retrieval benchmarks, and real-world long-document tasks. They kept fixed to isolate the effect of changing and added key convolution to test clustering.
Main Findings and Why They Matter
- SNR rule: The router’s accuracy scales with . This gives a clear design rule: smaller blocks help the router pick relevant content more accurately, and short key convolutions further improve clustering.
- Quality gains with small blocks: Reducing block size from 512 to 128 consistently improved performance. With small blocks plus key convolution, MoBA matched or beat standard dense attention on many tasks.
- Long-context retrieval: On tests up to 64K tokens, MoBA with small blocks and key convolution stayed accurate, while dense attention often failed as sequences grew.
- Real-world tasks: MoBA performed strongly on multi-document QA, summarization, and code tasks, showing it helps focus on the right information instead of spreading attention too thin.
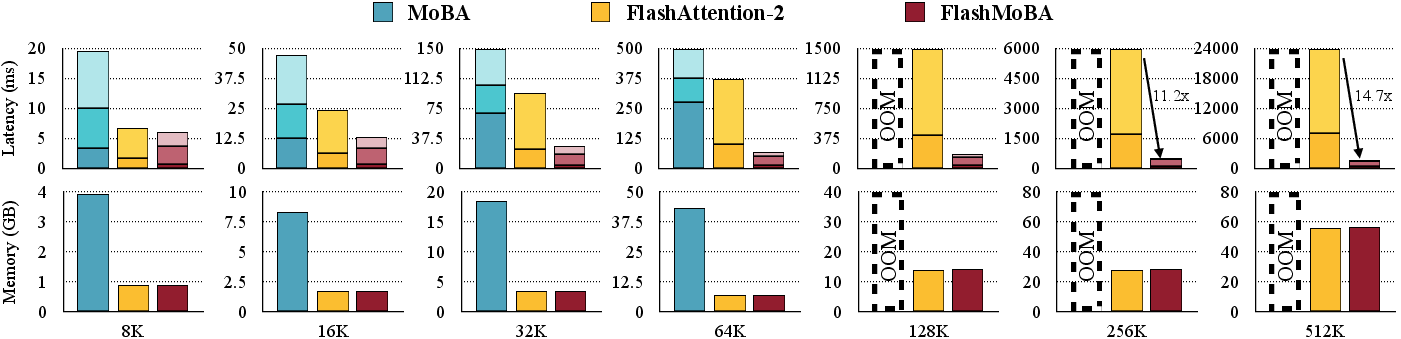
- Big speedups on GPU: FlashMoBA made small-block MoBA practical. At long sequence lengths, it achieved up to 14.7× speedup compared to a widely used fast attention implementation (FlashAttention-2), while also reducing memory use and avoiding out-of-memory crashes.
- Overall, MoBA with FlashMoBA gives near-linear cost in sequence length (instead of quadratic), which is crucial for very long inputs.
Implications and Impact
This work shows a clear path to making LLMs handle extremely long contexts—like long videos, books, or many documents—both accurately and efficiently. The SNR formula gives a simple, practical design rule: use smaller blocks and group related tokens. FlashMoBA turns that theory into practice by making those settings fast on GPUs. This could lower costs, speed up training and inference, and enable new applications that need models to remember and reason over hundreds of thousands to millions of tokens without slowing to a crawl.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
The following list summarizes what remains missing, uncertain, or unexplored in the paper, framed as concrete directions future researchers can pursue.
- The statistical SNR model relies on simplifying assumptions (normalized vectors, independence, Gaussian approximations) and analyzes one signal block versus a single noise block; it does not account for extreme-value effects when competing against noise blocks in top- selection. Derive and validate failure probability bounds that depend on and , using extreme-value theory and empirical calibration on real representations.
- The paper fixes head dimension to avoid confounds but therefore does not test the SNR prediction across varying . Run iso-parameter and iso-FLOPs ablations varying and to validate independently of capacity gains.
- Sparsity is kept constant at 7/8 by co-varying with , but the trade-off between , , and quality/efficiency is not mapped. Characterize optimal as a function of sequence length , task type, and block size, including dynamic or content-adaptive policies.
- Only contiguous fixed-size blocks are used. Investigate learned or content-adaptive block boundaries, overlapping or variable-size blocks, and hierarchical or coarse-to-fine block layouts, and quantify their effect on routing accuracy and GPU efficiency.
