- The paper introduces FFSE, an autoregressive diffusion-based framework that performs 3D-aware multi-round object manipulation without explicit 3D reconstruction.
- The method uses a hybrid real-synthetic dataset and domain-specific LoRA modules to achieve physically-plausible results and consistent scene editing across rounds.
- Empirical evaluations and ablation studies confirm FFSE’s superiority in maintaining scene integrity and realistic environmental effects compared to existing techniques.
Existing text-to-image (T2I) diffusion models have advanced semantic image editing, but they traditionally lack physically-plausible, 3D-aware object manipulation capabilities. Most approaches either operate strictly in 2D image space—failing to generalize beyond simple object transformations—or require computationally intensive and error-prone 3D reconstruction pipelines, which struggle with realistic environmental interactions (shadows, reflections, occlusions) and scene consistency during multi-stage editing. Free-Form Scene Editor (FFSE) is proposed as a framework for enabling user-controllable, 3D-aware, multi-round object manipulation directly in real-world image contexts without explicit 3D reconstruction, simulating iterative manipulations akin to professional 3D engines.

Figure 1: FFSE demonstrates robust manipulation results, including diverse object effects, physically-constrained background responses, and consistency across multiple editing cycles.
Foundations: Dataset Design for 3D-Aware Editing
A critical bottleneck for learning iterative 3D manipulations is the absence of an adequate multi-round editing dataset. FFSE introduces "3DObjectEditor": a hybrid dataset incorporating both realistic and synthetic data. The dataset construction is partitioned into:
This dataset enables training deep models to execute complex, physically-consistent multi-round 3D editing, addressing limitations of prior datasets in domain diversity and operational scope.

Figure 3: Dsyn statistics reveal extensive category coverage for both objects and backgrounds.
Model Architecture: Autoregressive Diffusion-Based Scene Editing
FFSE models the state transitions of a scene as a sequence of learned 3D transformations, conditioned on the editing history. Core architectural components include:
- Frame Encoder: Encodes previous observations and the binary mask of the target location to maintain scene context.
- Operation Encoder: Maps user-specified 3D op types (translation, scaling, x/y/z rotations) and object regions (bounding box, centroid) into high-dimensional Fourier-MLP feature vectors. Inputs are concatenated per editing step, with learnable null embedding for missing conditions.
- Operation Self-Attention: Injects operation-conditioned signals between contextual and cross attention layers, modulating editing behavior.
- Context Self-Attention (CSA): Augments ordinary self-attention, using object-centric token correspondence from current and previous rounds (with bounding-box-guided masking) to enforce robust appearance consistency.
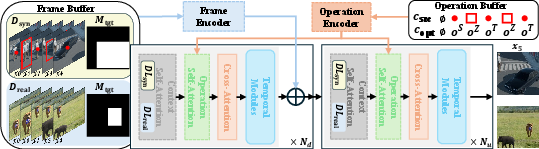
Figure 4: FFSE framework, showing operation and frame encoders, learnable domain adapters (LoRA modules), and editing history integration.
This framework is initialized from a pretrained video diffusion backbone (SVD), leveraging its temporal coherence modeling for framewise scene consistency.
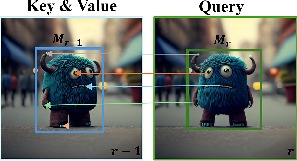
Figure 5: The CSA module explicitly aligns object embeddings between editing steps for appearance coherence.
Multi-Stage Training Strategy and Domain Adaptation
FFSE pioneers a multi-stage training regime for robustly learning across realistic and synthetic domains:
- Domain LoRA Modules (DLreal, DLsyn): Low-rank adapters injected selectively into CSA layers for each domain, minimizing overfitting to domain-specific styles and enhancing cross-domain generalization.
- Stage 1: Joint training of newly introduced components and LoRA modules across both Dreal and Dsyn to learn general object effects and manipulation consistency.
- Stage 2: Fine-tuning exclusively on Dsyn (with high-fidelity physics) further enhances the model's ability to generate realistic background effects (accurate shadows, reflections).
Empirical Evaluation: Comparative and Ablative Analysis
FFSE is benchmarked against state-of-the-art image-space (3DIT, Zero-1-to-3) and 3D-space (Diffusion Handles, 3DitScene) methods under both single-round and multi-round editing tasks.
Single-Round Object and Background Effects
FFSE surpasses competitors in the fidelity of object transformations—handling large-angle rotations and partial occlusions—and consistently generates physically plausible environmental interactions (dynamic shadows, specular reflections, occlusion restoration). Unlike image-space methods, FFSE does not suffer from artifact accumulation and suboptimal blending during overlays or inpainting. Unlike 3D-space methods, FFSE is reconstruction-free, avoiding geometry estimation errors and computational bottlenecks.

Figure 6: Comparative evaluation of object effects reveals FFSE's robust support for all 3D operation types.

Figure 7: FFSE achieves realistic environmental response to manipulations, correctly handling shadows and occlusions.
Multi-Round Consistency
FFSE's autoregressive sequential modeling and explicit context alignment maintain consistent object identities and scene structure through iterative manipulations. Competing algorithms accumulate errors or lose occluded objects as editing progresses.

Figure 8: FFSE preserves scene integrity and occlusion relationships across several consecutive editing rounds.
FFSE demonstrates clear superiority over previous methods on PSNR, SSIM, CLIP and DINO object-identity metrics—across both single-round and multi-round editing. Human preference studies confirm its quality and operation fidelity.
Ablation Studies
Ablative analyses confirm the necessity of multi-stage training, domain-specific LoRA modules, and CSA. Omitting any component degrades either realism, consistency, or operational effectiveness.

Figure 9: Ablation studies: eliminating multi-stage training, domain adaptation, or CSA reduces editing and appearance consistency.
Theoretical and Practical Implications
FFSE demonstrates that 3D-aware editing can be significantly improved by autoregressive sequence modeling conditioned directly on 2D region specifications and discrete operation types, obviating the need for explicit geometry reconstruction. Its multi-domain training strategy generalizes manipulation capabilities to real-world image distributions, potentially informing future data synthesis approaches for vision-LLMs.
Practically, FFSE offers a user-centric interface for physical scene editing with enhanced efficiency and reliability. Its domain adaptation and context alignment techniques point towards robust generalization strategies for vision models trained on hybrid datasets.
Future Directions
Outstanding limitations remain: FFSE does not support non-rigid deformable editing; editing iteration depth is bounded by GPU memory and performance constraints; and compromising on input history length for efficiency may degrade long-term consistency. Future work should explore scalable memory-efficient history conditioning and expand support to non-rigid manipulations.
Conclusion
FFSE establishes a new state-of-the-art for multi-round, physically-consistent, 3D-aware object manipulation in images, matching the flexibility and realism of professional 3D engines via direct autoregressive modeling. The integration of hybrid dataset construction, robust multi-stage training, domain-adaptive attention modules, and explicit context-conditioned processing represents a substantial advance in user-driven scene editing frameworks. The design and performance of FFSE suggest promising future research in efficient, generalizable scene editing for both vision-centric and multimodal AI systems.
