- The paper introduces semantic triangulation, a novel method that transforms coding tasks to verify solution consistency and reduce hallucinations in LLM-generated code.
- It achieves a 21% improvement in identifying correct solutions, even with low sampling probabilities, validated on benchmarks like LiveCodeBench and CodeElo.
- The framework addresses limitations of consensus methods in multi-solution tasks and paves the way for robust automation in code generation.
Reducing Hallucinations in LLM-Generated Code via Semantic Triangulation
Introduction
LLMs are increasingly employed for generating software code from natural language descriptions. Despite their versatility, these models can produce programs with substantial errors, known as hallucinations. Efforts to mitigate these hallucinations typically involve sample consensus methods like majority voting or validation against generated tests. However, these approaches often fail to identify correct solutions when their sampling probability is low or when problems allow multiple valid but non-equivalent solutions. Additionally, these methods can fail to abstain when no correct solution is present in the sample.
To enhance the reliability of LLM-generated code, the paper introduces a novel framework called semantic triangulation. This method involves transforming programming problems into non-trivial variants that alter their semantics while preserving verifiable mappings between solutions before and after transformation. The paper demonstrates that verifying consistency across problem transformations can increase confidence in the generated programs, ensuring that they reflect accurate generalization rather than superficial statistical correlations.
Semantic Triangulation Framework
Semantic triangulation operates by utilizing controlled transformations of coding tasks, verifying solutions to both the original and transformed tasks. Responses consistent across transformations indicate deeper semantic structure, while inconsistencies highlight hallucinations due to the LLM's reliance on shallow statistical correlations. This is analogous to the parable of the blind men and an elephant, where consistent understanding across perspectives ensures reliability.
The theoretical foundation for semantic triangulation is established under the assumption that LLMs function as "stochastic parrots," often producing solutions with a reliance on surface-level statistical features rather than deep semantic understanding. Given empirical evidence of error correlation, the framework is designed to decorrelate errors with non-trivially transformed problems, bolstering the confidence in correctness when triangulation witnesses agree with a given program.
Evaluation and Results
Semantic triangulation is empirically validated on benchmarks such as LiveCodeBench and CodeElo using models like GPT-4o and DeepSeek-V3. The results showcase that triangulation improves the reliability of generated code by 21%, allowing correct solutions to be pinpointed even at low sampling probabilities. Furthermore, semantic triangulation effectively resolves tasks with multiple valid but non-equivalent solutions, addressing limitations of previous consensus methods that fail under such problem conditions.
Here are some figures demonstrating the results:
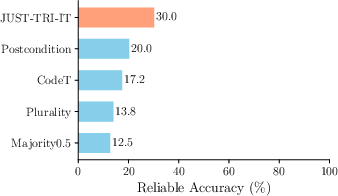
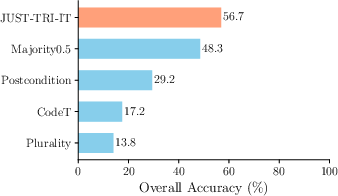
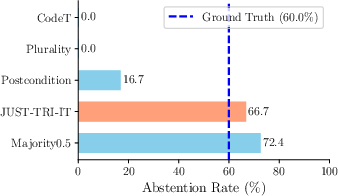
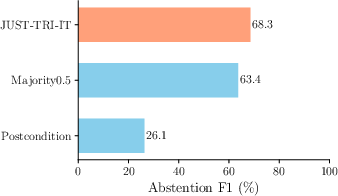
Figure 1: Performance comparison of methods showing semantic triangulation enhancing reliability by 21%.
Figure 2: Probability distribution highlighting correct solutions identified by semantic triangulation at low sampling probabilities.
Implications and Future Directions
Semantic triangulation marks a significant advancement in addressing hallucinations in LLM-generated code. By employing robust transformations and verifying cross-task consistency, it enhances the confidence in the reliability of LLM outputs. This approach has practical implications for automating code generation tasks in complex problem settings, especially those with multiple valid outputs or low-confidence solutions.
Future studies could explore extensions of semantic triangulation in interactive environments where code interacts with users or external systems. Additionally, integrating semantic triangulation with multi-agent systems or reinforcement learning frameworks might offer deeper validation and refinement strategies, expanding its applicability and robustness.
In conclusion, semantic triangulation promises improved accuracy and reliability for LLM-based code generation, facilitating more confident deployment of automated programming solutions across various domains.