- Routing scores are based on mean-pooled centroids without exploring alternatives. Evaluate alternative pooling (max, robust statistics, attention-weighted centroids), multi-centroid per block, or a learned router network (e.g., MLP on block summaries), including two-stage re-ranking within top candidates.
- Top- gating is discrete and non-differentiable; training dynamics and potential gradient starvation for unselected blocks are not analyzed. Compare hard vs. soft/differentiable gating (e.g., Gumbel-top-, softmax with temperature), and measure selection entropy, coverage, and stability.
- The key convolution intervention is limited to shallow depthwise causal kernels (sizes 3 and 5). Systematically explore kernel size, dilation, stride, number of layers, whether to convolve queries/values, and learned vs. fixed filters; quantify when convolution helps or harms across tasks.
- The architecture interleaves sliding window attention (odd layers) with MoBA (even layers), and MoBA uses no positional encoding. Assess pure-MoBA stacks, add relative or block-level positional encodings to MoBA, and analyze interactions with RoPE for long-range order sensitivity.
- The smallest tested block size is , despite theory favoring smaller blocks. Benchmark for quality, router recall, and FlashMoBA efficiency, and identify the practical lower bound on per hardware and head dimension.
- The empirical evaluation is limited to 340M and 1B models trained on 100B tokens with 8K context; zero-shot evaluations extend to 64K but training does not. Train at longer contexts (e.g., 32K–128K), scale models to 3B–7B+, and test million-token contexts with realistic tasks to substantiate claims of scalability.
- The comparison set omits strong sparse baselines (e.g., BigBird, Longformer, Routing Transformer, XAttention, Native Sparse Attention). Provide head-to-head comparisons under matched FLOPs, memory, and accuracy on the same benchmarks.
- The SNR model posits within-block clustering boosts via and , but these quantities are not measured. Empirically estimate per-layer , , and retrieve-recall vs. curves; test whether convolution actually increases cluster size and affinity in learned representations.
- Softmax dilution is proposed as an explanation for dense attention’s degradation, but there is no quantitative analysis. Measure attention weight concentration, entropy, and effective number of attended tokens vs. sequence length for dense vs. MoBA to validate the dilution hypothesis.
- FlashMoBA benchmarks use batch size 2 and H100 GPUs; portability and scaling are not assessed. Evaluate performance across batch sizes, sequence lengths, head dimensions, and GPU architectures (A100, consumer GPUs, AMD MI300), including multi-GPU distributed training and inference.
- The backward pass relies on atomic additions for accumulating , which may introduce nondeterminism or contention. Quantify numerical stability, determinism, and scaling overhead of atomics; explore warp-level reductions or alternative accumulation strategies.
- Memory behavior of gather-and-densify with varlen indices is not characterized (fragmentation, cache behavior, NUMA). Profile memory bandwidth, SRAM reuse, and fragmentation effects across workloads; provide guidelines for tile sizes and layouts per architecture.
- Integration with real-world inference workflows (KV cache, streaming generation, prefix reuse) is not addressed. Design incremental routing and cache management for MoBA, and benchmark end-to-end generation throughput and latency under streaming.
- Failure modes in adversarial or near-duplicate contexts are not studied (e.g., semantically similar distractor blocks). Stress-test routing under high-confusion settings, measure false-positive rates, and develop regularizers or tie-breakers to mitigate misrouting.
- The paper motivates multimodal long-context needs (e.g., video) but evaluates only text. Extend MoBA and FlashMoBA to multimodal settings (vision, audio), including cross-attention patterns, and report long-context video understanding/generation results.
- Energy efficiency and wall-clock training throughput are not reported. Provide end-to-end training speed, energy per token, and cost savings vs. dense and other sparse baselines at scale.
- Some task results show regressions (e.g., OBQA and TruthfulQA variability with key convolution) without analysis. Identify task characteristics where convolution or small blocks hurt, and propose adaptive per-layer or per-task configuration policies.
- Robustness across layers and training stages is not analyzed. Track router accuracy, selection diversity, and SNR proxies across depth and training checkpoints; determine where MoBA contributes most and where it may be redundant.
- The role of normalization in practice (L2-normalized keys/queries assumed by theory) is unclear. Evaluate the effect of explicit normalization on routing accuracy and final quality; reconcile theoretical assumptions with actual representation scaling.
Glossary
- AdamW optimizer: An optimizer that decouples weight decay from the gradient update to improve generalization. "using AdamW optimizer with β1=0.9, β2=0.95, weight decay 0.1, and cosine learning rate schedule."
- ARC-e/c: The AI2 Reasoning Challenge Easy/Challenge benchmarks used for zero-shot evaluation. "ARC-e/c~\citep{clark2018thinksolvedquestionanswering}"
- attention dilution: The phenomenon where attention probability mass becomes spread thinly over many tokens as sequence length grows. "These results demonstrate the benefit of reducing attention dilution: dense softmax spreads probability mass thinly across all tokens as sequence length grows"
- atomic additions: A GPU synchronization primitive that safely accumulates values in shared memory without race conditions. "using atomic additions to a high-precision global buffer."
- bfloat16: A 16-bit floating-point format with 8-bit exponent, commonly used for mixed-precision training. "mixed precision training with bfloat16."
- block-sparsity: A sparsity pattern where computation is restricted to selected blocks rather than individual elements. "adding novel optimizations for block-sparsity, FlashMoBA achieves significant speedups."
- causal masking: Masking future tokens so a model only attends to past or current tokens, preserving autoregressive causality. "each query always attends to its current block with causal masking."
- centroid: The mean vector of all keys in a block used for routing decisions. "represents the centroid ---i.e., mean pooling of the block ."
- cosine learning rate schedule: A learning rate schedule that decays following a cosine curve. "using AdamW optimizer with β1=0.9, β2=0.95, weight decay 0.1, and cosine learning rate schedule."
- CUDA kernel: A GPU-executed function implemented in CUDA for parallel computation. "FlashMoBA, a hardware-aware CUDA kernel that makes these theoretically optimal configurations practical."
- depthwise causal convolution: A per-channel convolution applied in a causal manner (only past context), used here on keys to cluster signals. "short depthwise causal convolution on keys~\citep{yang2025parallelizinglineartransformersdelta} (kernel size 3 or 5)"
- dense attention: Standard self-attention that computes interactions between each query and all keys. "showing that our improved MoBA models match the performance of dense attention baselines."
- epilogue: The final stage in a kernel pipeline that formats or writes results. "an efficient epilogue reformats the query-centric indices into a key-block-centric varlen layout"
- FlashAttention-2: An IO-aware attention implementation optimized for performance and memory efficiency. "FlashMoBA achieves up to 14.7× speedup over FlashAttention-2 for small blocks, making our theoretically-grounded improvements practical."
- FlashMoBA: A hardware-aware optimized CUDA kernel for efficient MoBA execution at small block sizes. "We introduce FlashMoBA, an hardware-aware CUDA kernel designed to make small-block MoBA practical and fast."
- Flash TopK: A fused, tiled kernel pipeline to compute top-k block selections without materializing full score matrices. "We replace this with Flash TopK (Step 1 in Figure~\ref{fig:flashmoba}), a highly optimized three-stage pipeline of fused kernels."
- fully-sharded data parallelism: A distributed training technique that shards model states across devices to reduce memory usage. "with gradient checkpointing and fully-sharded data parallelism for memory efficiency."
- gather-and-densify: A strategy that gathers sparse data into on-chip buffers and computes with dense tiles to maximize hardware efficiency. "This gather-and-densify strategy coalesces memory, maximizes hardware utilization and makes small-block MoBA fast on GPUs"
- GEMM: General Matrix-Matrix Multiplication, the core dense operation in many GPU kernels. "amortizing costly irregular memory access with efficient dense GEMMs."
- gating mechanism: The routing component that scores blocks and selects the most relevant ones. "The block selection uses a gating mechanism."
- gradient checkpointing: A memory-saving technique that recomputes activations during backward pass to reduce peak memory. "with gradient checkpointing and fully-sharded data parallelism for memory efficiency."
- gradient clipping: A stabilization technique that limits the norm of gradients during training. "All models use gradient clipping at 1.0"
- GPU occupancy: The degree to which GPU compute resources are utilized by active threads. "low GPU occupancy results from the reduced work per block and the overhead of launching many independent kernels, leading to poor parallelism and low hardware utilization."
- HBM: High Bandwidth Memory used on modern GPUs for fast data transfer. "leading to uncoalesced memory reads from HBM."
- head dimension: The dimensionality of each attention head’s query/key/value vectors. "where is the head dimension and is the block size."
- IO-aware algorithms: Algorithms optimized to reduce memory traffic and improve throughput by aligning computation with IO patterns. "FlashAttention~\citep{dao2022flashattention,dao2023flashattention2} improves implementation via IO-aware algorithms but doesn't reduce complexity."
- logsumexp: A numerically stable operation to compute log of a sum of exponentials, often used in softmax. "logsumexp vector in HBM."
- LongBench: A benchmark suite evaluating long-context understanding across tasks. "Performance on real-world LongBench tasks for 340M models trained on 100B tokens."
- Mixture of Block Attention (MoBA): A sparse attention mechanism that routes queries to a subset of key-value blocks via a learned router. "Mixture of Block Attention (MoBA)~\citep{lu2025mobamixtureblockattention} is a promising building block for efficiently processing long contexts in LLMs"
- on-chip SRAM: Fast, limited-capacity memory located on the GPU used for high-throughput tiling. "queries are gathered into on-chip SRAM, computed densely with FlashAttention-2 logic, then scattered back."
- perplexity: A language modeling metric measuring predictive uncertainty; lower is better. "Smaller block sizes improve WikiText perplexity and RULER accuracy"
- RoPE: Rotary Positional Embeddings, a technique for encoding positions in attention. "odd layers use sliding window attention (window size 256) with RoPE"
- router: The learned component that decides which blocks a query should attend to. "a learned router directs each query to a small subset of key-value blocks, reducing complexity to near-linear."
- RULER: A benchmark evaluating retrieval and long-context capabilities. "Zero-shot performance on RULER S-NIAH tasks for 340M models trained on 100B tokens."
- S-NIAH: A long-context “needle-in-a-haystack” retrieval task variant in RULER. "Zero-shot performance on RULER S-NIAH tasks for 340M models trained on 100B tokens."
- signal-to-noise ratio (SNR): A measure comparing the strength of the signal to the variability/noise in routing scores. "We derive a signal-to-noise ratio that formally connects architectural parameters to this retrieval accuracy."
- sliding window attention: Attention restricted to a local window around each token to capture short-range dependencies. "odd layers use sliding window attention (window size 256) with RoPE"
- softmax: The normalized exponential function used to convert scores into attention weights. "MoBA() = \text{softmax}(\mathbf{q}\mathbf{K}\mathcal{S}\top/\sqrt{d})\mathbf{V}\mathcal{S},"
- Sparse attention: Attention mechanisms that focus computation on a subset of tokens or regions to reduce complexity. "Sparse attention~\citep{zaheer2020bigbird,guo2024blocksparse,xu2025xattention} aims to solve this by focusing computation only on important regions."
- tiled Top-k selection: A method that computes top-k over tiles to avoid materializing large score matrices. "Tiled Top- Selection: a fused kernel streams tiles of and to emit a sparse routing mask without materializing the full matrix."
- Top-k: Selecting the k highest-scoring items from a set. "The top- blocks with highest scores are selected"
- Triton kernel: GPU kernels written in the Triton language for high-performance custom operations. "First, a Triton kernel computes key-block centroids"
- varlen indices: Variable-length index lists used to represent sparse mappings efficiently. "Varlen indices ."
- weight decay: A regularization technique that penalizes large weights to prevent overfitting. "using AdamW optimizer with β1=0.9, β2=0.95, weight decay 0.1, and cosine learning rate schedule."
- zero-shot: Evaluation on tasks without task-specific fine-tuning or training examples. "Zero-shot performance on RULER S-NIAH tasks for 340M models trained on 100B tokens."
Practical Applications
Immediate Applications
Below are concrete use cases that can be deployed today using the paper’s findings (SNR-guided design) and engineering contributions (FlashMoBA CUDA kernels and training recipes). Each item includes target sectors, likely products/workflows, and key assumptions.
- Faster, cheaper long-context inference for LLM serving
- Sectors: software infrastructure, cloud AI, enterprise AI platforms
- What to build: swap dense attention/FlashAttention-2 with FlashMoBA in inference stacks to support 64K–512K token contexts with lower latency and memory; integrate into PyTorch backends, Triton Inference Server, TensorRT-LLM, vLLM-like engines
- Why now: FlashMoBA reports up to 14.7× speedup over FlashAttention-2 at long sequences and scales to 512K tokens, with quality matching dense attention
- Assumptions/Dependencies:
- CUDA GPUs (A100/H100-class) and PyTorch; willingness to adopt custom kernels
- Model head dimension and block-size tuned (e.g., MoBA-128, k=8) per the principle; kernel maintenance across drivers
- Long-document QA and summarization products
- Sectors: knowledge management, customer support, media/meetings
- What to build: assistants that pack entire contracts, regulatory filings, or multi-hour meeting transcripts into a single context for QA/summarization without heavy retrieval; align with LongBench-style tasks
- Why now: MoBA-128 (+ key convolution) matches/exceeds dense attention on LongBench and achieves robust long-context retrieval up to 64K
- Assumptions/Dependencies:
- Models fine-tuned or trained with MoBA layers; chunk orchestration that preserves causality and block layout
- Data privacy controls for larger contexts
- Enterprise knowledge assistants for compliance, audit, and e-discovery
- Sectors: legal, compliance, finance, governance/risk
- What to build: tools that read multi-year audit trails, case dockets, or multi-fund prospectuses in one pass; timeline queries and synthesis without attention dilution
- Why now: Sparse routing reduces “attention dilution” at long lengths, improving retrieval of relevant content
- Assumptions/Dependencies:
- On-prem GPU availability; integration with document ingestion pipelines and access controls
- Validation on domain-specific corpora
- Code understanding over large repositories
- Sectors: software engineering, DevOps
- What to build: code copilots that ingest thousands of files at once for refactoring, impact analysis, and repo-wide QA; enable monorepo-aware PR review
- Why now: Reported gains on code benchmarks (LCode/RepoBench) with small-block MoBA; memory/latency benefits allow much larger prefill windows
- Assumptions/Dependencies:
- Good tokenization and structural packing to cluster related files/functions within blocks
- Incremental updates for active repos (e.g., streaming prefill)
- Training/finetuning cost and stability improvements for long-context LLMs
- Sectors: foundation model labs, academic ML groups
- What to build: pretraining/finetuning pipelines that use hybrid SWA + MoBA layers; apply key convolution (kernel size 3–5) to increase within-block clustering; choose via tuning
- Why now: The paper shows MoBA matches dense quality while using ≈12.5% of dense compute for the long-context portion; provides controlled recipes and hyperparameters
- Assumptions/Dependencies:
- Training stacks with FlashAttention-2 + FlashMoBA; gradient checkpointing; multi-GPU setup
- Data layouts that preserve local semantic clustering to benefit routing
- Cost and energy savings for long-context workloads
- Sectors: cloud providers, AI operations, sustainability programs
- What to build: GPU scheduling tiers for long-context jobs using FlashMoBA; costed SLAs for 64K–512K contexts; sustainability reporting (kWh/token) improvements
- Why now: Reduced HBM traffic and near-linear complexity in vs lowers runtime and peak memory
- Assumptions/Dependencies:
- Accurate measurement pipelines; kernel stability across GPU generations
- Workload profiles with significant long-context usage
- Research and teaching: principled architecture selection for long-context transformers
- Sectors: academia, ML R&D
- What to build: coursework and tutorials on SNR-driven routing (), ablation kits for block-size vs. head-dimension, and benchmark suites (RULER/LongBench) to evaluate routing accuracy
- Why now: The paper provides a compact statistical model linking design choices to retrieval accuracy and open-source kernels for experimentation
- Assumptions/Dependencies:
- Access to GPUs for controlled studies; reproducible training scripts
Long-Term Applications
These applications are enabled by the paper’s principles and kernels but require further scaling, integration with other modalities/systems, or hardware/standards evolution.
- Million-token context assistants and lifelong memory for AI agents
- Sectors: CRM, enterprise knowledge management, engineering, research labs
- What to build: agents that keep entire customer histories, design docs, or research logs in-context for reasoning over months/years
- Why later: Needs robust training and inference beyond 512K tokens, adaptive routing at extreme scale, and memory orchestration across sessions
- Assumptions/Dependencies:
- Stable MoBA behavior at 1M+ tokens; distributed inference kernels; checkpointing and error handling at massive sequence lengths
- Multimodal long-context models for video, audio, and robotics
- Sectors: autonomy, surveillance, media analytics, healthcare monitoring
- What to build: sparse-routed attention over long video/audio streams to track events and plans; robot memory over long trajectories; clinical waveform timelines
- Why later: Requires modality-specific embeddings, causal convolutions for signals, and MoBA kernels generalized to non-text tensor layouts
- Assumptions/Dependencies:
- Efficient batching for frames/clips; synchronization with vision/audio backbones; evaluation suites for long-horizon tasks
- Hardware–software co-design for sparse, block-routed attention
- Sectors: semiconductor, systems software, compilers
- What to build: GPU/ASIC features (e.g., gather-and-densify primitives, block-sparse tensor cores, compiler-level fusion) to further accelerate MoBA-style routing
- Why later: Needs vendor roadmaps and standardization; evidence from production deployments to justify silicon
- Assumptions/Dependencies:
- Stable sparsity patterns; shared IR in compilers (e.g., Triton/TVM) for block-sparse fusion
- Privacy-preserving, on-device long-context assistants
- Sectors: mobile, edge, healthcare, legal
- What to build: on-device summarization and analytics over large personal corpora (notes, emails, health records) with sparse routing to fit memory/energy budgets
- Why later: Requires further efficiency gains, mixed-precision safety, and possibly NPU support for MoBA kernels
- Assumptions/Dependencies:
- Porting to ROCm/Metal/NPUs; secure enclaves and consent management for long in-context personal data
- Hybrid RAG + MoBA memory systems
- Sectors: enterprise search, analytics, developer tools
- What to build: controllers that first retrieve candidate blocks from external indexes, then route within-context via MoBA; dynamic and adaptive block construction
- Why later: Needs orchestration across vector DBs and attention routers, plus training that aligns retrieval granularity and block layout
- Assumptions/Dependencies:
- Data pipelines that respect semantic contiguity; feedback loops to jointly learn retrieval and routing
- Standards, benchmarks, and policy for “green long-context AI”
- Sectors: government, standards bodies, sustainability programs
- What to build: procurement and evaluation guidelines emphasizing energy/latency per token for long-context tasks; standardized long-context benchmarks beyond 64K
- Why later: Requires consensus on metrics, third-party audits, and widespread tooling support
- Assumptions/Dependencies:
- Neutral test beds; lifecycle analyses of datacenter energy and carbon
- Domain-specialized long-horizon analytics
- Healthcare: longitudinal EHR summarization, pharmacovigilance timelines, clinical trial eligibility across years
- Finance: multi-quarter SEC filings analysis, risk aggregation across portfolios, compliance narratives
- Legal/government: end-to-end discovery over case histories; legislative-history synthesis and impact analysis
- Education: course-long tutoring that tracks knowledge over a semester and references all prior work
- Why later: Requires domain-adapted training, validation, and governance; integration with secure data systems and auditing
- Assumptions/Dependencies:
- Rigorous evaluation for factuality/safety; HIPAA/PII handling (healthcare), SOX/SEC compliance (finance), chain-of-custody (legal)
- Advanced routing research and automated architecture tuning
- Sectors: ML research, AutoML
- What to build: learned policies to set per layer/task; hierarchical or multi-stage routing; coupling MoBA with Mixture-of-Experts for joint token/block and expert selection
- Why later: Needs large-scale ablations and stability work, especially under distribution shift
- Assumptions/Dependencies:
- Robust optimization techniques; diagnostics for routing failure and SNR monitoring in training
Cross-cutting assumptions and risks
- Quality and efficiency gains hinge on maintaining a favorable ratio and benefiting from within-block clustering (often encouraged by short key convolutions).
- FlashMoBA currently targets NVIDIA CUDA; portability to other accelerators (ROCm, NPUs) will affect broader adoption.
- Extremely long contexts may require new memory-management, checkpointing, and failure-recovery strategies.
- Some domains may still benefit from hybrid retrieval (RAG) rather than pure in-context packing; data-layout and chunking strategies are critical to realize routing gains.
- Kernel and driver updates can affect determinism and performance; continuous benchmarking and regression testing are needed.
Collections
Sign up for free to add this paper to one or more collections.